
上一篇中看了List的使用方式、quicklist中的各個結構體,這一篇來看看quicklist里面的幾個核心函數,quicklistCreate函數、quicklistCreateNode函數、quicklistPush函數、quicklistPop函數。
接下來我們通過源碼看一下quicklist中是如何借鑒STL中deque的這種實現思想來完成對于sdlist及ziplist有點的結合的,并且在時間和空間是如何做的均衡,來達到“quick”的效果。
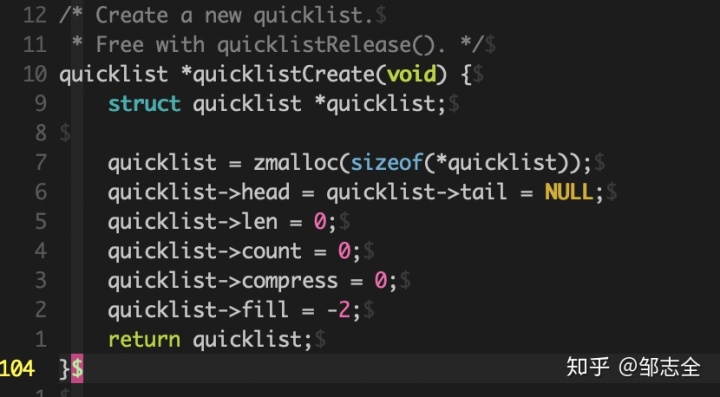
我們打開quicklist.c文件,找到第94行。
首先完成了對于一個quicklist結構體的指針,然后對quicklist進行內存分配操作,之后再設置首尾指針,再指定quicklist的長度、數據項總和、壓縮深度、ziplist的的大小限定(這個值可以有五個取值,-1:每個節點的ziplist字節數不能超過4kb,-2:每個節點的ziplist字節數不能超過8kb,-3:每個節點的ziplist字節數不能超過16kb,-4:每個節點的字節數不能超過32kb,-5:每個節點的字節數不能超過64kb, 默認是不能超過4kb的)
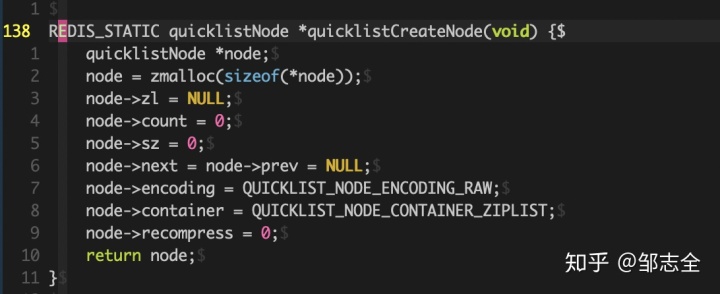
創建完quicklist之后,下一步就是創建quicklist節點了,看一下quicklist的第138行
這個過程和創建quicklist基本上是一致的,聲明指針、申請內存、初始化ziplist指針、初始化數據項、ziplist的大小、初始化prev、next指針、初始化節點編碼方式默認是QUICK_NODE_ENCODING_RAW、初始化數據的存放方式默認是QUICKLIST_NODE_CONTAINER_ZIPLIST,最后初始完壓縮標示然后結束。
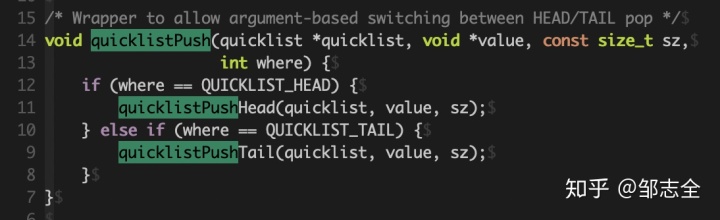
看完初始化操作之后,接下來是PUSH操作:
不管是LPUSH還是RPUSH都包含兩個步驟,如果插入節點的ziplist大小沒有超過限制直接用ziplistPush函數壓入,如果ziplist的大小超過了限制,則新創建一個quicklist來進行壓入。
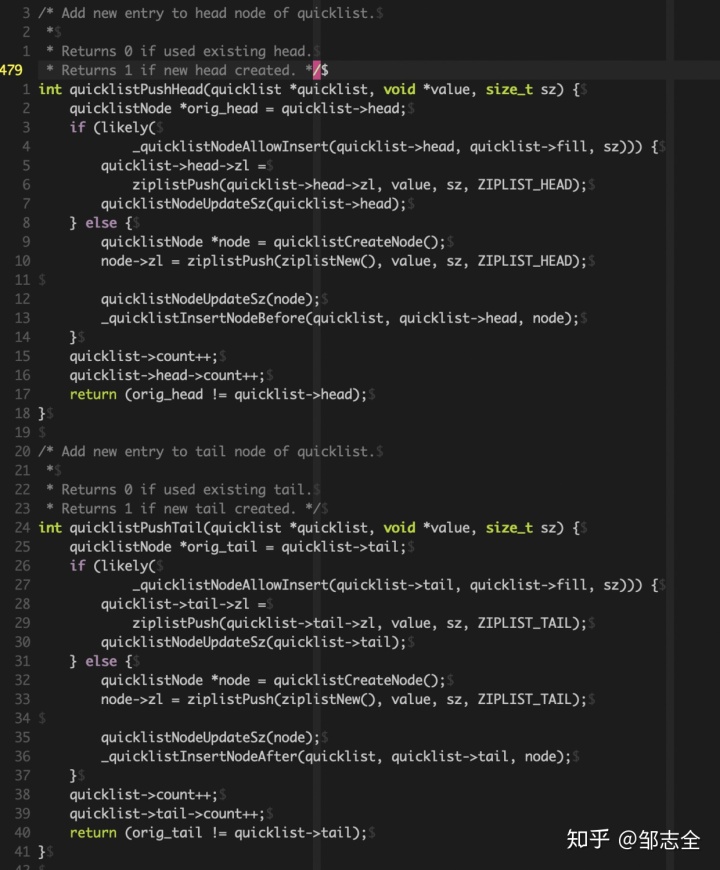
然后來看一下這兩個函數:
likely是linux提供的可選擇的編譯優化方法,可以講分支專一的信息提供給編譯器,然后減少指令跳轉帶來的性能下降(likely是編譯器級別的優化)。
首先判斷首/尾是否允許插入(首部節點的大小和fill參數做比較)然后如果允許插入世界調用ziplistpush插入,然后更新首部大小即可以了,如果節點滿了,看一些else里面的內容,就需要重新創建一個節點,將新節點壓入心創建的ziplist中,并且與新創建的quicklist節點關聯起來,同時更新大小,然后創建一個新的ziplist節點,完成壓入,更新數據項等。如果反悔的quicklist指針沒變,則返回0,否則返回1。
接下來看一下quicklistPop函數,然后具體的邏輯其實是在quicklistPopCustom中實現的。
就是進行Pop操作,執行成功返回1,失敗返回0,如果彈出的節點是字符串,那么data、sz存放彈出字符串值,如果彈出節點是整型,slong存放彈出節點的整型值。
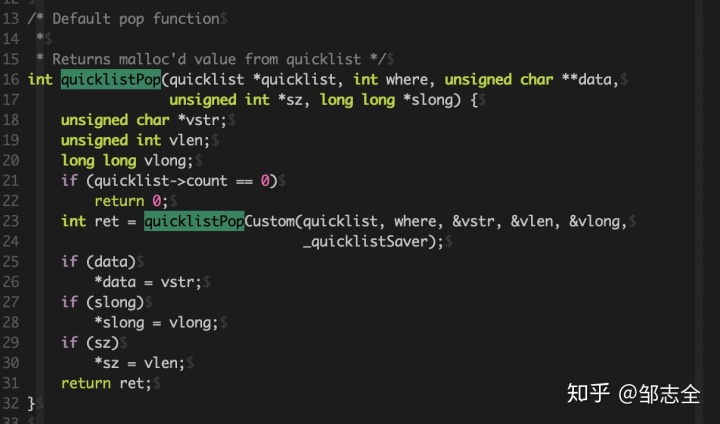
然后具體看一下quicklistPopCustom函數,執行成功返回1,失敗返回0,如果彈出的節點是字符串,那么data、sz存放彈出字符串值,如果彈出節點是整型,slong存放彈出節點的整型值。
首先判斷彈出位置首部或者尾部,如果沒有數據直接return 0,然后獲取quicklist的節點(ziplist),再獲取ziplist的節點,然后獲取節點的值,如果是字符串值,通過_quicklistSaver深拷貝取出返回值,如果是整型的則字符串設置為NULL,彈出節點的整型值,刪除該節點。
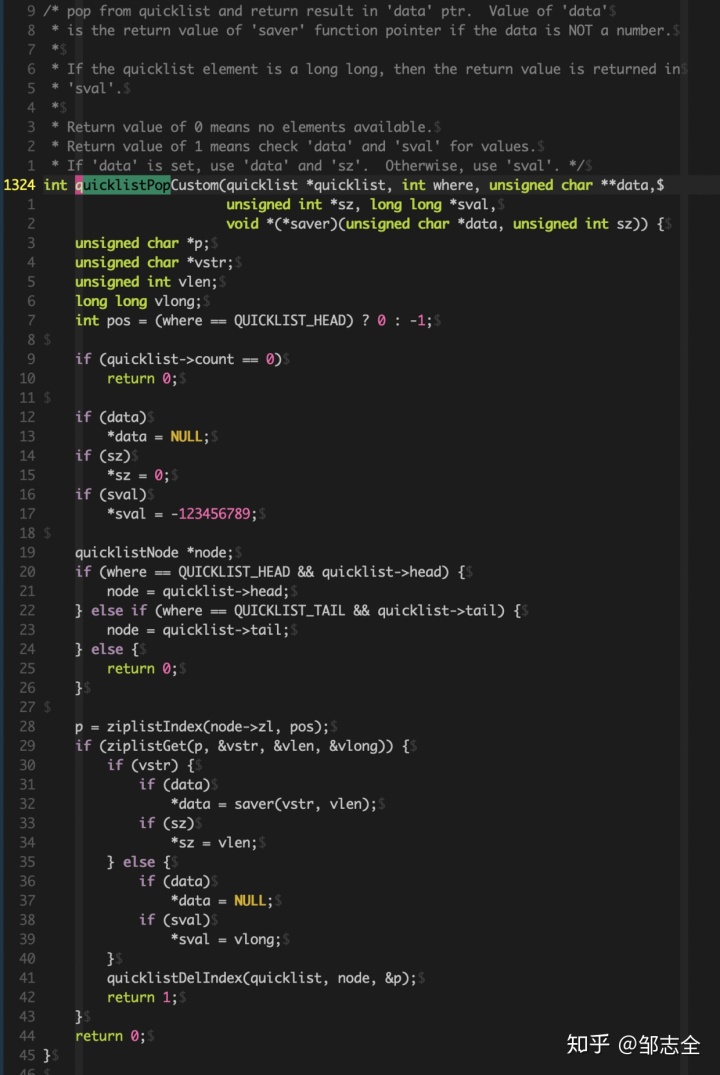
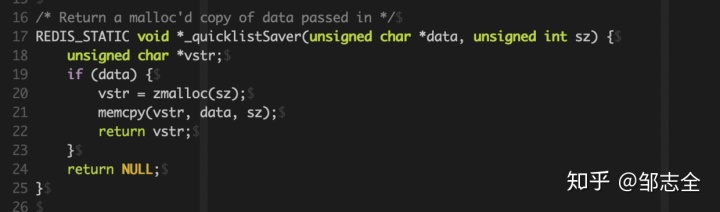
這里_quicklistSaver 深拷貝取值的原因是避免二次釋放。
quicklist核心的API就這幾個,但Redis實際上是實現了好多的,比如說:
1、比較兩個quicklist結構數據的:quicklistCount
2、從節點node中取出LZF壓縮編碼后的數據:quicklistGetLzf
3、翻轉quicklist:quicklistRotate
4、刪除ziplist節點entry:quicklistDelEntry
5、在node節點前添加一個value:quicklistInsertBefore
6、在node節點后添加一個value:quicklistInsertAfter
7、將ziplist轉換為quicklist:*quicklistCreateFromZiplist
)











)





...)
