1.簡介
(1) 貝葉斯分類器的分類原理發源于古典概率理論,是通過某對象的先驗概率,利用貝葉斯公式計算出其后驗概率,即該對象屬于某一類的概率,選擇具有最大后驗概率的類作為該對象所屬的類。樸素貝葉斯分類器(Naive Bayes Classifier)做了一個簡單的假定:給定目標值時屬性之間相互條件獨立,即給定元組的類標號,假定屬性值有條件地相互獨立,即在屬性間不存在依賴關系。樸素貝葉斯分類模型所需估計的參數很少,對缺失數據不太敏感,算法也比較簡單。(2) Mahout 實現了Traditional Naive Bayes 和Complementary Naive Bayes,后者是在前者的基礎上增加了結果分析功能(Result Analyzer).
(3) 主要相關的Mahout類:
org.apache.mahout.classifier.naivebayes.NaiveBayesModel
org.apache.mahout.classifier.naivebayes.StandardNaiveBayesClassifier
org.apache.mahout.classifier.naivebayes.ComplementaryNaiveBayesClassifier
2.數據
使用20 newsgroups data (http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz) ,數據集按時間分為訓練數據和測試數據,總大小約為85MB,每個數據文件為一條信息,文件頭部幾行指定消息的發送者、長度、類型、使用軟件,以及主題等,然后用空行將其與正文隔開,正文沒有固定的格式。
3.目標
根據新聞文檔內容,將其分到不同的文檔類型中。
4.程序
使用Mahout自帶示例程序,主要的訓練類和測試類分別為TrainNaiveBayesJob.java和TestNaiveBayesDriver.java,JAR包為mahout-core-0.7-job.jar,詳細代碼見(mahout-distribution-0.7/core/src/main/java/org/apache/mahout/classifier/naivebayes/trainning,mahout-distribution-0.7/core/src/main/java/org/apache/mahout/classifier/naivebayes/test).
5.步驟
(1) 數據準備
①將20news-bydate.tar.gz解壓,并將20news-bydate中的所有子文夾中的內容復制到20news-all中,該步驟已經完成,20news-all文件夾存放在hdfs:/share/data/ Mahout_examples_Data_Set中
②將20news-all放在hdfs的用戶根目錄下
user@hadoop:~/workspace$hadoop dfs -cp /share/data/Mahout_examples_Data_Set/20news-all .
③從20newsgroups data創建序列文件(sequence files)
user@hadoop:~/workspace$mahout seqdirectory -i 20news-all -o 20news-seq
④將序列文件轉化為向量
user@hadoop:~/workspace$mahout seq2sparse -i ./20news-seq -o ./20news-vectors ?-lnorm -nv ?-wt tfidf ?
⑤將向量數據集分為訓練數據和檢測數據,以隨機40-60拆分
user@hadoop:~/workspace$mahout split -i ./20news-vectors/tfidf-vectors --trainingOutput ./20news-train-vectors --testOutput ./20news-test-vectors --randomSelectionPct 40 --overwrite --sequenceFiles -xm sequential
(2)訓練樸素貝葉斯模型
user@hadoop:~/workspace$mahout trainnb -i ?./20news-train-vectors -el -o ./model -li ./labelindex -ow -c ?(3)檢驗樸素貝葉斯模型
user@hadoop:~/workspace$mahout testnb -i ./20news-train-vectors -m ./model -l ./labelindex -ow -o 20news-testing -c
結果如下:
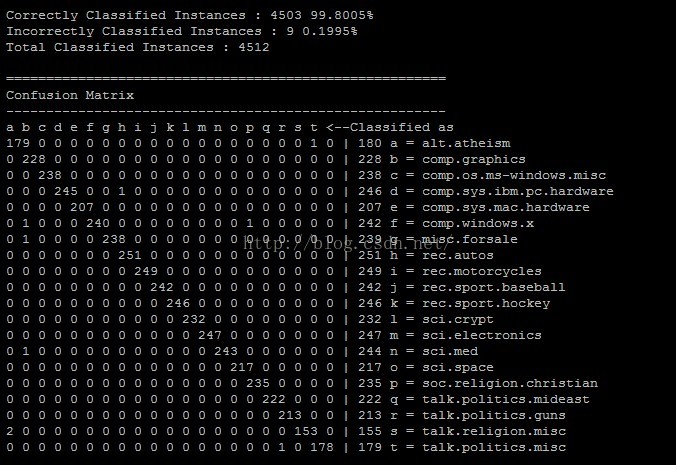
(4)檢測模型分類效果
user@hadoop:~/workspace$mahout testnb -i ./20news-test-vectors -m ./model -l ./labelindex -ow -o ./20news-testing -c
結果如下:
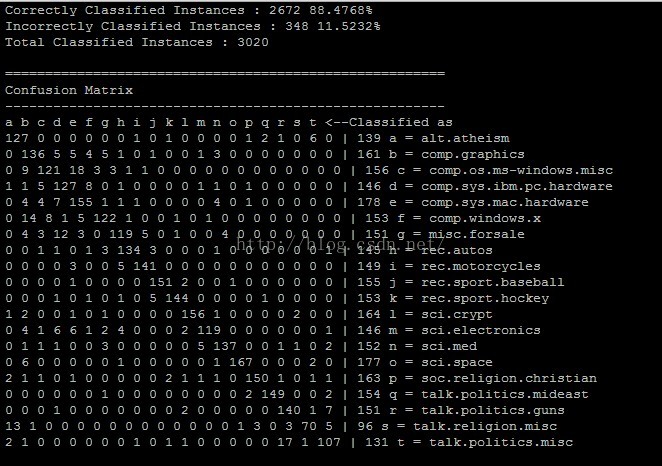
(5)查看結果,將序列文件轉化為文本
user@hadoop:~/workspace$mahout seqdumper -i ./20news-testing/part-m-00000 -o ./20news_testing.res
user@hadoop:~/workspace$cat 20news_testging.res
結果如下:
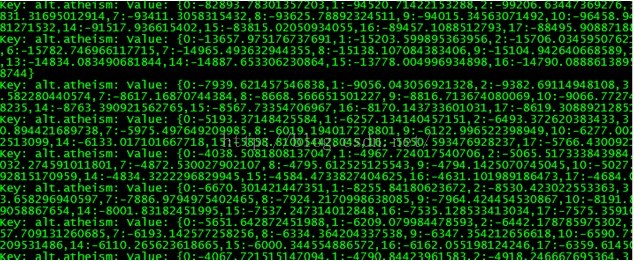



)

(必懂!題解 1-100 內素數)素數原來是質數!為什么你不早說!)
自動化測試)



至單部件要素的兩種方法)


無底洞的循環)


3.2 安裝教程(附安裝包下載))


