一、MapReduce模型框架
? ? ? ?MapReduce是一個用于大規模數據處理的分布式計算模型,最初由Google工程師設計并實現的,Google已經將完整的MapReduce論文公開發布了。其中的定義是,MapReduce是一個編程模型,是一個用于處理和生成大規模數據集的相關的實現。用戶定義一個map函數來處理一個Key-Value對以生成一批中間的Key-Value對,再定義一個reduce函數將所有這些中間的有相同Key的Value合并起來。很多現實世界中的任務都可用這個模型來表達。
1、MapReduce模型
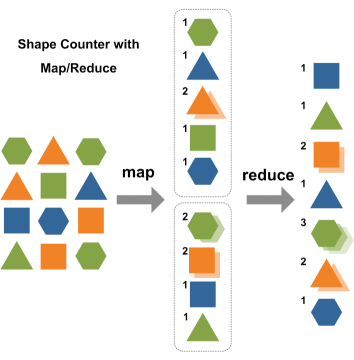
源數據 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 中間數據 ? ? ? ? ? ? ? ? ?結果數據
MapReduce模型如上圖所示,Hadoop MapReduce模型主要有Mapper和Reducer兩個抽象類。Mapper端主要負責對數據的分析處理,最終轉化為Key-Value的數據結構;Reducer端主要是獲取Mapper出來的結果,對結果進行統計。
2、MapReduce框架
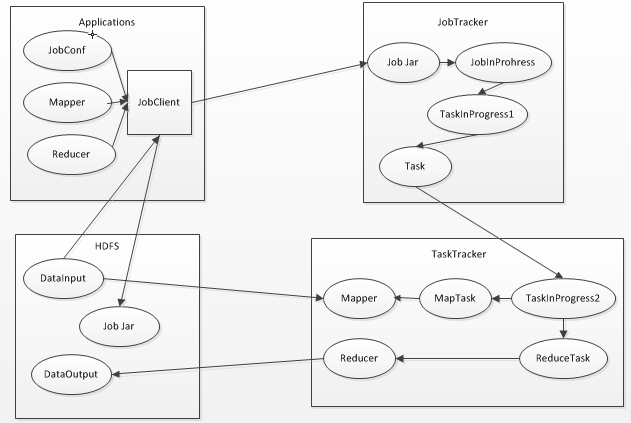
整個過程如上圖所示,包含4個獨立的實體,如下所示:
- client:提交MapReduce作業,比如,寫的MR程序,還有CLI執行的命令等。
- jobtracker:協調作業的運行,就是一個管理者。
- tasktracker:運行作業劃分后的任務,就是一個執行者。
- hdfs:用來在集群間共享存儲的一種抽象的文件系統。
- Mapper和Reducer
- JobTracker
- TaskTracker
- JobClient
- JobInProgress
- TaskInProgress
- MapTask和ReduceTask
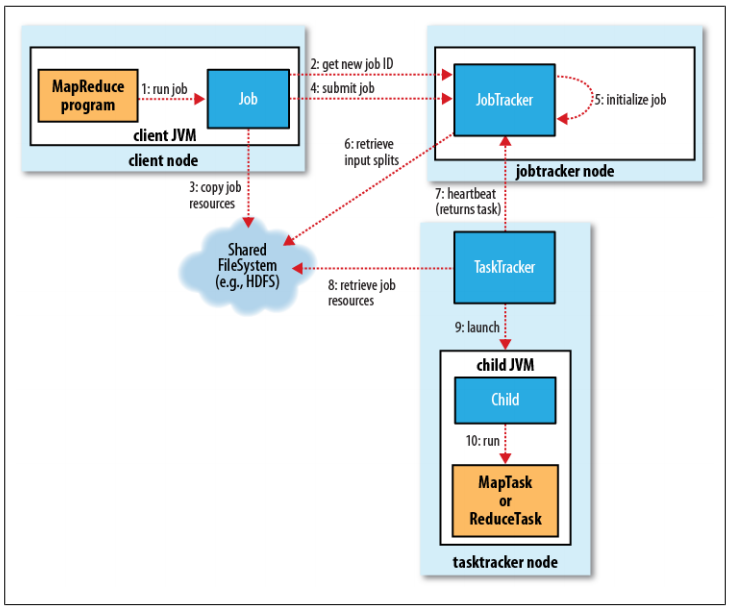
- 通過JobTracker的getNewJobId()方法,向jobtracker請求一個新的作業ID。參見步驟2。
- 檢查作業的輸出說明,也就是說要指定輸出目錄的路徑,但是輸出目錄還不能存在(防止覆蓋輸出結果),如果不滿足條件,就會將錯誤拋給MapReduce程序。
- 檢查作業的輸入說明,也就是說如果輸入路徑不存在,作業也沒法提交,如果不滿足條件,就會將錯誤拋給MapReduce程序。
- 將作業運行所需的資源,比如作業JAR文件、配置文件等復制到HDFS中。參見步驟3。
- 通過JobTracker的submitJob()方法,告訴jobtracker作業準備執行。參見步驟4。
- JobTracker接收到對其submitJob()方法調用之后,就會把此調用放入一個內部隊列當中,交由作業調度器進行調度。(說明:Hadoop作業的調度器常見的有3個:先進先出調度器;容量調度器;公平調度器。Hadoop作業調度器采用的是插件機制,即作業調度器是動態加載的、可插拔的,同時第三方可以開發自己的作業調度器,參考資料”大規模分布式系統架構與設計實戰”)。參見步驟5。
- 初始化包括創建一個表示正在運行作業的對象——封裝任務的記錄信息,以便跟蹤任務的狀態和進程。參見步驟5。
- 接下來要創建運行任務列表,作業調度器首先從共享文件系統中獲取JobClient已計算好的輸入分片信息,然后為每個分片創建一個map任務(也就是說mapper的個數與分片的數目相同)。參見步驟6。(創建reduce任務的數量由JobConf的mapred.reduce.task屬性決定,它是用setNumReduceTasks()方法來設置的,然后調度器創建相應數量的要運行的reduce任務,默認情況只有一個reducer)
- tasktracker本身運行一個簡單的循環來定期發送”心跳(heartbeat)”給jobtracker。什么是心跳呢?就是tasktracker告訴jobtracker它是否還活著,同時心跳也充當兩者之間的消息通信,比如tasktracker會指明它是否已經做好準備來運行新的任務了,如果是,管理者jobtracker就會給執行者tasktracker分配一個任務。參見步驟7。
- 當然,在管理者jobtracker為執行者tasktracker選擇任務之前,jobtracker必須先選定任務所在的作業。一旦選擇好作業,jobtracker就可以給tasktracker選定一個任務。如何選擇一個作業呢?當然是Hadoop作業的調度器了,它就像是Hadoop的中樞神經系統一樣,默認的方法是簡單維護一個作業優先級列表。(對于調度算法的更深理解可以學習操作系統的作業調度算法,進程調度算法,比如先來先服務(FCFS)調度算法,短作業優先(SJF)調度算法,優先級調度算法,高響應比優先調度算法,時間片輪轉調度算法,多級反饋隊列調度算法等。如果從更高的角度來看調度算法,其實是一種控制和決策的策略選擇。)
- 作業選擇好了,任務也選擇好了,接下來要做的事情就是任務的運行了。首先,從HDFS中把作業的JAR文件復制到tasktracker所在的文件系統,同時,tasktracker將應用程序所需要的全部文件從分布式緩存復制到本地磁盤,也就是從HDFS文件系統復制到ext4等文件系統之中。參見步驟8。
- tasktracker為任務新建一個本地工作目錄,并把JAR文件中的內容解壓到這個文件夾中,新建一個TaskRunner實例來運行該任務。
- TaskRunner啟動一個新的JVM(參見步驟9)來運行每個任務(參見步驟10),以便用戶定義的map和reduce函數的任何缺陷都不會影響TaskTracker守護進程(比如導致它崩潰或者掛起)。需要說明一點的是,對于map和reduce任務,tasktracker有固定數量的任務槽,準確數量由tasktracker核的數量和內存大小來決定,比如一個tasktracker可能同時運行兩個map任務和reduce任務。map任務和reduce任務中關于數據本地化部分不再講解,因為DRCP沒有用到,只要理解本地數據級別就可以了,比如node-local,rack-local,off-switch。
- 子進程通過umbilical接口與父進程進行通信,任務的子進程每隔幾秒便告訴父進程它的進度,直到任務完成。
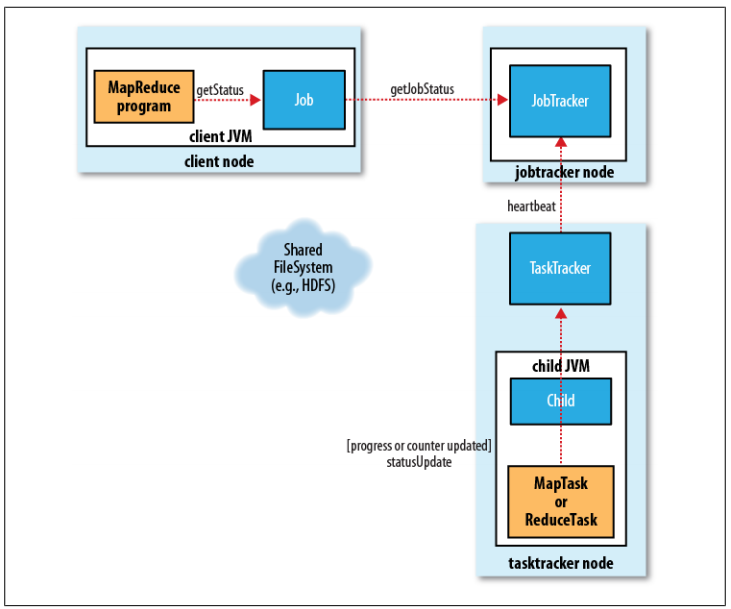
- MapReduce是Hadoop的一個離線計算框架,運行時間范圍從數秒到數小時,因此,對于我們而言直到作業進展是很重要的。
- 一個作業和每個任務都有一個狀態信息,包括作業或任務的運行狀態(比如,運行狀態,成功完成,失敗狀態)、Map和Reduce的進度、計數器值、狀態消息和描述(可以由用戶代碼來設置)等。
- 這些消息通過一定的時間間隔由Child JVM—>TaskTracker—>JobTracker匯聚。JobTracker將產生一個表明所有運行作業及其任務狀態的全局視圖。可以通過Web UI查看。同時JobClient通過每秒查詢JobTracker來獲得最新狀態,輸出到控制臺上。
- 現在可能會有一個疑問,這些狀態信息在作業執行期間不斷變化,它們是如何與客戶端進行通信的呢?詳細細節不在講解,參考資料《Hadoop權威指南》。
- 當jobtracker收到作業最后一個任務已完成的通知后,便把作業的狀態設置為”成功”。然后,在JobClient查詢狀態時,便知道作業已成功完成,于是JobClient打印一條消息告知用戶,最后從runJob()方法返回。
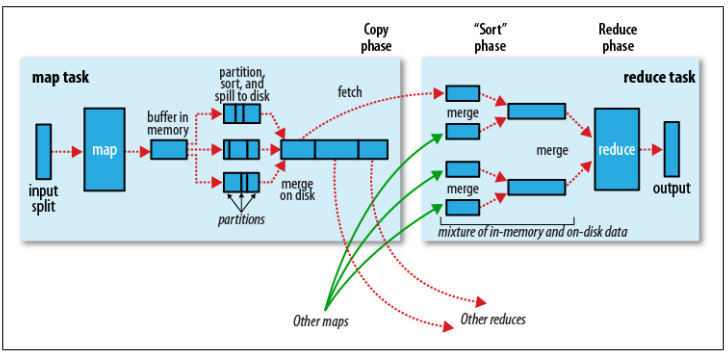
- 輸入分片: 在進行map計算之前,mapreduce會根據輸入文件計算輸入分片,每個輸入分片針對一個map任務,輸入分片存儲的并非數據本身,而是一個分片長度和一個記錄數據位置的數組,輸入分片往往和hdfs的block關系很密切。假如我們設定hdfs塊的大小是64MB,如果我們有三個輸入文件,大小分別是3MB、65MB和127MB,那么mapreduce會把3MB文件分為一個輸入分片,65MB則是兩個輸入分片,而127MB也是兩個輸入分片,就會有5個map任務將執行。
- map階段: 就是編寫好的map函數,而且一般map操作都是本地化操作,也就是在數據存儲節點上進行。
- combiner階段: combiner階段是可以選擇的,combiner本質也是一種reduce操作。Combiner是一個本地化的reduce操作,它是map運算的后續操作,主要是在map計算出中間文件后做一個簡單的合并重復key值的操作,比如,我們對文件里的單詞頻率做統計,如果map計算時候碰到一個hadoop單詞就會記錄為1,這篇文章里hadoop可能會出現多次,那么map輸出文件冗余就會很多,因此在reduce計算前對相同的key做一個合并操作,文件就會變小,這樣就提高了寬帶的傳輸效率。但是combiner操作是有風險的,使用它的原則是combiner的輸入不會影響到reduce計算的最終結果,比如:如果計算只是求總數,最大值,最小值可以使用combiner,但是如果做平均值計算使用combiner,那么最終的reduce計算結果就會出錯。
- shuffle階段: 將map的輸出作為reduce輸入的過程就是shuffle。一般mapreduce計算的都是海量數據,map輸出的時候不可能把所有文件都放到內存中進行操作,因此map寫入磁盤的過程十分的復雜,更何況map輸出的時候要對結果進行排序,內存開銷是很大的。map在做輸出的時候會在內存里開啟一個環形內存緩沖區,這個緩沖區是專門用來輸出的,默認大小是100MB,并且在配置文件里為這個緩沖區設定了一個閥值,默認是0.80(這個大小和閥值都是可以在配置文件里進行配置的),同時map還會為輸出操作啟動一個守護線程,如果緩沖區的內存達到了閥值的80%時候,這個守護線程就會把內容寫到磁盤上,這個過程叫spill。另外的20%內存可以繼續寫入要寫進磁盤的數據,寫出磁盤和寫入內存操作是互不干擾的,如果緩存區被填滿了,那么map就會阻塞寫入內存的操作,讓寫出磁盤操作完成后再繼續執行寫入內存操作。寫出磁盤前會有個排序操作,這個是在寫出磁盤操作的時候進行的,不是在寫入內存的時候進行的,如果還定義了combiner函數,那么排序后還會執行combiner操作。每次spill操作也就是寫出磁盤操作的時候就會寫一個溢出文件,即在做map輸出的時候有幾次spill操作就會產生多少個溢出文件。這個過程里還會有一個partitioner操作,其實partitioner操作和map階段的輸入分片很像,一個partitioner對應一個reduce作業,如果mapreduce操作只有一個reduce操作,那么partitioner就只有一個。如果有多個reduce操作,那么partitioner對應的就會有多個。因此,可以把partitioner看作reduce的輸入分片。到了reduce階段就是合并map輸出文件,partitioner會找到對應的map輸出文件,然后進行復制操作,復制操作時reduce會開啟幾個復制線程,這些線程默認個數是5個(也可以在配置文件中更改復制線程的個數),這個復制過程和map寫出磁盤的過程類似,也有閥值和內存大小,閥值一樣可以在配置文件里配置,而內存大小是直接使用reduce的tasktracker的內存大小,復制的時候reduce還會進行排序操作和合并文件操作,這些操作完畢之后就會進行reduce計算。
- reduce階段: 和map函數一樣,是編寫好的reduce函數,最終結果是存儲在hdfs上的。
參考文獻:
[1]?MapReduce編程模型的要點:?http://blog.sina.com.cn/s/blog_4a1f59bf0100tgqj.html
[2] Hadoop權威指南(第三版)
[3] Hadoop應用開發技術詳解
[4]?mapreduce中reducers個數設置:?http://www.2cto.com/os/201312/263998.html
[5]?操作系統典型調度算法:?http://see.xidian.edu.cn/cpp/html/2595.html
[6]?MapReduce框架結構:?http://www.cppblog.com/javenstudio/articles/43073.html
[7] MapReduce框架詳解:?http://www.cnblogs.com/sharpxiajun/p/3151395.html



...)



![c語言volatile_[技術]為什么單片機C語言編程時某一變量有時亂碼](http://pic.xiahunao.cn/c語言volatile_[技術]為什么單片機C語言編程時某一變量有時亂碼)





![32位數據源中沒有mysql_[SpringBoot實戰]快速配置多數據源(整合MyBatis)](http://pic.xiahunao.cn/32位數據源中沒有mysql_[SpringBoot實戰]快速配置多數據源(整合MyBatis))





