基于WIN10的64位系統演示
一、寫在前面
由于不少模型使用的是Pytorch,因此這一期補上基于Pytorch實現CNN可視化的教程和代碼,以SqueezeNet模型為例。
二、CNN可視化實戰
繼續使用胸片的數據集:肺結核病人和健康人的胸片的識別。其中,肺結核病人700張,健康人900張,分別存入單獨的文件夾中。
(a)SqueezeNet建模
######################################導入包###################################
# 導入必要的包
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as npwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 設置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################導入數據集#####################################
import torch
from torchvision import datasets, transforms
import os# 數據集路徑
data_dir = "./MTB"# 圖像的大小
img_height = 100
img_width = 100# 數據預處理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加載數據集
full_dataset = datasets.ImageFolder(data_dir)# 獲取數據集的大小
full_size = len(full_dataset)
train_size = int(0.7 * full_size) # 假設訓練集占80%
val_size = full_size - train_size # 驗證集的大小# 隨機分割數據集
torch.manual_seed(0) # 設置隨機種子以確保結果可重復
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 將數據增強應用到訓練集
train_dataset.dataset.transform = data_transforms['train']# 創建數據加載器
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=4)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes###############################定義ShuffleNet模型################################
# 定義SqueezeNet模型
model = models.squeezenet1_1(pretrained=True) # 這里以SqueezeNet 1.1版本為例
num_ftrs = model.classifier[1].in_channels# 根據分類任務修改最后一層
model.classifier[1] = nn.Conv2d(num_ftrs, len(class_names), kernel_size=(1,1))# 修改模型最后的輸出層為我們需要的類別數
model.num_classes = len(class_names)model = model.to(device)# 打印模型摘要
print(model)#############################編譯模型#########################################
# 定義損失函數
criterion = nn.CrossEntropyLoss()# 定義優化器
optimizer = optim.Adam(model.parameters())# 定義學習率調度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 開始訓練模型
num_epochs = 20# 初始化記錄器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每個epoch都有一個訓練和驗證階段for phase in ['train', 'val']:if phase == 'train':model.train() # 設置模型為訓練模式else:model.eval() # 設置模型為評估模式running_loss = 0.0running_corrects = 0# 遍歷數據for inputs, labels in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零參數梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在訓練模式下進行反向和優化if phase == 'train':loss.backward()optimizer.step()# 統計running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 記錄每個epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'squeezenet.pth')(b)可視化卷積神經網絡的中間輸出
import torch
from torchvision import models, transforms
import matplotlib.pyplot as plt
from torch import nn
from PIL import Image# 定義圖像的大小
img_height = 100
img_width = 100# 1. 加載模型
model = models.squeezenet1_1(pretrained=False)
num_ftrs = model.classifier[1].in_channels
num_classes = 2
model.classifier[1] = nn.Conv2d(num_ftrs, num_classes, kernel_size=(1,1))
model.num_classes = num_classes
model.load_state_dict(torch.load('squeezenet.pth'))
model.eval()
model = model.to('cuda' if torch.cuda.is_available() else 'cpu')# 2. 加載圖片并進行預處理
img = Image.open('./MTB/Tuberculosis/Tuberculosis-203.png')
transform = transforms.Compose([transforms.Resize((img_height, img_width)),transforms.Grayscale(num_output_channels=3), transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
img_tensor = transform(img).unsqueeze(0)
img_tensor = img_tensor.to('cuda' if torch.cuda.is_available() else 'cpu')# 3. 提取前N層的輸出
N = 25
activations = []
x = img_tensor
for i, layer in enumerate(model.features):x = layer(x)if i < N:activations.append(x)# 4. 將每個中間激活的所有通道可視化,但最多只顯示前9個通道
max_channels_to_show = 9
for i, activation in enumerate(activations):num_channels = min(max_channels_to_show, activation.shape[1])fig, axs = plt.subplots(1, num_channels, figsize=(num_channels*2, 2))for j in range(num_channels):axs[j].imshow(activation[0, j].detach().cpu().numpy(), cmap='viridis')axs[j].axis('off')plt.tight_layout()plt.show()# 清空當前圖像
plt.clf()結果輸出如下:

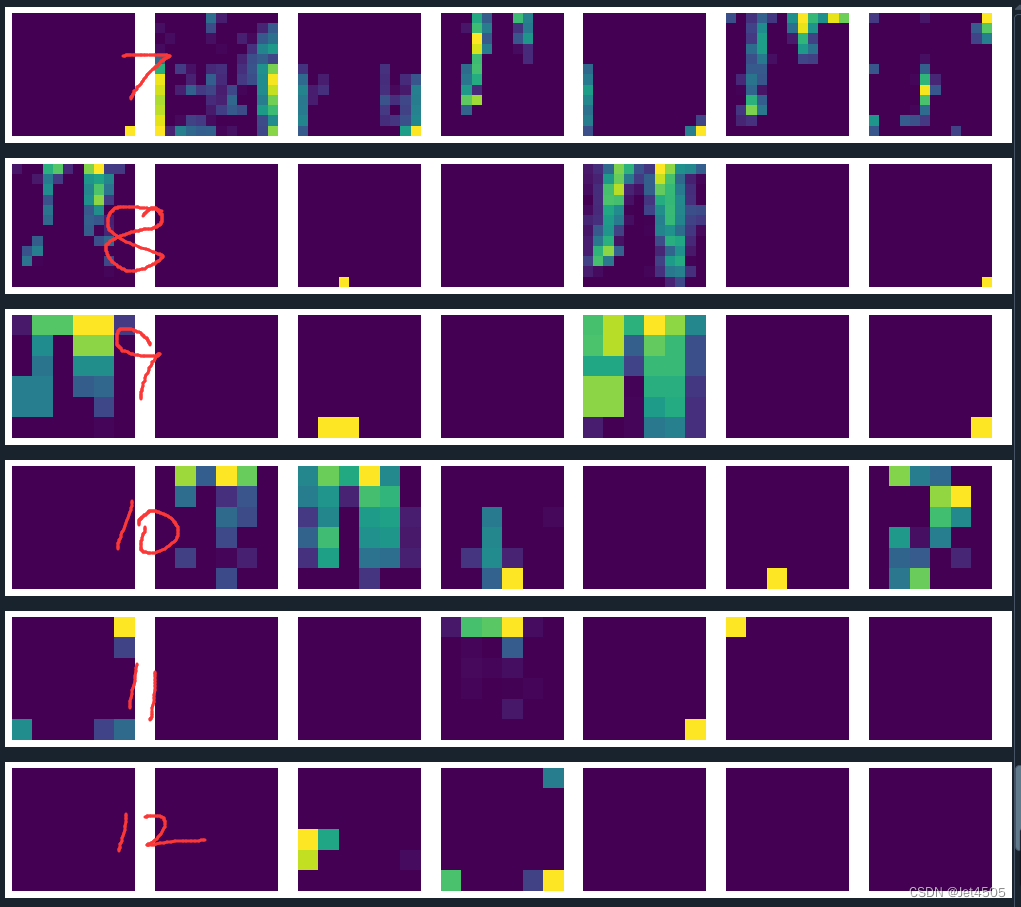

?由于SqueezeNet只有13層,所以即使我們在代碼中要求輸出25層,那也只能輸出13層。從第一層到最后一層,可以看到逐漸抽象化。
(c)可視化過濾器
import matplotlib.pyplot as pltdef visualize_filters(model):# 獲取第一個卷積層的權重first_conv_layer = model.features[0]weights = first_conv_layer.weight.data.cpu().numpy()# 取絕對值以便于觀察所有權重weights = np.abs(weights)# 歸一化權重weights -= weights.min()weights /= weights.max()# 計算子圖網格大小num_filters = weights.shape[0]num_cols = 12num_rows = num_filters // num_colsif num_filters % num_cols != 0:num_rows += 1# 創建子圖fig, axs = plt.subplots(num_rows, num_cols, figsize=(num_cols*2, num_rows*2))# 繪制過濾器for filter_index, ax in enumerate(axs.flat):if filter_index < num_filters:ax.imshow(weights[filter_index].transpose(1, 2, 0))ax.axis('off')plt.tight_layout()plt.show()# 調用函數來顯示過濾器
visualize_filters(model)這個更加抽象:

(d)Grad-CAM繪制特征熱力圖
import torch
from torchvision import models, transforms
from torch.nn import functional as F
from torch.autograd import Variable
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.cm as cm# 模型路徑
model_path = 'squeezenet.pth'# 圖像路徑
image_path = './MTB/Tuberculosis/Tuberculosis-203.png'# 加載模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 創建一個SqueezeNet模型
model = models.squeezenet1_1(pretrained=False)# 修改最后一層為二分類
model.classifier[1] = torch.nn.Conv2d(512, 2, kernel_size=(1,1), stride=(1,1))# 這行代碼用于在模型全連接層輸出后添加一個softmax函數,使得模型輸出可以解釋為概率
model.num_classes = 2model = model.to(device)
model.load_state_dict(torch.load(model_path))
model.eval()class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.feature = Noneself.gradient = None# 定義鉤子self.hooks = self.target_layer.register_forward_hook(self.save_feature_map)self.hooks = self.target_layer.register_backward_hook(self.save_gradient)# 保存featuredef save_feature_map(self, module, input, output):self.feature = output# 保存梯度def save_gradient(self, module, grad_in, grad_out):self.gradient = grad_out[0]# 計算權重def compute_weight(self):return F.adaptive_avg_pool2d(self.gradient, 1)def remove_hooks(self):self.hooks.remove()def __call__(self, inputs, index=None):self.model.zero_grad()output = self.model(inputs)if index == None:index = np.argmax(output.cpu().data.numpy())target = output[0][index]target.backward()weight = self.compute_weight()cam = weight * self.featurecam = cam.cpu().data.numpy()cam = np.sum(cam, axis=1)cam = np.maximum(cam, 0)# 歸一化處理cam -= np.min(cam)cam /= np.max(cam)self.remove_hooks()return cam# 圖像處理
img = Image.open(image_path).convert("RGB")
img_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
img_tensor = img_transforms(img)
img_tensor = img_tensor.unsqueeze(0).to(device)# 獲取預測類別
outputs = model(img_tensor)
_, pred = torch.max(outputs, 1)
pred_class = pred.item()# 獲取最后一個卷積層
target_layer = model.features[12]# Grad-CAM
grad_cam = GradCAM(model=model, target_layer=target_layer)
# 獲取輸入圖像的Grad-CAM圖像
cam_img = grad_cam(img_tensor, index=pred_class)# 重新調整尺寸以匹配原始圖像
cam_img = Image.fromarray(np.uint8(255 * cam_img[0]))
cam_img = cam_img.resize((img.width, img.height), Image.BICUBIC)# 將CAM圖像轉換為Heatmap
cmap = cm.get_cmap('jet')
cam_img = cmap(np.float32(cam_img))# 將RGBA圖像轉換為RGB
cam_img = Image.fromarray(np.uint8(cam_img[:, :, :3] * 255))
cam_img = Image.blend(img, cam_img, alpha=0.5)# 顯示圖像
plt.imshow(cam_img)
plt.axis('off') # 不顯示坐標軸
plt.show()print(pred_class)輸出如下,分別是第一、二、六、十二層的卷積層的輸出:
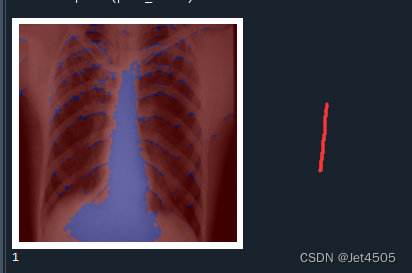
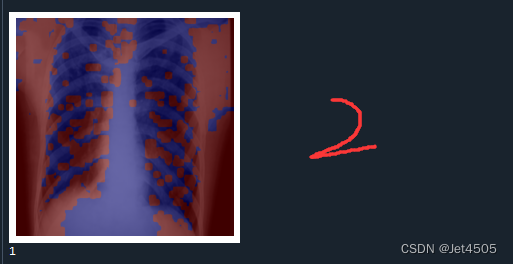

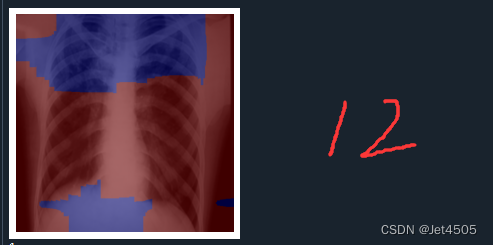
結果解讀:
在Grad-CAM熱圖中,顏色的深淺表示了模型在做出預測時,對輸入圖像中的哪些部分賦予了更多的重要性。紅色區域代表了模型認為最重要的部分,這些區域在模型做出其預測時起到了主要的決定性作用。而藍色區域則是對預測貢獻較少的部分。
具體來說:
紅色區域:這些是模型在進行預測時,權重較高的部分。也就是說,這些區域對模型的預測結果影響最大。在理想情況下,這些區域應該對應于圖像中的目標對象或者是對象的重要特征。
藍色區域:這些是模型在進行預測時,權重較低的部分。也就是說,這些區域對模型的預測結果影響較小。在理想情況下,這些區域通常對應于圖像的背景或無關信息。
這種可視化方法可以幫助我們理解卷積神經網絡模型是如何看待圖像的,也能提供一種評估模型是否正確關注到圖像中重要部分的方法。
三、數據
鏈接:https://pan.baidu.com/s/15vSVhz1rQBtqNkNp2GQyVw?pwd=x3jf
提取碼:x3jf




![[C++ 網絡協議編程] TCP/IP協議](http://pic.xiahunao.cn/[C++ 網絡協議編程] TCP/IP協議)


)





理解NFT)

)
)


