前言:
大概一年多前寫過一個部署ELK系列的博客文章,前不久剛好在部署一個ELK的解決方案,我順便就把一些基礎的部分拎出來,再整合成一期文章。大概內容包括:搭建ELK集群,以及寫一個簡單的MQ服務。
如果需要看一年多之前寫的文章,可以詳見下列文章鏈接(例如部署成Windows服務、配置瀏覽器插件、logstash接收消費者數據等,該篇文章不再重復描述,可以點擊下方鏈接自行參考):
ElasticSearch、head-master、Kibana環境搭建:https://www.cnblogs.com/weskynet/p/14853232.html
給ElasticSearch添加SQL插件和瀏覽器插件:https://www.cnblogs.com/weskynet/p/14864888.html
使用Logstash通過Rabbitmq接收Serilog日志到ES:https://www.cnblogs.com/weskynet/p/14952649.html
使用nssm工具將ES、Kibana、Logstash或者其他.bat文件部署為Windows后臺服務的方法:https://www.cnblogs.com/weskynet/p/14961565.html
安裝包目錄
將有關環境解壓備用。如圖:
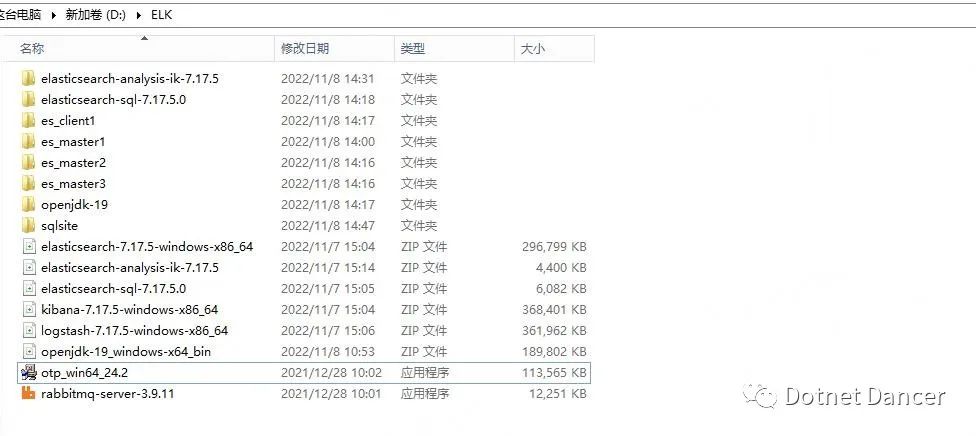
說明:集群環境下,使用4 個elasticsearch 數據庫。其中三個為master,分別可用于選舉主節點、存儲數據使用;另外一個為client,僅作為es 的負載均衡使用。如果服務器配置環境太低的情況下,client 也可以不需要,不會產生影響;如果訪問會比較頻繁,建議可以加上。以下配置操作,均以使用3+1 的集群策略進行配置。
各個環境/安裝包說明
Elasticsearch:主要用來存儲數據的一個非關系型文檔數據庫,基于lucene 內核的搜索引擎,可以實現快速搜索數據的目的。一般用來存儲日志數據比較常見。
Logstash:用于收集數據的管道, 例如此處用來收集消息隊列的數據進行轉儲到elasticsearch 里面。
Kibana:一個可視化的搜索引擎組件,用來查詢elasticsearch 的數據和展示使用。
OpenJDK:非官方版本的JDK 環境,此處使用的是華為鏡像下的定制過的open JDK 19 版本。
Elasticsearch-analisis-ik: 一個中文分詞工具,用于搜索引擎內搜索詞匯時候,可以對詞匯進行歸集處理,而不至于導致搜索出來的結果是模糊查詢。例如:如果沒有分詞,輸入“大佬”進行查詢,會把有“大”和“佬”的結果都查詢出來。而實際上我們需要查的是“大
佬”這個詞。IK 分詞的目的就是這個作用。
Elasticsearch-sql: 一款用于提供SQL 語句進行查詢的工具。
Sqlsite:一款瀏覽器插件,用來集成到谷歌內核的瀏覽器上,可以通過sql 語句進行查詢es 的數據集。
Otp_win64_xx : rabbitmq 環境的erlang 語言包環境,安裝rabbitmq 服務之前,需要先安裝該包
Rabbitmq-server: rabbitmq 安裝包
JDK 環境配置
把解壓縮的open jdk 的bin 目錄,添加到【系統變量】的環境變量Path 里面去。
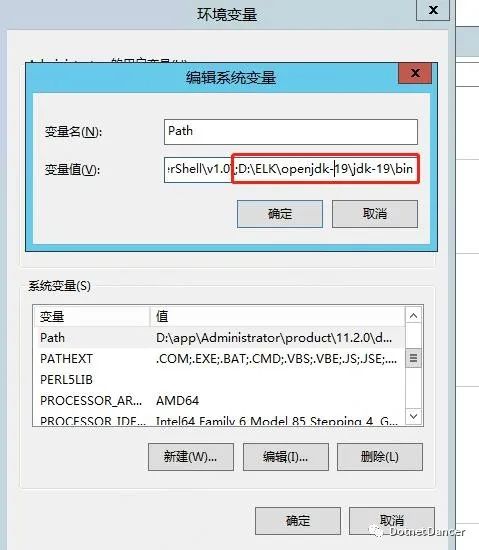
打開cmd,輸入java --version 查看版本,提示版本正確,說明JDK 環境配置OK

?RabbitMQ 環境配置
安裝Otp 語言包:全部默認下一步到頭,簡單粗暴。如果有提示確認的,勾選確認即可。
安裝RabbitMQ 服務安裝包:同上,直接下一步到底,完成。
備注:安裝rabbitmq 對應的服務器主機,服務器【主機的名稱】和【用戶名稱】不能有中文字符,不能有中文字符,不能有中文字符,重要的事情說三遍,我年輕時候踩過坑。
配置環境變量。先新增一個ERLANG_HOME,路徑是安裝erlang的目錄:
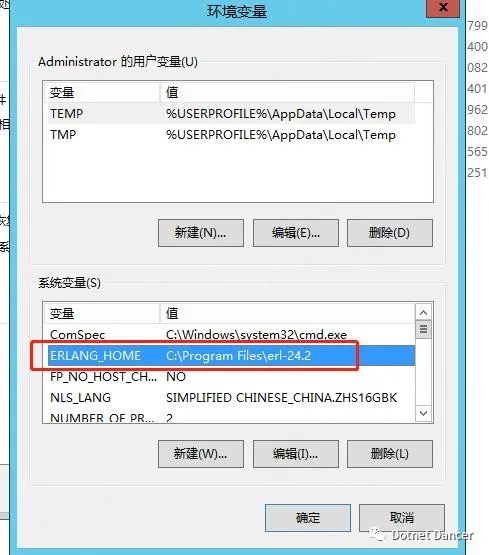
環境變量的Path 里面新增ERLANG_HOME 的bin 目錄:
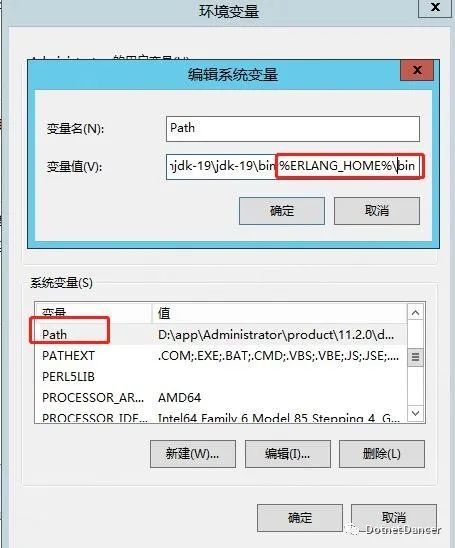
新增RabbitMQ 服務的變量RABBITMQ_SERVER,值是rabbitmq 服務的安裝目錄:
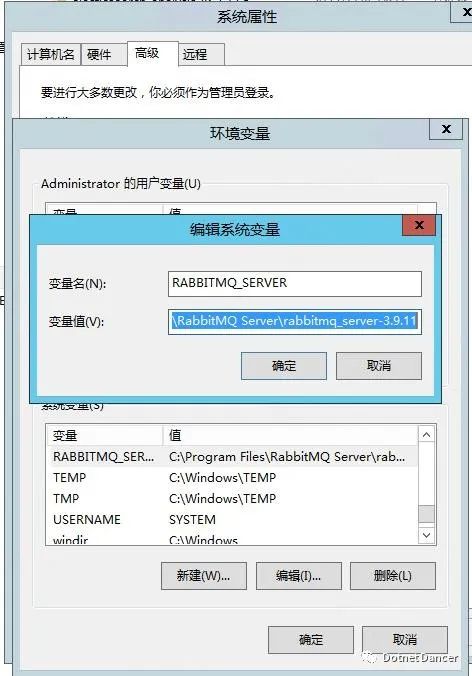
把rabbitmq 的sbin 目錄,加入到path 環境變量里面去:
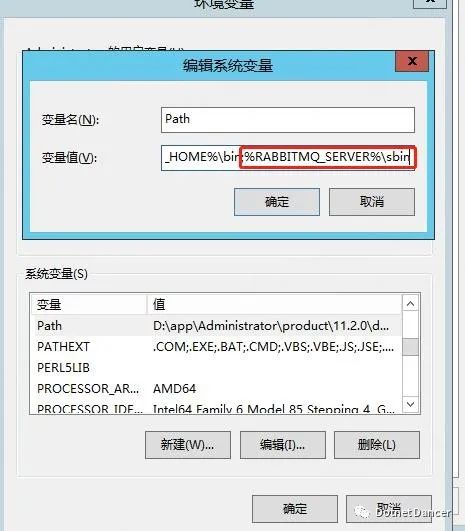
打開cmd,輸入 rabbitmq-plugins enable rabbitmq_management ?進行安裝RabbitMQ-Plugins 的插件:
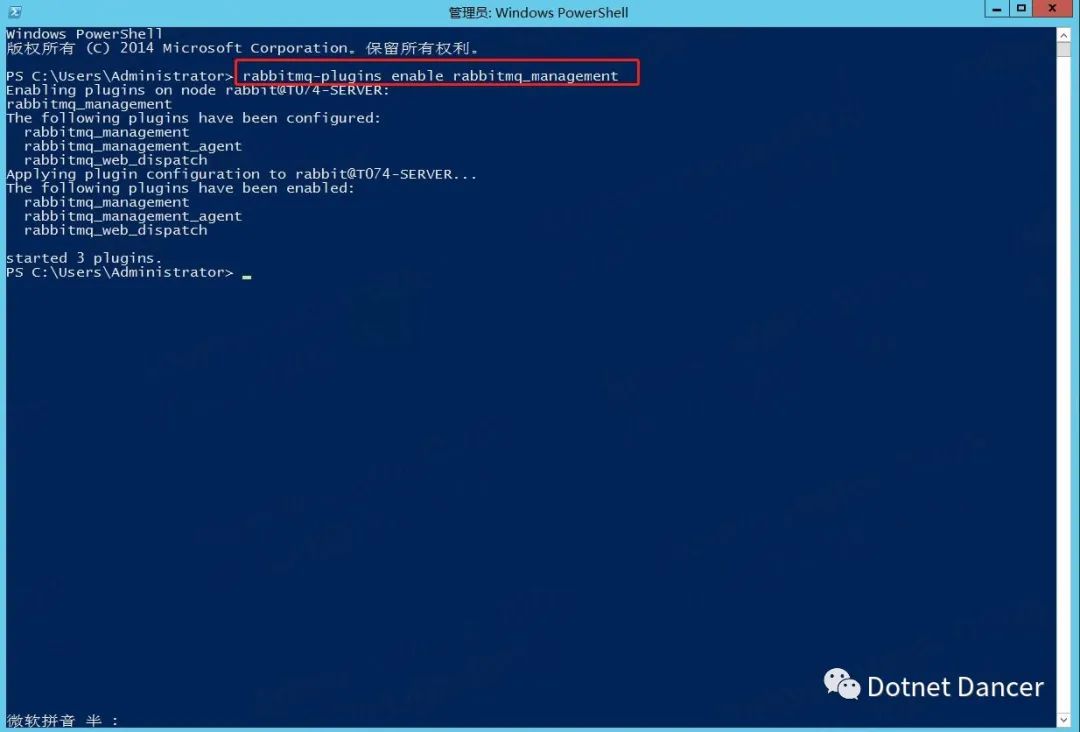
設置好以后,打開瀏覽器,在服務器上輸入訪問http://127.0.0.1:15672
使用guest 賬號進行登錄
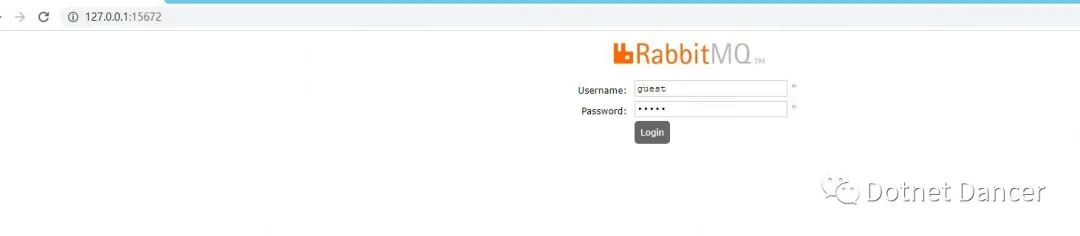
進去以后,找到Admin 菜單,新增一個用戶。此處用戶默認為admin,密碼默認為admin。
也可以設為其他的,設為其他的。最后點擊set 旁邊的Admin,再點擊左下角的Add User
進行添加一個我們的用戶。(不建議使用guest 用戶直接做消息隊列的處理,可能有安全風
險)
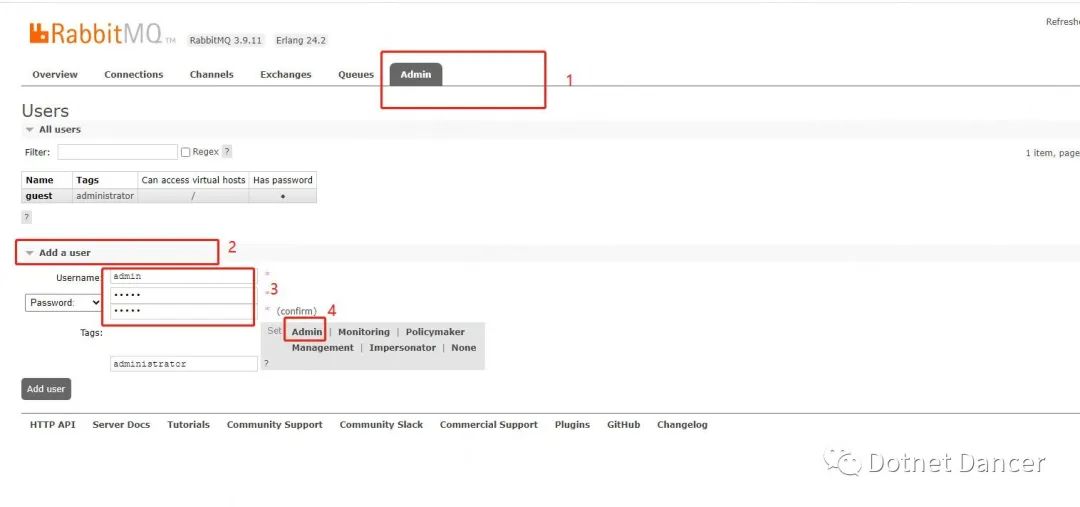
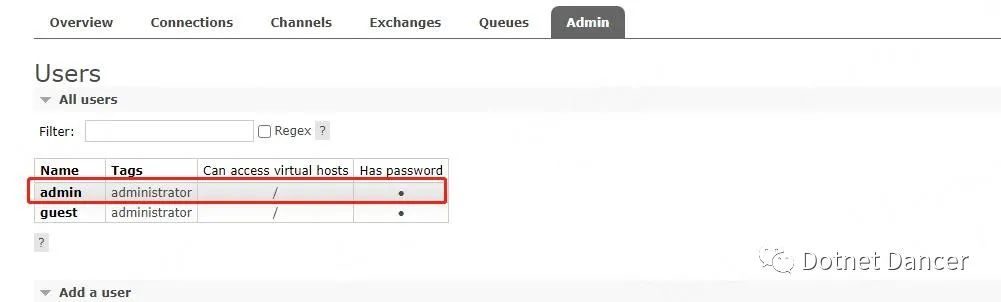
默認添加完成以后,是沒有權限的,需要進一步進行添加權限。點擊表格下的Name字段,會自動進入到設置權限頁面。
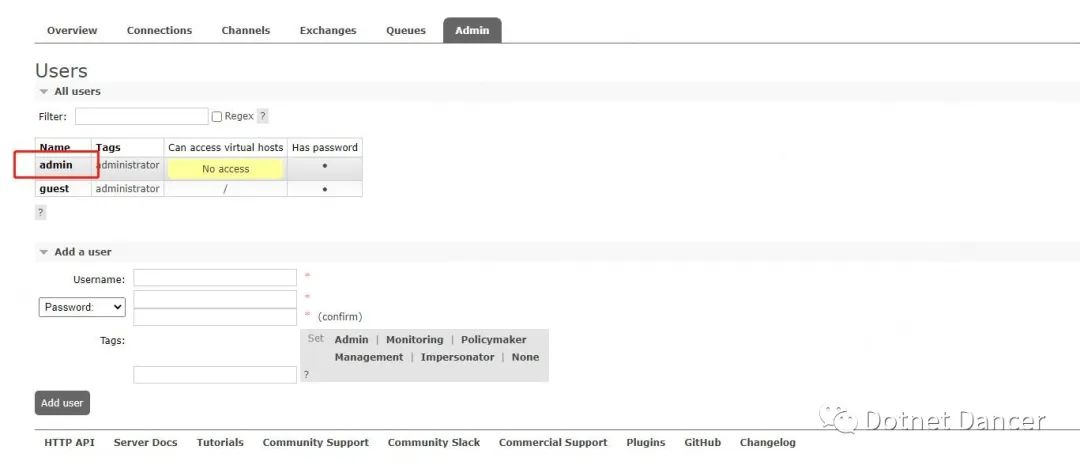
啥也不干,直接點下方第一個按鈕【Set permission】即可
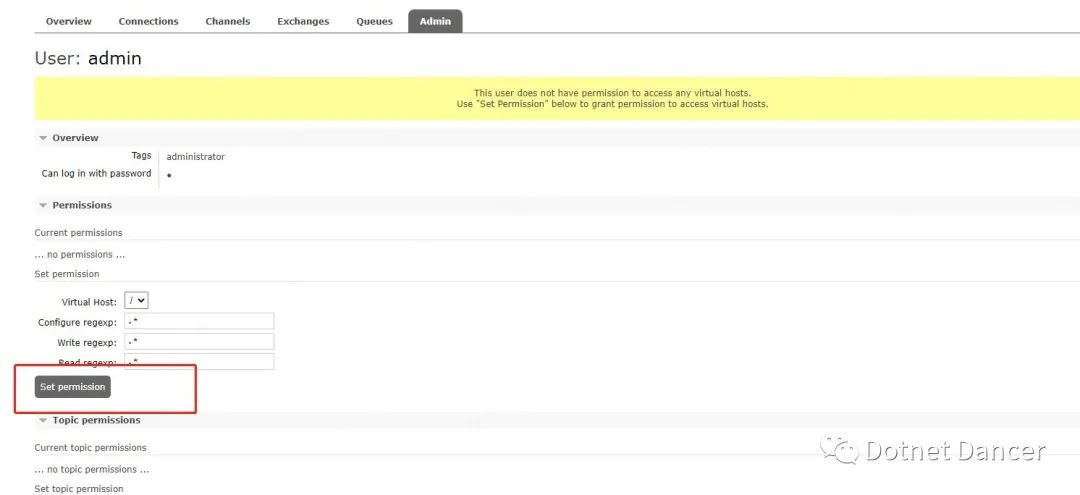
返回Admin 菜單下,可以看到admin 用戶的黃色底色已經沒有了,并且access 權限也
變成了/
Elasticsearch 配置文件elasticsearch.yml 說明
【以下內容摘自網絡,如果不想科普可以跳過該部分】
cluster.name: elasticsearch
配置的集群名稱,默認是elasticsearch,es 服務會通過廣播方式自動連接在同一網段下的es服務,通過多播方式進行通信,同一網段下可以有多個集群,通過集群名稱這個屬性來區分不同的集群。
node.name: "node-01"
當前配置所在機器的節點名,你不設置就默認隨機指定一個name 列表中名字,該name 列表在es 的jar 包中config 文件夾里name.txt 文件中,其中有很多作者添加的有趣名字。當創建ES 集群時,保證同一集群中的cluster.name 名稱是相同的,node.name 節點名稱是不同的;
node.master: true
指定該節點是否有資格被選舉成為node(注意這里只是設置成有資格, 不代表該node 一定就是master),默認是true,es 是默認集群中的第一臺機器為master,如果這臺機掛了就會重新選舉master。
node.data: true
指定該節點是否存儲索引數據,默認為true。
index.number_of_shards: 5
設置默認索引分片個數,默認為5 片。
index.number_of_replicas: 1
設置默認索引副本個數,默認為1 個副本。如果采用默認設置,而你集群只配置了一臺機器,那么集群的健康度為yellow,也就是所有的數據都是可用的,但是某些復制沒有被分配(健康度可用curl ?'localhost:9200/_cat/health?v' 查看, 分為綠色、黃色或紅色。綠色代表一切正常,集群功能齊全,黃色意味著所有的數據都是可用的,但是某些復制沒有被分配,紅色則代表因為某些原因,某些數據不可用)
path.conf: /path/to/conf
設置配置文件的存儲路徑,默認是es 根目錄下的config 文件夾。
path.data: /path/to/data
設置索引數據的存儲路徑,默認是es 根目錄下的data 文件夾,可以設置多個存儲路徑,用逗號隔開,例:path.data: /path/to/data1,/path/to/data2
path.work: /path/to/work
設置臨時文件的存儲路徑,默認是es 根目錄下的work 文件夾。
path.logs: /path/to/logs
設置日志文件的存儲路徑,默認是es 根目錄下的logs 文件夾
path.plugins: /path/to/plugins
設置插件的存放路徑,默認是es 根目錄下的plugins 文件夾, 插件在es 里面普遍使用,用來增強原系統核心功能。
bootstrap.mlockall: true
設置為true 來鎖住內存不進行swapping。因為當jvm 開始swapping 時es 的效率會降低,所以要保證它不swap,可以把ES_MIN_MEM 和ES_MAX_MEM 兩個環境變量設置成同一個值,并且保證機器有足夠的內存分配給es。同時也要允許elasticsearch 的進程可以鎖住內存,linux 下啟動es 之前可以通過`ulimit -l unlimited`命令設置。
network.bind_host: 192.168.0.1
設置綁定的ip 地址,可以是ipv4 或ipv6 的,默認為0.0.0.0,綁定這臺機器的任何一個ip。
network.publish_host: 192.168.0.1
設置其它節點和該節點交互的ip 地址,如果不設置它會自動判斷,值必須是個真實的ip 地址。(可以用不配)
network.host: 192.168.0.1
這個參數是用來同時設置bind_host 和publish_host 上面兩個二手手機參數。(低版本時配置
0.0.0.0,不然啟動會報錯。1.7.1 和1.3.1 版本親測)
transport.tcp.port: 9300
設置節點之間交互的tcp 端口,默認是9300。如我搭建多節點,我的配置分別是9300、9302、9304
transport.tcp.compress: true
設置是否壓縮tcp 傳輸時的數據,默認為false,不壓縮。
http.port: 9200
設置對外服務的http 端口,默認為9200。
http.max_content_length: 100mb
設置內容的最大容量,默認100mb
http.enabled: false
是否使用http 協議對外提供服務,默認為true,開啟。
gateway.type: local
gateway 的類型,默認為local 即為本地文件系統,可以設置為本地文件系統,分布式文件系統,hadoop 的HDFS,和amazon 的s3 服務器等。
gateway.recover_after_nodes: 1
設置集群中N 個節點啟動時進行數據恢復,默認為1。
gateway.recover_after_time: 5m
設置初始化數據恢復進程的超時時間,默認是5 分鐘。
gateway.expected_nodes: 2
設置這個集群中節點的數量,默認為2,一旦這N 個節點啟動,就會立即進行數據恢復。
cluster.routing.allocation.node_initial_primaries_recoveries: 4
初始化數據恢復時,并發恢復線程的個數,默認為4。
cluster.routing.allocation.node_concurrent_recoveries: 2
添加刪除節點或負載均衡時并發恢復線程的個數,默認為4。
indices.recovery.max_size_per_sec: 0
設置數據恢復時限制的帶寬,如入100mb,默認為0,即無限制。
indices.recovery.concurrent_streams: 5
設置這個參數來限制從其它分片恢復數據時最大同時打開并發流的個數,默認為5。
discovery.zen.minimum_master_nodes: 1
設置這個參數來保證集群中的節點可以知道其它N 個有master 資格的節點。默認為1,對于大的集群來說,可以設置大一點的值(2-4)
discovery.zen.ping.timeout: 3s
設置集群中自動發現其它節點時ping 連接超時時間,默認為3 秒,對于比較差的網絡環境可以高點的值來防止自動發現時出錯。
discovery.zen.ping.multicast.enabled: false
設置是否打開多播發現節點,默認是true。
discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]
設置集群中master 節點的初始列表,可以通過這些節點來自動發現新加入集群的節點。例如:discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9302","127.0.0.1:9304"] 配置了三個節點
?ES 集群配置文件配置
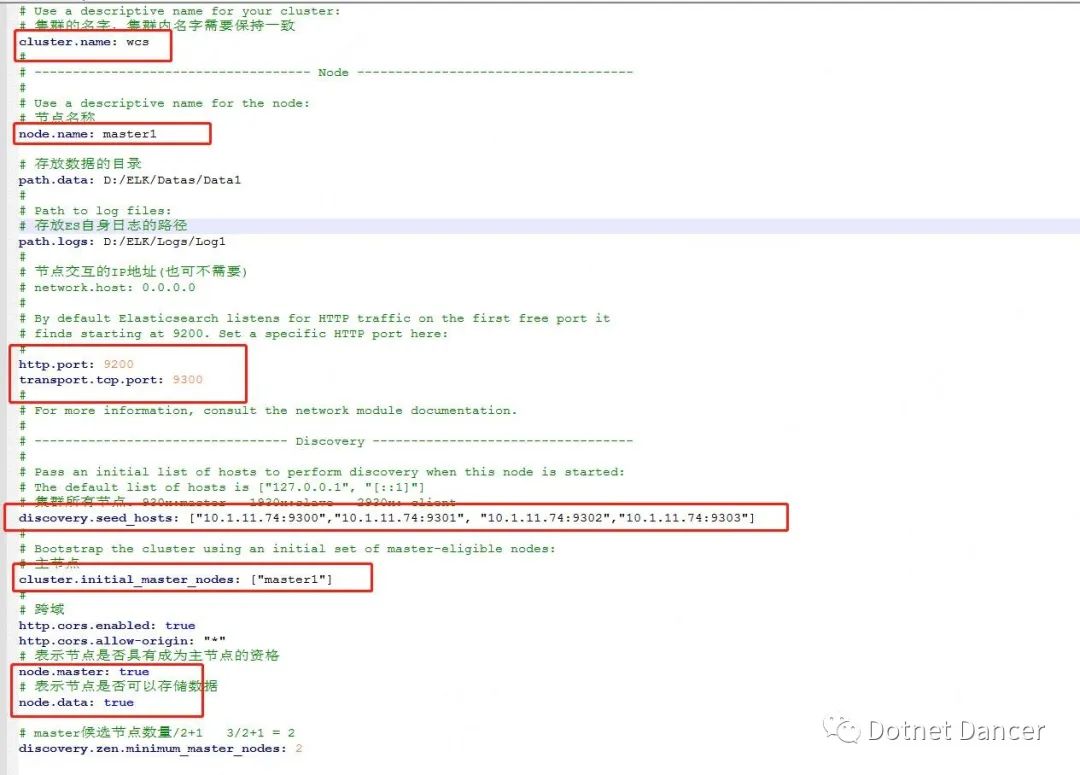
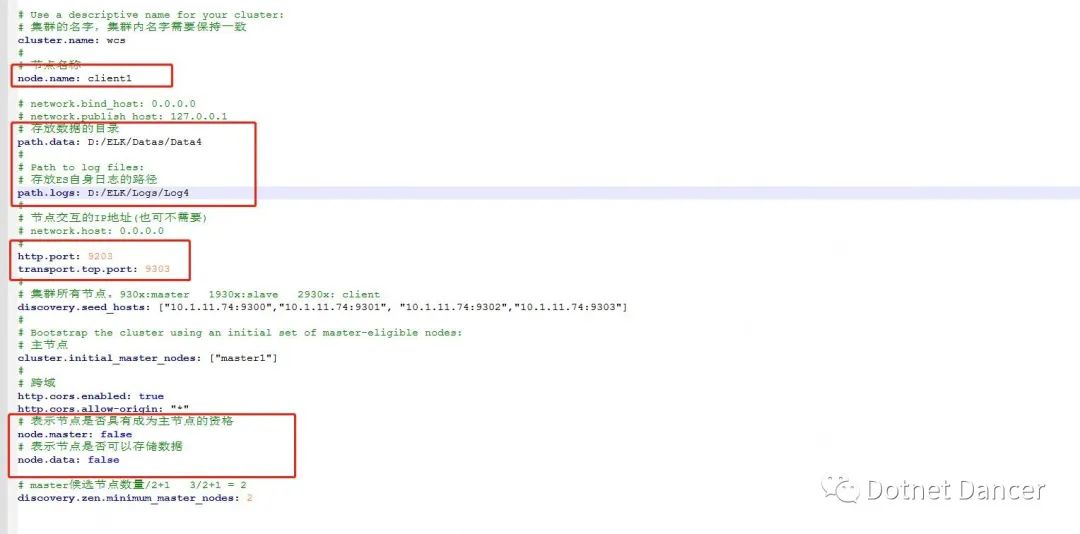
集群配置,采用3+1 的部署方案,包括3 個可選主節點,以及1 個客戶端節點。
其中:
cluster.name 的值保持一致
node.name 的值,可自定義,此處默認可以成為主節點的節點名稱為master1 master2和master3
path.data 和path.log 用來存儲es 節點存儲的數據和自身日志的路徑使用。
path.data 的值不能一樣,不同的節點,存儲的地址需要分開,否則會報錯。data 路徑用于存放我們發送
給es 的數據所存儲的路徑位置。
http.port 默認為9200,用于外部訪問es 使用;四個節點,端口號此處分別設置為9200、9201、9202、9203。其中9203 端口號用于分配給client 使用。
transport.tcp.port 默認為9300,用于內部集群間通信使用;四個節點,端口號此處分別設置為9300,9301,9302,92303。其中9303 用于client 節點使用。
discovery.seed_hosts 記錄的是這四個集群節點的內部通信地址,我本地局域網內的一臺服務器為10.1.11.74,所以我此處為了好分辨,就全部寫成10.1.11.74 的地址。生產環境下,可以根據實際情況修改為生產環境的ip 地址。
警告:如果es 部署在同一個服務器上,請默認使用127.0.0.1 這個ip,其他ip 可能會受到防火墻限制。例如上面我寫的10.1.11.74 的ip,后面就會有集群關連失敗的情況。
cluster.initial_master_nodes 此處默認主節點設置為master1,當然也可以設為master2或者3,但是不能是client,因為client 不能當做主節點。
node.master 和node.data,3+1 集群模式下,【master 節點的值全是true】,【client
節點的值全是false】。
以下是我先前做的一個master1 的配置文件截圖:
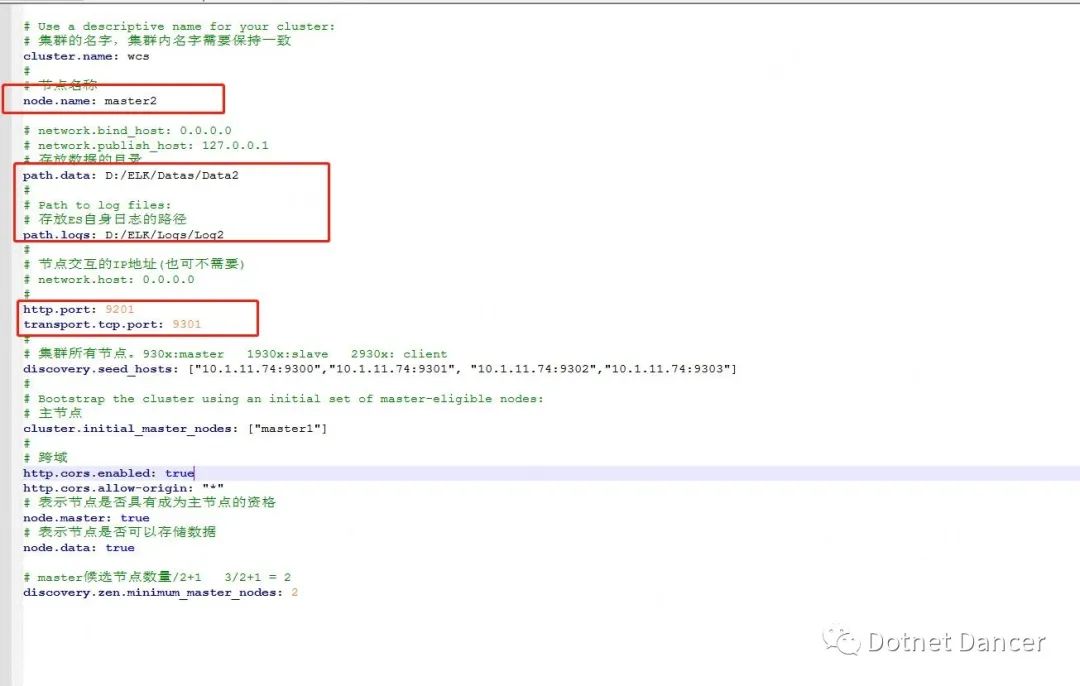
以下是master2 的配置文件截圖,可以和以上的master1 的配置文件進行比對查看不同點。master3 節點以此類推。
以下是client 節點的配置文件截圖,可以和master 節點進行比較差異點。Client 節點不進行主節點的選舉,也不進行存儲數據,僅用于負載均衡,用于對3 個主要節點進行壓力分解的作用使用。
Jvm.options 環境配置
Jvm.options 文件在config 文件夾下
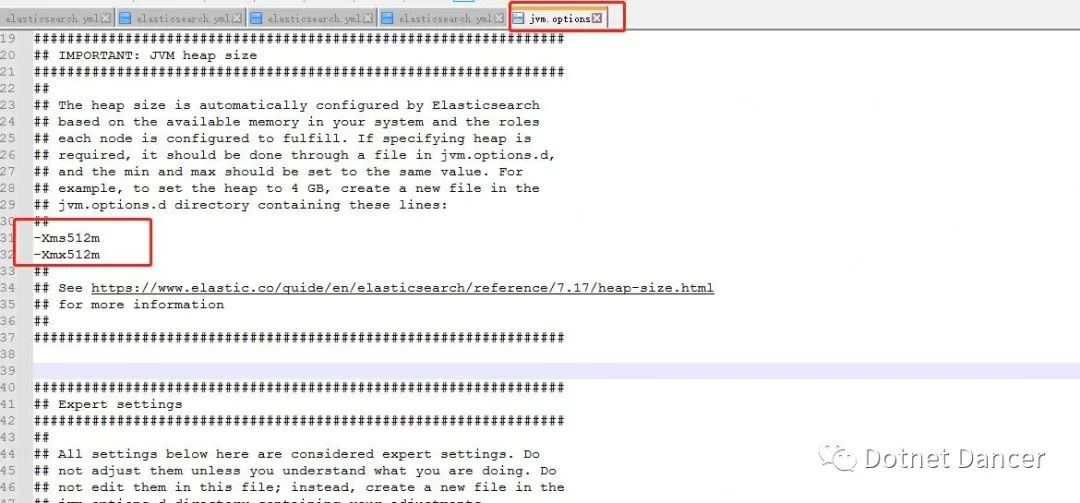
該路徑下用來配置單個ES 的內存分配規則。最低可以配置512m,最高32g 此處以最高和最低內存使用量都是512m 來配置(公司云服務器配置太低,沒辦法~)。如果是g 為單位,注意都是小寫,并且不帶b,例如Xms512m Xmx4g 等等。Xms 代表最低分配內存,Xmx 代表最大分配內存。
以此類推,把4 個es 的內存都設置一下。
警告:以上512m 只是因為我本地的局域網內的服務器上的配置比較低,所以在生產環境下,請配置大一點,例如,一臺64GB 內存的服務器,以3+1 部署模式進行部署的情況下,最大可以對每個節點
分配(64/2)/5 ≈ 6g 的最大值,其中5 代表的是4 臺es 和一臺logstash。ELK 的總內存最大
占用建議不要超過服務器總內存的一半,留點面子。
?通過bat 文件啟動es 集群進行初始驗證
進入到四個es 的根目錄下(esxxx/bin),打開cmd,執行elasticsearch.bat 文件:
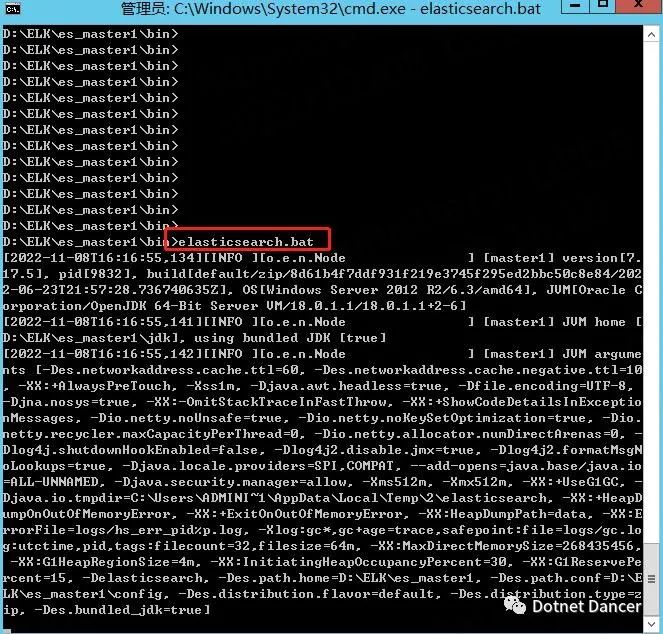
啟動以后,瀏覽器輸入localhost:端口號,例如master1 的端口號是9200,啟動成功會有一段簡單的提示信息,包括節點名稱、集群名稱,es 版本等等:
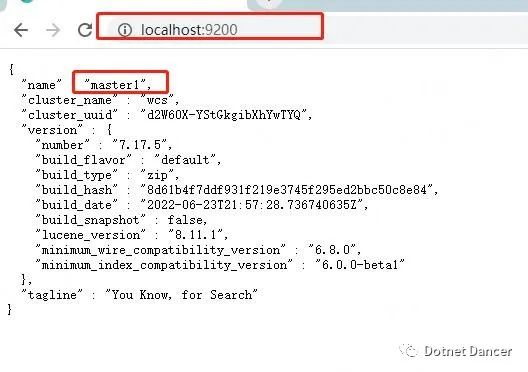
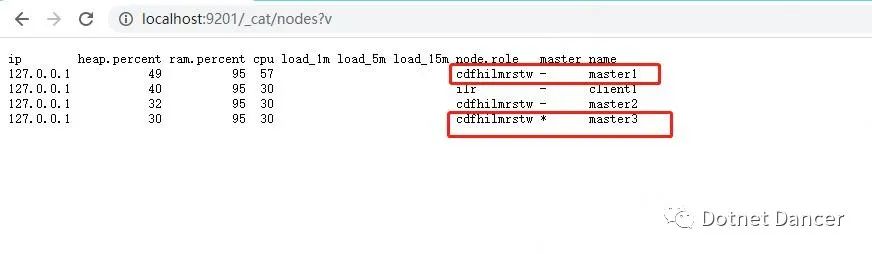
四個es 都啟動成功以后,瀏覽器輸入http://localhost:9200/_cat/nodes?v
可以看到集群內部的活動以及主節點信息。當然,上面的ip 和端口號改成任意集群內
的一個節點的地址,都可以查出來。其中master1 為現在的主節點。
做個測試,測試主節點宕機以后的效果。(以下內容僅用于測試觀看,可以直接跳過)
停止master1 節點,看看情況。
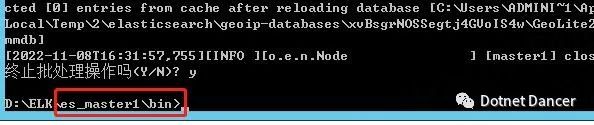
刷新一下頁面,可以看到少了一個master1,然后master3 被自動選舉為主節點。
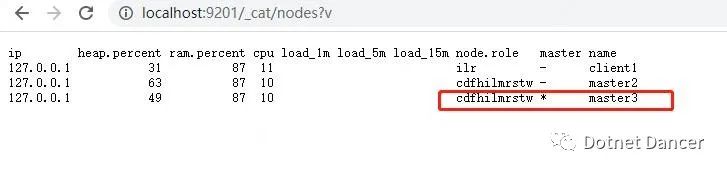
重新啟動master1 節點,看下效果。如圖所示,master1 自動成為了子節點,這個就是集群的魅力,掛了一個一點都不慌。
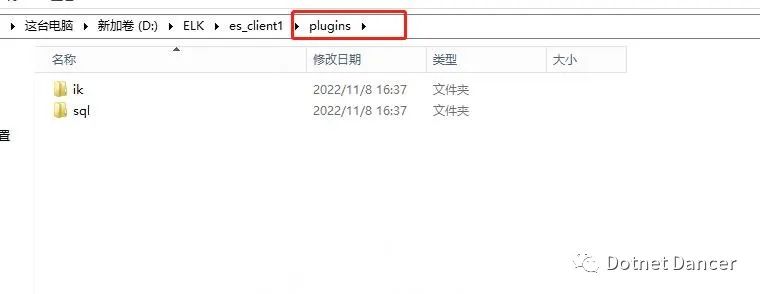
?集成sql 插件和ik 插件
在所有的es 的plugins 文件夾下,新建兩個文件夾,分別是sql 和ik
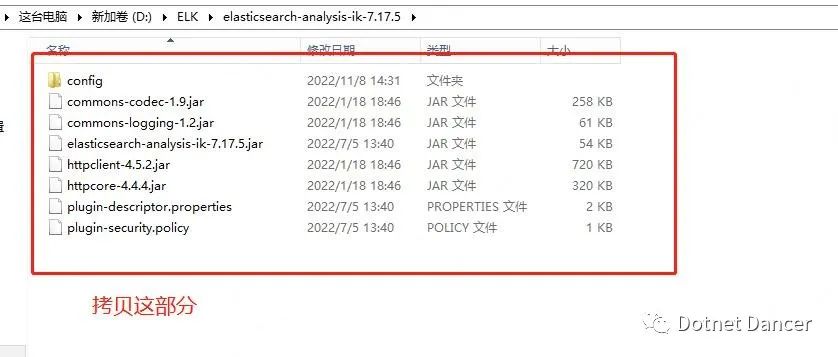
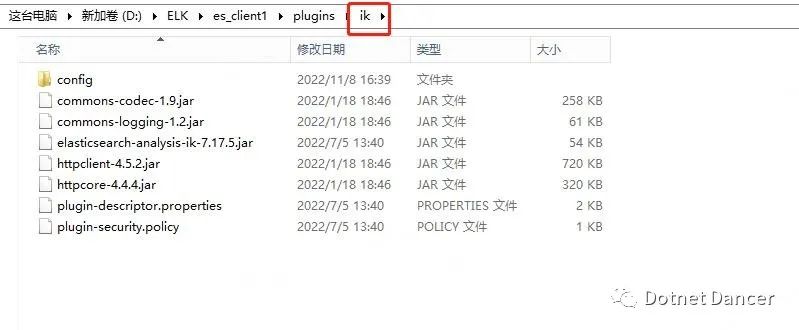
把ik 解壓后的內容,全部拷貝到各個es 都ik 文件夾下:
From
To:
ik 說明:如果有某個關鍵詞匯查不出來,就可以在ik 分詞里面進行新增,例如“老吳”。
新增說明:在ik 的config 目錄下,任意找一個詞字典,在最后進行添加有關詞匯。
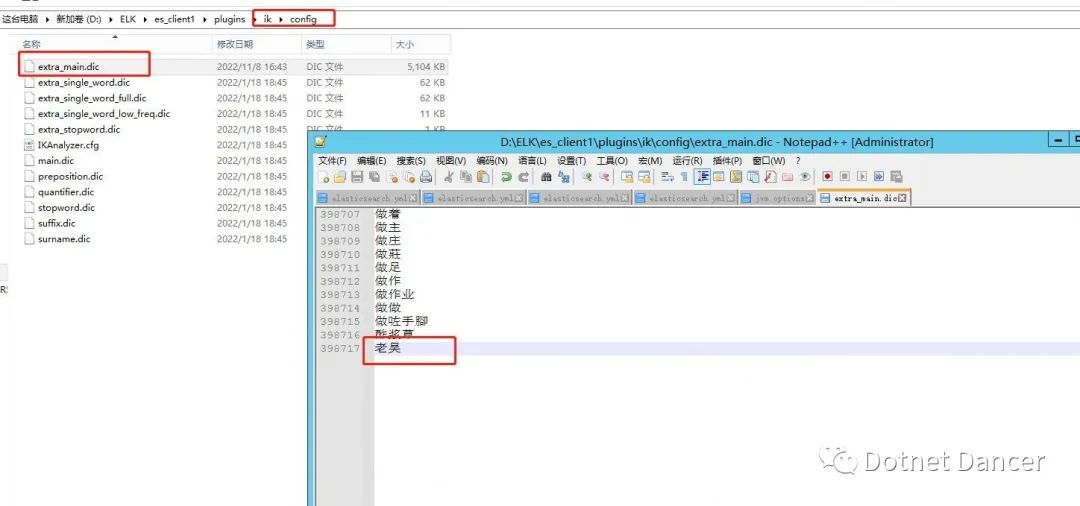
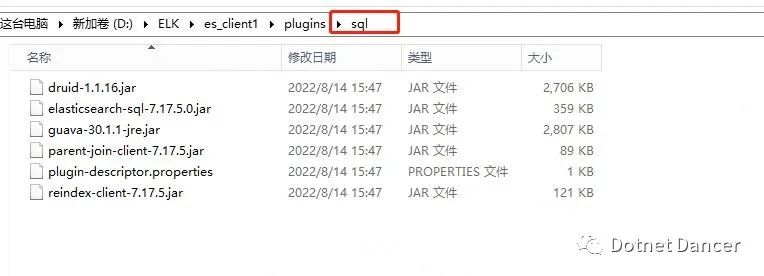
把sql 解壓后的內容,全部拷貝到各個es 都sql 文件夾下:
From:
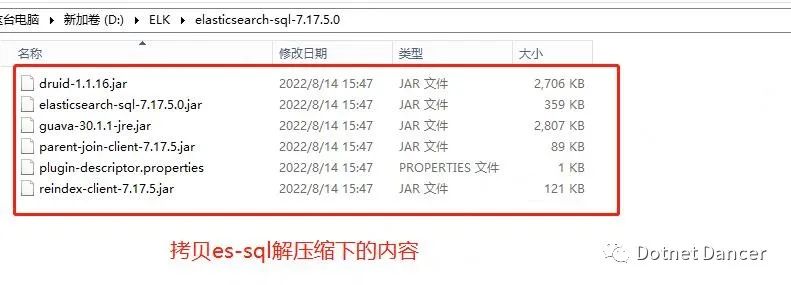
To:
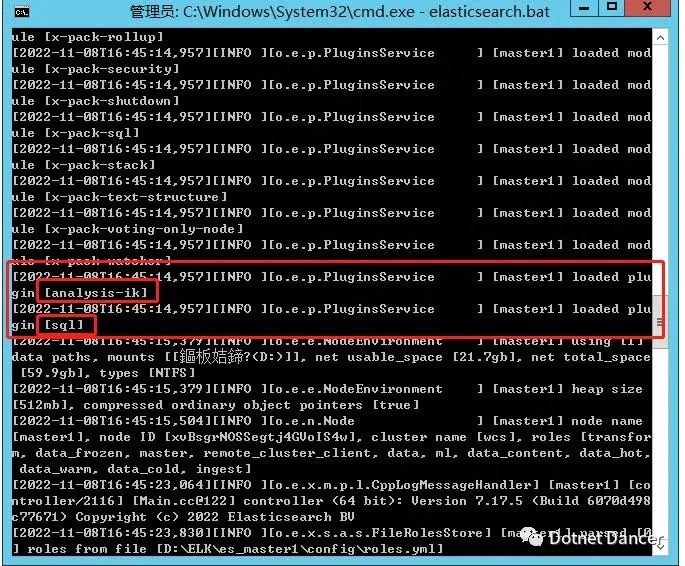
添加完成以后,通過bat 啟動時候,可以看到有關的加載信息:
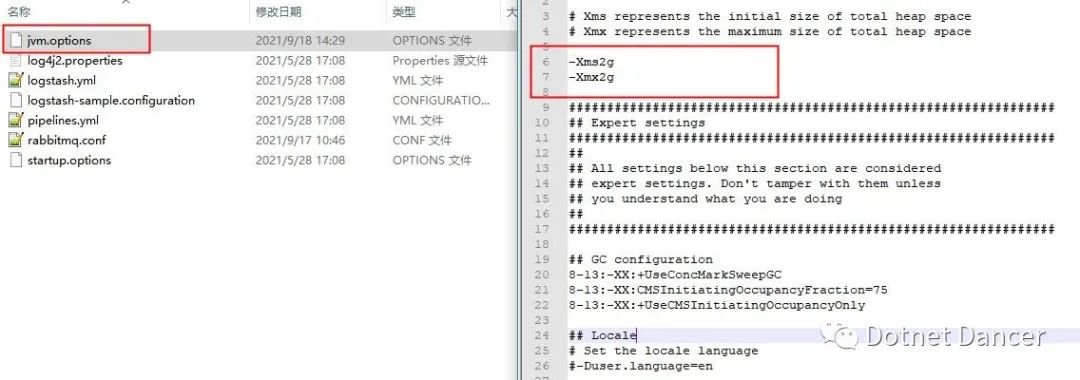
logstash 的jvm 配置
Logstash 的jvm 配置,同elasticsearch 配置,也需要配置最大內存和最小內存的臨界值。
此處寫的是2g,我改為了512m(自行根據個人服務器配置進行設置)
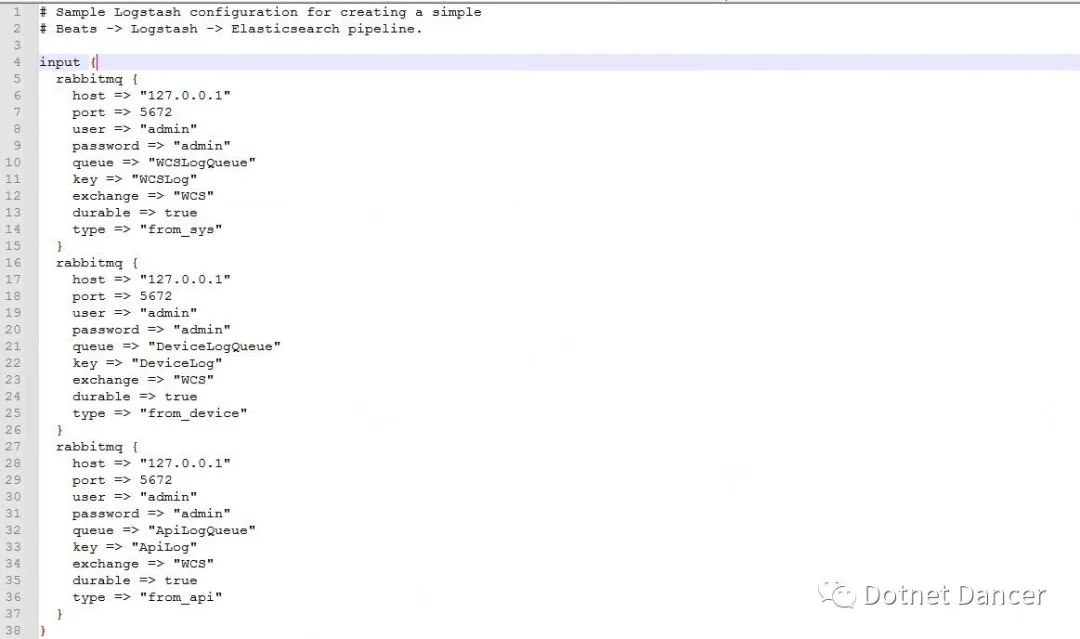
logstash 的config 配置文件設置
config 文件用于指定logstash 使用何種方式進行監聽數據流的輸入和輸出功能,當前使用監聽RabbitMQ 的方式來監聽日志數據流,然后進行轉存到ElasticSearch 數據庫上。
以下截圖為預設置的配置文件接收端(config 目錄下的rabbitmq.conf 文件),預設三個監聽數據來源的隊列信息。采用direct 模式,并且指定不同的日志內容走不同的隊列,例如我之前項目上使用的WCSLog、DeviceLog、ApiLog 等,配置信息可以當做參考。
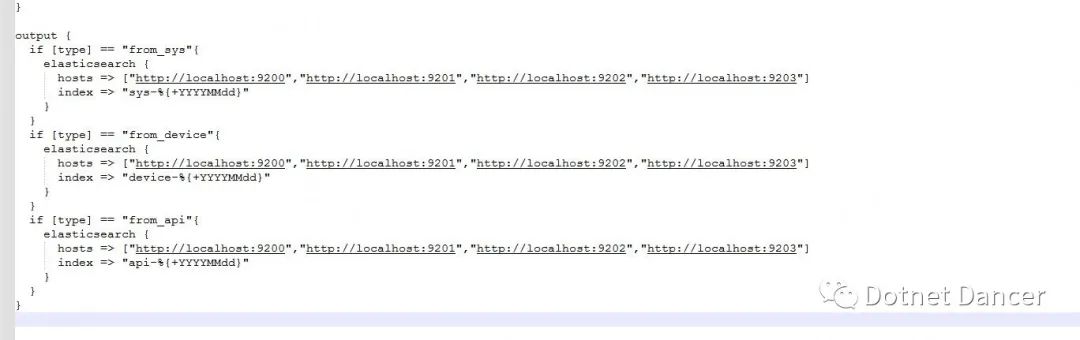
以下截圖配置的是每天新增一個索引,分別以sys、device、api 開頭。
注意事項:RabbitMQ 里面必須已經存在以上的隊列以后,才可以啟動logstash,否則會啟動失敗。正確做法是,先啟動你的程序,初始化一下或者創建一下MQ 有關的隊列信息以后,再啟動Logstash。
?Kinaba 配置
打開kibana 根目錄下的config 文件夾,下面的kibana.yml 配置文件進行配置。
Kibana 配置比較簡單,此處只配置三個地方:
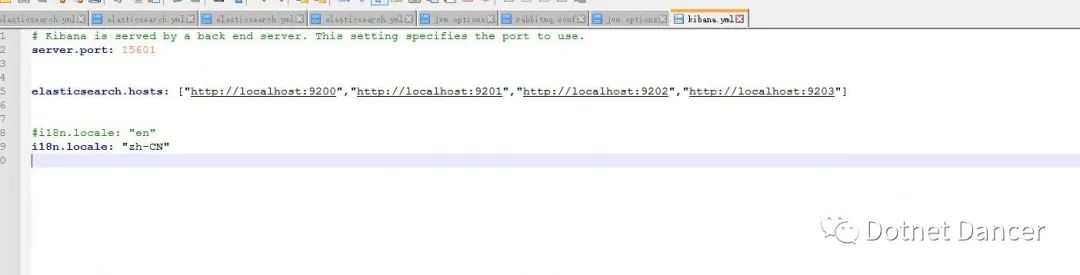
其中,server.port 是對外開放的端口號,默認是5601,此處改成了15601,防止被人隨
意登錄。
然后是es.hosts,有多少es 的節點,就都配上去。
還一個是il8n.locale 是默認的語言類型,默認是en 英語,此處我們改為zh-CN 中文。
本公眾號文章原文地址是:https://www.cnblogs.com/weskynet/p/16890741.html
如果公眾號內顯得圖片比較小,也可以轉場去網上看博客原文。
快速開發MQ生產者和消費者基礎服務
新建一個webapi項目進行測試。并添加引用:Wesky.Infrastructure.MQ
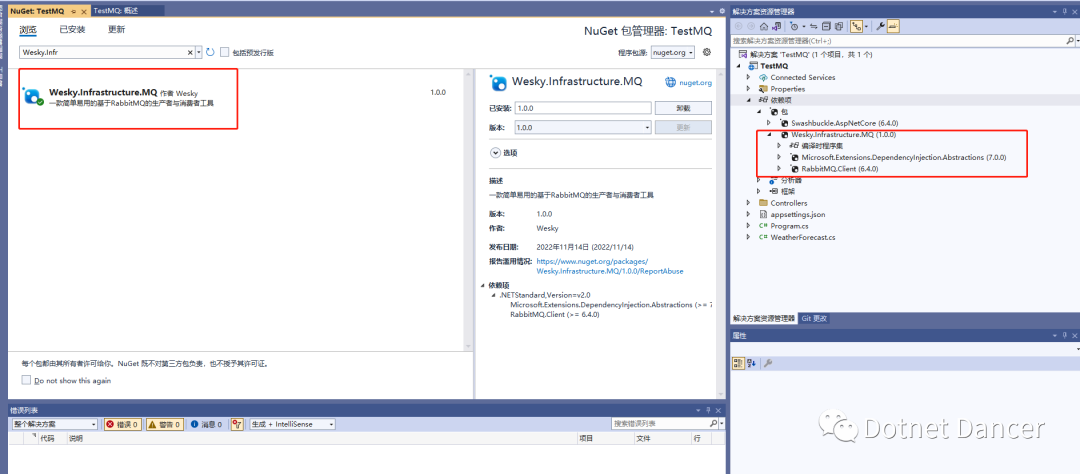
其中,這個包是我寫的一個比較通用的基于DIRECT模式的簡易版MQ生產者和消費者基礎功能服務,也可以直接拿來做MQ的業務對接開發。
然后,在program.cs里面,添加對WeskyMqService的注冊,里面注冊了基礎的生產者和消費者服務。
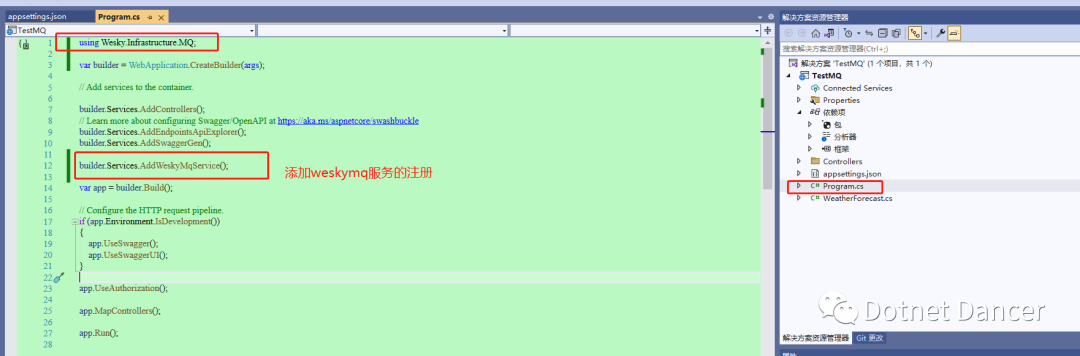
?咱新增一個消費者消息消費的方法ConsumeMessage以及有關interface接口,該方法后面用來當作回調函數使用,用來傳給MQ消費者,當監聽到消息以后,會進入到該方法里面。

?再然后,回到program里面,對剛才新增的方法進行依賴注入的注冊;以及在里面做一個簡單的MQ隊列的配置信息。
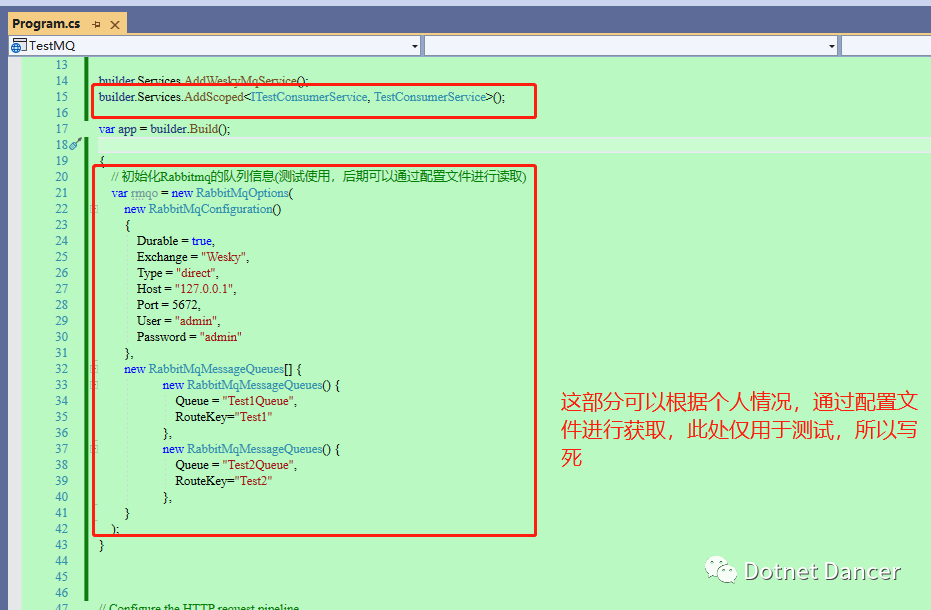
?其中,RabbitMqOptions構造函數帶有兩個參數,分別是
RabbitMqConfiguration:它傳入MQ的連接
RabbitMqMessageQueues[]:路由鍵以及對應的隊列名稱數組,有多少個隊列,數組元素就是多少個一一對應。
以上創建了基礎的連接,通過direct模式進行消息訂閱和發布;并且創建兩個隊列,分別是Test1和Test2
再然后,新建一個API控制器,并提供有關依賴注入進行實現的驗證。

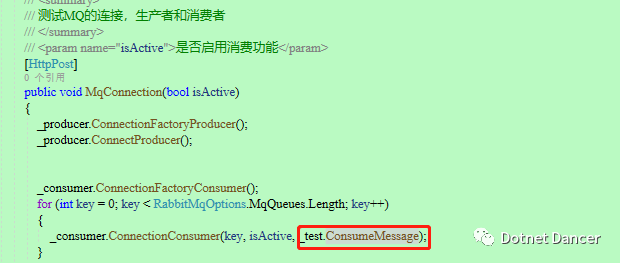
為了方便測試,新增兩個api接口,用來檢測MQ的連接以及消息發布和訂閱。

?其中,index此處的作用是咱們配置的消息隊列的隊列數組里面的下標。
連接參數isActive代表是否消費者消費消息,如果不消費消息,那么就可以用來給我們上面的logstash來消費了;如果消費消息,那么消息就會進入到我們剛才創建的ConsumeMessage方法里面去,因為它通過回調函數參數丟進去了:
打開MQ面板,可以看到現在是都沒有隊列存在的。
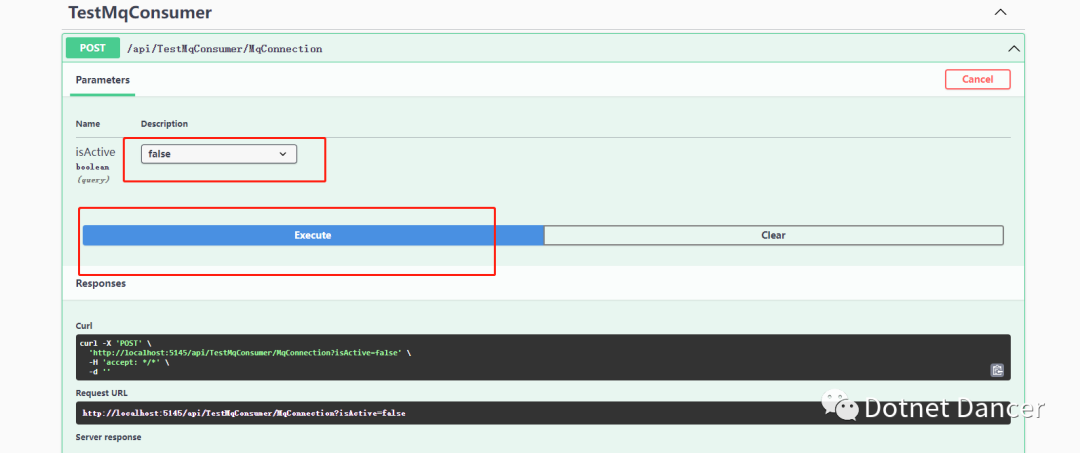
?此時啟動程序,先調用連接的API(API里面,包括了生產者連接和消費者連接,平常如果只需要連接一個,也是可以屏蔽其他的,例如與第三方MQ做信息通信的話),再調用發布消息的API,查看效果。咱先做一個不消費(允許消費參數設為false)的例子:
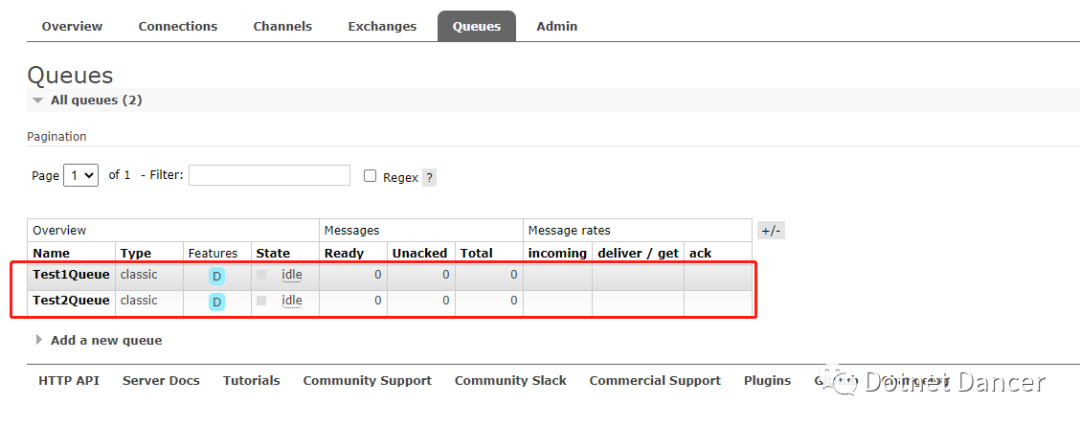
?然后再查看MQ面板,可以看到多了兩個隊列,這兩個隊列就是代碼里面連接以后自動創建的:
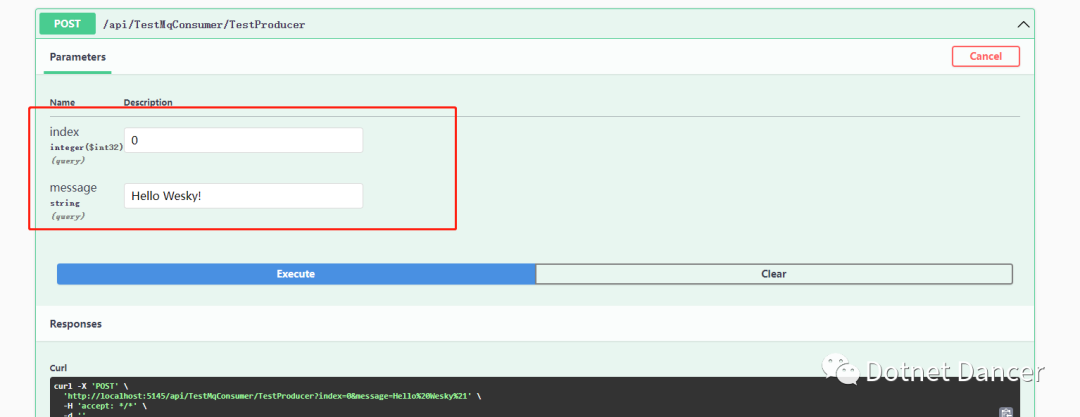
?調用生產者,發布一條消息,例如發給數組的第一個隊列一條消息:
?因為不允許消費,所以消息會一直在隊列里面沒有被消費掉:
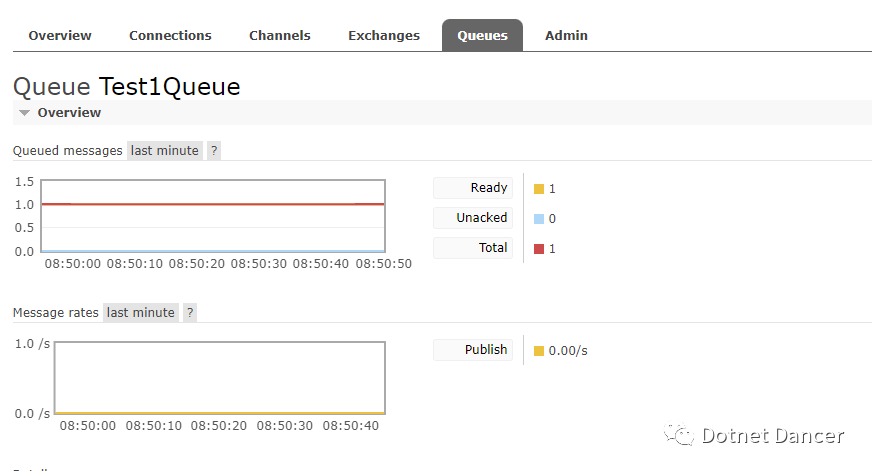
我們先關閉api程序,然后重新做個連接,做成允許消費的,看下效果:
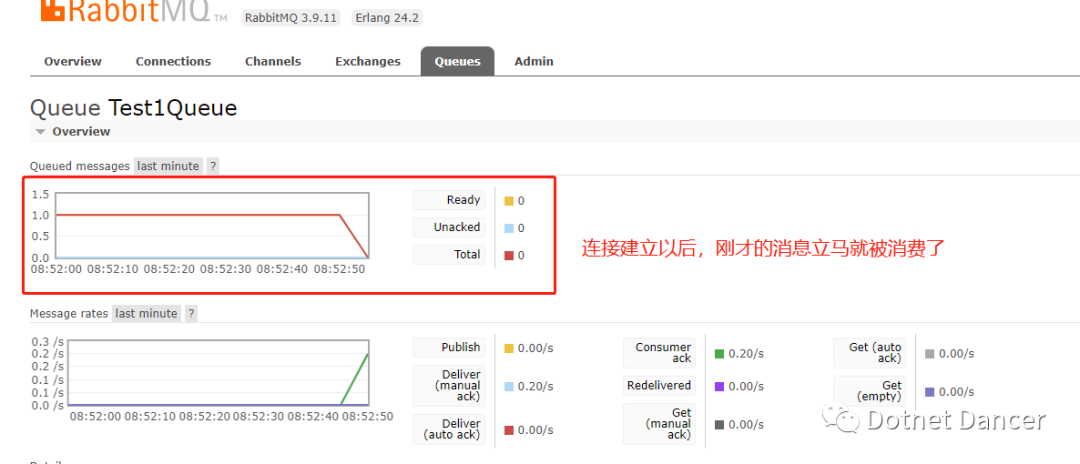
?再切換到MQ面板,可以看到消息立馬被消費了:
?我們剛才寫的一個輸出控制臺的消費消息的業務方法,此時也被執行了:

以上說明MQ的生產者與消費者服務是OK的了。然后就可以與上面的EKL集群進行配合使用,例如你的程序需要通過MQ的方式給Logstash發送消息,那么就可以使用傳入不啟用MQ客戶端消費的功能來實現;如果需要與其他生產者對接,或者需要做MQ消息消費的業務,就可以通過類似方式,寫一個回調函數當作參數丟進MQ消費者服務里面去即可。
最后,ELK上面我沒做其他的優化,大佬們感興趣可以自己優化,例如信息的壓縮、定時刪除等等,這些都可以在Kibana的管理界面里面進行配置。
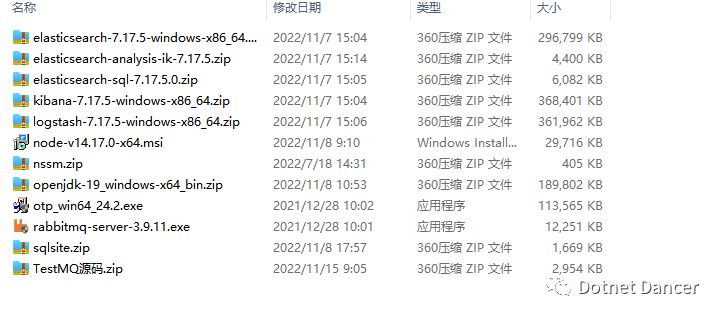
如果需要以上的環境全套資源、以及后面的MQ的例子,可以掃碼關注以下公眾號,或者搜索【Dotnet Dancer】關注公眾號,發送【ELKQ】即可獲取。

公眾號聊天框內回復【ELKQ】可以獲取的工具環境、內容等,見下圖:






![MASA MAUI Plugin (六)集成個推,實現本地消息推送[Android] 篇](http://pic.xiahunao.cn/MASA MAUI Plugin (六)集成個推,實現本地消息推送[Android] 篇)

)







Java springcloud B2B2C o2o多用戶商城 springcloud架構- Spring Cloud構建分布式電子商務平臺...)
)

