作者:你是我的海嘯
出處:https://blog.csdn.net/chang384915878/article/details/86756463
只要用緩存,就可能會涉及到緩存與數據庫雙存儲雙寫,你只要是雙寫,就一定會有數據一致性的問題,那么你如何解決一致性問題?
面試題剖析
一般來說,如果允許緩存可以稍微的跟數據庫偶爾有不一致的情況,也就是說如果你的系統不是嚴格要求 “緩存+數據庫” 必須保持一致性的話,最好不要做這個方案,即:讀請求和寫請求串行化,串到一個內存隊列里去。
串行化可以保證一定不會出現不一致的情況,但是它也會導致系統的吞吐量大幅度降低,用比正常情況下多幾倍的機器去支撐線上請求。
Cache Aside Pattern
最經典的緩存+數據庫讀寫的模式,就是 Cache Aside Pattern。
讀的時候,先讀緩存,緩存沒有的話,就讀數據庫,然后取出數據后放入緩存,同時返回響應。
更新的時候,先更新數據庫,然后再刪除緩存。
為什么是刪除緩存,而不是更新緩存?
原因很簡單,很多時候,在復雜點的緩存場景,緩存不單單是數據庫中直接取出來的值。
比如可能更新了某個表的一個字段,然后其對應的緩存,是需要查詢另外兩個表的數據并進行運算,才能計算出緩存最新的值的。
另外更新緩存的代價有時候是很高的。是不是說,每次修改數據庫的時候,都一定要將其對應的緩存更新一份?也許有的場景是這樣,但是對于比較復雜的緩存數據計算的場景,就不是這樣了。如果你頻繁修改一個緩存涉及的多個表,緩存也頻繁更新。但是問題在于,這個緩存到底會不會被頻繁訪問到?
舉個栗子,一個緩存涉及的表的字段,在 1 分鐘內就修改了 20 次,或者是 100 次,那么緩存更新 20 次、100 次;但是這個緩存在 1 分鐘內只被讀取了 1 次,有大量的冷數據。實際上,如果你只是刪除緩存的話,那么在 1 分鐘內,這個緩存不過就重新計算一次而已,開銷大幅度降低,用到緩存才去算緩存。
其實刪除緩存,而不是更新緩存,就是一個 lazy 計算的思想,不要每次都重新做復雜的計算,不管它會不會用到,而是讓它到需要被使用的時候再重新計算。像 mybatis,hibernate,都有懶加載思想。查詢一個部門,部門帶了一個員工的 list,沒有必要說每次查詢部門,都里面的 1000 個員工的數據也同時查出來啊。80% 的情況,查這個部門,就只是要訪問這個部門的信息就可以了。先查部門,同時要訪問里面的員工,那么這個時候只有在你要訪問里面的員工的時候,才會去數據庫里面查詢 1000 個員工。
最初級的緩存不一致問題及解決方案
問題:先修改數據庫,再刪除緩存。如果刪除緩存失敗了,那么會導致數據庫中是新數據,緩存中是舊數據,數據就出現了不一致。
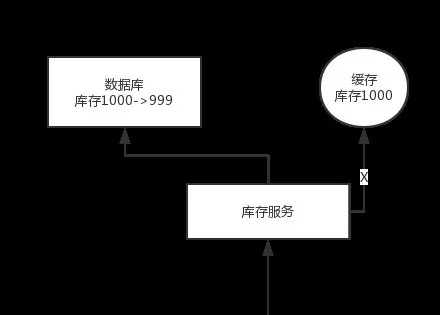
解決思路:先刪除緩存,再修改數據庫。如果數據庫修改失敗了,那么數據庫中是舊數據,緩存中是空的,那么數據不會不一致。因為讀的時候緩存沒有,則讀數據庫中舊數據,然后更新到緩存中。
比較復雜的數據不一致問題分析
數據發生了變更,先刪除了緩存,然后要去修改數據庫,此時還沒修改。一個請求過來,去讀緩存,發現緩存空了,去查詢數據庫,查到了修改前的舊數據,放到了緩存中。隨后數據變更的程序完成了數據庫的修改。
完了,數據庫和緩存中的數據不一樣了。。。
為什么上億流量高并發場景下,緩存會出現這個問題?
只有在對一個數據在并發的進行讀寫的時候,才可能會出現這種問題。其實如果說你的并發量很低的話,特別是讀并發很低,每天訪問量就 1 萬次,那么很少的情況下,會出現剛才描述的那種不一致的場景。但是問題是,如果每天的是上億的流量,每秒并發讀是幾萬,每秒只要有數據更新的請求,就可能會出現上述的數據庫+緩存不一致的情況。
解決方案如下:
更新數據的時候,根據數據的唯一標識,將操作路由之后,發送到一個 jvm 內部隊列中。讀取數據的時候,如果發現數據不在緩存中,那么將重新讀取數據+更新緩存的操作,根據唯一標識路由之后,也發送同一個 jvm 內部隊列中。
一個隊列對應一個工作線程,每個工作線程串行拿到對應的操作,然后一條一條的執行。這樣的話,一個數據變更的操作,先刪除緩存,然后再去更新數據庫,但是還沒完成更新。此時如果一個讀請求過來,讀到了空的緩存,那么可以先將緩存更新的請求發送到隊列中,此時會在隊列中積壓,然后同步等待緩存更新完成。
這里有一個優化點,一個隊列中,其實多個更新緩存請求串在一起是沒意義的,因此可以做過濾,如果發現隊列中已經有一個更新緩存的請求了,那么就不用再放個更新請求操作進去了,直接等待前面的更新操作請求完成即可。
待那個隊列對應的工作線程完成了上一個操作的數據庫的修改之后,才會去執行下一個操作,也就是緩存更新的操作,此時會從數據庫中讀取最新的值,然后寫入緩存中。
如果請求還在等待時間范圍內,不斷輪詢發現可以取到值了,那么就直接返回;如果請求等待的時間超過一定時長,那么這一次直接從數據庫中讀取當前的舊值。
高并發的場景下,該解決方案要注意的問題:
1、讀請求長時阻塞
由于讀請求進行了非常輕度的異步化,所以一定要注意讀超時的問題,每個讀請求必須在超時時間范圍內返回。
該解決方案,最大的風險點在于說,可能數據更新很頻繁,導致隊列中積壓了大量更新操作在里面,然后讀請求會發生大量的超時,最后導致大量的請求直接走數據庫。務必通過一些模擬真實的測試,看看更新數據的頻率是怎樣的。
另外一點,因為一個隊列中,可能會積壓針對多個數據項的更新操作,因此需要根據自己的業務情況進行測試,可能需要部署多個服務,每個服務分攤一些數據的更新操作。如果一個內存隊列里居然會擠壓 100 個商品的庫存修改操作,每隔庫存修改操作要耗費 10ms 去完成,那么最后一個商品的讀請求,可能等待 10 * 100 = 1000ms = 1s 后,才能得到數據,這個時候就導致讀請求的長時阻塞。
一定要做根據實際業務系統的運行情況,去進行一些壓力測試,和模擬線上環境,去看看最繁忙的時候,內存隊列可能會擠壓多少更新操作,可能會導致最后一個更新操作對應的讀請求,會 hang 多少時間,如果讀請求在 200ms 返回,如果你計算過后,哪怕是最繁忙的時候,積壓 10 個更新操作,最多等待 200ms,那還可以的。
如果一個內存隊列中可能積壓的更新操作特別多,那么你就要加機器,讓每個機器上部署的服務實例處理更少的數據,那么每個內存隊列中積壓的更新操作就會越少。
其實根據之前的項目經驗,一般來說,數據的寫頻率是很低的,因此實際上正常來說,在隊列中積壓的更新操作應該是很少的。像這種針對讀高并發、讀緩存架構的項目,一般來說寫請求是非常少的,每秒的 QPS 能到幾百就不錯了。
實際粗略測算一下
如果一秒有 500 的寫操作,如果分成 5 個時間片,每 200ms 就 100 個寫操作,放到 20 個內存隊列中,每個內存隊列,可能就積壓 5 個寫操作。每個寫操作性能測試后,一般是在 20ms 左右就完成,那么針對每個內存隊列的數據的讀請求,也就最多 hang 一會兒,200ms 以內肯定能返回了。
經過剛才簡單的測算,我們知道,單機支撐的寫 QPS 在幾百是沒問題的,如果寫 QPS 擴大了 10 倍,那么就擴容機器,擴容 10 倍的機器,每個機器 20 個隊列。
2、讀請求并發量過高
這里還必須做好壓力測試,確保恰巧碰上上述情況的時候,還有一個風險,就是突然間大量讀請求會在幾十毫秒的延時 hang 在服務上,看服務能不能扛的住,需要多少機器才能扛住最大的極限情況的峰值。
但是因為并不是所有的數據都在同一時間更新,緩存也不會同一時間失效,所以每次可能也就是少數數據的緩存失效了,然后那些數據對應的讀請求過來,并發量應該也不會特別大。
3、多服務實例部署的請求路由
可能這個服務部署了多個實例,那么必須保證說,執行數據更新操作,以及執行緩存更新操作的請求,都通過 Nginx 服務器路由到相同的服務實例上。
比如說,對同一個商品的讀寫請求,全部路由到同一臺機器上。可以自己去做服務間的按照某個請求參數的 hash 路由,也可以用 Nginx 的 hash 路由功能等等。
4、熱點商品的路由問題,導致請求的傾斜
萬一某個商品的讀寫請求特別高,全部打到相同的機器的相同的隊列里面去了,可能會造成某臺機器的壓力過大。就是說,因為只有在商品數據更新的時候才會清空緩存,然后才會導致讀寫并發,所以其實要根據業務系統去看,如果更新頻率不是太高的話,這個問題的影響并不是特別大,但是的確可能某些機器的負載會高一些。



)

函數和fetchall()函數的區別)


與 detach()區別)






方法詳解)


)

