論文來源
- ICCV2017
- arXiv report
- github代碼(caffe-matlab)
本文的主要問題是行人檢測。作者探討了如何將語義分割應用在行人檢測上,提高檢測率,同時也不損壞檢測效率。作者提出了一種語義融合網絡(segmentation infusion networks)去促進在語義分割與行人檢測上的聯合監督。其中行人檢測為主要任務,語義分割主要起到了矯正,指導共享層的特征生成。作者在題目中提到了照亮行人。其實主要指的是通過語義分割的監督,可以使得生成的feature更聚焦在行人上,從而便于下游的行人檢測。
另外本文比較好的貢獻在于對網絡的設置很合適,也就是說語義分割層的設置恰到好處。因此就算使用弱標注的語義信息也足以提升性能。
背景介紹
行人檢測試計算機視覺中的核心問題,主要方法有兩種:目標檢測與語義分割。這兩種方法高度關聯,但有各自的優缺點。比如目標檢測可以定位不同的物體,但是很少能給出物體的邊界。而語義分割雖然能逐像素地定位物體的邊界,但是很難區別同類。
自然我們希望來自一個任務的知識能使得另一任務變得容易些。這在一研究的目標檢測中已經得到了實現。那么在行人檢測中卻研究地很少。部分原因是在傳統的行人數據集中缺乏逐像素的標注。
例如我們來看傳統的幾個數據集.
- Caltech
- KITTI
- KITTI數據集簡介與使用
此數據集為攝像機視野內的運動物體提供一個3D邊框標注(使用激光雷達的坐標系)。該數據集的標注一共分為8個類別:’Car’, ’Van’, ’Truck’, ’Pedestrian’, ’Person (sit- ting)’, ’Cyclist’, ’Tram’ 和’Misc’ (e.g., Trailers, Segways)。
以上兩個數據集,僅僅提供了行人的bounding box,沒有提供語義信息。
-
COCO
本數據集是一般的目標檢測數據集,可以從圖上看出它提供了豐富的標簽,既有位置信息,也有語義信息。 -
Cityscapes
此數據集提供了詳細的城市語義標注,當然也包含了行人的語義標注。此數據集的主要意圖就是促進語義分割在行人檢測上的應用。這也是本文的core所在。
Simultaneous Detection & Segmentation
有兩種方式來研究同時的檢測與分割。一種是同時促進兩種任務。例如我們廣知的Instance-aware segmentation .
其實上面的圖d就是典型的這類任務,它不同與以往的語義分割,而是在語義分割的基礎上還要求把同類的分開。其實就是分割+檢測。
第二種就是使用語義分割作為強線索明顯地提高目標檢測。其實很早,我讀過人臉加測與人臉特征點的一篇文章,
《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
這篇文章就是以人臉特征點檢測來促進人臉檢測的。其實人識別人臉往往就是識別人的五官來進行人臉檢測。那么在目標檢測中,語義信息往往提供了很強大的特征來促進檢測,并且可以抑制背景的干擾。但有些工作要求先有一個單獨的分割網絡才能進行檢測。我們的框架克服了這個缺點,可以將語義信息融合到shared feature maps,最后在準確性和性能上都有了提升。
方法解析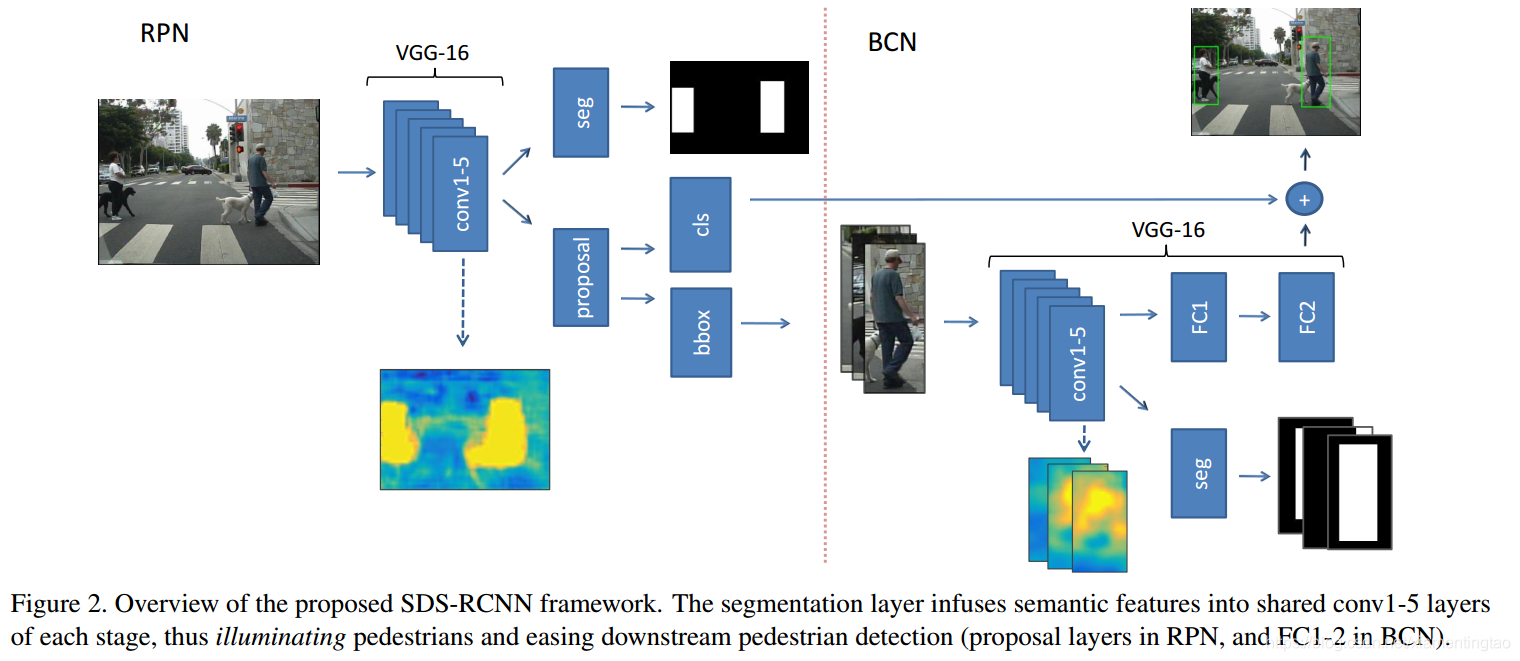
上面是整個網絡結構,包含了兩階段。第一階段使用rpn網絡提出行人檢測候選框與給出初步的分值。第二階段進一步地挖掘了hard sample,給出了對應的細化分數.由于rpn已經預測行人的位置足夠準確了,因此第二步只是單純的分類,沒有bounding box的回歸。而且兩個網絡的預測分數進行了疊加,作為最后的分類分數。
下面我們仔細闡述一下其中的道理。
RPN
RPN來源自Fatser rcnn,用來propose a set of bounding with associated confidence scores around pedestrains.
rpn網絡在某個feature map的每一點處分別枚舉出一定比例與尺度的anchor box,相當于在一個池化的圖像空間的一個滑動窗口。每一個proposal box i都對應一個anchor(指scale與aspect ratio)與圖像空間的一個位置。
如圖,rpn采用VGG-16的conv1-5作為backbone(提特征),然后接了兩個分層,一個層叫segementation infusion layer,另一個就是傳統的proposal layer,帶有兩個輸出層分別用于分類與bounding box回歸。
從網絡結構上看到,上面的segmentation infusion layer的ground truth 是兩個白色小方塊做成的mask,其實就是標注的行人檢測的bouding box的內部。然后經過兩個分層的聯合訓練,最終CONV1-5輸出的feature map明顯凸顯了行人,即照亮了行人。
此rpn的目標函數如下:
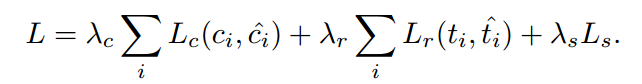
LcL_cLc?代表分類的損失,采用softmax logistic loss over two classes。(行人vs 背景)。此處將一個box識別為行人的法則是IoU>=0.5.
Lr是回歸損失。使用Lr(ti,ti^)=R(ti?ti^)L_r(t_i,\hat{t_i})=R(t_i-\hat{t_i})Lr?(ti?,ti?^?)=R(ti??ti?^?),R代表魯棒的L1損失。其中bounding box的偏移信息被定義成在x,y與在w,h上的偏移量,即t=[tx,ty,tw,th]t=[t_x,t_y,t_w,t_h]t=[tx?,ty?,tw?,th?].
Ls是語義分割的損失。后面闡述。
實驗中,λc=λs=1,λr=5\lambda_c=\lambda_s=1,\lambda_r=5λc?=λs?=1,λr?=5,顯然這里突出了回歸的重要性,因為回歸只有一次,而分類與語義分割就顯得沒那么重要。
BCN(Binary Classfication Network)
BCN主要完成在RPN提出的proposal的行人識別。作為一般的目標檢測,一般采用faster rcnn后端的識別部分即可。但是根據《Is faster rcnn doing well for pedestrian detection?》,faster rcnn的后端反而會degrade pedestrian detection accuracy。因此這里選擇使用VGG-16構建一個單獨的識別網絡。
這個網絡主要在于識別RPN遺忘的hard example。提高那些遮擋、變形等行人的分數,從而可以將其檢測出來。
當然了,此部分仍然增加了語義信息,提高識別率。
此部分的目標函數如下:
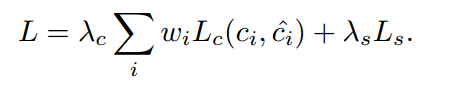
其中主要特點如下:
- LcL_cLc?指的是分類損失,其中這里cic_ici?是第i個proposal的類別標簽,而ci^\hat{c_i}ci?^?則融合了來自RPN與BCN的分數。
具體說來,對于第i個Proposal,給定RPN的預測兩類分數為{c^i0r,c^i1r}\left \{ \hat{c}_{i0}^r, \hat{c}_{i1}^r \right \}{c^i0r?,c^i1r?},BCN的分數為{c^i0b,c^i1b}\left \{ \hat{c}_{i0}^b, \hat{c}_{i1}^b \right \}{c^i0b?,c^i1b?},則融合后的分數為:
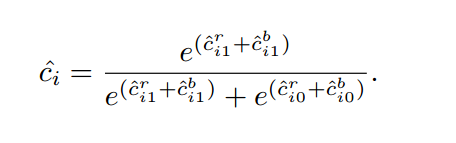
這里重點說一下,他這里給出的融合分數到底有何技巧?正如下面一章【問題1】提出的,這里為什么要這樣取分數?而且這里的分類損失又是什么呢?
我們先來看看一般,如RPN中的分類損失怎么計算,實際上是使用softmax-logistic loss,也就是先計算softmax得分,再求label對應的logistic似然損失,最后令其最小化。
那么我們這里呢,肯定也是使用似然損失,那么如何計算label對應的分數呢?是不是也是使用softmax呢?
我們觀測這里給出的c^i\hat{c}_ic^i? ,其實就是softmax的形式。而這里原始的分數就是RPN+BCN之和。
而且這里省略了一個分數,即預測其為背景的分數,即1?c^i1-\hat{c}_i1?c^i?。
2. 設置了cost-sensitive的權重wiw_iwi?,用來優先檢測大的行人。其中wi=1+hihw_i=1+\frac{h_i}{h}wi?=1+hhi??,其中hih_ihi?為第i個proposal 的高,h為預計算的平均高。
3. 采取了更加嚴格的labeling policy,要求 a proposal to have IoU > 0.7 with a ground truth pedestrian box to be considered pedestrian (ci = 1), and otherwise background (ci = 0).
Simultaneous Detection & Segmentation
無論在RPN還是在BCN,都集合了融合layer.The segmentation infusion layer旨在輸出兩個mask揭示行人與背景分割的可能性 .這里選擇使用僅僅一個layer和一個1x1的核,以至于盡可能高地施加影響到共享的層,從而驅使網絡去直接融合語義特征到shared feature map。
Ls是一個在兩類(行人vs 背景)的softmax logistic loss,應用于每一個位置i,同時也引入了cost-sensitive weight 即wiw_iwi?.
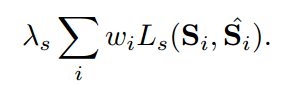
這里SiS_iSi?可以取所有行人的bounding box內的所有區域標注為1,其他區域為0. 也就是weak segmentation ground truth masks。這就是很大的優勢,不再需要嚴格的標注信息。
這樣做是可行的,因為我們將會融合層放在了conv5后面,此時圖像已經經過了多層降采樣。也就是基于box的標注與基于pixel的標注已經基本相同了。
那么具體怎么計算LsL_sLs?呢?文中提到使用softmax logistic loss。那么這里的i應該指的bounding box的序號。因為有一個權重wiw_iwi?的存在(我猜測)。
則Ls(Si,S^i)L_s(S_i,\hat{S}_i)Ls?(Si?,S^i?)應該針對每一個bounding box內的像素計算。使用infusion layer獲取每一個像素的預測值(行人VS背景),那么我們就可以計算每一個像素點的二分類分數,對于bounding box內的像素點,取行人的預測分數,進而計算似然損失,并將其加起來,作為最后的LsL_sLs?。而對于bounding box以外的區域,則取背景的預測分數,進而計算似然損失。也加起來,作為一個LsL_sLs?。
留下一個疑問,對于非盒子區域的S,如何計算權重呢?或者是不是不再需要權重了??
實驗設計
實驗設計其實就是兩方面,一方面與baseline進行比較,一方面解釋上述網絡設計的可行性,也就是ablation study.
如下圖,作者進行了 weak segmentation supervision,proposal padding, cost-sensitive weighting, and stricter supervision以及stage-wise fusion的研究。
對于weak segmentation supervision,proposal padding, cost-sensitive weighting, and stricter supervision,作者分別切除了每一部分,分別計算RPN,BCN以及Fusion的miss rate.
- 這里RPN很明白,可以直接輸入圖片,禁掉了 weak segmentation supervision,進而檢測行人,計算miss rate。
- BCN呢?輸入是什么?在原文中,BCN直接輸入的是proposal裁剪測圖像。這里應該還是如此,只不過禁掉了 weak segmentation supervisio,但是RPN中正常,不要禁掉weak segmentation supervision。
- Fusion則全部禁掉weak segmentation supervision.
對于最后一行的SDS-RCNN,BCN則還是需要以RPN為輸入,只不過分數不再融合,直接計算其分類得分,從而檢測行人。而Fusion則融合RPN與BCN的分數。
問題
- BCN(Binary Classfication Network)的分數融合機制是否是最優的,文中提到:
也即是說兩個網絡進行了互補機制,一句話概括就是好上加好,優中選優。
具體說來,當RPN網絡預測某個proposal為行人的分數很高,而BCN網絡也如此,則顯然,最后預測行人的分數會很高。相反對于一些hard example,可能RPN預測地很低,而BCN預測地很高,則最終的結果如何呢?這實際上取決于二者分數的綜合效果,其實就是兩者的和,如果行人分數的和大于背景分數的和,則最終預測行人的分數就很高。反之,則可能還是背景。這也說明,只有BCN預測hard example的能力足夠強,才能形成互補機制。對于一些模棱兩可的example,即使BCN預測其為行人的分數較高,但如果不是足夠高,則最終也不能將其判為行人,這實際上就減輕了false positive的壓力。 - softmax logistic loss??
參考 softmax logistic loss詳解



![[C#]async和await刨根問底](http://pic.xiahunao.cn/[C#]async和await刨根問底)















