一、GBDT的通俗理解
提升方法采用的是加法模型和前向分步算法來解決分類和回歸問題,而以決策樹作為基函數的提升方法稱為提升樹(boosting tree)。GBDT(Gradient Boosting Decision Tree)就是提升樹算法的一種,它使用的基學習器是CART(分類和回歸樹),且是CART中的回歸樹。
GBDT是一種迭代的決策樹算法,通過多輪迭代,每輪學習都在上一輪訓練的殘差(用損失函數的負梯度來替代)基礎上進行訓練。在回歸問題中,每輪迭代產生一棵CART回歸樹,迭代結束時將得到多棵CART回歸樹,然后把所有的樹加總起來就得到了最終的提升樹。下面是一個簡單的示意圖。
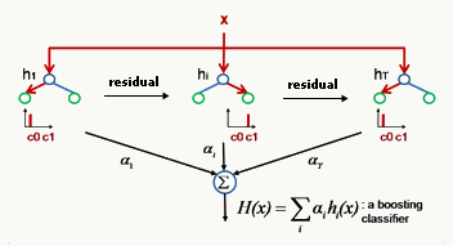
?
看到這個闡述還是很懵對不對?對于初次接觸的人,應該是這種感覺。沒關系,我們一步一步來分析這個闡述中所涉及到的關鍵詞。
要理解GBDT,那么需要理解兩個主要的概念:回歸樹(DT, 即Regression Decision Tree)和梯度提升(GB, 即Gradient Boosting)。
1、理解回歸樹
GBDT中的樹都是CART回歸樹,不是分類樹,因為GBDT的核心在于累加所有樹的結果作為最終結果,而只有回歸樹的結果可以累加,分類樹的結果進行累加是沒有意義的。盡管GBDT調整后也可以用于分類,但這不代表GBDT中用到的決策樹是分類樹。
由于GBDT的學習過程是通過多輪迭代,每次都在上一輪訓練結果的殘差的基礎上進行學習,于是要求基學習器要足夠簡單,具有高偏差、低方差的特點。GBDT的基學習器是CART回歸樹,由于高偏差和簡單的要求,每棵CART回歸樹的深度不會很深。
訓練的過程就是通過降低偏差來不斷提高最終的提升樹進行分類和回歸的精度,使整體趨近于低偏差、低方差。最終的提升樹就是將每輪訓練得到的CART回歸樹加總求和得到(也就是加法模型)。
2、理解梯度提升
在理解GBDT中的梯度提升之前,首先要明白,提升樹的每次迭代,就是用一棵決策樹去擬合上一輪訓練的殘差,而之前所有樹的預測值的累加值,加上這個殘差就等于真實值。比如A的真實年齡是18歲,第一棵樹預測的年齡是12歲,那么殘差是6歲,6歲作為第二棵樹學習的目標。如果第二棵樹的預測年齡是5歲,那么殘差等于真實年齡減去這兩棵樹的預測值之和(18-12-5),即為1。于是第三棵樹中A的年齡變成了1歲,繼續去學習,越來越逼近18歲這個目標。如果恰巧在第m棵樹時,殘差為0,那么累加這m棵樹預測的年齡,就和真實的年齡完全相等了。
但是有個問題是損失函數各種各樣,對各種損失函數的殘差進行擬合并不容易,怎么找到一種通用的擬合方法呢?
于是在GBDT中,就使用損失函數的負梯度作為提升樹算法中殘差的近似值,然后每次迭代時,都去擬合損失函數在當前模型下的負梯度。這就找到了一種通用的擬合方法。
?
二、GBDT的推導過程
(一)提升樹算法
開頭介紹了,提升方法采用的是加法模型和前向分布算法來解決分類和回歸問題,而以決策樹作為基函數的提升方法稱為提升樹(boosting tree)。
那么提升樹算法的大致情況是:
(1)模型為決策樹的加法模型
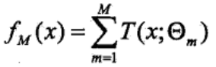
其中T(x; θm)表示決策樹,θm為決策樹的參數,M為樹的個數。
(2)算法為前向分步算法
首先確定初始提升樹f0(x)=0,經過迭代得到第m步的模型為:
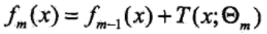
其中fm-1(x)為當前模型,而θm則通過經驗風險極小化來確定,從而得到fm(x),即最小化損失函數:
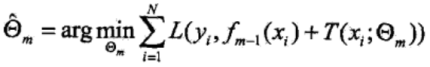
(3)由前向分步算法得到M棵決策樹T(x; θm)后,再進行加總,就得到了提升樹模型fM(x)。
分類問題中決策樹是二叉分類樹,回歸問題中決策樹是二叉回歸樹。在不同的問題中,損失函數的形式不同,分類問題一般選擇指數損失函數,回歸問題則選擇平方誤差損失函數。?
(二)GBDT推導
在提升方法中,我之前學習了AdaBoost算法,這里又來了提升樹和GBDT,讓人有點頭疼。那么這三者的大致關系是什么樣的呢?
在二類分類問題中,如果提升樹算法選擇二類分類樹,并且損失函數選擇指數損失函數,那么這個提升樹算法就是AdaBoost算法的一個特例。GBDT盡管必須使用回歸樹來構建,但是它也可以用于分類問題;GBDT在解決分類問題時有兩種辦法,一個是選擇指數損失函數作為損失函數,此時GBDT退化為AdaBoost算法,另一個是選擇類似于邏輯回歸的對數似然損失函數。
此外,GBDT就是提升樹的一種,可以用于回歸問題,它使用的基學習器是CART(分類和回歸樹),且是CART中的回歸樹,損失函數一般選擇平方誤差損失函數。它的特點在于gradient,也就是用損失函數的負梯度作為提升樹算法的殘差的近似值去擬合回歸樹,讓損失函數沿著梯度方向下降。
于是理解GBDT要分為兩步,第一步是理解什么叫做用決策樹去擬合當前模型的殘差,第二步是理解為什么以及如何用損失函數的負梯度去替代當前模型的殘差。
1、回歸問題的提升樹算法
步驟一:已知訓練數據集T={(x1, y1),(x2, y2),..., (xN,yN)}, xi∈χ∈Rn,yi∈γ∈R,損失函數選擇平方誤差損失函數。確定初始提升樹f0(x)=0。
步驟二:對于m=1, 2, ..., M,采用加法模型和前向分步算法,循環地進行下面的計算:
(1)將輸入空間X劃分為J個互不相交的區域R1, R2, ..., Rj,并且在每個區域上確定輸出的常量cj,那么決策樹可以表示為:
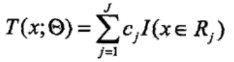
其中,參數Θ={(R1,c1),(R2,c2),...,(RJ,cJ)}表示樹的區域劃分和每個區域上的輸出值。J表示回歸樹的葉節點的個數。
(2)當前模型為fm-1(x),預設fm(x)=fm-1(x)+T(x;Θm),由經驗風險最小化來求解fm(x)中的參數Θm,即求解:
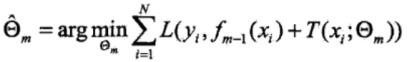
由于損失函數具體選擇的是平方誤差損失函數,所以損失函數為:
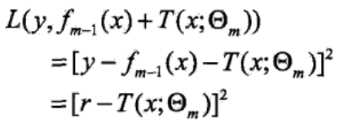
而當前模型擬合數據的殘差(residual)為:r = y - fm-1(x),所以實際上,就是用一個決策樹去擬合當前模型的殘差r,得到參數Θm和決策樹T(x;Θm)。
(3)更新提升樹fm(x)=fm-1(x)+T(x;Θm)。
步驟三:得到M個決策樹后,根據加法模型,得到回歸問題的提升樹:
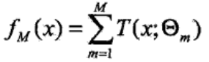
2、GBDT回歸算法的負梯度擬合
上面得到了回歸問題的提升樹算法,為什么還要提出個GBDT算法?原因在于回歸問題的提升樹算法采用加法模型和前向分步算法來進行優化求解,但每一步優化過程其實并不容易求解。當損失函數取平方誤差損失函數和指數損失函數時,每一步的優化還算簡單,可是如果損失函數是其他一般損失函數時,那可就難了。而回想邏輯回歸中的求解過程,是用梯度下降法來簡化了優化過程,因此有學者(Friedman)就想到了用梯度提升(gradient boosting)的方法來近似求解提升樹的優化問題,這樣就找到了一個通用的解決辦法,適用于各種不同類型損失函數的情形。這就是為什么提出了GBDT的原因。
而GBDT這個算法中最關鍵的一點就是用損失函數在當前模型中的負梯度值,即:
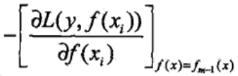
作為回歸問題提升樹算法中殘差的近似值,再用一棵CART回歸樹去擬合這個負梯度值,從而得到下一棵CART回歸樹。
所以GBDT回歸算法的求解過程如下:
步驟一:已知訓練數據集T={(x1, y1),(x2, y2),..., (xN,yN)}, xi∈χ∈Rn,yi∈γ∈R。初始化提升樹:

c是第一個決策樹的輸出值。
步驟二:對于m=1,2,..., M,循環對以下過程進行計算:
(1)對于i=1, 2, ..., N,計算提升樹fm-1(x)的負梯度:
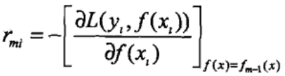
(2)對負梯度rmi擬合一棵CART樹,得到第m棵樹的葉結點區域Rmj,j=1,2,..., J。
(3)對于j=1, 2, ..., J,使損失函數最小,計算每個區域Rmj上的最優輸出值:
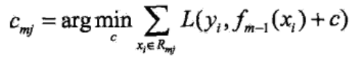
從而得到本輪擬合的決策樹:
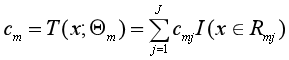
(4)更新提升樹fm(x),然后回到(1)繼續求負梯度。
 ?
?
步驟三:求得M棵CART回歸樹后,加總得到最終的回歸樹

從回歸樹的提升樹算法過渡到GBDT算法,理解起來就不那么難受了。GBDT通過損失函數的負梯度來擬合CART回歸樹,這是一種通用的近似替代殘差來擬合決策樹的方法,不管損失函數取什么類型,都可以用這種方法。
3、GBDT的特征選擇
GBDT的基學習器選擇的是CART回歸樹,所以GBDT的特征選擇過程其實就是CART回歸樹的特征選擇問題。
CART回歸樹是一棵二叉樹,它在訓練數據集所在的輸入空間中,選擇最優切分變量和切分點,遞歸地將每個區域劃分為兩個子區域,并決定每個子區域上的輸出值。假設訓練數據集中的實例有J個特征,于是首先要選擇一個最優的特征j,作為二叉樹的第一個節點。再對特征j的值選擇一個最優的切分點s,將輸入空間劃分為兩個子區域。具體是通過求解以下的公式來得到最優的特征j和切分點s:

過程據說比較粗暴,就是先遍歷訓練樣本的所有特征,找到最優特征j后,固定特征j,掃描所有可能的切分點,找到最優的切分點s。
而找到了最優的特征j和切分點s后,對于特征值小于s的樣本,歸為第一類,特征值大于s的樣本,歸為第二類,就可以把輸入空間劃分為兩個區域:

就構建了二叉樹的兩個子節點。
?
三、GBDT用于分類
經過以上對回歸問題中GBDT算法的推導,GBDT這個神奇的模型在我腦中的輪廓漸漸清晰,褪去了原有的神秘感。可是我要繼續探索,學習GBDT如何應用于分類問題,畢竟分類問題實在太常見了。
GBDT的分類算法從思想上和GBDT的回歸算法沒有區別,但是由于樣本的輸出不是連續的值,而是離散的類別,一般用{-1, 0, 1, ...}這樣的整數表示,導致我們無法直接用樣本的輸出去計算殘差。
回想一下線性回歸和邏輯回歸,線性回歸是一種回歸算法,而邏輯回歸卻是一種分類算法。邏輯回歸用于分類的關鍵就在于邏輯回歸采用了sigmoid函數,得到了類別的預測概率分布,同時采用了對數似然損失函數。于是借鑒這種做法,在GBDT分類算法中,采用對數似然損失函數來計算殘差,并用對數似然損失函數的負梯度作為殘差的近似替代,然后用決策樹去擬合殘差。
1、二分類GBDT算法
在Friedman的論文中,他采用負二項對數似然損失函數(negative binomial log-likelihood)作為GBDT的損失函數:
![]()

他這個損失函數其實和邏輯回歸的損失函數是等價的,作者省略了一些步驟,推導過程附在本文的末尾。
?步驟一:對F(x)進行初始化
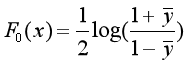
步驟二:對于m=1,2,..., M,循環進行以下的計算:
(1)求對數似然損失函數的負梯度:
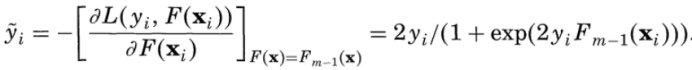
(2)對于第m棵樹的葉結點區域Rmj,j=1,2,..., J,使對數損失最小化,計算每個區域Rmj上的J個最優輸出值:
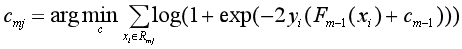
由于上面這個公式很難求,所以就用已經算出來的負梯度和牛頓-拉弗森迭代法(Newton–Raphson?)來近似求解:
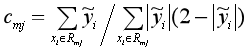
從而得到本輪擬合的決策樹:
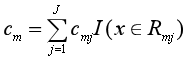
(3)更新Fm(x),然后回到(1)中求負梯度。
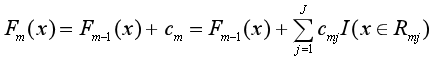
步驟三:求得M棵CART回歸樹后,加總得到最終的回歸樹
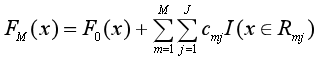
算法的流程整理得簡潔一些就是:
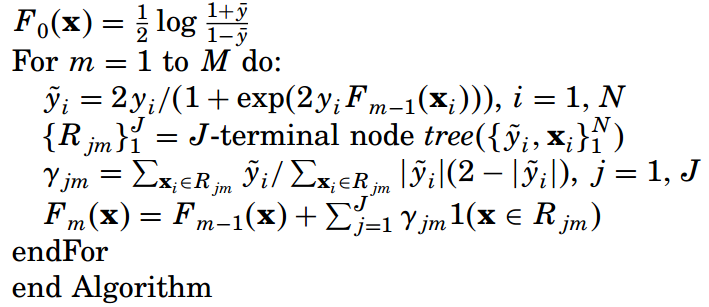
求出了用于分類的GBDT回歸樹后,盡可以計算實例屬于兩個類別中每一類的概率:

進而進行分類。
2、多分類GBDT算法
在二元分類GBDT中,我們用邏輯回歸來進行類比,而在多元分類GBDT中,就用softmax回歸來進行類比。Friedman選擇多元對數似然損失函數作為損失函數:
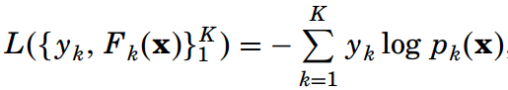
這里類別yk=1(類別=k)相當于一個指示函數,取值1或0,表示當類別為k時,yk=1。而Pk(x)=P(yk=1|x),表示類別為k的概率,用softmax來進行計算:

與二元分類的GBDT類似,由上面兩個公式,根據鏈式法則和softmax的簡便求導公式【(Pk(x))'=Pk(x)(1-Pk(x)),不過求出來還是不太一樣】,我們求出第m輪迭代中第i個樣本對應類別k的負梯度如下。負梯度的表達式清晰地表明了這是樣本i對應的類別k的真實概率yik和第m輪的概率預測值Pk,m-1(xi)的差值,也就是訓練的誤差。
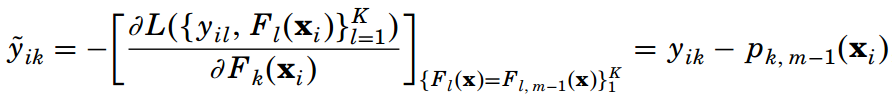
接下來在每一輪迭代中,都用K棵決策樹來擬合K個類別的訓練誤差。每棵決策樹都有J個葉節點,或者說劃分為了J個子區域 {Rjkm}Jj=1。然后求每棵樹在每個子區域上的最優輸出值:
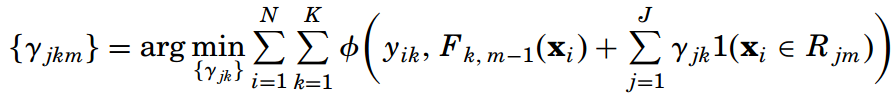
這里的函數Φ(yk, Fk) = -yklog(pk)。
同樣使用牛頓-拉弗森迭代法來簡化求解,得到最優輸出值的近似值:
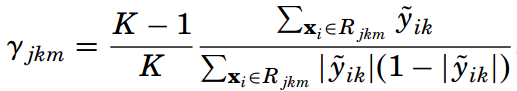
再通過下面的公式來更新K棵提升樹,然后繼續求負梯度,進行下一輪迭代:
![]()
把上面求負梯度、計算每棵樹的最優輸出值、更新提升樹的過程重復M次,最終得到K棵提升樹FkM(x):
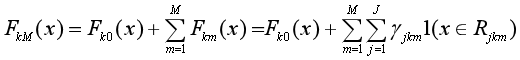
求出了K棵用于多元分類的提升樹FkM(x)后,對于每一個樣本x,都可以計算它屬于K個類別的概率分布,從而確定它所屬的類別。

多分類GBDT算法的流程整理如下:
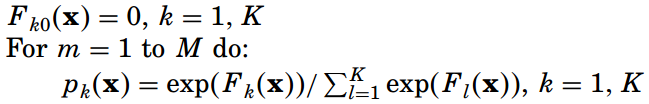
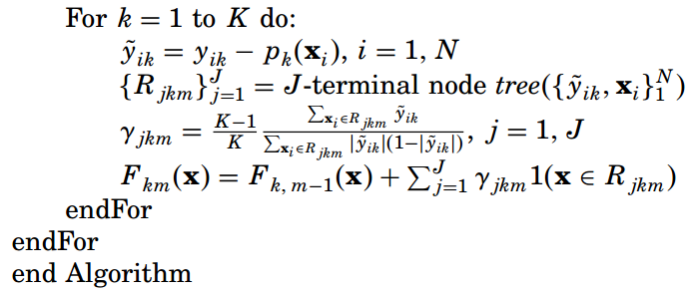
?
四、兩個小問題
看其他人的博客上分析了下面兩個問題,我感覺對于更深入地理解GBDT有一定幫助,所以摘錄在這里。
第一個問題,為什么GBDT要把CART回歸樹樹分成m棵二叉樹去求(每棵樹只有兩個葉子節點),而不是求一棵二叉樹,這棵樹有m+1(最多有2m個葉子節點)層呢?這是為了解決過擬合問題,因為在決策樹的剪枝算法中我們知道,只要允許一棵樹的葉子節點足夠多,那么訓練數據集總是能訓練到100%的準確率,但是模型的復雜度非常高,在測試數據上表現比較差。而GBDT把一棵樹拆成m棵樹,限制每棵樹只有兩個葉子節點,就可以解決過擬合問題。前面也說了,基學習器要具有簡單、高偏差和低方差的特點,因此每棵CART回歸樹的深度不會很深。
第二個問題是,為什么第m次學習的目標,是前m-1棵樹預測值的累加和的殘差?可以這樣理解,一方面通過分步求解,一步步逼近目標值,比一步到位要簡單;另一方面每一步的殘差計算其實變相地增大了被分錯的實例的權重,因為被分錯的實例其殘差較大,而已經分對的實例的殘差趨近于0。這樣后面的樹就能越來越專注于前面被分錯的實例了。
?
附:負二項對數似然損失函數的推導
考慮一個二項邏輯回歸模型,模型由條件概率分布P(Y|X)表示,隨機變量X取值為實數,而隨機變量Y取值為1或-1(注意一般邏輯回歸的Y取值為1或0)。
則二項邏輯回歸模型是如下的條件概率分布(參考《統計學習方法》第六章):
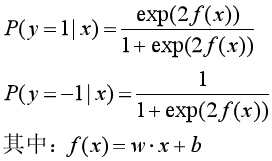
把條件概率分布統一為一個函數F(x):
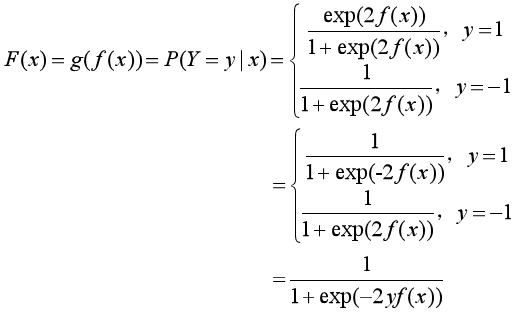
對數損失函數的標準形式為:
![]()
于是把F(x)的表達式代入對數損失函數中,得到:
![]()
再把f(x)用概率的形式表示:
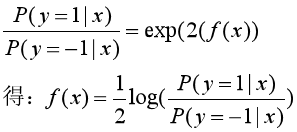
?
?
?
參考資料:
1、李航:《統計學習方法》
2、Friedman J H . Greedy Function:《Approximation: A Gradient Boosting Machine》
? ? ?我的分享:https://pan.baidu.com/s/1JBAA6qk6aPZIDUqkVlLYVg??提取碼:eyt4?
2、https://www.cnblogs.com/peizhe123/p/5086128.html
3、https://www.cnblogs.com/ModifyRong/p/7744987.html
4、https://www.zybuluo.com/vivounicorn/note/446479#24-bagging-and-boosting框架
5、https://www.cnblogs.com/pinard/p/6140514.html


![BZOJ 1047: [HAOI2007]理想的正方形 單調隊列瞎搞](http://pic.xiahunao.cn/BZOJ 1047: [HAOI2007]理想的正方形 單調隊列瞎搞)
















