Java中的編譯分為兩個部分:
源碼文件編譯成字節碼文件(前端編譯)
字節碼文件被虛擬機加載以后編譯成機器碼(后端編譯)
對于開發來說接觸的一般都是第一個步驟也就是源碼編譯成字節碼文件(class文件),第二個步驟開發幾乎不會接觸,因為這是虛擬機在運行過程中自己做的一些編譯流程,將字節碼轉換成可被虛擬機識別執行的機器碼。
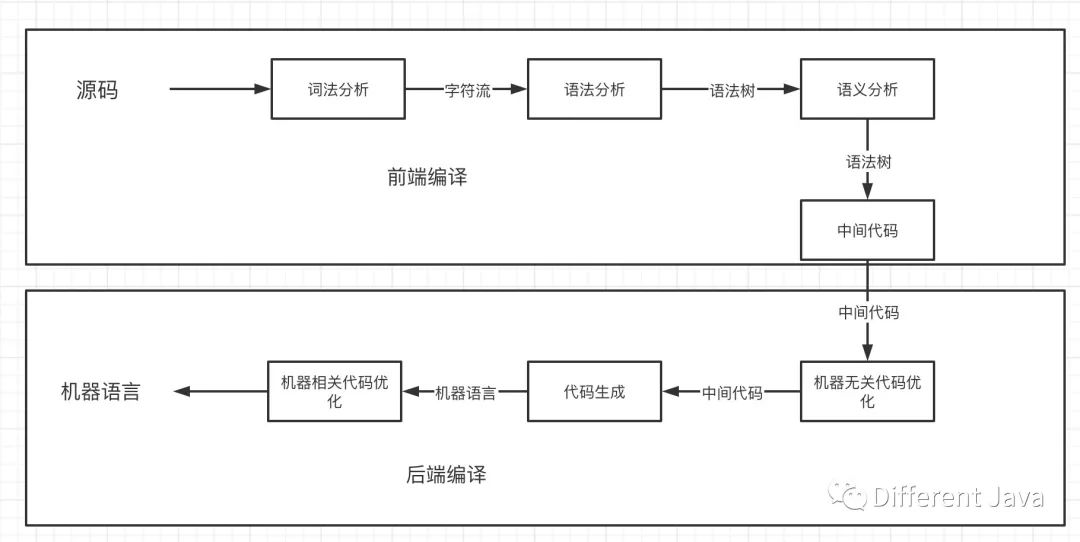
1. 前端編譯
前端編譯大致主要有以下流程:
對源文件進行詞法分析產生字符流
對字符流進行語法分析產生抽象語法樹
對語法樹進行語義分析,確保語義正常
語義分析通過以后生成中間代碼(字節碼)
下面我們站在javac的角度上看,編譯過程大致分為:
解析與填充符號表
插入式注解處理器的處理注解
語義分析與字節碼的生成
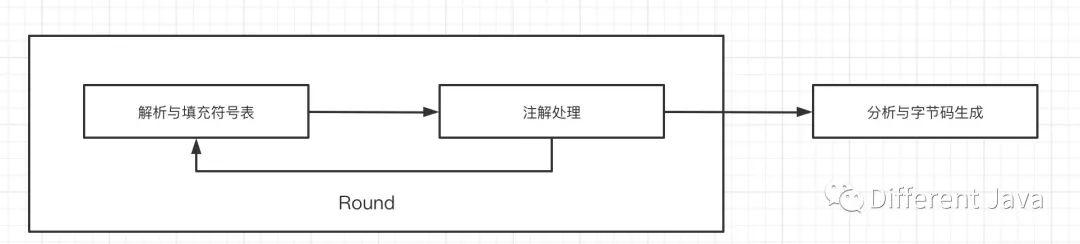
上述3個過程會包含前段編譯4個步驟的所有流程,下面我們看一下這個3個步驟需要做什么。
2. 解析與填充符號表
2.1 解析
2.1.1 詞法分析
Java源文件是由一個個字符構成,但是編譯器所能識別的是Token(標記)。我們需要通過詞法分析來將源文件中的字符流轉換成Token集合,這樣才能用于后續的語法分析。
int?a?=?b?+?c;
int是由3個字符構成,但是對于詞法分析來說,這三個字符會被解析成一個Token(標記)。
詞法分析主要由com.sun.tools.javac.parser.Scannaer類來實現。
2.1.2 語法分析
根據Token集合生成抽象語法樹,語法樹是一種用來表示程序代碼語法結構的表現形式,語法樹的每一個節點都代表著程序代碼中的一個語法結構,例如包、類型、修飾符。
package?jvm;
/**
*?@author?sh
*/
public?class?ClassTest{
public?int?add(int?a,?int?b){
return?a?+?b;
}
}
語法分析主要有com.sun.tools.javac.parser.Parser類來實現。
上述這段代碼生成的抽象語法樹如下(IDEA ?JDT AstView插件可以查看抽象語法樹):
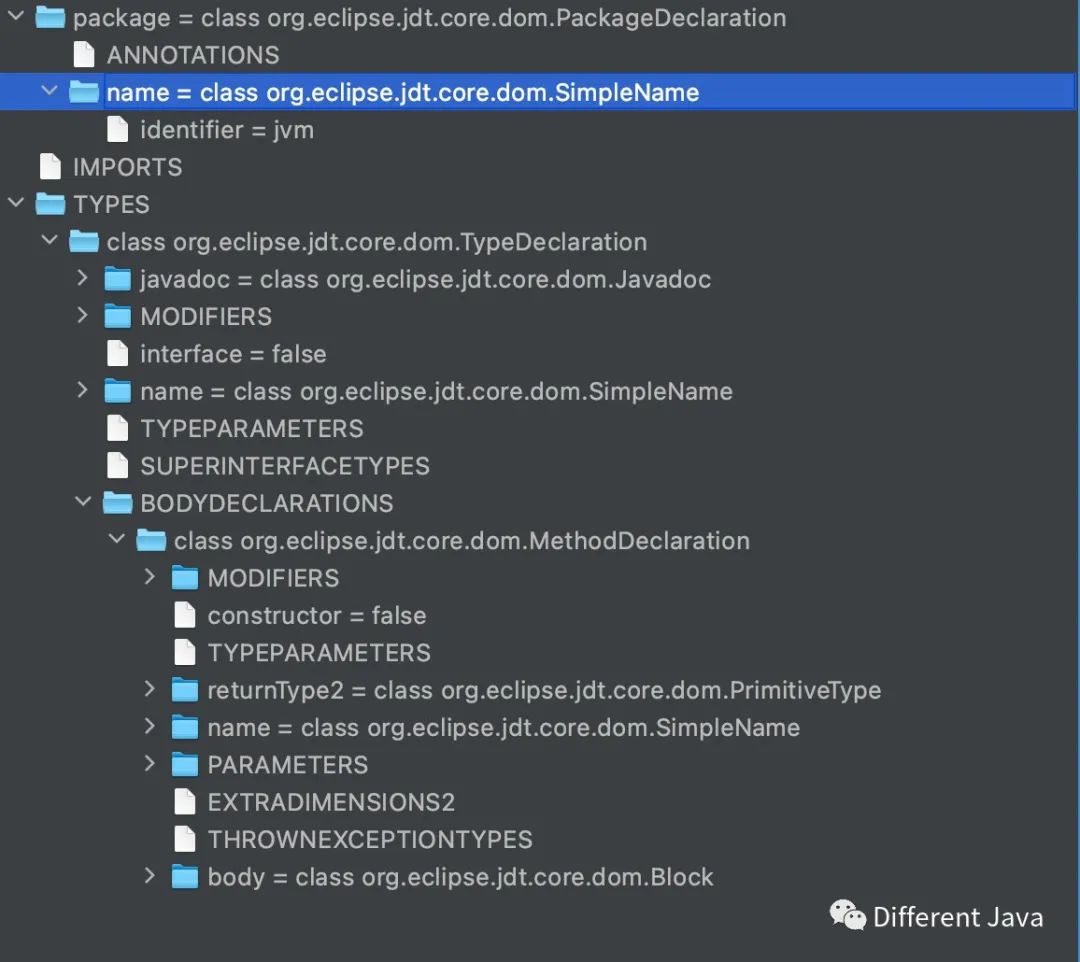
上述抽象語法樹在Java中使用com.sun.tools.javac.tree.JCTree類來表示,之后所有的操作均建立在抽象語法樹之上。
2.2 填充符號表
結束了詞法分析和語法分析以后,下一步就是填充符號表。符號表中信息可以用在語義分析過程中的檢查和產生中間代碼
3. 注解處理器
注解處理器在編譯期間對注解進行處理,可以讀取、修改、添加抽象語法樹中的任意元素。如果注解處理器對語法樹進行了修改,編譯器將會回到解析和填充符號表的過程重新處理,直到注解處理器不再對語法樹進行修改為止,每一次循環稱為一個Round。
4. 語義分析和字節碼生成
4.1 語義分析
語義分析主要是對程序上下文進行檢查,如變量類型檢查。
語義分析主要包含兩個步驟:
標注檢查
數據及控制流分析
4.1.1 標注檢查
標注檢查主要用來檢查變量是否已被聲明、變量與賦值之間的數據類型是否匹配。在標注檢查的步驟中還會實施常量折疊。
int?a?=?1?+?2;
上述代碼我們在語法樹上可以看到字面量1、2以及操作符+,在經過常量折疊步驟以后,會生成一個新的字面量3,在程序運行時a的值就是3,不會再消耗CPU進行計算。
4.1.2 數據及控制流分析
數據及控制流分析是對程序上下文邏輯進行驗證,檢查局部變量是否在使用前已經賦值、方法的每條路徑都有返回值、所有的受檢查異常是否被正確處理。
局部變量final類型的變量的不變性只能依靠編譯來保證,這是因為局部變量在常量池中沒有CONSTANT_Fieldref_info的符號引用,沒有訪問標志的信息,在運行期虛擬機并不確定局部變量是否是final,因此需要編譯期的保證。
4.2 字節碼生成
字節碼在生成之前,還需要進行最后一項工作解語法糖。
4.2.1 解語法糖
Java中的語法糖包括范型、變長參數、自動裝箱/拆箱、Lambda。
語法糖可以增加程序的可讀性、減少代碼量。
4.2.2 字節碼生成
字節碼生成是javac編譯的最后一個階段。字節碼生成階段不僅僅是把各個步驟生成的信息轉換成字節碼寫到磁盤,還進行了代碼的添加和轉換工作。
將static語句塊、static變量收斂到
方法中
將實例變量初始化、調用父類構造器收斂到
方法
程序優化,比如將字符串的+操作替換成StringBuilder的append
完成了語法樹的遍歷和調整以后,就會填充了所有信息的符號表交給com.sun.tools.javac.jvm.ClassWriter類,最后由該類的writeClass()方法輸出字節碼。
本期的Java前端編譯介紹到這,我們下期再見!!!
我是shysh95,希望可以和你專注技術的路上并肩作戰,長按識別或者掃碼關注微信公眾號,更多精彩文章!!!












 A. Snacktower)






