與MySQL傳統復制相比,GTID有哪些獨特的復制姿勢?
http://mp.weixin.qq.com/s/IF1Pld-wGW0q2NiBjMXwfg
陳華軍,蘇寧云商IT總部資深技術經理,從事數據庫服務相關的開發和維護工作,之前曾長期從事富士通關系數據庫的開發,PostgreSQL中國用戶會核心成員,熟悉PostgreSQL和MySQL。
?
?
[MySQL 5.6] GTID實現、運維變化及存在的bug
http://www.cnblogs.com/MYSQLZOUQI/p/3850578.html
?
適當減小binlog文件的大小
如果開啟GTID,理論上最好調小每個binlog文件的最大值,以縮小掃描文件的時間。
?
GTID(Global Transaction ID)是MySQL5.6引入的功能,可以在集群全局范圍標識事務,用于取代過去通過binlog文件偏移量定位復制位置的傳統方式。借助GTID,在發生主備切換的情況下,MySQL的其它Slave可以自動在新主上找到正確的復制位置,這大大簡化了復雜復制拓撲下集群的維護,也減少了人為設置復制位置發生誤操作的風險。另外,基于GTID的復制可以忽略已經執行過的事務,減少了數據發生不一致的風險。
GTID雖好,要想運用自如還需充分了解其原理與特性,特別要注意與傳統的基于binlog文件偏移量復制方式不一樣的地方。本文概述了關于GTID的幾個常見問題,希望能對理解和使用基于GTID的復制有所幫助。
GTID長什么樣
根據官方文檔定義,GTID由source_id加transaction_id構成。
GTID = source_id:transaction_id
上面的source_id指示發起事務的MySQL實例,值為該實例的server_uuid。server_uuid由MySQL在第一次啟動時自動生成并被持久化到auto.cnf文件里,transaction_id是MySQL實例上執行的事務序號,從1開始遞增。 例如:
e6954592-8dba-11e6-af0e-fa163e1cf111:1
一組連續的事務可以用'-'連接的事務序號范圍表示。例如
e6954592-8dba-11e6-af0e-fa163e1cf111:1-5
更一般的情況是GTID的集合。GTID集合可以包含來自多個source_id的事務,它們之間用逗號分隔;如果來自同一source_id的事務序號有多個范圍區間,各組范圍之間用冒號分隔,例如:
e6954592-8dba-11e6-af0e-fa163e1cf111:1-5:11-18,
e6954592-8dba-11e6-af0e-fa163e1cf3f2:1-27
即,GTID集合擁有如下的形式定義:
gtid_set:
??? uuid_set [, uuid_set] ...
??? | ''
uuid_set:
??? uuid:interval[:interval]...
uuid:
??? hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhh
h:
??? [0-9|A-F]
interval:
??? n[-n]
??? (n >= 1)
如何查看GTID
可以通過MySQL的幾個變量查看相關的GTID信息。
gtid_executed
在當前實例上執行過的GTID集合; 實際上包含了所有記錄到binlog中的事務。所以,設置set sql_log_bin=0后執行的事務不會生成binlog 事件,也不會被記錄到gtid_executed中。執行RESET MASTER可以將該變量置空(搭主從時候,導入數據到從庫不能導入就執行reset master)。
gtid_purged
binlog不可能永遠駐留在服務器上,需要定期進行清理(通過expire_logs_days可以控制定期清理間隔),否則遲早它會把磁盤用盡。gtid_purged用于記錄已經被清除了的binlog事務集合,它是gtid_executed的子集。只有gtid_executed為空時才能手動設置該變量,此時會同時更新gtid_executed為和gtid_purged相同的值。gtid_executed為空意味著要么之前沒有啟動過基于GTID的復制,要么執行過RESET MASTER。執行RESET MASTER時同樣也會把gtid_purged置空,即始終保持gtid_purged是gtid_executed的子集。
gtid_next
會話級變量,指示如何產生下一個GTID。可能的取值如下:
1)AUTOMATIC:
自動生成下一個GTID,實現上是分配一個當前實例上尚未執行過的序號最小的GTID。
2)ANONYMOUS:
設置后執行事務不會產生GTID。
3)顯式指定的GTID:
可以指定任意形式合法的GTID值,但不能是當前gtid_executed中的已經包含的GTID,否則,下次執行事務時會報錯。
這些變量可以通過show命令查看,比如:
show variables like '%gtid%';
+---------------------------------+-----------+
| Variable_name | Value |
+---------------------------------+-----------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | |
| gtid_mode | ON |
| gtid_next | AUTOMATIC |
| gtid_owned | |
| gtid_purged | |
| simplified_binlog_gtid_recovery | ON |
+---------------------------------+-----------+
如何產生GTID
GTID的生成受gtid_next控制。 在Master上,gtid_next是默認的AUTOMATIC,即在每次事務提交時自動生成新的GTID。它從當前已執行的GTID集合(即gtid_executed)中,找一個大于0的未使用的最小值作為下個事務GTID。同時在binlog的實際的更新事務事件前面插入一條set gtid_next事件。
以下是一條insert語句生成的binlog記錄:
在Slave上回放主庫的binlog時,先執行set gtid_next ...,然后再執行真正的insert語句,確保在主和備上這條insert對應于相同的GTID。
一般情況下,GTID集合是連續的,但使用多線程復制(MTS)以及通過gtid_next進行人工干預時會導致gtid空洞。比如下面這樣:
繼續執行事務,MySQL會分配一個最小的未使用GTID,也就是從出現空洞的地方分配GTID,最終會把空洞填上。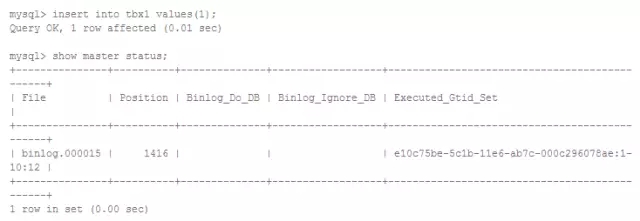
這意味著嚴格來說我們即不能假設GTID集合是連續的,也不能假定GTID序號大的事務在GTID序號小的事務之后執行,事務的順序應由事務記錄在binlog中的先后順序決定。
GTID的持久化
GTID相關的信息存儲在binlog文件中,為此MySQL5.6新增了下面2個binlog事件。
Previous_gtids_log_event 在每個binlog文件的開頭部分,記錄在該binlog文件之前已執行的GTID集合。
Gtid_log_event 即前面看到的set gtid_next ...,它出現在每個事務的前面,表明下一個事務的gtid。
示例如下:
MySQL服務器啟動時,通過讀binlog文件,初始化gtid_executed和gtid_purged,使它們的值能和上次MySQL運行時一致。
gtid_executed被設置為最新的binlog文件中Previous_gtids_log_event和所有Gtid_log_event的并集。
gtid_purged為最老的binlog文件中Previous_gtids_log_event。
由于這兩個重要的變量值記錄在binlog中,所以開啟gtid_mode時必須同時在主庫上開啟log_bin在備庫上開啟log_slave_updates。
但是,在MySQL5.7中沒有這個限制。MySQL5.7中,新增加一個系統表mysql.gtid_executed用于持久化已執行的GTID集合。當主庫上沒有開啟log_bin或在備庫上沒有開啟log_slave_updates時,mysql.gtid_executed會跟用戶事務一起每次更新。否則只在binlog日志發生rotation時更新mysql.gtid_executed。
如何配置基于GTID的復制
MySQL服務器的my.cnf配置文件中增加GTID相關的參數
log_bin???????????????????????????????? = /mysql/binlog/mysql_bin
log_slave_updates??????????????? = true
gtid_mode??????????????????????????? = ON
enforce_gtid_consistency????? = true
relay_log_info_repository?????? = TABLE
relay_log_recovery??????????????? = ON
然后在Slave上指定MASTER_AUTO_POSITION = 1執行CHANGE MASTER TO即可。比如:
CHANGE MASTER TO MASTER_HOST='node1',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_AUTO_POSITION=1;
基于GTID的復制如何工作
在MASTER_AUTO_POSITION = 1的情況下 ,MySQL會使用 COM_BINLOG_DUMP_GTID 協議進行復制。過程如下:
備庫發起復制連接時,將自己的已接受和已執行的gtids的并集(后面稱為slave_gtid_executed)發送給主庫。即下面的集合:
UNION(@@global.gtid_executed, Retrieved_gtid_set - last_received_GTID)
主庫將自己的gtid_executed與slave_gtid_executed的差集的binlog發送給Slave。主庫的binlog dump過程如下:
1、檢查slave_gtid_executed是否是主庫gtid_executed的子集,如否那么主備數據可能不一致,報錯。 2、檢查主庫的purged_executed是否是slave_gtid_executed的子集,如否代表缺失備庫需要的binlog,報錯 3、從最后一個Binlog開始掃描,獲取文件頭部的PREVIOUS_GTIDS_LOG_EVENT,如果它是slave_gtid_executed的子集,則這是需要發送給Slave的第一個binlog文件,否則繼續向前掃描。 4、從第3步找到的binlog文件的開頭讀取binlog記錄,判斷binlog記錄是否已被包含在slave_gtid_executed中,如果已包含跳過不發送。
從上面的過程可知,在指定MASTER_AUTO_POSITION = 1時,Master發送哪些binlog記錄給Slave,取決于Slave的gtid_executed和Retrieved_Gtid_Set以及Master的gtid_executed,但是和relay_log_info以及master_log_info中保存的復制位點沒有關系。
如何修復復制錯誤
在基于GTID的復制拓撲中,要想修復Slave的SQL線程錯誤,過去的SQL_SLAVE_SKIP_COUNTER方式不再適用。需要通過設置gtid_next或gtid_purged完成,當然前提是已經確保主從數據一致,僅僅需要跳過復制錯誤讓復制繼續下去。比如下面的場景:
在從庫上創建表tb1
mysql> set sql_log_bin=0;
Query OK, 0 rows affected (0.00 sec)
mysql> create table tb1(id int primary key,c1 int);
Query OK, 0 rows affected (1.06 sec)
mysql> set sql_log_bin=1;
Query OK, 0 rows affected (0.00 sec)
在主庫上創建表tb1:
mysql> create table tb1(id int primary key,c1 int);
Query OK, 0 rows affected (1.06 sec)
由于從庫上這個表已經存在,從庫的復制SQL線程出錯停止。
上面的輸出可以知道,從庫已經執行過的事務是'e10c75be-5c1b-11e6-ab7c-000c296078ae:1-5',執行出錯的事務是'e10c75be-5c1b-11e6-ab7c-000c296078ae:6',當前主備的數據其實是一致的,可以通過設置gtid_next跳過這個出錯的事務。
在從庫上執行以下SQL:
mysql> set gtid_next='e10c75be-5c1b-11e6-ab7c-000c296078ae:6';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> set gtid_next='AUTOMATIC';
Query OK, 0 rows affected (0.00 sec)
mysql> start slave;
Query OK, 0 rows affected (0.02 sec)
設置gtid_next的方法一次只能跳過一個事務,要批量的跳過事務可以通過設置gtid_purged完成。假設下面的場景:
主庫上已執行的事務
從庫上已執行的事務
假設經過修復從庫已經和主庫的數據一致了,但由于復制錯誤Slave的SQL線程依然處于停止狀態。現在可以通過把從庫的gtid_purged設置為和主庫的gtid_executed一樣跳過不一致的GTID使復制繼續下去,步驟如下。
在從庫上執行
此時從庫的Executed_Gtid_Set已經包含了主庫上'1-10'的事務,再開啟復制會從后面的事務開始執行,就不會出錯了。
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
使用gtid_next和gtid_purged修復復制錯誤的前提是,跳過那些事務后仍可以確保主備數據一致。如果做不到,就要考慮pt-table-sync或者拉備份的方式了。
GTID與備份恢復
在做備份恢復的時候,有時需要恢復出來的MySQL實例可以作為Slave連上原來的主庫繼續復制,這就要求從備份恢復出來的MySQL實例擁有和數據一致的gtid_executed值。這也是通過設置gtid_purged實現的,下面看下mysqldump做備份的例子。
1、通過mysqldump進行備份
通過mysqldump做一個全量備份:
[root@node1 ~]# mysqldump --all-databases --single-transaction --routines --events --host=127.0.0.1 --port=3306 --user=root > dump.sql
生成的dump.sql文件里包含了設置gtid_purged的語句
SET @MYSQLDUMP_TEMP_LOG_BIN = @@SESSION.SQL_LOG_BIN;
SET @@SESSION.SQL_LOG_BIN= 0;
...
SET @@GLOBAL.GTID_PURGED='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10';
...
SET @@SESSION.SQL_LOG_BIN = @MYSQLDUMP_TEMP_LOG_BIN;
恢復數據前需要先通過reset master清空gtid_executed變量
[root@node2 ~]# mysql -h127.1 -e 'reset master'
[root@node2 ~]# mysql -h127.1 <dump.sql
否則執行設置GTID_PURGED的SQL時會報下面的錯誤
ERROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty.
此時恢復出的MySQL實例的GTID_EXECUTED和備份時點一致:
show master status看一下從庫的GTID_EXECUTED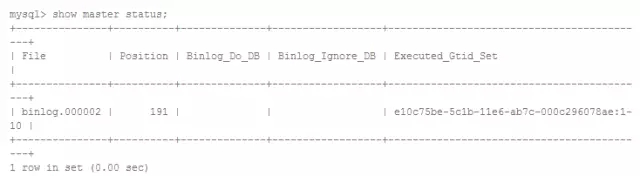
由于恢復出的MySQL實例已經被設置了正確的GTID_EXECUTED,以master_auto_postion = 1的方式CHANGE MASTER到原來的主節點即可開始復制。
CHANGE MASTER TO MASTER_HOST='node1', MASTER_USER='repl', MASTER_PASSWORD='repl', MASTER_AUTO_POSITION = 1
如果不希望備份文件中生成設置GTID_PURGED的SQL,可以給mysqldump傳入--set-gtid-purged=OFF關閉。
2、通過Xtrabackup進行備份
相比mysqldump,Xtrabackup是效率更高并且被廣泛使用的備份方式。使用Xtrabackup進行備份的舉例如下。
通過Xtrabackup創一個全量備份(可以在Slave上創建備份,以避免對主庫的性能沖擊)
innobackupex --defaults-file=/etc/my.cnf --host=127.1 --user=root --password=mysql --no-timestamp --safe-slave-backup --slave-info /mysql/bak
應用日志
innobackupex --apply-log /mysql/bak
查看備份目錄中的xtrabackup_binlog_info文件可以找到備份時已經執行過的gtids
[root@node2 ~]# cat /mysql/bak/xtrabackup_binlog_info
mysql_bin.000001??? 191??? e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10
由于備份時添加了”--slave-info”選項并且從Slave節點拉取的備份,所以會生成xtrabackup_slave_info文件,也可以從這個文件里查找建立復制的SQL語句。
[root@node2 ~]# cat /mysql/bak/xtrabackup_slave_info
SET GLOBAL gtid_purged='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10';
CHANGE MASTER TO MASTER_AUTO_POSITION=1
將備份文件傳送到新的節點node3的/mysql/bak目錄并恢復(如果直接把備份傳輸到數據目錄了,這一步可以省略 ?備份文件可以直接mv)。
[root@node3 ~]# innobackupex --defaults-file=/etc/my.cnf --copy-back /mysql/bak
啟動MySQL。
[root@node3 ~]# mysqld --defaults-file=/home/mysql/etc/my.cnf --skip-slave-start &
如果是從Slave拉的備份,一定不能直接開啟Slave復制,這時的gtid_executed是錯誤的。需要手動設置gtid_purged后再start slave
MASTER_HOST='node1',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_AUTO_POSITION=1;
start slave;
GTID與MHA
MHA是被廣泛使用MySQL HA組件,MHA 0.56以后支持基于GTID的復制。 MHA在failover時會自動判斷是否是GTID based failover,需要滿足下面3個條件即為GTID based failover
所有節點gtid_mode=1
所有節點Executed_Gtid_Set不為空
至少一個節點Auto_Position=1
和之前的基于binlog文件位置的復制相比,基于GTID復制下,MHA在故障切換時的變化主要如下:
基于binlog文件位置的復制
在Master宕機后會嘗試從Master上拷貝binlog日志進行補償
如果候選Master不擁有最新的relay log,會從擁有最新relay log的Slave上生成差異的binlog傳送到候選Master并實施補償
新Master的日志補償完成后,同樣采用應用差異binlog的方式將其它Slave和新Master同步后再change master到新Master
基于GTID的復制
如果候選Master不擁有最新的relay log,讓候選Master連上擁有最新relay log的Salve進行補償。
嘗試從binlog server上拉取缺失的binlog并應用
新Master的數據同步到最新后,讓其它的Slave連上新Master并等待數據完成同步。并且可以給masterha_master_switch傳入--wait_until_gtid_in_sync=1參數使其不等其它Slave完成數據同步,以加快切換速度。
GTID模式下MHA不會嘗試從舊Master上拷貝binlog日志進行補償,所以在MySQL進程crash而OS仍然健康的情況下,應盡量不要做主備切換而是原地重啟MySQL,除非有其它能確保切換后不丟數據的措施。
在GTID模式下MHA支持在復制拓撲中增加一個或多個binlog server起到日志補償的作用,非GTID模式下即使配置了binlog server也會被MHA忽略。
日志補償可以說是MHA中最復雜也最精華的部分,有了GTID后故障切換變得更簡單了,不再需要原本復雜的binlog日志解析和補償。所以Oracle官方推出了只支持GTID復制的切換工具mysqlfailover,在GTID的幫助下,我們有更多靠譜的HA工具可以選擇。
GTID與crash safe salve
crash safe slave是MySQL 5.6提供的功能,意思是說在slave crash后,把slave重新拉起來可以繼續從Master進行復制,不會出現復制錯誤也不會出現數據不一致。
1、基于binlog文件位置的復制
在基于binlog文件位置的復制下,要保證crash safe slave,配置下面的參數即可。
relay_log_info_repository????? = TABLE
relay_log_recovery?????????????? = ON
這樣可行的原因是,relay_log_info_repository = TABLE時,apply event和更新relay_log_info表的操作被包含在同一個事務里(如果用relay_log_info文件就不能包含在同一個事務里),innodb要么讓它們同時生效,要么同時不生效,保證位點信息和已經應用的事務精確匹配。同時relay_log_recovery = ON時,會拋棄master_log_info中記錄的復制位點,根據relay_log_info的執行位置重新從Master獲取binlog,這就回避了由于relaylog文件未同步刷盤導致的binlog文件接受位置和實際relaylog文件不一致以及relay log文件被截斷刪除的問題。
在同時使用MTS(multi-threaded slave)時,為保證crash safe slave基于binlog文件位置的復制還需要設置sync_relay_log=1,因為MySQL在Crash恢復時必須先通過讀取relay log補齊MTS導致的事務空洞。
2、基于GTID的復制
上面的設置并不適用于基于GTID的復制。在基于GTID的復制下,crash的Slave重啟后,從binlog中解析的gtid_executed決定了要apply哪些binlog記錄,所以binlog必須和innodb存儲引擎的數據保持一致。要做到這一點,需要把sync_binlog和innodb_flush_log_at_trx_commit都設置為1,即所謂的"雙1"。
slave_relay_log_info表沒有Executed_Gtid_Set,只有pos點
select * from slave_relay_log_info\G;
*************************** 1. row ***************************
Number_of_lines: 7
Relay_log_name: /data/mysql/mysql3306/logs/mysql-relay.000001
Relay_log_pos: 4
Master_log_name:
Master_log_pos: 0
Sql_delay: 0
Number_of_workers: 0
Id: 1
?
另外MySQL啟動時,會從relay log文件中獲取已接收的GTIDs并更新Retrieved_Gtid_Set。由于relay log文件可能不完整,所以需要拋棄已接收的relay log文件。因此relay_log_recovery = ON也是必須的。
這樣,對于基于GTID的復制,保證crash safe slave的設置就是下面這樣。
sync_binlog?????????????????????????????? = 1
innodb_flush_log_at_trx_commit? = 1
relay_log_recovery???????????????????? = ON
關于如何設置以確保crash safe slave,官方文檔有明確記載,見 17.3.2 Handling an Unexpected Halt of a Replication Slave。
但是其中關于GTID的記載中存在筆誤,將relay_log_recovery=1寫成了relay_log_recovery=0 (#83711)。同時也沒有提到必須設置"雙1",但是"雙1"是必要的,否則crash的Slave重啟后,可能會重復應用binlog event也可能會遺漏應用binlog event(#70659)。其中遺漏應用binlog event的情況更可怕,因為Slave在不觸發SQL錯誤的情況下就默默的和Master不一致了。
3、設置"雙1"對性能的影響
出于安全考慮,強烈推薦設置"雙1"。"雙1"會增大每個事務的RT,但得益于MySQL的組提交機制,高并發下"雙1"對系統整體tps的影響在可接受范圍內。
sysbench oltp.lua 10張表每張表100w記錄(qps/并發數)
對更新同一行這樣無法有效并行的場景,"雙1"對性能的影響非常大。
sysbench update_non_index.lua 1張表1條記錄(qps/并發數)
對不能有效并行的Slave replay,存在同樣的問題。
通過指定tx-rate執行sysbench的update_non_index.lua腳本壓測30秒,完成后檢查主備延遲。
可以發現在Slave被配置為"雙1"的情況下,延遲非常嚴重,1000以上的QPS就會出現延遲,非"雙1"下QPS到5000以上才會出現延遲(主庫配置為"雙1")。
sysbench update_non_index.lua 1張表100w條記錄 128并發(延遲/qps)
以上測試環境是Percona Server 5.6運行在配置HDD的8 core虛機,由于測試結果和系統IO能力有很大關系,僅供參考。
4、如何在非"雙1"下保證crash safe slave
如果是MySQL 5.7可以關閉log_slave_updates,這樣MySQL會將已執行的GTIDs實時記錄到系統表mysql.gtid_executed中,mysql.gtid_executed是和用戶事務一起提交的,因此可以保證和實際的數據一致。
log_slave_updates????????????? = OFF
relay_log_recovery???????????? = ON
如果是MySQL 5.6可以采用如下變通的方式。
按照基于binlog文件復制時crash safe slave的要求設置relay_log_info_repository = TABLE
relay_log_info_repository????? = TABLE
relay_log_recovery?????????????? = ON
在Slave crash后,根據relay_log_info_repository設置相應的gitd_purged再開啟復制,步驟如下。
1.啟動MySQL,但不開啟復制
?mysqld --skip-slave-start
2.在Slave上修改為基于binlog文件位置的復制
change master to MASTER_AUTO_POSITION = 0
3.啟動slave IO線程
start slave io_thread
這里不能啟動SQL線程,如果接受到的GTID已經在Slave的gtid_executed里了,會被Slave skip掉。
4.檢查binlog傳輸的開始位置(即Retrieved_Gtid_Set的值)
show slave status\G
假設輸出的Retrieved_Gtid_Set值為e10c75be-5c1b-11e6-ab7c-000c296078ae:7-10
5.在Master上檢查gtid_executed
show master status
假設輸出的Executed_Gtid_Set值為e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10
6.在Slave上設置gitd_purged為binlog傳輸位置的前面的GTID的集合
reset master;
set global gitd_purged='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-6'; ?
7.修改回auto position的復制
change master to MASTER_AUTO_POSITION = 1
8.啟動slave SQL線程
?start slave sql_thread
但是,這種變通的方法不適合多線程復制。因為多線程復制可能產生gtid gap和Gap-free low-watermark position,這會導致Salve上重復apply已經apply過的event。后果就是數據不一致或者復制中斷,除非設置binlog格式為row模式并且slave_exec_mode=IDEMPOTENT,slave_exec_mode=IDEMPOTENT(冪等(idempotent、idempotence))允許Slave回放binlog時忽略重復鍵和找不到鍵的錯誤,使得binlog回放具有冪等性,但這也意味著如果真的出現了主備數據不一致也會被它忽略。
5、MTS下特有的問題
在同時使用MTS(slave_parallel_workers > 1)時,即使按上面crash safe slave的要求設置了基于GTID的復制,Slave crash后再重啟還是會導致復制中斷。
通過強制殺掉MySQL所在虛機的方式模擬Slave宕機,然后再啟動MySQL,MySQL日志中有如下錯誤消息:
啟動slave時也會報錯
mysql> start slave;
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
出現這種現象的原因在于,relay_log_recovery=1 且 slave_parallel_workers>1的情況下,mysql啟動時會進入MTS Group恢復流程,即讀取relay log,嘗試填補由于多線程復制導致的gap。然后relay log文件由于不是實時刷新的,在relay log文件中找不到gap對應的relay log記錄(覆蓋了gap的relay log起始和結束位置分別被稱為低水位和高水位,低水位點即slave_relay_log_info.Relay_log_pos的值)就會報這個錯。
實際上,在GTID模式下,slave在apply event的時候可以跳過重復事件,所以可以安全的從低水位點應用日志,沒必要解析relay log文件。 這看上去是一個bug,于是提交了一個bug報告#83713,目前還沒有收到回復。
作為回避方法,可以通過清除relay log文件,跳過這個錯誤。執行步驟如下:
reset slave;
change master to MASTER_AUTO_POSITION = 1
start slave;
在這里,單純的調reset slave不能把狀態清理干凈,內部的Relay_log_info.inited標志位仍然處于未被初始化狀態,此時調用start slave仍然會失敗。因此需要補一刀change master。
6、Master的crash safe
前面一直在講crash safe slave,Master的crash safe同樣重要。 要想Master保持crash safe需要按下面的參數進行設置,否則不僅會丟失事務,gtid_executed還可能和實際的innodb存儲引擎中的數據不一致。
sync_binlog????????????????????????????? = 1
innodb_flush_log_at_trx_commit = 1
在Master配置為"雙1"的情況下,Master crash后,如果沒有發生failover,可以繼續作為Master。 如果發生了failover,可以檢查舊Master和新Master上由舊Master執行的事務集合是否一致。
show master status
如果一致,可以按MASTER_AUTO_POSITION = 1的方式將舊Master作為Slave和新Master建立復制關系。否則,考慮做事務補償或從新Master上拉取備份進行恢復。
在Master配置不是"雙1"的情況下,在Master crash后由于難以準確知道舊Master上究竟執行了哪些事務,安全的做法是實施主備切換,并從新Master上拉取備份,把舊Master作為新Master的Slave進行恢復。
mysql5.7并行復制(MTS:enhanced Multi-threaded slave)
https://my.oschina.net/anthonyyau/blog/663137
5.7.2 支持單庫增強型多線程slave(多個sql work線程),mariadb 10.0.5支持
原理
slave利用事務組提交的特性(To provide parallel execution of transactions in the same schema, MariaDB 10.0 and MySQL 5.7 take advantage of the binary log group commit optimization),在slave 多個sql worker線程進行并行回放
master依據group commit的并行性,在binary log進行標記,slave使用master提供的信息并行執行事務
?
注意事項
級聯復制場景,其他slave將會出現并行性更小(并行度不一樣),使用binlog server做替代方案
配置
mysql 5.7
slave_parallel_type=logical_clock 默認為database,使用db并行方式,logical_clock使用邏輯時鐘的并行模式
slave_parallel_workers=16 設置worker線程數
binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 在master延時事務提交,增加group commit事務數
查看狀態
show processlist 檢查worker線程的狀態
從這篇文章里知道
從庫的gtid_executed從binlog里獲取
從庫的Retrieved_Gtid_Set從relaylog里獲取
?


![[轉]想要成為一名優秀的Java程序員,這份文檔必讀](http://pic.xiahunao.cn/[轉]想要成為一名優秀的Java程序員,這份文檔必讀)

定時任務)


)


)





![[轉]解決Android studio升級到3.5的一些問題](http://pic.xiahunao.cn/[轉]解決Android studio升級到3.5的一些問題)
)

