LinkedHashSet是Set集合的一個實現,具有set集合不重復的特點,同時具有可預測的迭代順序,也就是我們插入的順序。
并且linkedHashSet是一個非線程安全的集合。如果有多個線程同時訪問當前linkedhashset集合容器,并且有一個線程對當前容器中的元素做了修改,那么必須要在外部實現同步保證數據的冥等性。
下面我們new一個新的LinkedHashSet容器看一下具體的源碼實現。并分析師如何保證數據的插入順序:
Set set = new LinkedHashSet<>();
跟進LinkedHashSet可以得到super一個父類初始化為一個容器為16大小,加載因子為0.75的Map容器。
構造一個空連接散列集合
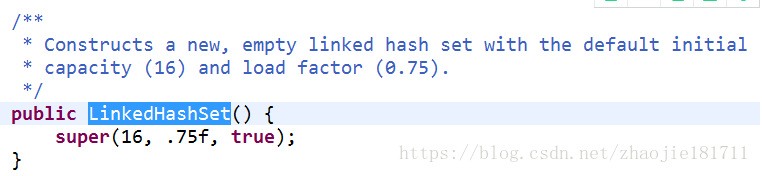

實際創建的是一個LinkedHashMap帶有制定大小和加載因子的容器。
在前面講過一次,map的容器的大小必須是2的冥,那么在講一次如何保證必須是2的冥,通過我們傳入的參數在構建map集合的是通過位運算實現:
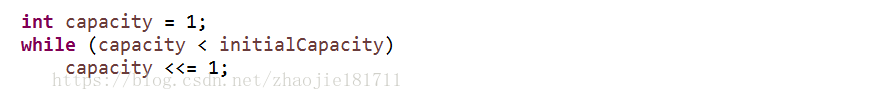
其中initialCapacity為我們傳入的具體按容器的大小。
上面是我們描述的LinkedHashSet的具體構建過程,以及構建的具體內容。
由于LinkedHashSet是一個哈希表和鏈表的結合,且是一個雙向鏈表,那么我們來看一下什么是雙向連邊?
雙向鏈表是鏈表的一種,他的每個數據節點都有兩個指針分別指向直接后繼和直接前驅,所以從雙向鏈表的任意一個節點開始都可以很方便的訪問它的前驅節點和后繼節點。這是雙向鏈表的優點,那么有優點就有缺點,缺點是每個節點都需要保存當前節點的next和prev兩個屬性,這樣才能保證優點。所以需要更多的內存開銷,并且刪除和添加也會比較費時間。
下面我們圖示一個雙向兩表的節點:

多個節點相互連接,保證了數據錄入的順序。
那么我們源碼分析一下具體的錄入詳情:
我們定義一個LinkedHashSet---LinkedHashSet set = new LinkedHashSet<>();
然后set.add();跟一下這個add是走的那個方法:
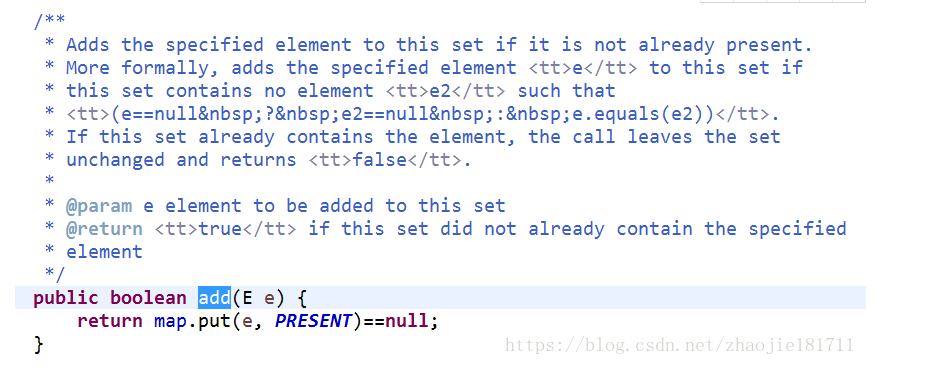
跟進來走的是put的方法:LinkedHashSet.class下的,這個是重寫了超類中put的具體add方法。他會在新分配的元素在鏈表的末尾插入一條。
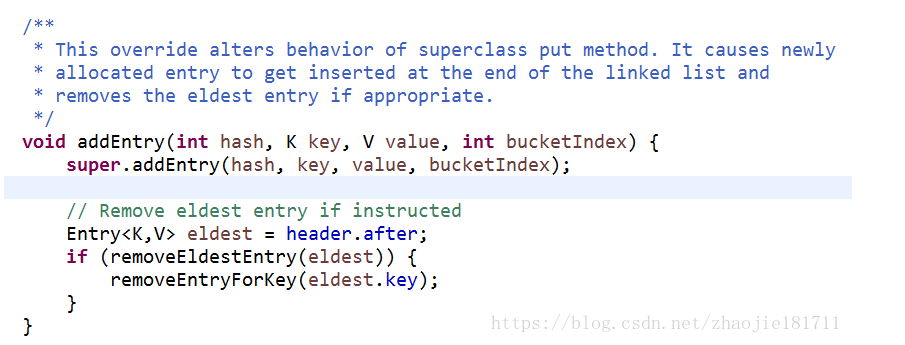

進來走的還是HashMap的put添加方法,在上面的判斷和計算hash確定位置之后,由于LinkedHashSet重寫了addEntry

在元素的后面添加新的元素。
整個過程就是LinkedHashSet在容器插入數據的過程。此過程主要由LinkedHashSet.class中重寫超類的兩個addEntry和createEntry 實現雙向鏈表的結構。保證數據已我們錄入的順序遍歷輸出。
————————————————
版權聲明:本文為CSDN博主「X-TIE」的原創文章,遵循 CC 4.0 BY-SA 版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/zhaojie181711/article/details/80510129



用Socket實現跨進程聊天程序)
![ArcGIS 網絡分析[4] 網絡數據集深入淺出之連通性、網絡數據集的屬性及轉彎要素...](http://pic.xiahunao.cn/ArcGIS 網絡分析[4] 網絡數據集深入淺出之連通性、網絡數據集的屬性及轉彎要素...)




![[BZOJ2064]分裂](http://pic.xiahunao.cn/[BZOJ2064]分裂)




![[樹形DP]沒有上司的舞會](http://pic.xiahunao.cn/[樹形DP]沒有上司的舞會)


)

