前言
之前一直感覺斷點續傳比較神秘,于是想去一探究竟,不知從何入手,以為就寫寫邏輯就行,結果搜索一番,還得了解相關http協議知識,又花了許久功夫去看http協議中有關斷點續傳知識,有時候發覺東西只有當你用到再去看相關內容時才會掌握的更加牢固,理解的更加透徹吧,下面我們首先來補補關于http協議中斷點續傳的知識。
http協議知識惡補
當請求一個html頁面時我們會看到請求頁面如下:

第一眼看到上面Accept中的參數時我是懵逼的,之前也就看看緩存cookie等常見的頭信息,于是借此機會也學習下這部分內容。
我們知道Accept是指客戶端允許請求返回的內容類型,那為何這里面參數有如此之多呢?在學習WebAPi時,我們在服務端未進行過濾時既可以返回xml,也可以返回json,此時如上圖一樣,text/html未匹配上,接著匹配xml類型,匹配后則進行相應格式內容返回,所以客戶端接受如此多類型內容,也是為了服務端那邊未設置特定內容響應,此時則根據客戶端設置的內容進行最合適的匹配。
那么問題來了,上面的q是啥玩意?
q(quality)
上面給出了客戶端能夠接受響應的內容類型,自然就有最合適的匹配,此時就用到了q這個參數,在此我將q翻譯為quality即權重的意思,應該是比較合適的,它用來表示我們期待接受內容偏愛的程度即所占的權重。它的范圍是0-1,其默認值為1,這就類似質檢部門對產品合格判斷的一種介質。例如當我們需要返回視頻資源時,我們客戶端設置為如下:
Accept: audio/*; q=0.2, audio/basic
此時我們將上述翻譯如下:
audio/basic; q=1 audio/*; q=0.2
我們更加期待返回的是audio/basic類型的資源,因為其權重為1大于audio/*類型的資源,若為匹配到則繼續匹配下一個資源,audio/*則表示屬于audio類型的所有子類型資源。
接下來,我們再來看一個例子:
Accept: text/plain; q=0.5, text/html,text/x-dvi; q=0.8, text/x-c
此時我們則可以翻譯為如下:
Accept: text/html;q=1或者 text/x-c;q=1 text/x-dvi; q=0.8 text/plain; q=0.5
傾向于返回text/html或者text/x-c類型資源,若都不存在,則返回權重為0.8的text/x-dvi,最終還是不存在則返回text/plain。
Accept-Ranges
在響應頭中添加此字段允許服務端來顯示表明對資源范圍的接受。如果服務端接受一個字節范圍的資源的請求則此時變成如下:
Accept-Ranges: bytes
如果服務端不接受任何范圍的請求資源此時則在響應頭添加如下來告訴客戶端不要發送范圍請求的資源:
Accept-Ranges: none
Content-Range
當在響應頭中添加接受字節范圍的資源時,此時若客戶端請求資源文件比較大時即只是返回部分數據時,此時則返回狀態碼為206的部分內容,在Content-Range響應頭信息中實時顯示當前數據的進度。比如如下:
//開始500個字節數據 Content-Range: bytes 0-499/1234//第二個500個字節數據 Content-Range: bytes 500-999/1234//除了開始500個字節之外的數據 Content-Range: bytes 500-1233/1234//最后500個字節數據(表示數據最終傳輸完畢) Content-Range: bytes 734-1233/1234
如果客戶端請求資源到達所給資源的界限此時則返回416的狀態碼。
注意:當請求資源為字節范圍請求時,不要在響應頭中使用?multipart/byteranges?類型的content-type。?
斷點續傳場景
當正在下載時出于其他任何原因此時下載中斷,那么下載用戶只能重新下載,這樣的體驗想必是比較痛苦的,最煩躁的是如果用戶是在移動端下載大文件時,居然下載中斷了,接下來又得重新下載,此時想必用戶會放棄下載。此時斷點續傳則應運而生。 斷點續傳則需要用到上述Accept-Ranges和Content-Range將其添加到響應頭中。例如如下:
HEAD http://localhost/api/files/get?filename=blog_backup.zip User-Agent: IIS Host: localhostHTTP/1.1 200 OK Content-Length: 1182367743 Content-Type: application/octet-stream Accept-Ranges: bytes Server: Microsoft-IIS/10.0 Content-Disposition: attachment; filename=blog_backup.zip
HEAD http://localhost/api/files/get?filename=blog_backup.zip User-Agent: IIS Host: localhost Range: bytes=0-999HTTP/1.1 206 Partial Content Content-Length: 1000 Content-Type: application/octet-stream Content-Range: bytes 0-999/1182367743 Accept-Ranges: bytes Server: Microsoft-IIS/10.0 Content-Disposition: attachment; filename=blog_backup.zip
接下來我們來實現簡單的下載以及斷點續傳下載對比看看效果。?
在webapi中提供了一系列方便我們調用的api,比如?ContentDispositionHeaderValue?來設置附件而不像在webform中手動在響應頭中進行拼接。以及返回的MimeType類型?MediaTypeHeaderValue?。首先我們看看最普通的下載。
普通下載
普通的下載無非就是獲取到文件的標識再打開下載的文件夾,最后得到文件流返回到響應的HttpContent對象中以及設置附件即可。我們看看如下代碼還是比較簡單的,這種相對比較簡單的下載想必我們大家定是信手拈來。
//響應的MimeType類型private const string MimeType = "application/octet-stream";//配置文件中配置的文件所在路徑private const string AppSettingDirPath = "DownloadDir";//將配置文件中取得的路徑賦給此變量private readonly string DirFilePath;this.DirFilePath = ConfigurationManager.AppSettings[AppSettingDirPath];
接下來就是最重要的下載邏輯了,如下:
public HttpResponseMessage Download(string fileName){var fullFilePath = Path.Combine(this.DirFilePath, fileName);if (!File.Exists(fullFilePath)){throw new HttpResponseException(HttpStatusCode.NotFound);}FileStream fileStream = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.ReadWrite);var response = new HttpResponseMessage();response.Content = new StreamContent(fileStream);response.Content.Headers.ContentDisposition= new ContentDispositionHeaderValue("attachment") { FileName = fileName };response.Content.Headers.ContentType= new MediaTypeHeaderValue(MimeType);response.Content.Headers.ContentLength= fileStream.Length;return response;}
那么問題來了,我們可不可以在獲取文件流返回到HttpContent之前是不是應該首先將文件流放入到緩沖流中然后再返回呢?如下:
var bufferStream = new BufferedStream(fileStream);response.Content = new StreamContent(bufferStream);
我們想著是不是將文件流率先放入到緩沖流中效果是否更佳呢?剛開始我也是這樣想來著,但是經過查證資料發現:
為了得到更好的性能,在文件流中已經包含有緩沖流的緩沖邏輯,對于用緩沖流來包裹文件流的情況沒有任何好處,還有一點就是在.NET Framework中沒有任何一個流需要用到緩沖流,但是,但是有一種情況除外則是若我們自定義實現流且默認沒有實現緩沖的邏輯情況下需要用到緩沖流,資料來源于:Filestream and BufferedStream
上述也算是漲知識了。繼續回到我們的話題,此時我們下載一個文件則看到如下圖所示:
 ?
?
因為未實現斷點續傳,此時我們通過右鍵可以看到無法暫停,如下:
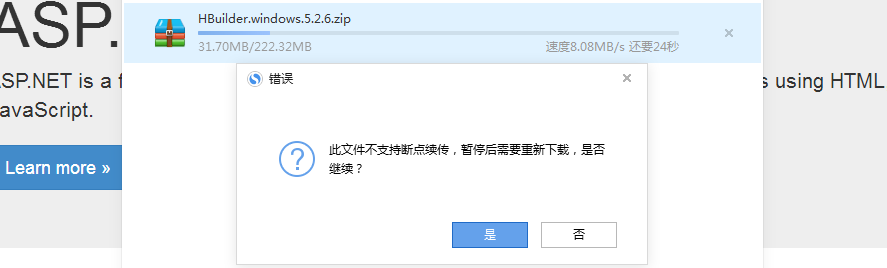
我們繼續往下走,接下來來實現斷點續傳看看:
斷點續傳下載
在WebAPi提供了Range屬性其返回對象為?RangeHeaderValue?里面有存在每個范圍的集合如下:
// 摘要: // Gets the ranges specified from the System.Net.Http.Headers.RangeHeaderValue// object.//// 返回結果: // Returns System.Collections.Generic.ICollection<T>.The ranges from the System.Net.Http.Headers.RangeHeaderValue// object.public ICollection<RangeItemHeaderValue> Ranges { get; }
這是為利用多線程下載而提供,這里我們僅僅實現一個范圍的下載。我們通過判斷這個對象的值是否為null來實現斷點續傳。
if (Request.Headers.Range == null || Request.Headers.Range.Ranges.Count == 0 || Request.Headers.Range.Ranges.FirstOrDefault().From.Value == 0){var sourceStream = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read);response = new HttpResponseMessage(HttpStatusCode.OK);response.Content = new StreamContent(sourceStream);response.Headers.AcceptRanges.Add("bytes");//告訴客戶端接受資源為字節response.Content.Headers.ContentLength = sourceStream.Length;response.Content.Headers.ContentType = new MediaTypeHeaderValue(MimeType);response.Content.Headers.ContentDisposition = new ContentDispositionHeaderValue("attachment"){FileName = fileName};}
獲取當前已經下載字節數,接著繼續進行剩下字節下載。
else{var item = Request.Headers.Range.Ranges.FirstOrDefault();if (item != null && item.From.HasValue){response = this.GetPartialContent(fileName, item.From.Value);}}
剩余字節數下載
private HttpResponseMessage GetPartialContent(string fileName, long partial){var response = new HttpResponseMessage();var fullFilePath = Path.Combine(this.DirFilePath, fileName);FileInfo fileInfo = new FileInfo(fullFilePath);long startByte = partial;var memoryStream = new MemoryStream();var buffer = new byte[65536];using (var fileStream = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read)){var bytesRead = 0;fileStream.Seek(startByte, SeekOrigin.Begin);int length = Convert.ToInt32((fileInfo.Length - 1) - startByte) + 1;while (length > 0 && bytesRead > 0){bytesRead = fileStream.Read(buffer, 0, Math.Min(length, buffer.Length));memoryStream.Write(buffer, 0, bytesRead);length -= bytesRead;}response.Content = new StreamContent(memoryStream); }response.Headers.AcceptRanges.Add("bytes");response.StatusCode = HttpStatusCode.PartialContent;response.Content.Headers.ContentType = new MediaTypeHeaderValue(MimeType);response.Content.Headers.ContentLength = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read).Length;response.Content.Headers.ContentDisposition = new ContentDispositionHeaderValue("attachment"){FileName = fileName};return response;}
接下來我們看看演示結果:
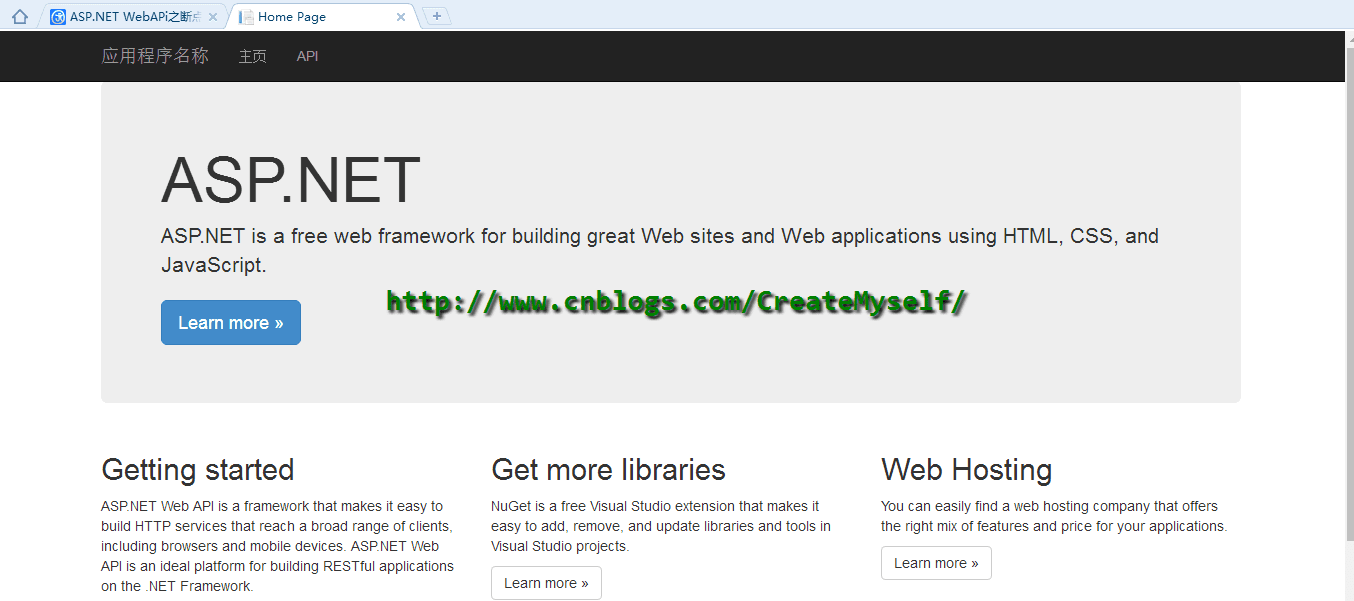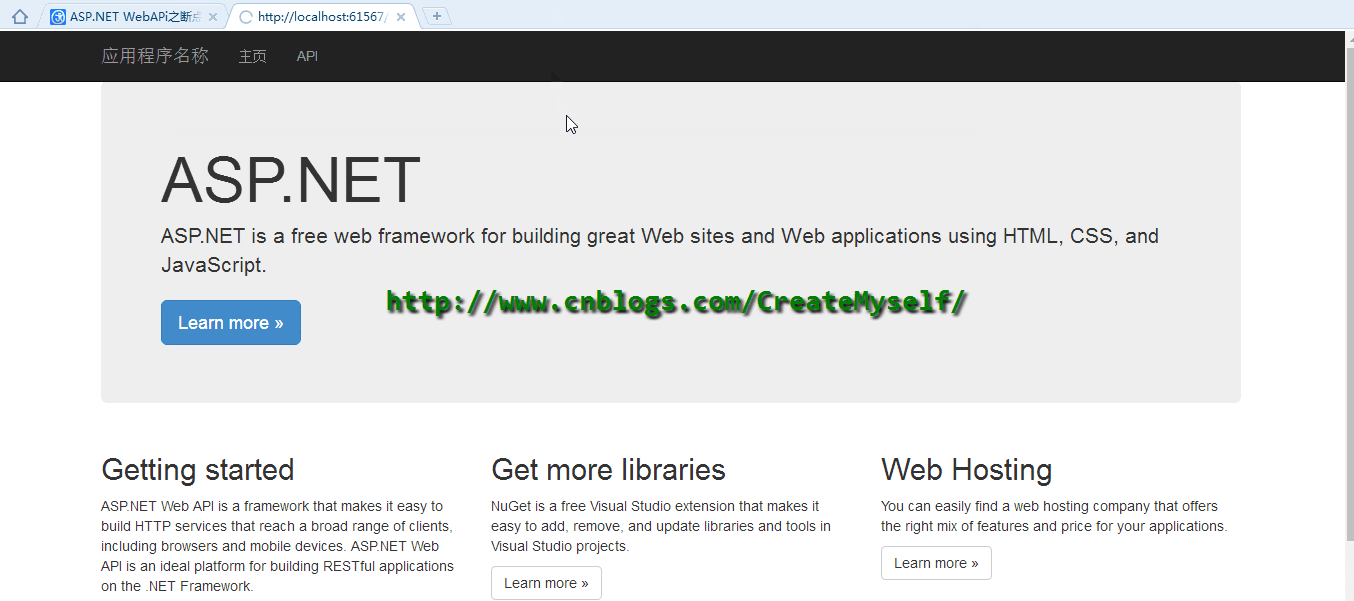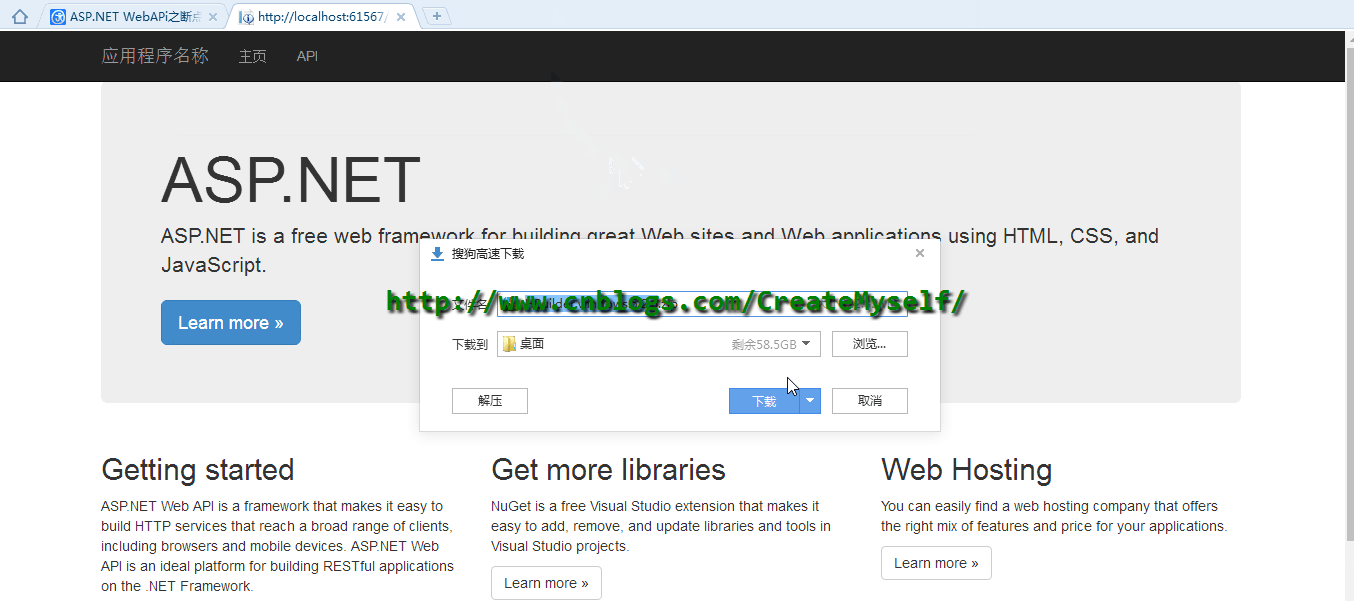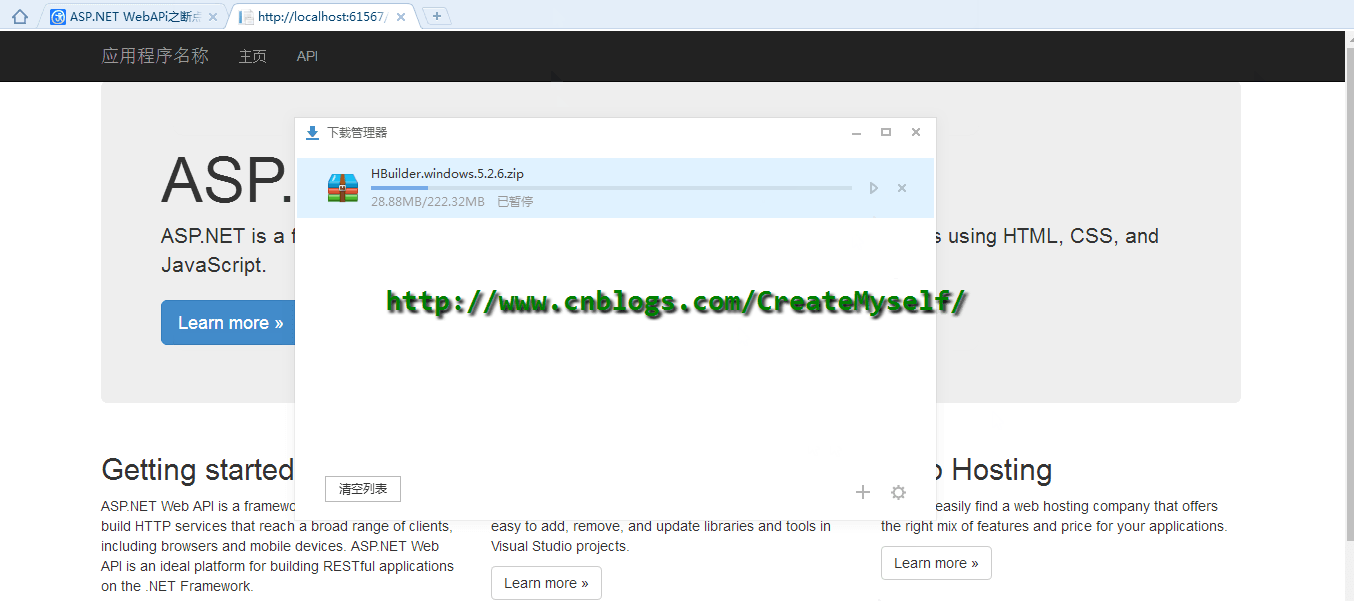
從上面演示我們看出目前已經實現了斷點續傳,瀏覽器下載管理器出現了暫停的按鈕,但是當暫停后無法繼續進行后續下載,在這里存在問題,我們下節再進行后續講解。同時當返回HttpContent發現居然還有一個可以返回的HttpContent即?PushStreamContent?,此時我們可以將剩余部分字節下載進行如下修改:
Action<Stream, HttpContent, TransportContext> pushContentAction = (outputStream, content, context) =>{try{var buffer = new byte[65536];using (var fileStream = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read)){var bytesRead = 0;fileStream.Seek(startByte, SeekOrigin.Begin);int length = Convert.ToInt32((fileInfo.Length - 1) - startByte) + 1;while (length > 0 && bytesRead > 0){bytesRead = fileStream.Read(buffer, 0, Math.Min(length, buffer.Length));outputStream.Write(buffer, 0, bytesRead);length -= bytesRead;}}}catch (HttpException ex){throw ex;}finally{outputStream.Close();}}; response.Content = new PushStreamContent(pushContentAction, new MediaTypeHeaderValue(MimeType));response.StatusCode = HttpStatusCode.PartialContent;response.Headers.AcceptRanges.Add("bytes");response.Content.Headers.ContentType = new MediaTypeHeaderValue(MimeType);response.Content.Headers.ContentLength = File.Open(fullFilePath, FileMode.Open, FileAccess.Read, FileShare.Read).Length;response.Content.Headers.ContentDisposition = new ContentDispositionHeaderValue("attachment"){FileName = fileName};return response;
如上所做也可行,返回StreamContent不就ok了嗎,為何還出現一個PushStreamContent呢?這又是一個遺留問題!
總結
本節我們講述了在webapi中普通下載以及斷點續傳下載,對于斷點續傳下載當暫停后無法繼續進行下載,暫時還存在一定問題,對于返回的內容既可以為StreamContent,也可以是PushStreamContent,這二者有何區別呢?二者的應用場景是什么呢?這又是一個問題,關于此二者我們下節再講,webapi一個很輕量的服務框架,你值得擁有,see u。
)

排序詳解)

(下))













:POJ 3624 Balanced Lineup)
