來源:力扣(LeetCode)
描述:
你會得到一個字符串 s (索引從 0 開始),你必須對它執行 k 個替換操作。替換操作以三個長度均為 k 的并行數組給出:indices, sources, targets。
要完成第 i 個替換操作:
- 檢查 子字符串
sources[i]是否出現在 原字符串s的索引indices[i]處。 - 如果沒有出現, 什么也不做 。
- 如果出現,則用
targets[i]替換 該子字符串。
例如,如果 s = "abcd" , indices[i] = 0 , sources[i] = "ab", targets[i] = "eee" ,那么替換的結果將是 "eeecd" 。
所有替換操作必須 同時 發生,這意味著替換操作不應該影響彼此的索引。測試用例保證元素間 不會重疊 。
- 例如,一個
s = "abc",indices = [0, 1],sources = ["ab","bc"]的測試用例將不會生成,因為"ab"和"bc"替換重疊。
在對 s 執行所有替換操作后返回 結果字符串 。
子字符串 是字符串中連續的字符序列。
示例 1:
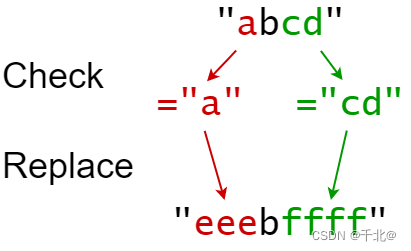
輸入:s = "abcd", indexes = [0,2], sources = ["a","cd"], targets = ["eee","ffff"]
輸出:"eeebffff"
解釋:
"a" 從 s 中的索引 0 開始,所以它被替換為 "eee"。
"cd" 從 s 中的索引 2 開始,所以它被替換為 "ffff"。
示例 2:
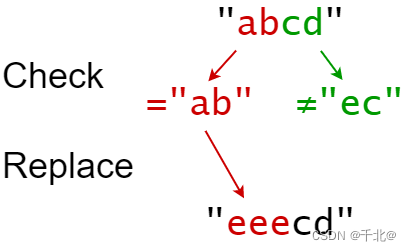
輸入:s = "abcd", indexes = [0,2], sources = ["ab","ec"], targets = ["eee","ffff"]
輸出:"eeecd"
解釋:
"ab" 從 s 中的索引 0 開始,所以它被替換為 "eee"。
"ec" 沒有從原始的 S 中的索引 2 開始,所以它沒有被替換。
提示:
- 1 <= s.length <= 1000
- k == indices.length == sources.length == targets.length
- 1 <= k <= 100
- 0 <= indexes[i] < s.length
- 1 <= sources[i].length, targets[i].length <= 50
- s 僅由小寫英文字母組成
- sources[i] 和 targets[i] 僅由小寫英文字母組成
方法一:按照下標排序 + 模擬
思路與算法
我們直接按照題目的要求進行模擬即可。
首先我們根據數組 indices,將所有的替換操作進行升序排序。在這一步中,同時對 indices,sources,targets 這三個數組進行排序較為困難,我們可以使用一個長度(記為 m)與它們相同的數組 ops,存儲 0 到 m ? 1 這 m 個下標,隨后對 ops 本身按照 indices 作為第一關鍵字進行排序即可。
在排序完成后,我們就可以遍歷給定的字符串 s 進行操作了。我們使用另一個指針 pt 指向 ops 的首個元素,表示當前需要進行的操作。當我們遍歷到第 i 個字符時,我們首先不斷往右移動 pt,直到其移出邊界,或者第 ops[pt] 個操作的下標不小于 iii。此時,會有如下的兩種情況:
- 如果這個下標大于 i,說明不存在下標為 i 的操作。我們可以直接將第 i 個字符放入答案中;
- 如果這個下標等于 i,說明存在下標為 i 的操作。我們將 s 從位置 i 開始的長度與 sources[ops[i]] 的子串與 sources[ops[i]] 進行比較:
- 如果相等,那么替換操作成功,我們將 targets[ops[i]] 放入答案中。由于替換操作不可能重疊,因此我們可以直接跳過 sources[ops[i]] 長度那么多數量的字符;
- 否則,替換操作失敗,我們可以直接將第 i 個字符放入答案中。
需要注意的是,題目中只保證了成功的替換操作不會重疊,而不保證失敗的替換操作不會重疊。因此當這個下標等于 i 時,可能會有多個替換操作需要進行嘗試,即我們需要不斷往右移動 pt,直到其移出邊界,或者第 ops[pt] 個操作的下標嚴格大于 i。遍歷到的替換操作需要依次進行嘗試,如果其中一個成功,那么剩余的不必嘗試,可以直接退出。
代碼:
class Solution {
public:string findReplaceString(string s, vector<int>& indices, vector<string>& sources, vector<string>& targets) {int n = s.size(), m = indices.size();vector<int> ops(m);iota(ops.begin(), ops.end(), 0);sort(ops.begin(), ops.end(), [&](int i, int j) { return indices[i] < indices[j]; });string ans;int pt = 0;for (int i = 0; i < n;) {while (pt < m && indices[ops[pt]] < i) {++pt;}bool succeed = false;while (pt < m && indices[ops[pt]] == i) {if (s.substr(i, sources[ops[pt]].size()) == sources[ops[pt]]) {succeed = true;break;}++pt;}if (succeed) {ans += targets[ops[pt]];i += sources[ops[pt]].size();}else {ans += s[i];++i;}}return ans;}
};
時間 0ms 擊敗 100.00%使用 C++ 的用戶
內存 9.95mb 擊敗 88.18%使用 C++ 的用戶
復雜度分析
- 時間復雜度:O(n+mlog?m+ml),其中 n 是字符串 s 的長度,m 是數組 indices 的長度,l 是數組 sources 和 targets 中字符串的平均長度。
- 排序需要的時間為 O(mlog?m);
- 在使用雙指針進行遍歷的過程中,遍歷字符串需要的時間為 O(n),遍歷數組 ops 需要的時間為 O(m),在最壞情況下需要嘗試每一個替換操作,比較和構造最終答案需要的時間為 O(ml)。
相加即可得到總時間復雜度 O(n+mlogm+ml)。- 空間復雜度:O(n + ml)。
- 數組 ops 需要的空間為 O(m);
- 排序需要的棧空間為 O(log?m);
- 在替換操作中進行比較時,如果使用的語言支持無拷貝的切片操作,那么需要的空間為 O(1),否則為 O(l);
- 在構造最終答案時,如果使用的語言支持帶修改的字符串,那么需要的空間為 O(1)(不考慮最終答案占用的空間),否則需要 O(n + ml) 的輔助空間。
對于不同語言,上述需要的空間會有所變化。這里取每一種可能的最大值,相加即可得到總空間復雜度 O(n + ml)。
方法二:哈希表 + 模擬
思路與算法
我們也可以將方法一中的數組 ops 換成哈希映射,其中的鍵表示字符串中的下標,值是一個數組,存儲了所有操作該下標的操作編號。我們只需要對數組 indices 進行一次遍歷,就可以得到這個哈希表。
在這之后,當我們對字符串 s 進行遍歷時,如果遍歷到位置 i,那么哈希表中鍵 i 對應的數組,就是所有對位置 i 進行的操作。我們使用與方法一相同的方法處理這些操作即可。
代碼:
class Solution {
public:string findReplaceString(string s, vector<int>& indices, vector<string>& sources, vector<string>& targets) {int n = s.size(), m = indices.size();unordered_map<int, vector<int>> ops;for (int i = 0; i < m; ++i) {ops[indices[i]].push_back(i);}string ans;for (int i = 0; i < n;) {bool succeed = false;if (ops.count(i)) {for (int pt: ops[i]) {if (s.substr(i, sources[pt].size()) == sources[pt]) {succeed = true;ans += targets[pt];i += sources[pt].size();break;}}}if (!succeed) {ans += s[i];++i;}}return ans;}
};
時間 0ms 擊敗 100.00%使用 C++ 的用戶
內存 10.12mb 擊敗 59.09%使用 C++ 的用戶
復雜度分析
- 時間復雜度:O(n+ml),其中 n 是字符串 s 的長度,m 是數組 indices 的長度,l 是數組 sources 和 targets 中字符串的平均長度。
- 空間復雜度:O(n+ml)。
author:力扣官方題解


![[C++ 網絡協議編程] UDP協議](http://pic.xiahunao.cn/[C++ 網絡協議編程] UDP協議)



)






)


)


