最后一次NOIP模擬了·····
題目1:回文數字
Tom?最近在研究回文數字。
假設?s[i]?是長度為?i?的回文數個數(不含前導0),則對于給定的正整數?n?有:
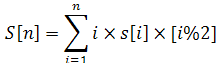
以上等式中最后面的括號是布爾表達式,Tom?想知道S[n]?mod?233333?的值是多少。
輸入格式
第一行一個正整數?T?。
接下來輸出共?T?行,每行一個正整數?n?。
輸出格式
輸出共?T?行,每行一個整數,表示?S[n]?mod?233333?。
樣例數據 1
輸入 [復制]
1?
2
輸出
9
備注
【數據規模與約定】
對于?30%?的數據:n≤5。
對于另?20%?的數據:∑n≤10^7。
對于另?20%?的數據:T=1。
對于?100%?的數據:T≤5*10^5;n≤10^9。
根據題意可以推出來就是一個差比數列·····用快速冪和逆元(中間有除法)求解即可
然而考試的時候作死cout<<endl直接超時····下次輸出換行一定要用cout<<"\n“·····
#include<iostream> #include<cstdio> #include<cstdlib> #include<cmath> #include<ctime> #include<cctype> #include<cstring> #include<string> #include<algorithm> using namespace std; const long long mod=233333; const long long niyuan=25926; long long a,T; inline long long R(){char c;long long f=0;for(c=getchar();c<'0'||c>'9';c=getchar());for(;c<='9'&&c>='0';c=getchar()) f=(f<<3)+(f<<1)+c-'0';return f; } inline long long ksm(long long a,long long b){long long ans=1;a%=mod;while(b){if(b&1) ans=ans*a%mod;b/=2;a=a*a%mod;}return ans; } int main(){//freopen("bug.in","r",stdin);//freopen("bug.out","w",stdout);T=R();while(T--){a=R();if(a==1||a==2) cout<<"9"<<endl;else{a=(a-1)/2; long long b=ksm(10,a+1);long long c=b;b=b*((2*a%mod+1)%mod)%mod;c=(c-10)*niyuan%mod*2%mod;b=((b-1-c)%mod+mod)%mod;cout<<b<<"\n";}}return 0; }
?
題目2:路徑統計
一個?n?個點?m?條邊的無重邊無自環的無向圖,點有點權,邊有邊權,定義一條路徑的權值為路徑經過的點權的最大值乘邊權最大值。
求任意兩點間的權值最小的路徑的權值。
輸入格式
第一行兩個整數?n?,m?,分別表示無向圖的點數和邊數。
第二行?n?個正整數,第?i?個正整數表示點i的點權。
接下來?m?行每行三個正整數?ui,vi,wi?,分別描述一條邊的兩個端點和邊權。
輸出格式
輸出?n?行,每行?n?個整數。
第?i?行第?j?個整數表示從?i?到?j?的路徑的最小權值;如果從?i?不能到達?j?,則該值為?-1?。特別地,當?i=j?時輸出?0?。
樣例數據 1
輸入 [復制]
3 3?
2 3 3?
1 2 2?
2 3 3?
1 3 1
輸出
0 6 3?
6 0 6?
3 6 0
備注
【樣例輸入輸出2】
??? 見選手目錄下path.in/path.ans。
【數據范圍與約定】
對于?20%?的數據:n≤5;m≤8。
對于?50%?的數據:n≤50。
對于?100%?的數據:n≤500;m≤n*(n-1)/2,邊權和點權不超過10^9?。
考慮直接用floyd的話會出現錯誤···比如說我們用k1更新f[i][j]后,下次用k2更新f[i][j]時可能會出錯····
方法是我們將每個點的點權從小到大排序··在枚舉最外層的中轉點時我們按升序枚舉···這樣就能保證正確性,具體怎么證明這里就不多寫了···
注意能開int的地方就開int··不然要超時
#include<iostream> #include<cstdio> #include<cstdlib> #include<string> #include<cstring> #include<algorithm> #include<cmath> #include<ctime> #include<cctype> using namespace std; const int N=505; struct node{int val,id; }p[N]; int n,m,mp[N][N],val[N],me[N][N]; long long dis[N][N]; bool Visit[N],jud[N][N]; inline int R(){char c;int f=0;for(c=getchar();c<'0'||c>'9';c=getchar());for(;c<='9'&&c>='0';c=getchar()) f=(f<<3)+(f<<1)+c-'0';return f; } inline long long Rl(){char c;long long f=0;for(c=getchar();c<'0'||c>'9';c=getchar());for(;c<='9'&&c>='0';c=getchar()) f=(f<<3)+(f<<1)+c-'0';return f; } int buf[1024]; inline void write(long long x){if(!x){putchar('0');return ;}if(x<0){putchar('-');x=-x;}while(x){buf[++buf[0]]=x%10,x/=10;}while(buf[0]) putchar(buf[buf[0]--]+48);return ; } inline bool cmp(const node &a,const node &b){return a.val<b.val; } int main(){//freopen("path.in","r",stdin);///freopen("path1.out","w",stdout);n=R();m=R();int a,b;long long c;memset(jud,false,sizeof(jud));for(int i=1;i<=n;i++)for(int j=1;j<=n;j++) mp[i][j]=me[i][j]=1e+9,dis[i][j]=2e+18;for(int i=1;i<=n;i++) val[i]=R(),p[i].val=val[i],p[i].id=i;sort(p+1,p+1+n,cmp);for(int i=1;i<=m;i++){a=R(),b=R(),c=R();me[a][b]=me[b][a]=c;mp[a][b]=mp[b][a]=max(val[a],val[b]);jud[a][b]=jud[b][a]=true;dis[a][b]=dis[b][a]=(long long)mp[b][a]*me[b][a];}for(int K=1;K<=n;K++)for(int i=1;i<=n;i++)for(int j=1;j<=n;j++){int k=p[K].id;if(!jud[i][k]||!jud[k][j]||i==j) continue;int maxp=max(mp[i][k],mp[k][j]); int maxe=max(me[i][k],me[k][j]);if((long long)maxp*maxe<dis[i][j]){dis[i][j]=(long long)maxp*maxe;mp[i][j]=maxp;me[i][j]=maxe;jud[i][j]=true;}}for(int i=1;i<=n;i++){for(int j=1;j<=n;j++){if(i==j) write(0),putchar(' ');else if(jud[i][j]) write(dis[i][j]),putchar(' ');else write(-1),putchar(' ');}putchar('\n');}return 0;}
?
題目3:字符串
給定兩個字符串?s1?和?s2?,兩個字符串都由?26?個小寫字母中的部分字母構成。現在需要統計?s2?在?s1?中出現了的次數。
對于?s1?中的每個位置?i?,設?strlen(s2)=m?,若:
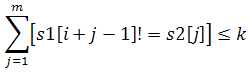
(最外層中括號為布爾表達式)
則認為?s2?在?s1?的?i?處出現了一次,現在想知道,s2?在?s1?中一共出現了多少次?
輸入格式
第一行為一個字符串?s1?;
第二行為一個字符串?s2?;
第三行為一個整數?k?。
輸出格式
輸出一行一個整數,表示?s2?在?s1?中出現的次數。
樣例數據 1
輸入 [復制]
ababbab?
aba?
1
輸出
3
備注
【數據范圍與約定】
前?10%?的數據:n>m。
前?30%?的數據:n,m≤1000。
對于另?40%?的數據:k≤20。
對于?100%?的數據:n≤200000;m≤100000;k≤100。
由于正解要用到后綴數組不屬于NOIP范圍··所以這里我就先挖個坑吧··只講講70分
暴力肯定是枚舉每一個起始位置暴力匹配···70分算法就是它的優化··每次匹配的時候我們用hash+二分來匹配即可
#include<iostream> #include<cstdio> #include<cstdlib> #include<cmath> #include<ctime> #include<cctype> #include<string> #include<cstring> #include<algorithm> using namespace std; const int N=2e5+5; const int base=61; int n,m,ans=0,k; unsigned long long bt[N],hash1[N],hash2[N]; char s1[N],s2[N]; inline void pre(){bt[0]=1;for(int i=1;i<=n;i++) bt[i]=bt[i-1]*base;for(int i=n;i>=1;i--) hash1[i]=hash1[i+1]*base+s1[i]-'a';for(int i=m;i>=1;i--) hash2[i]=hash2[i+1]*base+s2[i]-'a'; } inline int getans(int st){int cnt=0,po=1;while(cnt<=k&&po<=m){int le=0,ri=m-po;while(le<=ri){int mid=(ri+le)/2;if((hash2[po]-hash2[po+mid+1]*bt[mid+1])==(hash1[st+po-1]-hash1[st+po+mid]*bt[mid+1])) le=mid+1;else ri=mid-1;}if(po+ri!=m) cnt++;po=po+ri+2;}if(cnt<=k) return 1;else return 0; } int main(){//freopen("a.in","r",stdin);scanf("%s%s",s1+1,s2+1);scanf("%d",&k);n=strlen(s1+1);m=strlen(s2+1);pre();for(int i=1;i<=n-m+1;i++) ans+=getans(i);cout<<ans<<"\n";return 0; }
?
?





)


![[ JavaScript ] JavaScript 實現繼承.](http://pic.xiahunao.cn/[ JavaScript ] JavaScript 實現繼承.)










