為了與金融從業者、科技從業者共同探討金融 + 業務的深層次問題,螞蟻金服聯手 TGO 鯤鵬會,在 12 月 8 日舉辦了「走進螞蟻金服:雙十一背后的螞蟻金服技術支持」活動。螞蟻金服高級技術專家天街為大家分享了《螞蟻雙 11 大促 OceanBase 核心技術全解析》。本文根據當天演講整理,有部分不改變原意的刪減。

天街現場演講照片
今天給大家介紹一下 OceanBase 在大促 5 年來的技術演進,主要內容是 OceanBase 大促體系,下文簡稱 OB。今年 OB 大促上有三個核心技術:百萬支付、容器化和平臺智能化。
OB 大促主要做什么事情?大促就是把平常的能力在雙 11 舞臺上做最大的展示。大促的內容很多,落到技術層面就是整個體系的分析,我們可以把它抽象出六個能力:
容量。面對這種脈沖式的壓力上升,我們可以從單機性能和集群性能量方面來考慮滿足大促容量;
可靠性。作為金融級公司,我們在峰值上要保持脈沖風險穩定可靠;
成本。日常使用的機器與雙 11 相比非常少,需要降低大促使用的機器成本;
效率。大促是常態化的流程,一年之中會有很多大促,要用最高的效率來實現大促,這是成敗的關鍵;
抗壓。用壓測試保證各方面的系統滿足雙 11 的峰值;
彈性。這是雙 11 最核心的技術,需要把應用服務器、DB 各種計算能力都彈到一個新的單元上,利用這部分資源支撐大促,同時在大促之后快速還回來。
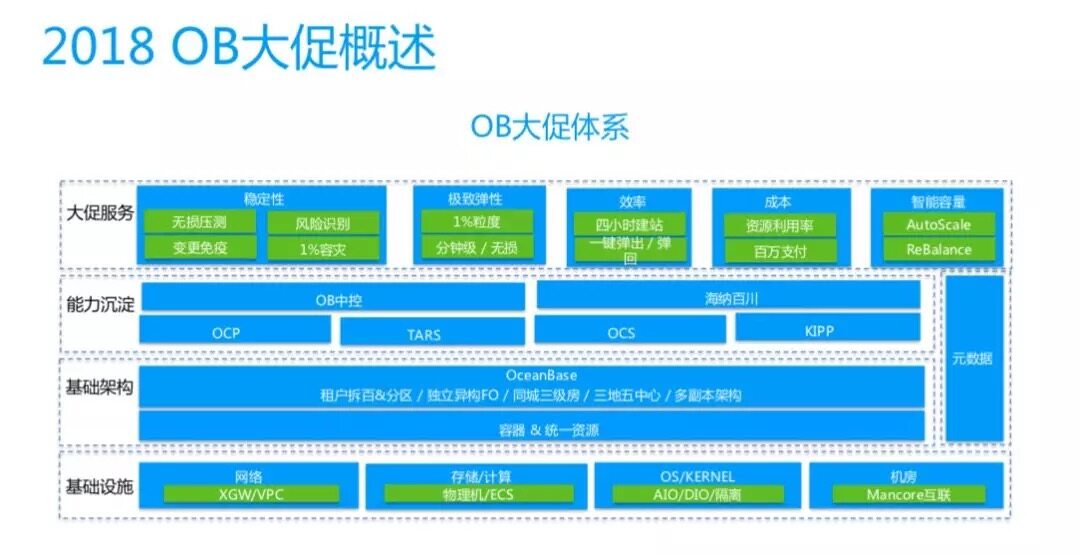
上圖是 OB 這幾年在大促上的彈性化體系,分為四層:
1、基礎設施。今年大促的基礎設施是網絡、存儲計算的介質、底層與內核的交互、網絡互聯。
2、基礎架構。這是底層對業務可見的基礎部署,我們把業務放到容器里,上面是業務可見的架構,有獨立的異構 FO 和同城三級房部署。為了彈性的效率,我們還做了多副本的架構,比如傳統的主庫、備庫以及最近兩年新加的日志節點。
3、能力沉淀。大促需要的能力和日常需要的能力相輔相成,如果日常就具備這樣的能力,那么大促時就能從容應對。
4、大促服務。我們今年雙 11 做了 4 萬 + 的變更,實際上是通過 AutoScale 平臺做的,同時我們也會結合穩定性的要求,比如變更三把斧,把這些能力做進去。
我們的三年戰略是百萬支付,經測算三年之內交付峰值將達到一百萬。因為應用是無狀態的,只要我們在整個系統上做到可擴容、可彈性,把機器加上去就可以解決。但是 DB 端不行,一份數據所能夠使用的存儲空間和很多東西相關,比如業務方的分表、單機的性能都有一定的瓶頸,百萬支付落到 DB 端最核心的問題就是怎么解決最小的數據分片,解決資源規格異構和負載均衡偏差的資源問題。
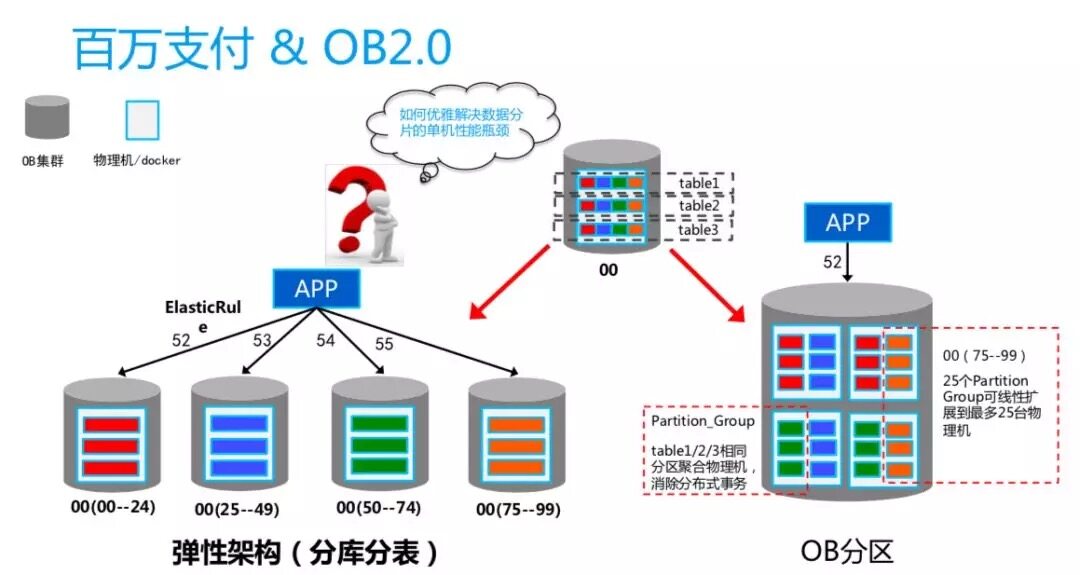
這個圖代表了當前支付寶架構的解決方案。右邊 00 代表一個分片,全中國路由出來是 UID 的 00。支付事務跨多張表,每一張表對應的多個分片,我們會把它聚合在一起,代表一個實例或者租戶,一個租戶使用的最大資源是物理機的資源。如果想要把 00 繼續拆分,就把 00 分片再取兩位做哈希。對新的業務通過彈性規則,訪問對應的庫。這樣業務改造的工作量很大,因為要加四個數據庫,并且加了之后沒有辦法回收。而且伸縮是有損的,因為要縮小服務器資源必然涉及到大量數據的縮容,那么應用就會感知到。
基于這些,我們提出了 OB2.0。這個項目最大的價值是做到 OB 分區,就是可以把一個應用維度看成一個數據分片,可以在 DB 端做到無限度的 sharding。我們通過 Partition Group 的概念,把不同表格相同分區聚合到相同的機器,同時還把任意一個分片結合物理機的數目進行二次聚合,聚合成大的 Partition Group,根據 server 數的不同,自動把分片分到不同的機器上,這就是百萬支付結合 OB2.0 的架構。
OB2.0 打造百萬支付能力的優勢:
彈性伸縮。分片可以無限 sharding,實現線性擴展,并且每一個分片都具備獨立的擴展能力,可以滿足多元化的彈性需求;
業務無感無損。無感是指業務感覺不到 DB 的伸縮,外部公司如果想要做一個大促活動,不需要業務感知,直接由 DB 完成。無損是指整個彈性過程中業務不會有失敗,因為這是通過我們的協議來實現的;
極致高可用。通過灰度做到不同分片之間互相隔離,并且可低版本和高版本同時運行,如果一個分片一個星期沒有問題,就可以自動對下一個版本進行處理;
資源。我們可以把一個在高峰期占有很大資源的數據源拆成一個非常統一的資源粒度,它的好處就是可以很獨立地做負載均衡。
我們做容器化有兩方面原因:第一,常態;第二,大促。
常態會面臨什么樣的問題?現在 DB 服務器有幾萬臺,如果對資源進行深入統計,就會發現 DB 資源肯定是過剩的。DB 資源無非就是 CPU、IO、內存,一個數據庫不可能這三類都占滿。我們做一個簡單的統計,大促時所有的服務器的瓶頸是 CPU,而日常的瓶頸是存儲空間,絕對不會是 CPU。另外,業務狀態注定存在高峰 / 低峰訪問。資源負載分為長尾、碎片兩類,我們需要把碎片收集起來再利用。資源分為絕對資源和相對資源,在不同業務間它們的比例差距很大,在現在的支付寶規模下使用的資源浪費很大。我們每年采用的機型都有很大的變化,現在 CPU 越來越多、內存越來越多,CPU 也有換代更新,所以針對異構的機型要把能力統一標準化,提供統一的服務能力。
而大促態的成本體現在哪里?第一,大促所需服務器總數;第二,持有服務器的時長。如果使用一千臺服務器,持有一個月,資源開銷遠遠大于持有兩千臺服務器五小時,這涉及到服務器運營。
這些問題就對 DB 提出了要求,DB 要有容器化的能力,目的是要調度 DB,把它放在我們想要的地方。
我們做的容器化主要有三點:
規格歸一。分區是一種方案,還有一種方案是業務拆分,比如把一些明顯不合理的長尾業務進行拆分,我們會把線上所有的 DB 順序分為五個可以滿足需求的規格,比如 2C8G、8C32G。我們做容器化的時候,只要是這五種規格就可以;
資源隔離 / 搶占,這是一個重點,因為容器化的目的是保證系統的正常運行,不要因為成本丟棄系統的穩定性。這里有三大塊:CPU、內存和 IO 通過 Cgroup 隔離,同時結合應用畫像,比如根據這個業務過去三個月的增長情況、存儲空間,做一個容器畫像,打上業務屬性的標簽,比如關鍵點的地域信息、資源信息;
多維調度,應用、機房、機架的調度。在 DB 層面,哪些租戶放在一起最節省資源,這是從上到下貫穿整個資源載體的調度。
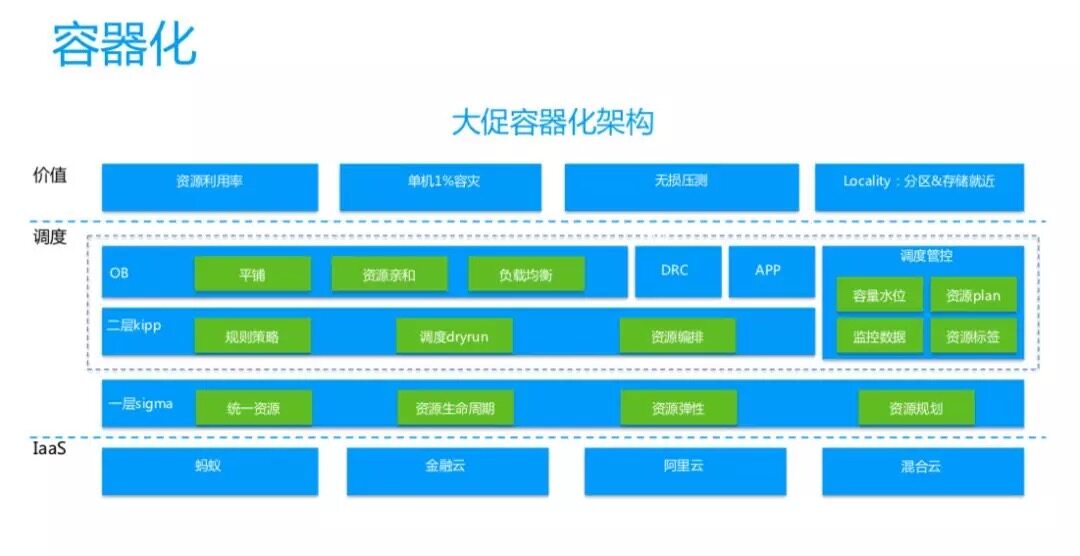
這是 OB 大促容器化的架構。底層是通用的調度平臺,要識別各種 IaaS,包括螞蟻、金融云、阿里云、混合云。再往上是統一的調度層:一層是 sigma,主要做統一資源規劃、資源生命周期、資源彈性、資源規劃;二層調度層分為 kipp 和 OB,按照不同租戶的畫像信息,得出調度策略是平鋪、搶占還是資源親和(資源親是指,單機不超過 1% 的容災,通過資源親和,把一筆支付鏈路上所能夠經過所有的應用和 DB 統一調度在同一臺機器上,通過一個親和性標簽放在一起,大大降低宕機的影響面);右邊是調度管控,包含水位、資源 Plan 和資源標簽;最上層是容器化達到的價值,首先是資源利用率,第二是單機 1% 容災,第三是無損壓測,第四是存區 \u0026amp; 存儲就近,讓存儲節點和計算節點兩者離得最近、網絡和 IO 離得最近。
為什么要做平臺智能化?第一是大促常態化。往年支付寶只有兩個活動:雙 11、雙 12,但是現在每個月都有三四個大促,大促的穩定性要求很高,那怎么把活動支持得更好呢?傳統上是做簡單的擴容,做一些預案,但現在會發現光做這些不夠了,我建議通過智能化的手段解決。可以把流程抽出來,結合最小的集群智能化,兩者有機結合實現根本目標。第二是隨著業務規模爆發,怎么解決硬件存在的隱患,怎么解決 10w+ 機器操作系統從 6U 升級到 7U。第三是穩定性,我們要做到 5 個 9,換算出來也就是全年停服不能超過 60 分鐘。要到達到這個目標,任何的應急措施都不能依賴于人,也不能通過指令觸發,必須通過智能。
介紹一下 OB 在大促智能化上的實踐,主要有兩點:第一,自動擴縮容;第二,SQL 調優。我們首先會對鏈路信息和 DB 運行狀態進行建模,從應用服務器中間件數據源清洗出來鏈路信息,從 CPU、IO 各方面對每一條鏈路的 DB 節點進行數據擬合,得到擬合線后,通過指標的輸入,推測在這個壓力下 DB 的水位會產生什么樣的波動或者峰值,從而可以把每一個業務的容量信息、每一個租戶信息刻劃出來,結合調度做一些智能的 rebalance;第二是 SQL 調優,我們會監控每一條 SQL 的狀態,比如這一條 SQL 的使用概率、任意資源的消耗情況,給出 SQL 調優的建議。
第三是壓測的資源預測和壟斷。如果預測在接下來三分鐘之內內存會占滿,就自動停止掉。如果預測到 RT 水位對于業務來說是超時的,就停止自動壓測。
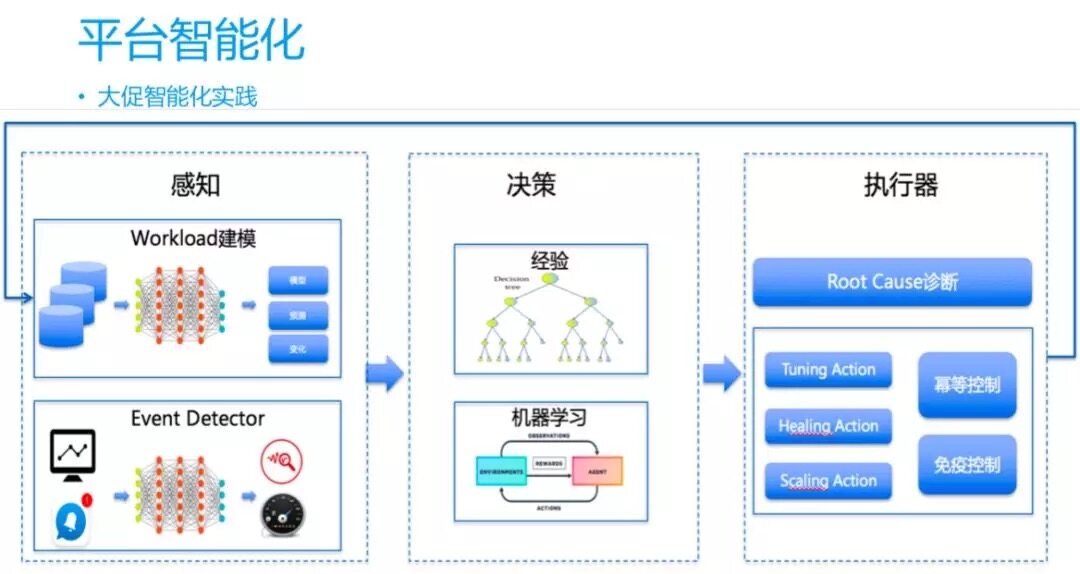
我們把穩定性做到 5 個 9,分成三個模塊:第一,感知,我們會對各種 workload 建模,形成非常豐富的曲線,通過曲線得出模型歸納和預測變化;第二,決策,第一個方法是基于經驗,形成每一個數,每一個數的子節點是上一個節點的原因分析,往下是它的根因;第二個方法是機器學習,這是自我認知的過程,我們會把這些經驗做輸入,通過演進和優化不斷得出最佳的決策樹;第三,執行器,我們會對上一層信息進行更新階段,根據診斷得出需要執行的方案,比如需要調優、擴容、還是修復。
OB 結合大促場景下的未來規劃主要有兩個方面:
資源。資源是我們做大促的核心價值,用最小的資源解決用戶最大的問題。第一,統一調度。不僅僅是 DB 端的統一調度,我們還要把用戶服務器、各種機型、資源池全部打通,這樣就有了更大的池子,技術可發揮的空間更大;第二,混合部署。統一部署之后會分池分布、分類混布;第三,分時復用。混布和分時復用的效率體現很明顯,因為不需要做大促處理時候可以節省資源開銷;
自治。第一是 OB 內核的自治,第二是平臺化的自治。自治分為三塊:
自愈,主要解決穩定性的問題,有硬件故障、流量無峰、軟件異常類的壟斷;
自駕駛,集群容量、租戶容量、集群升級等完全不需要人參與,實現無人職守;
自調優,把線上流量全部抓下來,在線下庫里對流量進行滾放,滾放出來的流量可以自編程核對、關聯度分析,所有的線上場景都可以在線下進行演練。
TGO鯤鵬會,系極客邦科技旗下高端技術人聚集和交流的組織,旨在組建全球最具影響力的科技領導者社交網絡,線上線下相結合,為會員提供專享服務。目前,TGO鯤鵬會已在北京、上海、杭州、廣州、深圳、成都、硅谷、臺灣、南京、廈門、蘇州十一個城市設立分會,武漢分會即將成立。現在全球擁有在冊會員 740 余名,60% 為 CTO、技術 VP、技術合伙人。
會員覆蓋了 BATJ 等互聯網巨頭公司技術領導者,同時,阿里巴巴王堅博士、同程藝龍技術委員會主任張海龍、蘇寧易購 IT 總部執行副總裁喬新亮已經受邀,成為 TGO 鯤鵬會榮譽導師。
如果你想和這些優秀的科技領導者們一起前行,歡迎點擊「報名表單,申請加入」。





mssql2005生成表字典)













