創建模型需要用到機器學習的庫,所以我們先下載sklearn庫
sklearn庫
下載完成后再輸入庫文件,就可以完美運行。
然后就是劃分測試集和訓練集,需要注意的是,在從數據處理函數中導入數據時,足足運行了有將近30多秒,可見在數據處理部分,分詞、添加停用詞等步驟是非常復雜和消耗資源的,所以我在當初講這個課題后提出的,把一次運行完后獲得的分詞數據進行保存,以便接下來的詞云繪制和模型構建兩步進行快速訪問數據,還是非常有用的。
往后在Tf-idf權重計算這一環節出現了錯誤
(X_tr = TfidfTransformer().fit_transform(data_tr.toarray()).toarray())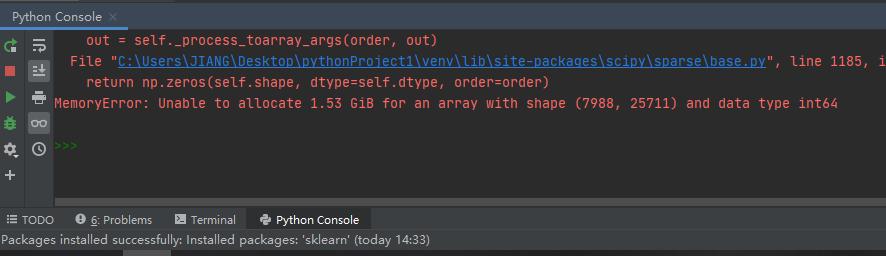
查了百度后,得知解決辦法大致是通過控制面板的高級系統設置,更改系統給每一個硬盤分區所分配的內存來解決,我試了之后,問題果然解決了。
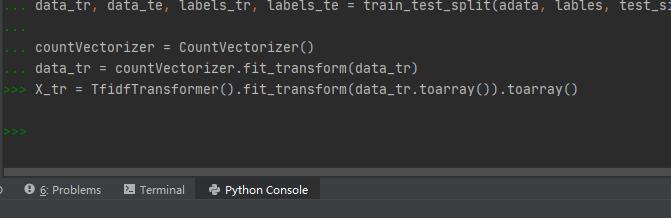
當然嚴格來說這其實是一個悖論,因為要想更改系統給硬盤分配的內存生效,就必須重啟計算機,而重啟計算機也會重新使系統給應用程序分配內存,這樣也可以解決內存不足問題。所以說你不可能只讓系統給應用分配的內存空間設置生效,而不讓系統重啟,這樣在邏輯上是行不通的。
之后測試集的劃分就順利多了,然后進行機器學習,輸入測試集評估模型,模型準確度為0.8525
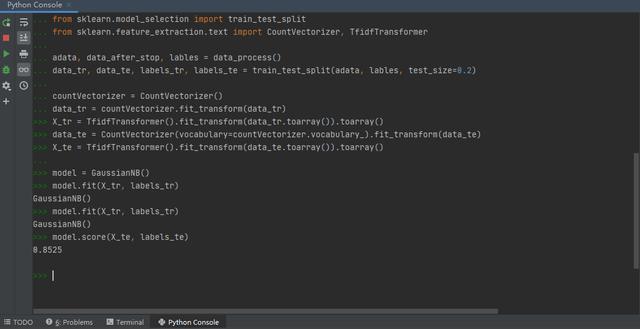
寫到這里整個項目算是完成了,但為了加深印象,我們不妨再看一下其中的幾個數據
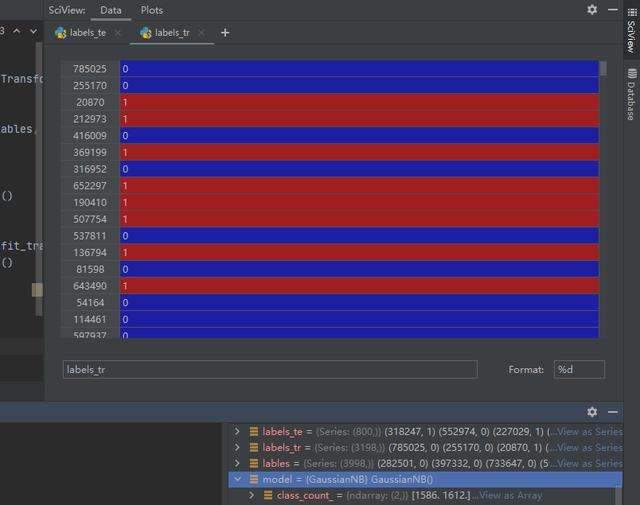
訓練集和測試集
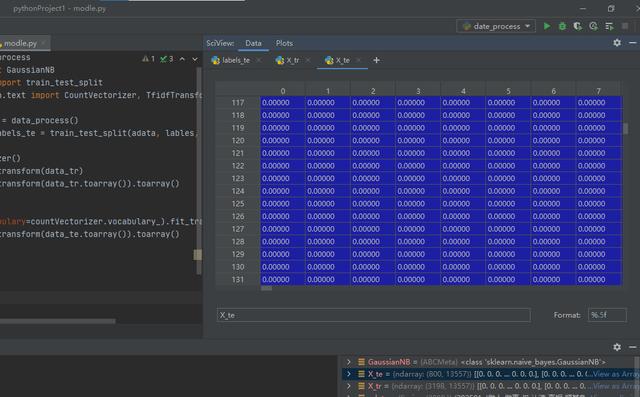
這個是數據的TF idf權重計算。因為得到的是稀疏矩陣,一行中只有很少部分有值,因此我們看到的大多都是零。
我個人認為,Pycharm并不是一個完美的文本編輯器,一是他的每個項目都是一個虛擬環境,為這個項目所匹配的庫文件并不能為其他項目所適用,如果在另外的項目里邊講引用庫,就要重新下載,當然pycharm的作者可能有他自己的想法,但是我個人總覺得,這種想法,似乎并不是很適合我們中國的不是頂尖的大學的大學生的思維。
我已經在邊角時間給 Python安裝了pip,并成功的給python增加了pandas 庫,所以說理論上,我們在Pycharm里面能完成的工作也能在Python自帶的IDEI里面完成,如果時間允許,我可能會嘗試這樣的操作。
總結
總結來說,由于計算機環境不同,我們不可能完全復制我們老師所錄制視頻的操作步驟,如果遇到的錯誤老師沒有講過,就要充分利用互聯網的豐富性和我們個人思維的靈活性,嘗試通過理解編譯器報錯提示和百度搜索這兩種方法來解決問題。
最后,作為python的新學者,遇到問題首先問身邊的朋友或者老師,但有些問題并不能得到解決。這時我們可以去網絡上搜索。這里我就推薦新學者去csdn搜索來解決我們遇到的問題。里面可以解決我們遇到的各種各樣的問題。最后愿天下再無bug。

20分鐘讀懂程序集)


)
)













