?
1、字符串在C里邊就是字符數組
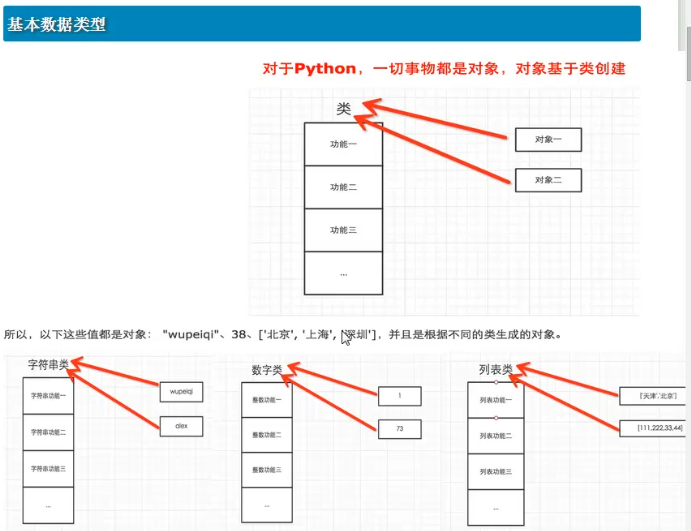
Python里邊一切事物都是對象,對象則是類創建的
?2、set集合
set是一個無序且不能重復的元素集合
#!/usr/bin/env python
# encoding: utf-8
#set對象不能有重復
s1 = set()
s1.add('alex')
print(s1)
s1.add('alex')
print(s1)
s1.add('shidong')
print(s1)
s1.clear()
print(s1)
s2 = set(['shi','shidong','sd','shi'])
print(s2)
結果:
{'alex'}
{'alex'}
{'shidong', 'alex'}
set()
{'shi', 'shidong', 'sd'
?
set中可以有添加列表
s2 = set(['shi','shidong','sd','shi'])
print(s2)
difference函數生成新的集合
s2 = set(['shi','shidong','sd','shi'])
s3 = s2.difference('shi','shidong')
print(s3)
結果:
{'sd'}
?
#def:difference_update ,刪除傳入參數,并改變原來的set()集合,
#但是s2.difference_update 集合并沒有內容
s2 = set(['shi','shidong','sd','shi'])
s4 = s2.difference_update(['shidong','sd'])
print(s2)
print(s4)
#discard 移除元素 intersection 取交集,新創建一個set
#symmetric_difference() 取到兩個集合的差集,遍歷兩個集合,把兩個集合的差集合并成一個集合
#isdisjoint 如果沒有交集返回True
#issubset 是否是子集
#issuperset 是否是父集
#remove 只移除元素,需要加參數,并且沒有返回值
#pop 移除一個元素,也可以把移除的元素賦值到新的集合中
s2 = set(['shi','shidong','sd','shi'])
ret = s2.pop()
print(s2)
print(ret) 3、collections系列
?一、計數器(counter)
Counter 是對字典類型的補充,用于追蹤值的出現次數
ps:具備字典的所有功能 + 自己的功能
| 1、c = Counter('abcdfasdfdsfa') |
| 2、print c |
| 3、輸出: Counter({'a':5, 'b':4,'c':3,'d':2,'e':1}) |
Counter方法:查找對象的前幾位:
例如:
#!/usr/bin/env python
# encoding: utf-8
import collections
obj = collections.Counter('shidong')
ret = obj.most_common(4)????? #most_common :顯示對象的前四位
print(ret)
#elements 方法:用來循環對象中的內容
for item in obj.elements():
print(item)
#循環并取出對象中的健值以及values
for k,v in obj.items():
print((k,v))
#update 方法:增加元素
obj = collections.Counter(['11','22','22','33'])
print(obj)
obj.update(['eric','11','11'])
print(obj)
#刪除元素substract()
obj.subtract(['eric','11'])
print(obj) ?
二、有序字典(orderedDict)
orderdDict是對字典類型的補充,他記住了字典元素添加的順序
#有序字典OrderedDict()
dic = collections.OrderedDict()
dic['k1'] = 'v1'
dic['k2'] = 'v2'
dic['k3'] = 'v3'
print(dic)
#把某個鍵跟值拿到最后
dic.move_to_end('k2')
print(dic)
#按照順序拿:拿最后一個健值,按照后進先出執行:popitem()
dic.popitem()
print(dic)
#自己指定去拿那個pop(),而且能夠返回值
dic.pop('k1')
print(dic)
ret = dic.pop('k3')
print(ret)
#setdefault 設置默認值
#update()方法,不存在則增加值,存在則更改值
#字典默認輸出的時候只輸出key
dic.update({'k1':'v111','k2':'v10','k3':'22'})
print(dic)
?
三、默認字典(defaultdict)
defaultdict是對字典的類型的補充,他默認給字典的值設置了一個類型。
?四、隊列(deque)
#!/usr/bin/env python
# encoding: utf-8
#Python提供了兩種隊列:一種是雙向隊列一種是單項隊列(先進先出FIFO)
#棧就相當于彈匣,后進先出
import collections
d = collections.deque()
d.append('1')
#在左側插入
d.appendleft('10')
d.appendleft('1')
d.appendleft('5')
print(d)
#查看某個元素的個數count方法
print(d.count('1'))
#擴展extend(向右側擴展)
d.extend(['yy','uu','ii'])
print(d)
#擴展extendleft(像左側擴展)
d.extendleft(['shi','dong'])
print(d)
#刪除某個值remove
d.remove('shi')
print(d)
#反轉reverse
d.reverse()
print(d)
#rotate(英文意思:旋轉,輪換,使輪流),功能:做到首尾連接
#最后一個元素能夠連接到第一個元素,從右邊的數據拿到左邊輪
#插入
d.rotate()
print(d)
d.rotate(3)
print(d)
五、拷貝 ——深淺拷貝
數字、字符串用的是同樣的內存地址,復制操作不會改變內存地址
其余拷貝會改變內存地址,,淺拷貝只拷貝第一次,不會拷貝多層,
深拷貝會全部拷貝。
六、單項隊列(先進先出)
#單項隊列在queue模塊中
import queue
#創建單項隊列
q = queue.Queue()
#往里邊插入一條數據
#qsize()方法:拿到隊列的個數
q.put('shi')
q.put('123')
print(q.qsize())
#從里邊拿數據
print(q.get())
七、函數
在學習函數之前,一直遵循:面向對象編程,即:根據業務邏輯從上到下實現功能,其往往用一段代碼來實現指定功能,
開發過程中最常用的功能就是粘貼復制,也就是將之前實現的代碼塊復制到現需功能處,如下:
while True:
if cpu利用率 > 90%:
#發送郵件提醒
連接 郵件服務器
發送郵件
關閉連接
if 硬盤使用空間 > 90%
#發送郵件提醒
連接郵件
關閉連接
if 內存占用 > 80%
#發送郵件提醒
連接郵件
關閉連接
定義函數:
def name():
try方法:(首先執行try方法中的代碼,如果代碼錯誤則執行except中的代碼)
try:
...
except Exception:
...
函數發送郵件示例:
#!/usr/bin/env python
# encoding: utf-8
#函數:自定義函數 函數格式
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
def mail():
ret = 123
try:
msg = MIMEText('收到即為成功','plain','utf-8')
msg['From'] = formataddr(["史冬",'sd880413@sina.cn'])
msg['To'] = formataddr(["sd", '980653381@qq.com'])
msg['Subject'] = "測試函數郵件"
server = smtplib.SMTP("smtp.sina.cn",25)
server.login("sd880413@sina.cn","shidong00")
server.sendmail('sd880413@sina.cn',['980653381@qq.com',],msg.as_string())
server.quit()
except Exception:
ret = 456
return ret
ret = mail()
if ret:
print("發送成功!!")
else:
print("發送失敗!!")
如果一個函數中沒有return,那么函數會返回None
return放在函數和方法中,一遇到return值,那么return后的代碼則不會執行:return——1、中斷函數操作2、返回函數值
#!/usr/bin/env python
# encoding: utf-8
#無參數
#show(): -->show()
# 一個參數
# def show(arg):
# print(arg)
# show('kkkk')
#兩個參數
# def show(arg,xxx):
# print(arg,xxx)
# show('kkkk','777')
#默認參數,給形參加上一個數值,如果在調用的時候不指定參數,那么就會返回
#形參的指定值,默認參數必須放在最后。
# def show(a1,a2=888):
# print(a1,a2)
# show(33)
# show(22,44)
#指定參數:
# def show(a1,a2):
# print(a1,a2)
# show(a2=23,a1=111)
#動態參數:參數也可以是列表,一顆星代表把所有的參數自動轉換成一個元組
#兩個星代表把傳入的所有參數全都轉換成一個字典
#一顆星:
# def show(*arg):
# print(arg,type(arg))
# show(1,2,3,3,4,5,7,)
#兩顆星
# def show(**arg):
# print(arg,type(arg))
# show(a1=88,uu=213)
#一星、兩星共用
def show(*args,**kwargs):
print(args,type(args))
print(kwargs,type(kwargs))
show(1,2,3,3,2,111,n=2,a=5)
結果:
(1, 2, 3, 3, 2, 111) <class 'tuple'>
{'a': 5, 'n': 2} <class 'dict'>
示例:
#一星、兩星共用
def show(*args,**kwargs):
print(args,type(args))
print(kwargs,type(kwargs))
#show(1,2,3,3,2,111,n=2,a=5)
l = [11,22,33,44]
d = {'n1':88,'alex':'sb'}
#如果直接添加參數,那么可能會被系統默認為是元組或者列表,
#字典也會加入到一星的動態參數中,如果想要對應加入,如:字典要
#放到兩星參數中,則采用如下方法
show(*l,**d)
結果:
(11, 22, 33, 44) <class 'tuple'>
{'n1': 88, 'alex': 'sb'} <class 'dict'>
?使用動態參數實現字符串格式化:
#字符串格式化,并傳入動態參數
s1 = "{0} is the best {1}"
resul = s1.format('shidong','man')
print(resul)
結果:
shidong is the best man
或者 如:
#字符串格式化,并傳入動態參數
s1 = "{0} is the best {1}"
l1 = ['shidong','winner']
#resul = s1.format('shidong','man')
resul = s1.format(*l1)
print(resul)
結果:
shidong is the best winner
或者 如:
s1 = "{name} is {acter}"
result = s1.format(name = 'shidong',acter = 'successful')
print(result)
結果:
shidong is successful
如果是參數是字典,需要加兩星
s1 = "{name} is {acter}"
d = {'name':'shidong','acter':'successful'}
result = s1.format(**d)
print(result)
結果:
shidong is successful
八、lambda表達式:簡單函數的簡單表示
例如:
lambda表達式:
func = lambda a :a + 1
#創建形式參數a
#函數內容,a + 1 并把結果return
ret = func(98)
print(ret)
結果:
99
九、內置函數
這些內置函數不需要導入任何模塊就能使用。
abs():絕對值:
a = -1
ret = abs(a)
print(ret)
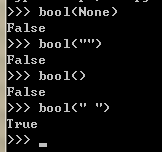
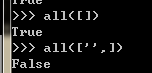
all():判斷元素,如果所有都為真才為真,如果為空或者None也為假
查看真假用bool
例如:
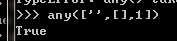
any():只要里邊有真的就為真
ascii() :可以得到一個返回值
?ascii(8) 相當于int.__repr__()
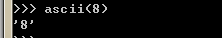
bin():表示二進制
>>>bin(10)
‘0b1010’
bool():布爾
bytearray():把傳入的字符串、列表轉換成字節數組
一個漢字需要占用3個字節
ret = bytearray('史冬',encoding='utf-8')
print(ret)
結果:bytearray(b'\xe5\x8f\xb2\xe5\x86\xac')
?callable():函數 查看函數兒能否被調用,是否可執行
例如:
func = lambda a : a + 1
print(func(2))
print(callable(func))
結果:
3
True
chr() 和ord() 兩個要經常一起用,一個是把數字轉換成ASCII碼,一個是把ASCII轉換成數字
chr():把數字轉換成字符,ord()把字符轉換成數字
import random
a = random.randint(97,120)
b = chr(a)
print(a,b) 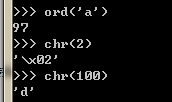
compile():編譯用到的
enumerate():函數會添加一個序列用來記錄序列,例如:
li = ["alex","shidong","xian"]
for i,item in enumerate(li,1):
print(i,item)
結果:
1 alex
2 shidong
3 xian
eval()函數:可以用于計算Excel表格中的運算,例如:
a = eval('6*8')
print(a)
結果:
48
map:
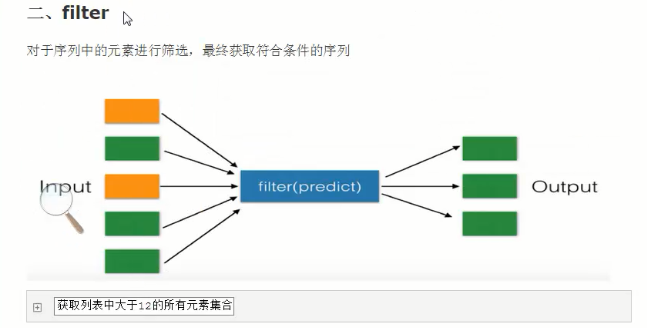
map示例:map左邊有多少然后經過條件后,右邊相對應的過濾出來,例如:
li = [11,22,33,44,]
new_li = map(lambda x : x + 100,li)
l = list(new_li)
print(l)
結果:
[111, 122, 133, 144]
filter()函數:起到過濾作用
def func(x):
if x > 33:
return True
else:
return False
li = [11,22,33,44,]
ret = filter(func,li)
print(list(ret))
float()函數:把一個數轉換成float類型
frozenset()函數:凍結集合
globals()函數:當前的全局變量
oct()函數:八進制
hex()函數:十六進制
例如:
hex(10)
結果:0xa
locals()函數:局部變量
max()函數:拿到最大值
例如:
print(max(11,22,3,34,534456345,))
結果:534456345
open()函數:打開文件
range()函數:拿到區間值
round()函數:四舍五入
zip()函數:兩個對象的元素對應起來
例如:
x = [1,2,3,4,]
y = [2,3,4,5,]
ziped = zip(x,y)
wo = list(ziped)
print(wo)
結果:
[(1, 2), (2, 3), (3, 4), (4, 5)]
?
read():可以讀取幾個字節,例如:
#!/usr/bin/env python
# encoding: utf-8
f = open('test.log','r',encoding='utf-8')
#f.write('hello world!!!')
ret = f.read(2)
print(ret)
f.close() readable():是否可讀
readline():僅讀取一行
seek():指定文件中指針位置
seekable():指針是否可操作
tell():獲取指針位置 ()指的是字節)
例如:
#!/usr/bin/env python
# encoding: utf-8
f = open('test.log','r',encoding='utf-8')
#print(f.tell())
#ret = f.read(2)#按照字符來拿
#print(f.tell())#tell按照字節執行
f.seek(1)#讓指針跳到哪兒
ret = f.read()#不加參數全部讀出來,加參數指定讀取字符
#print(f.tell())
f.close()
print(ret)
truncate()函數:讀取指針前面的數,刪除指針后面的數,然后保存源文件
?
?
?
?
?
?
?













外部程序)





