文章目錄
- 摘要
- Introduction
- Revisiting Video Object Detection Baseline
- Practice for Mobiles
- Model Architecture for Mobiles
- Light Flow
摘要
盡管在桌面GPU上取得了視頻目標檢測的最近成功,但其架構對于移動設備來說仍然過于沉重。目前尚不清楚在非常有限的計算資源下,稀疏特征傳播和多幀特征聚合的關鍵原則是否適用。在本文中,我們提出了一種適用于移動設備的輕量級視頻目標檢測網絡架構。我們在稀疏關鍵幀上應用了輕量級圖像目標檢測器。設計了一個非常小的網絡,名為Light Flow,用于在幀之間建立對應關系。我們還設計了一個流引導的GRU模塊,以有效地聚合關鍵幀上的特征。
對于非關鍵幀,進行了稀疏特征傳播。整個網絡可以端到端地進行訓練。所提出的系統在移動設備上(例如華為Mate 8)以25.6 fps的速度在ImageNet VID驗證集上實現了60.2%的mAP分數。
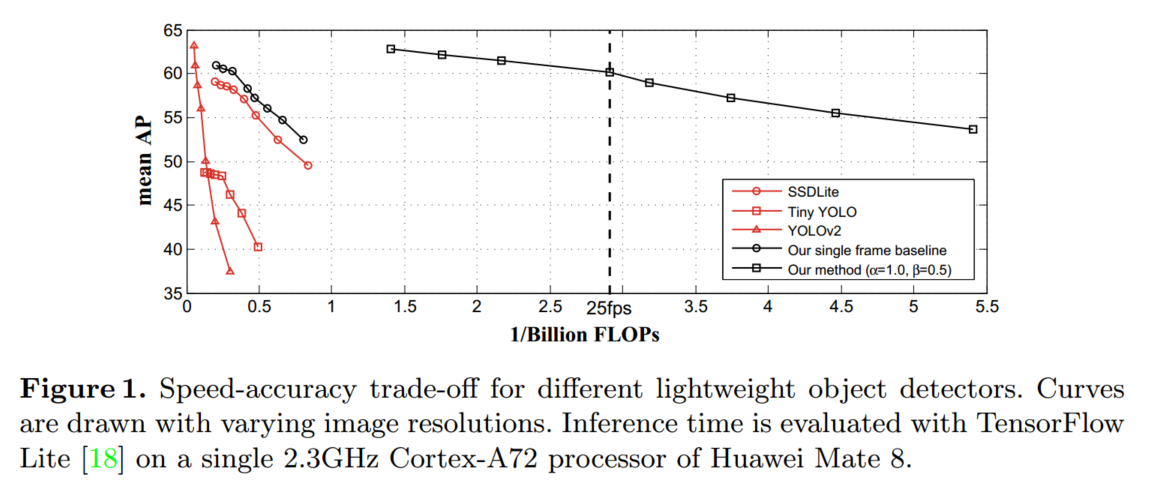
Introduction
近年來,利用深度神經網絡進行目標檢測取得了顯著的進展[1]。一般趨勢是構建更深、更復雜的目標檢測網絡[2,3,4,5,6,7,8,9,10,11],以達到更高的準確性。然而,這些提高準確性的進展未必能使網絡在尺寸和速度方面更加高效。在許多實際應用中,如機器人、自動駕駛汽車、增強現實和移動手機等,目標檢測任務需要在計算資源有限的平臺上實時執行。
最近,越來越多的人開始關注構建非常小、低延遲的模型,以便輕松適應移動和嵌入式視覺應用的設計要求,例如SqueezeNet [12]、MobileNet [13] 和ShuffleNet [14]。這些結構是通用的,但并非專門為目標檢測任務設計。為此,已經探索了一些適用于靜態圖像目標檢測的小型深度神經網絡架構,如YOLO [15]、YOLOv2 [11]、Tiny YOLO [16] 和Tiny SSD [17]。然而,直接將這些檢測器應用于視頻面臨新的挑戰。首先,在所有視頻幀上應用深度網絡會帶來無法承受的計算成本。其次,識別準確度會受到視頻中很少在靜止圖像中觀察到的惡化外觀的影響,如運動模糊、視頻散焦、罕見的姿勢等。
為了解決這些問題,當前的最佳實踐[19,20,21]利用了時間信息來加速和提高視頻的檢測準確性。一方面,在[19,21]中使用稀疏特征傳播來節省大部分幀上昂貴的特征計算。在這些幀上的特征從稀疏的關鍵幀傳播而來。另一方面,在[20,21]中進行了多幀特征聚合,以提高特征質量和檢測準確性。
基于這兩個原則,最新的工作[21]在桌面GPU上實現了很好的速度-準確性權衡。然而,該架構對于移動設備來說并不友好。例如,作為特征傳播和聚合的關鍵和共同組成部分,流估計在移動設備上的實時計算需求仍然遠遠不夠。具有長期依賴性的聚合也受到移動設備有限運行時內存的限制。
本文描述了一種適用于移動設備的輕量級視頻目標檢測網絡架構。它主要基于兩個原則——在大多數非關鍵幀上傳播特征,同時在稀疏的關鍵幀上計算和聚合特征。然而,我們需要仔細重新設計這兩個結構,以考慮速度、尺寸和準確性。在所有幀上,我們提出了Light Flow,一個非常小的深度神經網絡,用于估計特征流,可在移動設備上立即使用。在稀疏關鍵幀上,我們提出了基于流引導的門控循環單元(GRU)特征聚合,這是在內存有限的平臺上的有效聚合。此外,我們還利用了輕量級圖像目標檢測器來在關鍵幀上計算特征,其中使用了先進而高效的技術,如深度可分離卷積 [22] 和Light-Head R-CNN [23]。
所提出的技術統一為一個端到端的學習系統。全面的實驗表明,該模型穩步推進了性能(速度-準確性權衡)的界限,朝著在移動設備上實現高性能的視頻目標檢測前進。例如,我們在移動設備上(例如華為Mate 8)以25.6幀每秒的速度,在ImageNet VID驗證集上實現了60.2%的mAP分數。它比先前在快速目標檢測方面的最佳努力速度快一個數量級,并且準確性相當(見圖1)。據我們所知,我們首次在移動設備上實現了具有合理準確性的實時視頻目標檢測。
Revisiting Video Object Detection Baseline
在靜態圖像中的目標檢測在近年來利用深度卷積神經網絡(CNN)取得了顯著的進展[1]。最先進的檢測器共享相似的網絡架構,包括兩個概念步驟。第一個步驟是特征網絡,它通過一個完全卷積的主干網絡[24,25,26,27,28,29,30,13,14]從輸入圖像I中提取一組卷積特征圖F,表示為Nf eat(I) = F。第二個步驟是檢測網絡,它通過在特征圖F上執行區域分類和邊界框回歸,使用多分支子網絡生成檢測結果y,可以是針對稀疏物體提案[2,3,4,5,6,7,8,9]或密集滑動窗口[10,15,11,31],即Ndet(F) = y。
它是隨機初始化并與Nf eat一起進行訓練。
將這些檢測器直接應用于視頻目標檢測面臨兩個方面的挑戰。就速度而言,將單一圖像檢測器應用于所有視頻幀并不高效,因為主干網絡Nf eat通常較深且較慢。
就準確性而言,檢測準確性會受到視頻中很少在靜態圖像中觀察到的惡化外觀的影響,如運動模糊、視頻散焦、罕見的姿勢。
目前的最佳實踐[19,20,21]通過稀疏特征傳播和多幀特征聚合分別利用時間信息來解決速度和準確性問題。
稀疏特征傳播 由于連續幀之間的內容之間存在很強的關聯性,不必在大多數幀上進行詳盡的特征提取計算。深度特征流[19]提供了一種高效的方法,它僅在稀疏的關鍵幀(例如每10幀)上計算昂貴的特征網絡,并將關鍵幀特征圖傳播到大多數非關鍵幀,從而實現了5倍的速度提升,但準確性略微降低。
在推斷過程中,任何非關鍵幀i上的特征圖都是通過從其前面的關鍵幀k傳播而來的,即:

多幀特征聚合 為了提高檢測準確性,流導引特征聚合(FGFA)[20]從附近的幀中聚合特征圖,這些特征圖通過估計的光流進行了很好的對齊。
在幀i上的聚合特征圖 ?Fi 是通過加權平均附近幀的特征圖得到的,其表達式為:
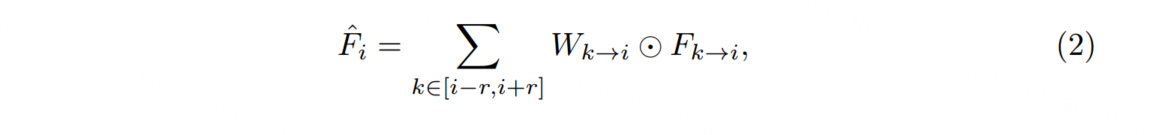

為了避免在所有幀上進行密集的聚合,[21] 提出了稀疏遞歸特征聚合,僅在稀疏的關鍵幀上操作。這種方法保留了聚合的特征質量,同時降低了計算成本。
具體而言,在連續的兩個關鍵幀 k 和 k0 上,幀 k0 上的聚合特征被計算為:
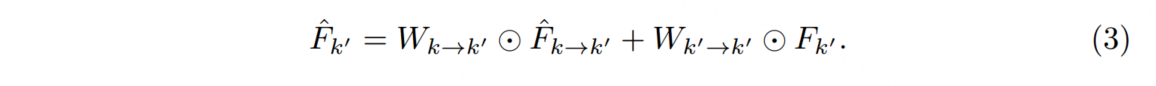
Practice for Mobiles
由于稀疏特征傳播和多幀特征聚合這兩個原則在桌面GPU上產生了最佳實踐,以實現高性能(速度和準確性的權衡)的視頻目標檢測[21]。然而,在移動設備上的計算能力和運行時內存非常有限,因此需要探索適用于移動設備的原則。
- 特征提取和聚合僅在稀疏的關鍵幀上操作,而在大多數非關鍵幀上執行輕量級特征傳播。
- 流估計是特征傳播和聚合的關鍵。然而,在[19、20、21]中使用的流網絡Nf low在移動實時處理方面仍然遠遠不夠。具體而言,FlowNet [32] 在相同的輸入分辨率下是MobileNet [13] 的11.8倍FLOPs。即使在[19]中使用的最小的FlowNet Inception也多了1.6倍的FLOPs。因此,需要更加輕量級的Nf low。
- 特征聚合應該在根據光流對齊的特征圖上進行操作。否則,由于大目標運動引起的位移會導致聚合嚴重錯誤。聚合中的長期依賴也是受歡迎的,因為可以融合更多的時間信息以獲得更好的特征質量。
- 單張圖像檢測器的主干網絡應盡可能小,因為我們需要它來計算稀疏關鍵幀上的特征。
Model Architecture for Mobiles
基于上述原則,我們設計了一個更小的移動視頻目標檢測網絡架構。推理管道如圖2所示。
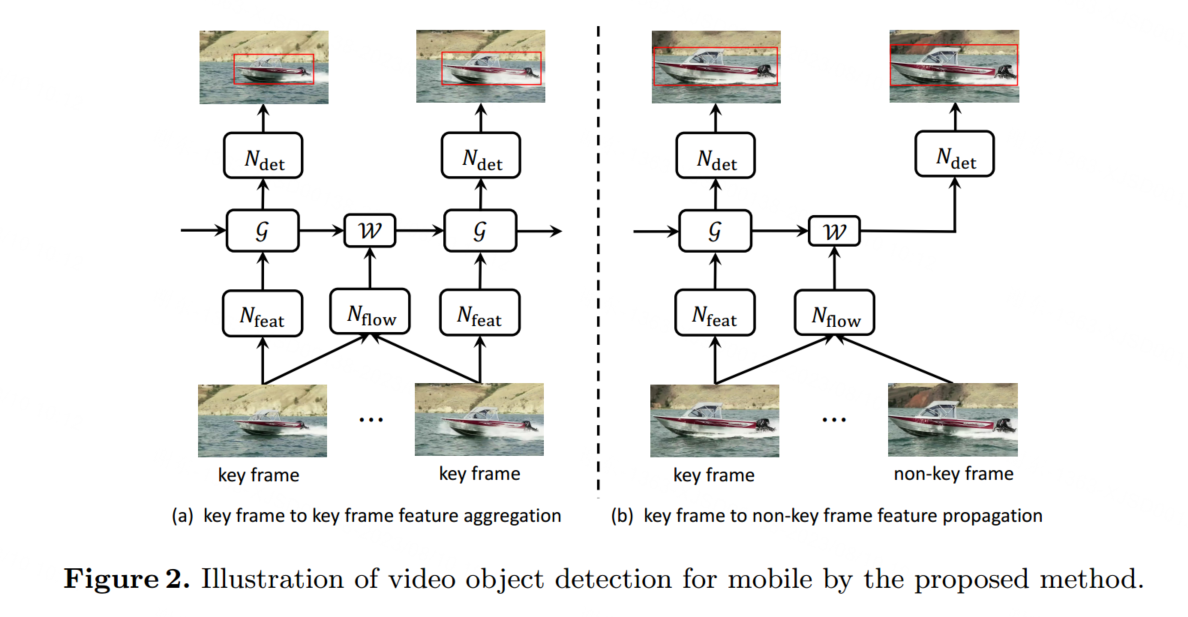


接下來,我們將介紹兩種專門為移動設備設計的新技術,包括Light Flow,一種更有效的移動設備流量網絡,以及一種基于流導向GRU的特征聚合,用于更好地建模長期依賴關系,從而獲得更好的質量和準確性。
Light Flow
FlowNet [32]最初是為像素級光流估計而提出的。它設計為編碼-解碼模式,后面是多分辨率光流預測器。兩個輸入的RGB幀被連接在一起形成一個6通道的輸入。在編碼器中,通過一系列卷積層,輸入被轉換成在空間維度上縮小到輸入大小的1/64的特征圖束。在解碼器中,特征圖被饋送到多個反卷積層,以實現高分辨率的光流預測。在每個反卷積層之后,特征圖與編碼器中的最后特征圖連接在一起,它們具有相同的空間分辨率和上采樣的粗糙光流預測。每個解碼器中連接的特征圖后面跟隨多個光流預測器。對每個預測器應用損失函數,但在推斷過程中僅使用最精細的預測。
為了極大地加速流網絡Nf low,我們提出了Light Flow,它是一個基于FlowNet [32]進行若干有意設計的輕量級流網絡。它在準確性方面只會帶來輕微的降低(端點誤差增加了15%),但在理論上速度提高了近65倍(見表2)。
在編碼器部分,卷積始終是計算的瓶頸。受MobileNet [13]的啟發,我們將所有的卷積替換為3×3的深度可分離卷積[22](每個3×3的深度可分離卷積后面跟著一個1×1的點卷積)。與標準的3×3卷積相比,3×3深度可分離卷積的計算成本減少了8~9倍,而準確性略有降低[13]。
在解碼器部分,每個反卷積操作都被最近鄰上采樣和隨后的深度可分離卷積所取代。[33]用最近鄰上采樣代替了反卷積,然后是標準卷積,以解決反卷積引起的棋盤狀偽影。相比之下,我們借鑒了這個想法,進一步將標準卷積替換為深度可分離卷積,以減少計算成本。
最后,我們采用了一種簡單有效的方式來考慮多分辨率的預測。這受到了FCN [34]的啟發,FCN在明確的求和方式下融合了多分辨率的語義分割預測作為最終預測。
與[32]不同,我們在推斷過程中不僅使用最精細的光流預測作為最終預測。相反,多分辨率的預測被上采樣到與最精細預測相同的空間分辨率,然后求平均作為最終預測。此外,在訓練期間,僅對平均光流預測應用單個損失函數,而不是在每個預測之后應用多個損失函數。這種方法可以將端點誤差減少近10%。
Light Flow的網絡架構和實現在表1中進行了說明。每個卷積操作之后都跟隨批量歸一化[35]和Leaky ReLU非線性變換[36],斜率固定為0.1。與[32,37]類似,Light Flow在Flying Chairs數據集上進行了預訓練。在訓練Light Flow時,使用Adam [38]作為優化方法,權重衰減為0.00004。在4個GPU上進行了70k次迭代,每個GPU持有64個圖像對。
采用了熱身學習率策略,首先訓練學習率為0.001的模型進行10k次迭代。然后使用學習率為0.01進行20k次迭代,并在每10k次迭代后將學習率除以2。
在將Light Flow應用于我們的方法時,為了進一步提速,進行了兩個修改。首先,與[19,20,21]一樣,Light Flow應用于輸入分辨率為特征網絡的一半,并且輸出步幅為4的圖像。由于特征網絡的輸出步幅為16,流場被下采樣以匹配特征圖的分辨率。其次,由于Light Flow非常小,計算量與檢測網絡Ndet相當,因此在檢測網絡的中間特征圖上應用稀疏特征傳播(參見第3.3節,RPN [5]中的256維特征圖和Light-Head R-CNN [23]中的490維特征圖),以進一步減少非關鍵幀的計算量。
后面略








)




![[C++ 網絡協議編程] TCP/IP協議](http://pic.xiahunao.cn/[C++ 網絡協議編程] TCP/IP協議)


)


