一、視圖
本質上相當于一張**“虛擬表”**,可當作獨立的一張表進行操作(增、刪、改、查)
**????? 作用:**
**?????? a)**可通過權限控制,只將“表中的少數列”暴露給數據庫用戶,而不讓該用戶直接操縱數據庫中“實際表”
**?????? b)**可將常用的,較復雜的SQL在數據庫中預先定義好,使得外部調用不用每次都編寫復雜的SQL語句,直
接當作一張“虛擬表”來調用即可 等等,聽說你們都很喜歡我~那給個小心心00~,為了表揚你們,戳這里有你們想要的完整zl
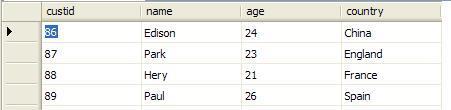
Customers表中原始數據:
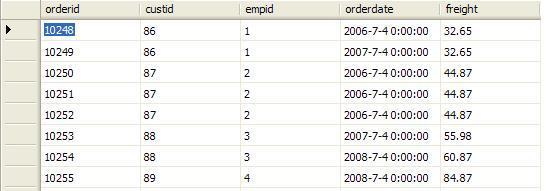
Orders表中的原始數據:
創建“查找運費在40到60之間的客戶信息”的視圖:
1 use edisondb; 2
3 ?if object_id('FortyToSixtyFreightCusts')is not null
4 drop view FortyToSixtyFreightCusts
5 ?go
6 ?create view FortyToSixtyFreightCusts
7 ?as
8
9 ?select C.custid as '客戶ID',C.name as '客戶名', C.age as '年齡'
10 from customers as C
11 ?where Exists(
12 select *
13 from Orders as O
14 where C.custid=O.custid and (O.freight between 40 and 60)
15 );
創建成功之后:

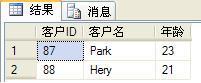
將該視圖當作一張“獨立的表”進行查詢操作:
1 use edisondb; 2 ?select 客戶ID,客戶名,年齡 from FortyToSixtyFreightCusts;
執行結果如下:
關于SCHEMABINDING選項的一些說明:
**???????? 作用:用“富”字組詞使得視圖中引用的對象不能被刪除,被引用的列不能被刪除或者修改(防止:由于引用的列等被刪除,造成視圖無法使用的情況)**
修改視圖,使其指定SCHEMABINDING選項:
1 alter view FortyToSixtyFreightCusts with schemabinding
2 ?as
3
4 ?select C.custid as '客戶ID',C.name as '客戶名', C.age as '年齡'
5 ?from dbo.customers as C
6 ?where Exists(
7 select O.custid
8 from dbo.Orders as O
9 where C.custid=O.custid and (O.freight between 40 and 60)
10 );
11
go
(以上表名,一定要以“dbo.”的形式出現,否則會出現:名稱 'customers' 對于架構綁定無效的錯誤)*
嘗試刪除Customers表中的age列:
1 use edisondb; 2 alter table customers drop column age;
執行結果:
**

**
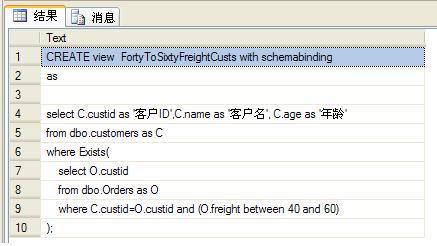
**? ? 附:可通過執行以下語句查看SQL Server中某對象的定義: ?????**
1 exec sp_helptext 'dbo.FortyToSixtyFreightCusts';
執行結果如下:
二、約束
**?? 1)檢查約束【通常認為的“約束”】**
創建檢查約束:
1 use edisondb; 2 ?alter table staffinfo 3 ?add constraint ck_StaffID check(StaffID between 5000 and 5999)
成功創建之后:
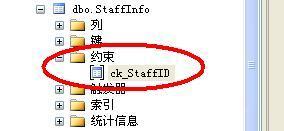
此時執行非法的插入行:
1 use edisondb; 2 ?insert into StaffInfo(StaffID,StaffName,Department) 3 values(6000,'Wade','Dev');
執行結果為:

**?? 2)唯一性約束**
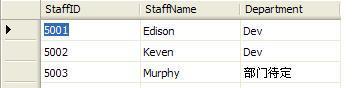
StaffInfo表原始數據:
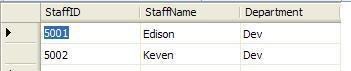
創建唯一性約束:
1 use edisondb; 2 ?alter table staffinfo 3 ?add constraint uq_StaffName unique(StaffName);
成功創建后:
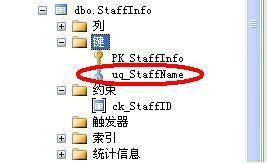
**?注:**唯一性約束創建成功后,是在“鍵”中顯示,而非“約束”中
此時執行非法的插入行:
1 use edisondb; 2 ?insert into StaffInfo(StaffID,StaffName,Department) 3 values(5003,'keven','Dev');
執行結果為:

**說明:**要使某列的值唯一,既可以通過主鍵來實現,也可以通過“唯一性約束”來實現
3)默認約束
創建默認約束:
1 use edisondb; 2 ?alter table staffinfo 3 ?add constraint df_Department default('部門待定') for Department;
成功創建后:
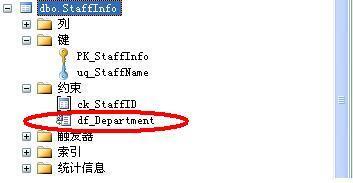
執行行插入:
1 use edisondb; 2 ?insert into StaffInfo(StaffID,StaffName) 3 values(5003,'Murphy');
執行結果為:
**注:**主鍵和外鍵也屬于一種約束
三、索引
**? 1.聚集索引**
對應于數據庫中數據文件的物理存儲方式,每張表只能建立一個
**? ?? ? 適用場合:**a)select次數遠大于insert、update的次數(insert、update時需要移動其他數據文件的物理位置) ?????????????? ? ? ?? b)建立聚合索引的列,既不能絕大多數都相同,又不能只有極少數相同(可從類似二維數組查找時間復雜的方式去理解)
創建一個NewOrders表,用于對索引的測試:
1 use edisondb; 2 3 create table NewOrders 4 ( orderID numeric(18, 0) identity(1,1) not null, 5 custID numeric(18, 0) not null, 6 empID numeric(18, 0) not null, 7 tradeDate datetime not null 8 );
在NewOrders表中插入10萬條測試數據:
1 use edisondb;
2 set nocount on
3 declare @i numeric(18,0)
4 declare @custid numeric(18,0)
5 declare @empid numeric(18,0)
6 declare @tradeDateTime datetime
7 begin
8 set @i=0
9 set @custid=100000
10 set @empid=500000
11 set @tradeDateTime=getdate()
12 while @i<100000
13 begin
14 insert into neworders(custID,empID,tradeDate)
15 values(@custid,@empid,@tradeDateTime)
16 set @i=@i+1
17 set @custid=@custid+1
18 set @empid=@empid+1
19 if (@i%1000)=0
20 set @tradeDateTime=dateadd(day,1,@tradeDateTime)
21 end
22 end
23 print 'Insert data over'
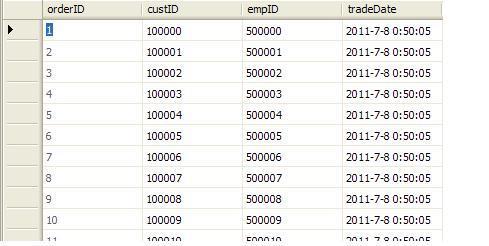
插入數據成功之后,NewOrders表中的部分數據如下:
進行查詢測試:
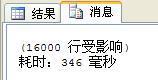
1 use edisondb; 2 declare @startDT datetime 3 set @startDT=getdate() 4 select * from neworders where tradedate> dateadd(day,10,'2011-9-20') 5 print '耗時:'+replace(str(datediff(ms,@startDT,getdate())),' ','')+' 毫秒'
執行結果為:
現在對建立“聚集索引”的表進行測試
刪除表中所有行:
1use edisondb 2truncate table neworders;
在用“桿”字組詞NewOrders表的tradeDate列上創建“聚集索引”:
1use edisondb 2create clustered index tradeDate_NewOrders on NewOrders(tradeDate)
執行結果為:

再次插入10萬行數據后,進行測試,結果為:
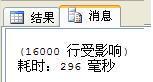
**聚合索引使用的關鍵:**在合適的列建立(通常為:最多用作查詢條件的列)


)


![[ JavaScript ] JavaScript 實現繼承.](http://pic.xiahunao.cn/[ JavaScript ] JavaScript 實現繼承.)













