
電子商務推薦系統主要是通過統計和挖掘技術,根據用戶在網站上的行為,主動為用戶提供推薦服務,從而提高網站體驗。而根據不同的業務場景,推薦系統需要滿足不同的推薦粒度,包括搜索推薦,商品類目推薦,商品標簽推薦,店鋪推薦等等,主要還是以 商品推薦 為主。而商品推薦主要分為規則模型,協同過濾模型和基于內內容的推薦。我們今天介紹的Apriori算法就是基于 規則模型 的算法。
把啤酒放在尿布旁,有助于提升啤酒銷售量
Apriori最典型的落地就是沃爾瑪的啤酒尿布案例。通過用戶交易數據集來尋找商品之間的 關聯規則,探究物品之間的相關性,同時達到“將尿布放入購物車之后,再推薦啤酒比直接推薦啤酒獲取有更好的售賣效果”。
本篇文章首先簡要介紹一下Apriori算法的基本思想,然后使用業務數據進行了簡單的演示。
一、基本概念
以下的是Apriori算法涉及的一些概念,可以通過后續的舉例來理解。
頻繁項集(frequent item sets): 經常 同時出在訂單中商品的組合。{啤酒,尿布}就是一個頻繁項集的例子。
關聯規則(associational rules): 暗示兩種物品集之間可能存在很強的關系。例如,“購買尿布的用戶,有大概率購買啤酒”,這就是一個關聯規則。
給定關聯規則X=>Y,即根據X推出Y:
支持度(Support):該項集出現的次數除以總的記錄數(交易數)。 同時包X和Y的記錄數/數據集記錄數
置信度(Confidence):項集{X,Y}同時出現的次數占項集{X}出現次數的比例。同時包含X和Y的記錄數/包含X的記錄數
提升度(Lift):度量項集{X}和項集{Y}的獨立性。
二、舉例說明
本節通過一個關聯規則推薦的例子給大家介紹一下上述名詞,假設shein售賣四類商品,歷史上共5筆訂單(見下表)
2.1 數據準備
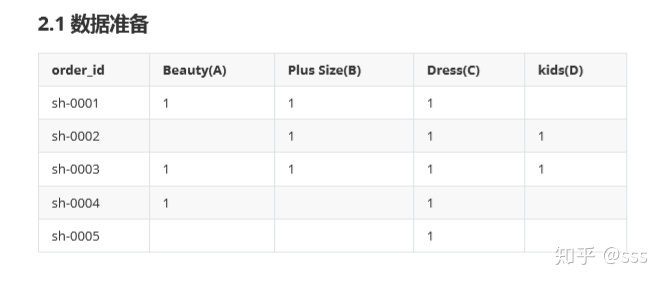
每一行表示一條訂單信息,例如:訂單編號為sh-0001的訂單中包含Beauty、Plus Size、Dress三個品類,以下為方便敘述,使用A、B、C、D來代表上圖的4個品類。
2.2 支持度的計算
支持度是某個商品在總銷售筆數(N)中出現的概率,可以理解為物品當前流行程度。計算方式是:
支持度 = (包含物品A的記錄數量) / (總的記錄數量)
例如下表中,共5筆訂單,3筆包含Beauty,Beauty的支持度是3/5。支持度評估商品包含在訂單中的“概率”,一個訂單,有多大概率包含這個商品。
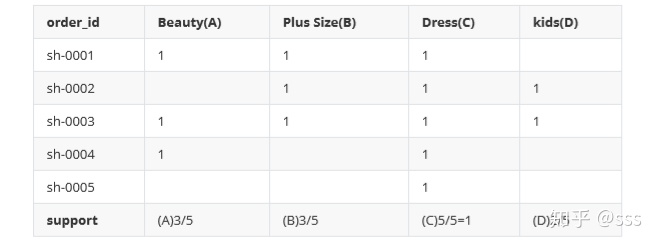
組合商品也有支持度。
共5筆訂單,2筆同時包含AB,即A&B的支持度是2/5。
全局總共4種商品,假設關聯規則只關聯2種商品,則一共需要計算$C_4^2$共6種組合商品的支持度{AB,AC,AD,BC,BD,CD}。
如果想查看那幾種商品組合出現的次數較多,可以通過計算支持度來實現。
2.3 置信度的計算
置信度是指如果購買物品A,有較大可能購買物品B,本質上是條件概率的應用。計算方式是這樣:
置信度( A -> B) = (包含物品A和B的記錄數量) / (包含 A 的記錄數量)
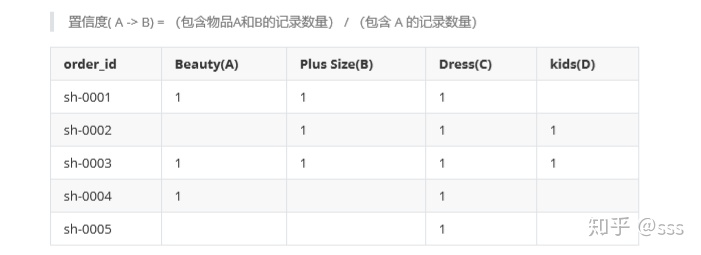
從上表可以看出,商品A有3次購買,這3次中有2次購買了B,A->B的置信度是2/3。
confidence(A->B) = support(A->B)/support(A)= (2/5)/(3/5) = 2/3
分子support(A->B)是同時購買A與B的比例,分母support(A)是只購買A的比例
這里需要注意的是,$X->Y$與$Y->X$的置信度不一定相等。
B->C的置信度是confidence(B->C)=support(B->C)/support(B)=1,即買商品B時,100%會買C;
C->B的置信度是confidence(C->B)=support(C->B)/support(C)=3/5,買商品C時,只有3/5買了B。
2.4 提升度的計算
提升度表示==先購買==A對購買B的概率的提升作用,用來判斷規則是否有實際價值。
在置信度的例子里,$confidence(B->C)=1$,那是不是意味著如果用戶將商品B放入購物車,就可以向用戶推薦商品C來達到提升C銷量的目的呢?
很顯然不是。我們目的是“將尿布放入購物車之后,再推薦啤酒”比“直接推薦啤酒”有更好的售賣效果。雖然購買商品B,100%會買C,但如果直接推薦C,用戶也100%會買C,所以購買B與購買C是獨立事件,用戶買不買C和用戶買不買B沒有直接關系。這里的關聯規則推薦,并沒有比直接推薦獲取更好的效果。
因此提升度是描述使用規則后商品在購物車中出現的次數是否高于商品單獨出現在購物車中的頻率。如果大于1說明規則有效,小于等于1則無效。
提升度( A -> B) = 置信度( A -> B) / 支持度(B)
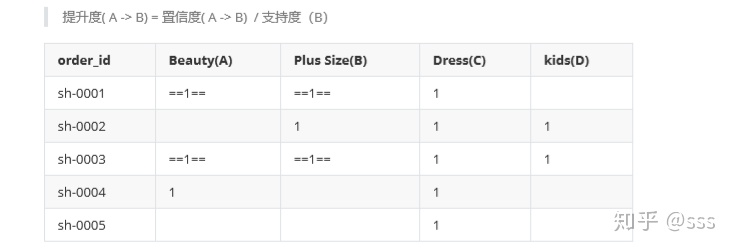
在上表中,有3個訂單購買A,這3個訂單中有2個訂單購買了B,所以:
$confidence(A->B) =support(A->B)/support(A) = 2/3$ 即買了A有$2/3$的概率會買B
$support(B) = 3/5$ 表示直接推薦B的話,5個訂單中有3個購買了B, 即B的支持度是$3/5$,即有$3/5$的概率會直接買B。
$lift(A->B) =confidence(A->B)/support(B) = 10/9$
會發現,使用關聯規則推薦,如果當用戶將Beauty(A)品類的商品加入購物車后,再推薦Plus Size(B)品類,比直接推薦Plus Size(B)品類的效果更好。
2.5 總結
在上述關聯規則推薦的例子中,推薦的目標是想“將尿布放入購物車之后,再推薦啤酒”比“直接推薦啤酒”有更好的售賣效果。
- 支持度support(A->B),是用戶同時購買A和B概率
- 置信度confidence(A->B),是用戶購買A的同時,有多大概率購買B
- 提升度lift(A->B),是“用戶購買A的同時,有多大概率購買B”與“直接購買B的概率”的比值
- 提升度大于1時,說明A->B有正向效果
- 提升度等于1時,說明A和B是獨立事件
- 提升度小于1時,說明A->B有負向效果
三、算法實現
網上有很多封裝好的Apriori算法,大家也可以自行下載使用,代碼詳見Jupyter notebook
算法對數據分析師而言只是工具,了解基本原理且會調用代碼即可。
算法實現涉及到兩個重要的定理:
- 如果一個集合是頻繁項集,則它的所有子集都是頻繁項集。假設一個集合{A,B}是頻繁項集,則它的子集{A}, {B} 都是頻繁項集。
- 如果一個集合不是頻繁項集,則它的所有超集都不是頻繁項集。假設集合{A}不是頻繁項集,則它的任何超集如{A,B},{A,B,C}必定也不是頻繁項集。
通過以上兩個定理可以減少程序的計算次數,提高程序的速度。
Apriori實際應用
? 1.需要根據不同的粒度,如品類,skc等,結合不同的維度,如瀏覽行為,購買行為,構建符合業務場景的規則模型。
? 2.Apriori也可以用來進行個topn個性化推薦。首先可以根據一定時間范圍內訂單數據找到強關聯規則(skc)。然后在根據用戶購買的商品和規則進行關聯,預測用戶感興趣的商品,同時過濾掉用戶已經購買過的商品,對于其他商品按照置信度降序進行排序,為用戶推薦。
? 3.Apriori也可以用來進行關鍵路徑分析,研究某個功能或者某些特點的人群的在某些業務場景下的路徑。
3.1presto中準備好數據
--準備數據
select
week(cast(substr(t1.pay_time,1,10) as date)) as week_num --周序號
,order_id --訂單ID
,array_join(array_agg(distinct cate2),',') as cate from dw.item_df t1
left join da.category t2
on t1.sku_cate = t2.cate4nmwhere site_tp = 'xxx'
and del_flag = 0
and substr(pay_time,1,10) = '2020-04-25' --修改時間事件范圍
and country = 'xxx'
and site_id <> 'xxx'
group by 1,23.2利用python中mlxtend模塊實現
1.首先在命令行中安裝mlxtend(可以新建一個環境防止包沖突)
pip install mlxtend2.導入模塊。
#導入包(第一次運行的時候會比較慢)
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules3.調整數據格式,調用包。
if __name__ == '__main__':#讀取數據并且調整格式data_set = pd.read_excel('shiyan.xlsx').cate.str.split(',').tolist()#進行 one-hot 編碼te = TransactionEncoder()te_ary = te.fit_transform(data_set)df = pd.DataFrame(te_ary, columns = te.columns_)#利用 Apriori 找出頻繁項集frequent_itemsets = apriori(df, min_support = 0.1, use_colnames = True)#計算關聯規則,一般只需要設置最小執行都就行rules = association_rules(frequent_itemsets, metric = 'confidence' ,min_threshold = 0.3)4.導出excel
#導出excel
rules.to_excel(r'C:/Users/dell/Desktop/result.xlsx',encoding = 'utf-8')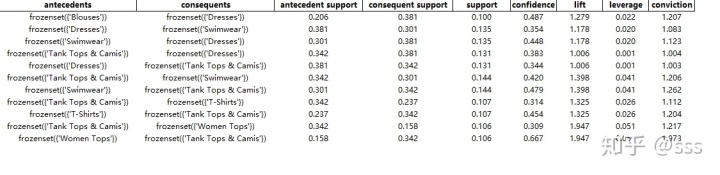
參數解釋:
association_rules(df, metric = ‘confidence‘, min_threshold = 0.8, support_only = False):
-df:這個不用說,就是 Apriori 計算后的頻繁項集。
-metric:可選值['support' , 'confidence' , 'lift' , 'leverage' , 'conviction']。里面比較常用的就是置信度和支持度。這個參數和下面的min_threshold參數配合使用
-min_threshold:參數類型是浮點型,根據 metric 不同可選值有不同的范圍,
- metric = 'support' => 取值范圍 [0,1]
- metric = 'confidence' => 取值范圍 [0,1]
- metric = 'lift' => 取值范圍 [0, inf]
-support_only:默認是 False。僅計算有支持度的項集,若缺失支持度則用 NaNs 填充。



















