1 :列表生成式和生成器的區別 ?
列表生成式直接生成一個列表,所有元素對象被立即創建在內存中,當元素過多時,勢必會占用過多內存,
不可取,要用到生成器,它即時創建一個生成器對象,未創建任何元素
生成器來生成一個列表,它不會立即創建大量的對象在內存中
生成器的缺點,沒有列表的方法,如append、len、index等等
通過next方法來訪問其元素
可通過循環打印出所有的元素
2、:如何不用任何循環快速篩掉列表中的奇數元素 ?
用內置函數filter配合匿名函數過濾掉數組中不符合條件的元素
print (filter(lambda x:x%2 ==0, [1,2,3,4,5])) #[2,4]
3、:map和reduce的用法 ?
#map
#使用函數來處理序列中的元素 :包含數字的元組、列表;
#可以接收2個數序列,生成一個列表
print map(lambda x,y:(x,y) , [1,2,3],[4,5,6]) #[(1, 4), (2, 5), (3, 6)]
#reduce
#使用函數來累積處理序列中的元素,可實現階乘、求數組內的數字和;reduce把一個函數作用在一個序列[x1, x2, x3, ...]上,這個函數必須接收兩個參數,reduce把結果繼續和序列的下一個元素做累積計算.
4、裝飾器的作用 ?
? ? ?答:裝飾器本質上是一個Python函數,它可以讓其他函數在不需要做任何代碼變動的前提下增加額外功能,提高了代碼的復用性。比如,在函數調用前后自動打印日志,但又不希望修改now()函數的定義,這種在代碼運行期間動態增加功能的方式,稱之為“裝飾器”(Decorator)
5、如何處理封IP的反爬 ?
? ? 答:因為網絡上的免費代理平臺可用的IP數量太少,所以自己寫一個模塊去抓取平臺的IP來維護是沒有什么意義的。我選擇的是付費代理,通過使用平臺的api在本地動態維護一個IP緩存池來供給分布式架構的爬蟲節點使用。這個緩存池不需要做IP有效性驗證,因為我的爬蟲若下載某個Request徹底失敗后會把這個Request重新放回Request隊列,而且選擇一個好的代理平臺可以大大提高代理IP質量。我常用的是快代理。緩存池的IP被取走一個,池中的數量就減少一個,當數量少于M時,再從平臺獲取N個。
6、如何處理驗證碼 ?
???答:簡單的驗證碼可以通過預處理(灰度、二值化、去除干燥點)驗證碼圖片再使用tesseract庫來識別;復雜一點的則接入付費平臺識別。當然,如果這個目標網站的app端沒有驗證碼的話,會優先通過app端爬取。
7、說幾個redis中的數據類型和命令
???答:?字符?串、列表、set集合;set key 123,,,lpush key 1 2 3,,,sadd key 1 2 3
8、MySQL中的inner join和left join的區別 ?
? ?答:?NNER JOIN(內連接,或等值連接):取得兩個表中存在連接匹配關系的記錄。?
? ? ? ? ? ?LEFT JOIN(左連接):取得左表(table1)完全記錄,即使右表(table2)并無對應匹配記錄。?
???????????擴展:RIGHT JOIN(右連接):與 LEFT JOIN 相反,取得右表(table2)完全記錄,即使左表(table1)并無匹配對應記錄。
?
9、Python中__new__與__init方法的區別
__new__:它是創建對象時調用,會返回當前對象的一個實例,可以用_new_來實現單例?
__init__:它是創建對象后調用,對當前對象的一些實例初始化,無返回值
10、python中的設計模式
11、常用的網絡數據爬取方法
正則表達式
Beautiful Soup
Lxml
12、設計一個基于session登錄驗證的爬蟲方案
?
13、什么是lambda函數?它有什么好處?
lambda 表達式,通常是在需要一個函數,但是又不想費神去命名一個函數的場合下使用,也就是指匿名函數
lambda函數:首要用途是指點短小的回調函數
lambda [arguments]:expression
>>> a=lambdax,y:x+y
>>> a(3,11)
二.框架問題(scrapy)可能會根據你說的框架問不同的問題,但是scrapy還是比較多的
1.scrapy的基本結構(五個部分都是什么,請求發出去的整個流程)
2.scrapy的去重原理 (指紋去重到底是什么原理)
(1).Scrapy本身自帶有一個中間件;
(2).scrapy源碼中可以找到一個dupefilters.py去重器;
(3).需要將dont_filter設置為False開啟去重,默認是True,沒有開啟去重;
(4) .對于每一個url的請求,調度器都會根據請求得相關信息加密得到一個指紋信息,并且將指紋信息和set()集合中的指紋信息進 行 比對,如果set()集合中已經存在這個數據,就不在將這個Request放入隊列中;
(5).如果set()集合中沒有存在這個加密后的數據,就將這個Request對象放入隊列中,等待被調度。
?
3.scrapy中間件有幾種類,你用過那些中間件,
?
4.scrapy中間件再哪里起的作用(面向切面編程)
(1)、scrapy的中間件理論上有三種(Schduler Middleware,Spider Middleware,Downloader Middleware),在應用上一般有以下兩種
? ? ? ?1.爬蟲中間件Spider Middleware
? ? ? ? ?主要功能是在爬蟲運行過程中進行一些處理.
2.下載器中間件Downloader Middleware
? ? ? ? ?主要功能在請求到網頁后,頁面被下載時進行一些處理.
(2)、使用
? ? ? 1.Spider Middleware有以下幾個函數被管理:
? ? ? ?-?process_spider_input 接收一個response對象并處理,
? ? ? ? ?位置是Downloader-->process_spider_input-->Spiders(Downloader和Spiders是scrapy官方結構圖中的組件)
? ? ? ?-?process_spider_exception spider出現的異常時被調用
? ? ? ?-?process_spider_output?當Spider處理response返回result時,該方法被調用
? ? ? ?- process_start_requests 當spider發出請求時,被調用
??位置是Spiders-->process_start_requests-->Scrapy Engine(Scrapy Engine是scrapy官方結構圖中的組件)? ? ? ? ?
? 2.Downloader Middleware有以下幾個函數被管理
-?process_request??request通過下載中間件時,該方法被調用
-?process_response 下載結果經過中間件時被此方法處理
-?process_exception 下載過程中出現異常時被調用
? ? ? 編寫中間件時,需要思考要實現的功能最適合在那個過程處理,就編寫哪個方法.
? ? ? 中間件可以用來處理請求,處理結果或者結合信號協調一些方法的使用等.也可以在原有的爬蟲上添加適應項目的其他功能,這一點在擴展中編寫也可以達到目的,實際上擴展更加去耦合化,推薦使用擴展.
5.代理問題
(1).為什么會用到代理
(2).代理怎么使用(具體代碼,請求在什么時候添加的代理)
(3).代理失效了怎么處理
6.驗證碼處理
(1).登陸驗證碼處理
(2).爬取速度過快出現的驗證碼處理
(3).如何用機器識別驗證碼
7.模擬登陸問題
(1).模擬登陸流程
(2).cookie如何處理
(3).如何處理網站傳參加密的情況
8、分布式
(1).分布式原理
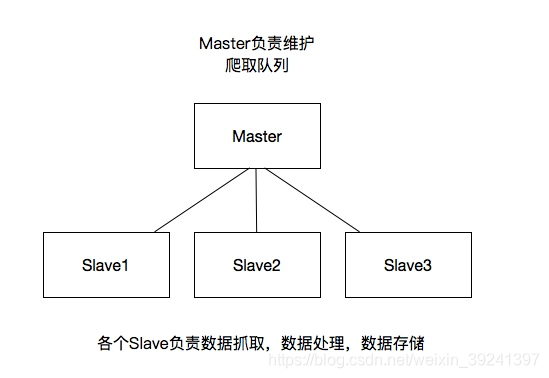
這里重要的就是我的隊列通過什么維護?
這里一般我們通過Redis為維護,Redis,非關系型數據庫,Key-Value形式存儲,結構靈活。
并且redis是內存中的數據結構存儲系統,處理速度快,提供隊列集合等多種存儲結構,方便隊列維護
如何去重?
這里借助redis的集合,redis提供集合數據結構,在redis集合中存儲每個request的指紋
在向request隊列中加入Request前先驗證這個Request的指紋是否已經加入集合中。如果已經存在則不添加到request隊列中,如果不存在,則將request加入到隊列并將指紋加入集合
如何防止中斷?如果某個slave因為特殊原因宕機,如何解決?
這里是做了啟動判斷,在每臺slave的Scrapy啟動的時候都會判斷當前redis request隊列是否為空
如果不為空,則從隊列中獲取下一個request執行爬取。如果為空則重新開始爬取,第一臺叢集執行爬取向隊列中添加request
如何實現上述這種架構?
這里有一個scrapy-redis的庫,為我們提供了上述的這些功能
scrapy-redis改寫了Scrapy的調度器,隊列等組件,利用他可以方便的實現Scrapy分布式架構
(2).分布式如何判斷爬蟲已經停止了
查一下爬蟲的狀態:
spider.getStatus();//獲取爬蟲狀態(3).分布式去重原理
?
(4).分布式爬蟲的實現:
- (1).使用兩臺機器,一臺是win10,一臺是ubuntu16.04,分別在兩臺機器上部署scrapy來進行分布式抓取一個網站.
- (2).ubuntu16.04的ip地址為39.106.155.194,用來作為redis的master端,win10的機器作為slave.
- (3).master的爬蟲運行時會把提取到的url封裝成request放到redis中的數據庫:“dmoz:requests”,并且從該數據庫中提取request后下載網頁,再把網頁的內容存放到redis的另一個數據庫中“dmoz:items”.
- (4).slave從master的redis中取出待抓取的request,下載完網頁之后就把網頁的內容發送回master的redis.
- (5).重復上面的3和4,直到master的redis中的“dmoz:requests”數據庫為空,再把master的redis中的“dmoz:items”數據庫寫入到mongodb中.
- (6).master里的reids還有一個數據“dmoz:dupefilter”是用來存儲抓取過的url的指紋(使用哈希函數將url運算后的結果),是防止重復抓取的.
三、selenium模擬登錄,遇到驗證碼:
截圖,找到驗證碼的位置,進行識別
#因為驗證碼不能一次就正確識別,我加了循環,一直識別,直到登錄成功
while True:
?? ?#清空驗證碼輸入框,因為可能已經識別過一次了,里面有之前識別的錯的驗證碼
? ? driver.find_element_by_name("verificationCode").clear()
? ? # 截圖或驗證碼圖片保存地址
? ? screenImg = "H:\screenImg.png"
? ? # 瀏覽器頁面截屏
? ? driver.get_screenshot_as_file(screenImg)
? ? # 定位驗證碼位置及大小
? ? location = driver.find_element_by_name('authImage').location
? ? size = driver.find_element_by_name('authImage').size
?? ?#下面四行我都在后面加了數字,理論上是不用加的,但是不加我這截的不是驗證碼那一塊的圖,可以看保存的截圖,根據截圖修改截圖位置
? ? left = location['x']+530
? ? top = location['y']+175
? ? right = location['x'] + size['width']+553
? ? bottom = location['y'] + size['height']+200
? ? # 從文件讀取截圖,截取驗證碼位置再次保存
? ? img = Image.open(screenImg).crop((left, top, right, bottom))
?? ?#下面對圖片做了一些處理,能更好識別一些,相關處理再百度看吧
? ? img = img.convert('RGBA') ?# 轉換模式:L | RGB
? ? img = img.convert('L') ?# 轉換模式:L | RGB
? ? img = ImageEnhance.Contrast(img) ?# 增強對比度
? ? img = img.enhance(2.0) ?# 增加飽和度
? ? img.save(screenImg)
? ? # 再次讀取識別驗證碼
? ? img = Image.open(screenImg)
? ? code = pytesseract.image_to_string(img)
? ? #打印識別的驗證碼
? ? #print(code.strip())
?
?
?



















