來源:IJCAI 2019
論文地址:https://arxiv.org/abs/1902.06667
代碼地址:https://github.com/CRIPAC-DIG/H-GCN
Introduction
1、問題定義:什么是半監督的節點分類?
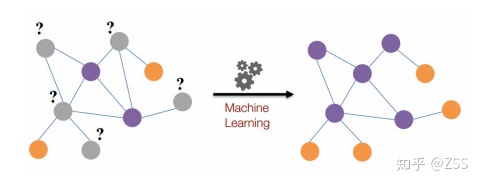
如圖1所示,在標記數據量很少,待預測的節點和標記節點距離較遠的情況下,預測未知節點的標簽就叫做半監督的節點分類。
2、為什么要進行半監督的節點分類?
在現實生活中,圖數據無處不在,例如社交網絡,知識圖譜,蛋白質分子等。許多應用都需要分析每個節點的性質,圖節點分類任務就是這樣一個基礎的任務。但是,目前圖的節點分類存在一些挑戰,主要包括:
(1)圖數據的非歐式空間難以應用傳統的深度學習方法;
(2)節點之間的關系錯綜復雜;
(3)實際應用中標注數據相比總體數據數據很少。
Related Work
1、GCN
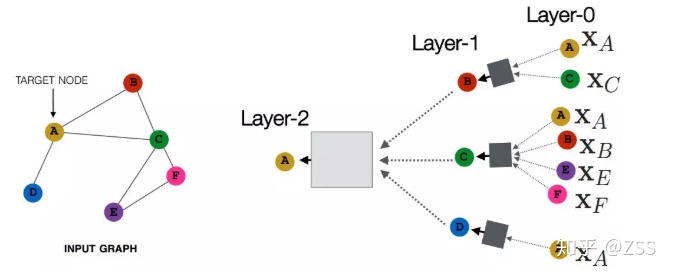
如圖2所示,每個節點通過鄰域聚合的方式,把它的鄰居節點的特征通過一定的方式聚合到一起,學出來中心節點的表達。
2、GAT
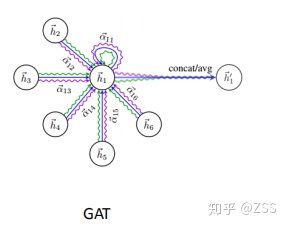
如圖3所示,GAT仍然是采用鄰域聚合的思想,想要學習h1表達,需要聚合h2~h6的特征,只是這里權重的學習使用了Attention機制。
3、GraphSAGE
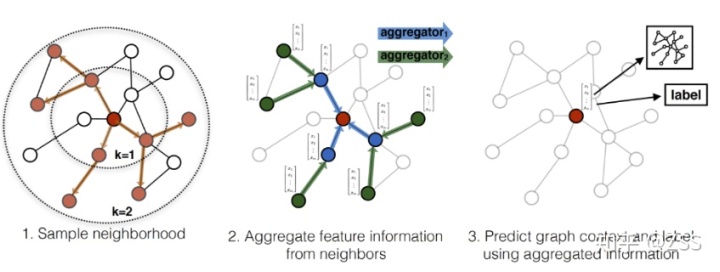
GCN、GAT都屬于直推學習(transductive),無法直接泛化到之前未見的節點。而GraphSAGE屬于歸納式(inductive)模型,能夠為新增節點快速生成embedding,而無需額外訓練過程。
主要由以下三部分組成:
鄰居采樣:因為每個節點的度是不一致的,為了計算高效, 為每個節點采樣固定數量的鄰居。
鄰居特征聚集:通過聚集采樣到的鄰居特征,更新當前節點的特征。
訓練:既可以用獲得的特征預測節點的上下文信息(context),也可以利用特征做有監督訓練。
4、Hierarchical Graph Representation Learning with Differentiable Pooling(NIPS 2018)
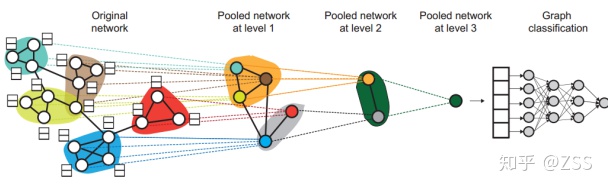
如圖5所示,層次化的圖卷積網絡加入了Pooling層,能夠捕捉圖的層次信息,擴大了感受野。但是,這里的Pooled network訓練十分困難,需要兩個Loss保證網絡能夠收斂,Pooled network at level 1,2,3各不相同,需要分別訓練。導致整個網絡參數量巨大。
Proposed Method
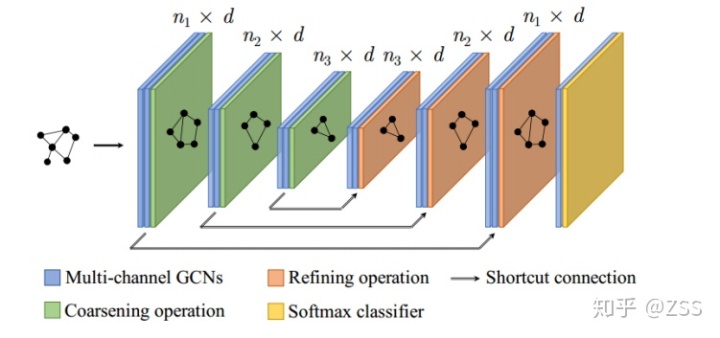
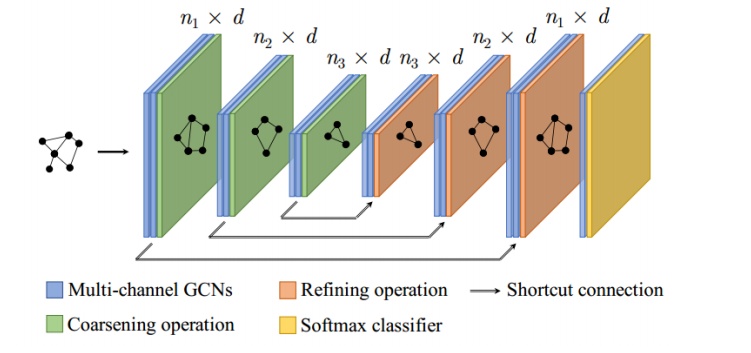
如圖6所示,H-GCN是一個對稱的網絡結構:在圖6的左側,在每次GCN操作后,我們使用Coarsening方法把結構相似的節點合并成超節點,因此可以逐層減小圖的規模。由于每個超點對應了原始圖中的一個局部結構,對超節點組成的超圖進行圖卷積操作就可以獲得更大的更大的感受野。對應地,在示意圖的右側,我們在每次GCN操作后將超節點進行還原,即可得到每個原始節點的表達。同時,我們在對稱的神經網絡層之間加了shortcut連接,從而可以更好地訓練。
具體的coarsening方法如圖7所示:
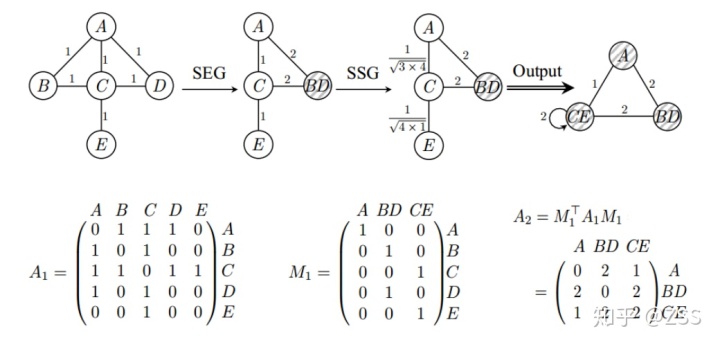
具體分為兩種情況:
(1)SEG(Structural Equivalence Grouping):合并鄰居節點完全相同的節點為一個超節點。
(2)SSG(Structural Similarity Grouping):按照結構相似度從大到小,合并相應的節點。結構相似性按照如下公式計算:
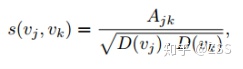
其中,Aij表示節點Vi,Vj所組成邊的權值,D(Vi),D(Vj)表示節點Vi,Vj的度。
Experiment
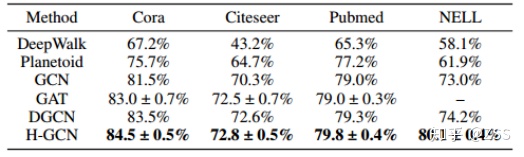
為了驗證H-GCN的有效性,作者在主流的節點分類任務上進行了測試,數據集包括引文數據集和知識圖譜。分類結果如圖8所示,H-GCN取得了SOTA的結果。
一個有意思的發現是:相比在引文數據集上的效果,H-GCN在知識圖譜數據集NELL上的精度遠遠超過其他baseline方法。這是因為在NELL數據集上的訓練數據量最少(僅0.3%的標記率),這可以定性地說明H-GCN能有效的增大感受野,使節點感受到相距比較遠的標記節點的標簽信息。
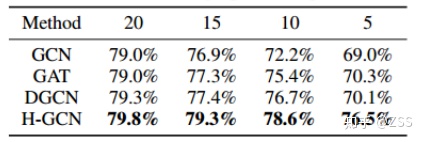
為了進一步定量驗證H-GCN對模型感受野的增大作用,作者在Pubmed上逐漸減小訓練數據量,從每類20個標記樣本到每類僅5個樣本,結果如圖9所示。可以發現,當訓練樣本逐漸減少時,baseline的精度下降非常明顯,而H-GCN卻能保持很高的準確率。在每類僅5個樣本時,H-GCN比其他方法至少高出6個百分點。這是個非常有用的性質,因為現實生活中由于海量的數據量和高昂的標記成本,我們通常沒有太多的標記樣本,而H-GCN更大的感受野可以更充分地利用標記樣本的標簽信息。
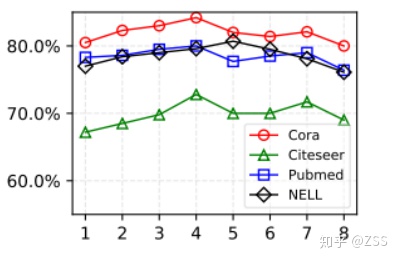
相比于傳統模型,H-GCN的一個特點是網絡層數更深了,作者進一步分析了層數加深對性能的影響。如圖10所示,當網絡層數加深時,精度逐漸提升,但是當網絡太深時,由于過擬合等原因,精度開始下降。在實驗中,我們在引文數據集上使用了4層粗化層(對應的網絡共有9層),在NELL數據集上使用了5層粗化層(對應的網絡共有11層),這可能是由數據集的規模不同導致的。因為NELL的數據集最大,所以網絡容量可以更大一點。
conclusion
圖數據上的coarsening/pooling機制可以有效地增大模型的感受野,從而獲取足夠的全局信息。不同于傳統的淺層圖神經網絡,作者提出了層次化的深度(分別為9層和11層)圖卷積模型H-GCN,在節點分類任務上取得了SOTA的結果。特別地,在訓練數據非常少的場景下,H-GCN的提升更為明顯。而在現實生活中由于海量的數據量和高昂的標記成本,我們通常沒有太多的標記樣本,而H-GCN更大的感受野可以更充分地利用標記樣本的標簽信息,進一步提高分類準確性。
.doc...)




SystemProcessesAndThreadsInformation)

函數實例用法講解)











