1.bouding box regression總結:
rcnn使用l2-loss
首先明確l2-loss的計算規則:
L?=(f?(P)?G?)2,?代表x,y,w,h
? ?整個loss :?L=Lx+Ly+Lw+Lh
也就是說,按照l2-loss的公式分別計算x,y,w,h的loss,然后把4個loss相加就得到總的bouding box regression的loss。這樣的loss是直接預測bbox的
絕對坐標與絕對長寬。
改進1:
? 問題:如果直接使用上面的l2-loss,loss的大小會收到圖片的大小影響。
? 解決方案:loss上進行規范化(normalization)處理。
??Lx=(fx(P)?Gx)W)2,Ly=(fy(P)?Gy)H)2,Lw=(fw(P)?Gw)W)2,Lh=(fh(P)?Gh)H)2,其中,?W,H分別為輸入圖片的寬與高
? 這種改進沒有被采納
改進2:
??rcnn直接使用的是下面這個公式,也使用了規范化,但除以的是proposal的wh,并且wh的loss用的log函數
?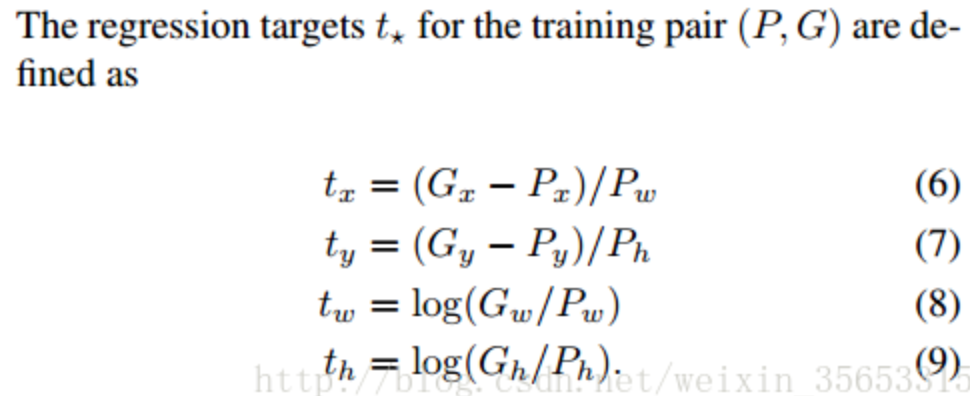
? cascade論文說這個改進的目的是:“To encourage a regression invariant to scale and location”,也就是增加scale和location的不變性 ?
? 位置不變性:delta_x = [(g_x + a) - (b_x + a)] / b_w。不管平移量a是多少,delta_x都是一樣的
? 尺寸不變性:delta_w = log((g_w * b) / (b_w * b))。不管圖片縮放b是多少,delta_w都是一樣的
?? 至于為什么用log,有個博客說是:是為了降低w,hw,h產生的loss的數量級, 讓它在loss里占的比重小些。? 這個解釋還有待觀察
改進3:
? 問題:當預測值與目標值相差很大時, 梯度容易爆炸, 因為梯度里包含了x?t
? 解決方案:smoothl1代替l2-loss,當差值太大時, 原先L2梯度里的x?t被替換成了±1, 這樣就避免了梯度爆炸
改進4:
? 問題:由于bouding box regression經常只在proposal上做微小的改變,導致bouding box regression的loss比較小,所以bouding box regression的loss一般比classification
? 的loss小很多。(整個loss是一個multi-task learning,也就是分類和回歸)
? 解決方案:標準化
??
?
延伸問題:iou-loss與l2-loss,smoothl1的優缺點
https://blog.csdn.net/weixin_35653315/article/details/54571681
?
2.性能上iou0.6大于iou0.5,但iou0.7卻小于0.5,為什么?
0.7的iou生成的正樣本的框的質量更高,應該性能更好,但ap值卻在下降。原因在于,iou在0.5時,正樣本大多集中在0.5到0.6之間,如果你閾值選在0.7,正樣本數量大大減少,造成了過擬合。
3.iterative bbox多次做bouding box的回歸,但每次回歸都使用的iou0.5,沒有考慮樣本分布改變;integral loss是根據不同iou分別算loss,沒有解決不同iou 正樣本的數量不一樣。cascade-rcnn與iterative bbox區別:1.每個stage進行了重采樣? ?2.訓練和測試的分布是一樣的
因此cascade的好處是:1.不會出現過擬合。每一個stage都有足夠的正樣本
? 2.每個stage用了更高的iou進行優化,proposal質量更高了
? 3.高iou過濾了一些outliers
4.對比實驗中的stat:就是為了解決分類loss大,bouding box regression loss小,將delta標準化的操作。
? cascade rcnn中的stat是每一次回歸都要做一次標準化,應該是因為每一次回歸生成的新分布的均值和方差發生變化
5.對比實驗1:
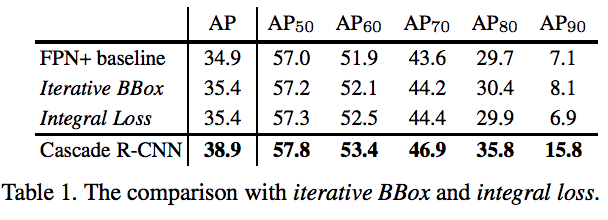
越高iou,cascade-rcnn提升越明顯,最常用的ap50的提升最小且提升性能有限
延伸問題1: 為什么iou越低的檢測性能會越低?
延伸問題2:? ?怎么去解決?
? 對比實驗2:
?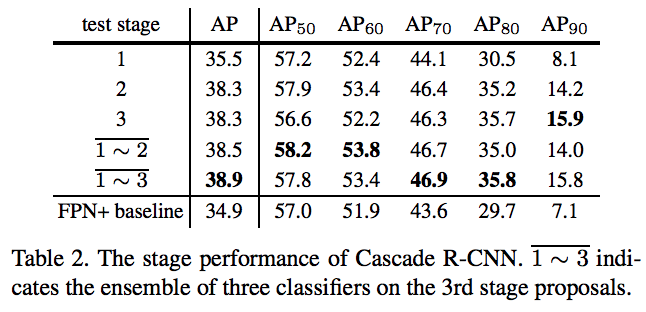
前提:這個實驗是都用訓練的時候用cascade rcnn,測試的時候在不同層測試和聯合測試做對比。
a.單獨在stage1上測試,性能比baseline要好,這是cascade的方式帶來的提升;單獨在stage2上測試性能提升最大,單獨stage3在ap70以下有略微下降,以上有略微上升
b.在stage1、stage2上聯合測試,ap70以下都獲得了最好的結果,ap70以上會比stage3低一點;在stage1、stage2、stage3上聯合測試,整體ap更高,ap70以上都有很大提升
延伸問題1: 為什么出現這樣的現象?
延伸問題2: cascade-rcnn如何做聯合測試的? ?
?
對比實驗3:
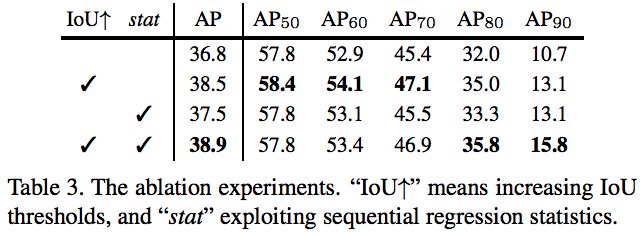
使用了iou,性能在提升;使用了stat性能也提升。同時使用iou和stat,總ap在上升,但是ap70以下的略微下降,ap80以上的提升,特別是ap90提升明顯
延伸問題:為什么在用iou的基礎上加stat,70以下反而下降?
對比實驗4:
?
聯合預測的時候,1-2聯合提升最明顯;1-3比1-2也有提升,主要在高質量框上,整體ap提升了;但是再多回歸一次,整體ap有略微下降,ap90以下的都下降了,
但是ap90上升了
延伸問題:為什么多一個stage,性能還下降了?
?
?cascade如何訓練?
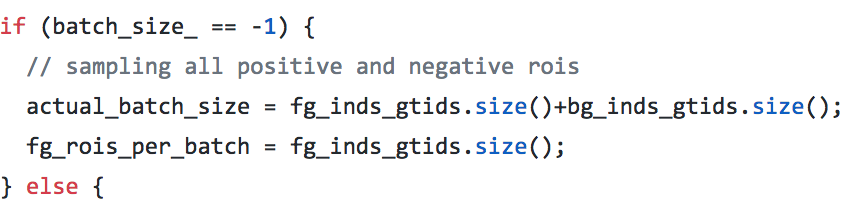
第一個stage選512個roi,訓練之后把這些roi全給第二個stage的proposal_info_2nd(這個里面調用decodebbox層,也就是對當前的框進一步精修給下一個stage),proposal_info_2nd中batchsize為-1,proposaltarget源碼增加了batchsize為-1的情況,就是把所有的正負樣本都考慮進來(實際上數量應該是小于512的),而不是原來默認的128.這個時候再跟gt進行assign,重新分配roi和gt給下一個stage.

 ?
?
在decodebox層里面,還會把精修后錯誤的roi去掉,比如x1大于x2;同時,也會把和gt iou超過0.95的去掉,就是覺得這個已經夠精確,不用再精修了
// screen out mal-boxesif (this->phase_ == TRAIN) {for (int i = 0; i < num; i++) {const int base_index = i*bbox_dim+4;if (bbox_pred_data[base_index] > bbox_pred_data[base_index+2] || bbox_pred_data[base_index+1] > bbox_pred_data[base_index+3]) {valid_bbox_flags[i] = false;}}} // screen out high IoU boxes, to remove redundant gt boxesif (bottom.size()==3 && this->phase_ == TRAIN) {const Dtype* match_gt_boxes = bottom[2]->cpu_data();const int gt_dim = bottom[2]->channels();const float gt_iou_thr = this->layer_param_.decode_bbox_param().gt_iou_thr();for (int i = 0; i < num; i++) {const float overlap = match_gt_boxes[i*gt_dim+gt_dim-1];if (overlap >= gt_iou_thr) {valid_bbox_flags[i] = false;}}}

cascade如何測試 ?
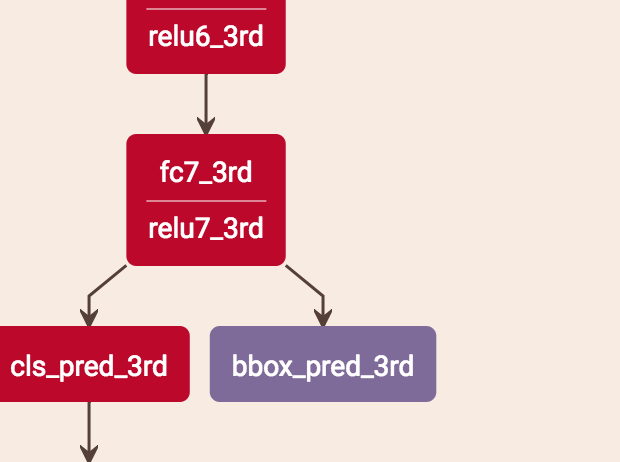
bouding box regression是直接從最后一個stage得到的結果,即bbox_pre_3rd。
?
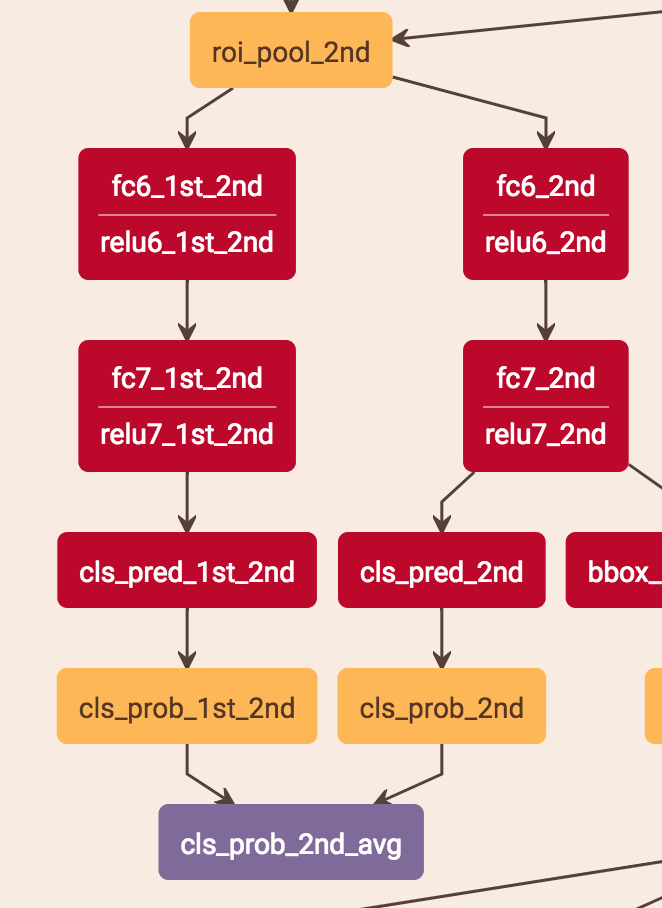
score的預測是把當前stage的score和之前層的score平均。stage2是把stage1的score*0.5 + stage2的score*0.5,stage3是把stage1的score*0.333 + stage2的score*0.333 + stage3的score*0.333。具體做法是:比如stage2的預測,roi-pooling出來的特征分別用兩個分支得到兩個score,這兩個分支就是兩層fc,一個用stage1的fc的參數,一個用stage2的fc的參數,這樣就分別得到了兩個stage的score再求平均。
注意:test.prototxt里面有cls_prob、cls_prob_2nd_avg、cls_prob_3rd_avg 3個輸出,cls_prob是1的結果,cls_prob_2nd_avg是1+2的結果,cls_prob_3rd_avg是1+2+3的結果,他這3個輸出應該是為了考慮最終的實驗比較,最終的實際輸出應該還是cls_prob_3rd_avg。
總的來說,cls是3個stage求平均,bouding box regression是直接從stage3獲得
?
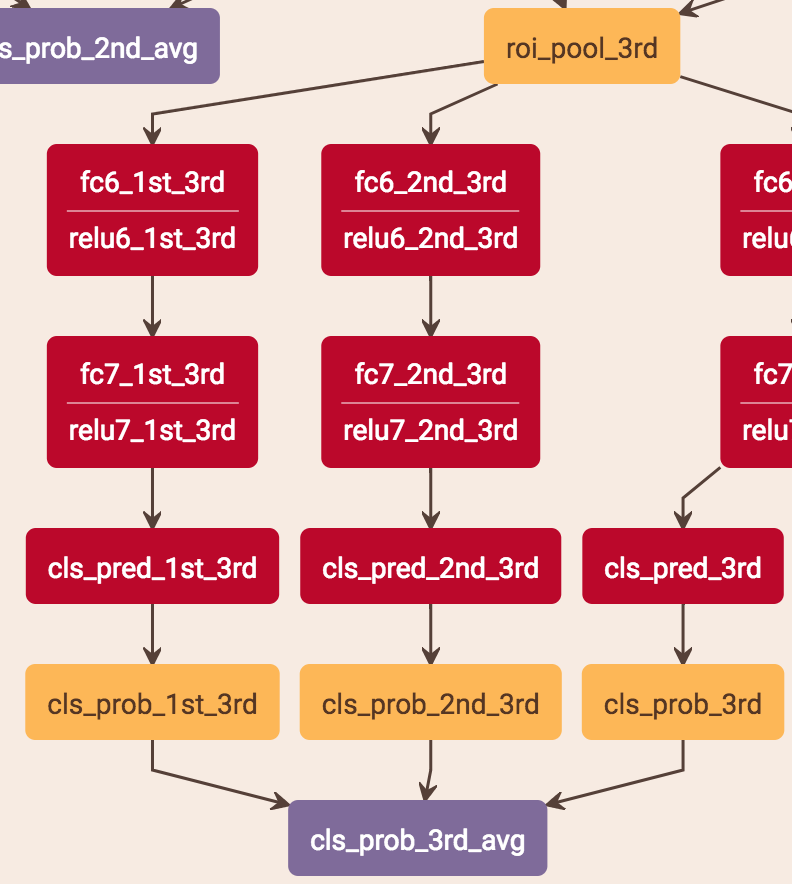
?為什么從3個stage到4個stage,性能還下降了?
可能是overfitting造成的:1.如果以faster來說的話,每個stage會增加兩個大的fc和兩個小的fc,這個參數量很大;? 2.cascade代碼中,每次回歸之前,會把前一個stage的roi與gt的iou大于0.9的消除掉,stage越往高走,roi的個數是越會下降的。? ?3.并且也會把一些負樣本去掉,因為cascade中每個stage會把roi不正常的框去掉,回歸可能導致負樣本這樣
還有一點,就是可能模型本身做regression,多次regression后,好多框其實已經修正的比較好了,再去修正可能就是擾動,不能讓性能很好提升,甚至有可能反而下降。
主要是往后特征沒辦法更好了吧,加更多也沒有收益,只要Inference設計好,下降倒不太會
Cascade rcnn 3 4 也沒下降,只是輕微影響一點,是飽和了


-系統架構)





_2.iView 實戰教程之導航、路由、鑒權篇)
答案...)









