最佳參考鏈接
https://opensourceteam.gitbooks.io/bigdata/content/spark/install/spark-160-bin-hadoop26an_zhuang.html
?
Apache Spark1.1.0部署與開發環境搭建 Spark是Apache公司推出的一種基于Hadoop Distributed File System(HDFS)的并行計算架構。與MapReduce不同,Spark并不局限于編寫map和reduce兩個方法,其提供了更為強大的內存計算(in-memory computing)模型,使得用戶可以通過編程將數據讀取到集群的內存當中,并且可以方便用戶快速地重復查詢,非常適合用于實現機器學習算法。本文將介紹Apache Spark1.1.0部署與開發環境搭建。 0. 準備 出于學習目的,本文將Spark部署在虛擬機中,虛擬機選擇VMware WorkStation。在虛擬機中,需要安裝以下軟件: Ubuntu 14.04.1 LTS 64位桌面版 但是ubuntu 的桌面版我安裝以后有問題 所以下載了server版本 然后安裝桌面就可以了http://jingyan.baidu.com/article/64d05a0262b613de55f73b0e.html
參考http://www.cnblogs.com/datahunter/p/4002331.html和http://www.cnblogs.com/datahunter/p/4002331.html
如何為ubuntu server 14.04 安裝圖形界面
出于學習目的,本文將Spark部署在虛擬機中,虛擬機選擇VMware WorkStation。在虛擬機中,需要安裝以下軟件:
- Ubuntu 14.04.1 LTS 64位桌面版
- hadoop-2.4.0.tar.gz
- jdk-7u67-linux-x64.tar.gz?
- scala-2.10.4.tgz
- spark-1.1.0-bin-hadoop2.4.tgz
Spark的開發環境,本文選擇Windows7平臺,IDE選擇IntelliJ IDEA。在Windows中,需要安裝以下軟件:
- IntelliJ IDEA?13.1.4?Community Edition
- apache-maven-3.2.3-bin.zip(安裝過程比較簡單,請讀者自行安裝)
方法/步驟
-
首先,ubuntu server版本的安裝這里就不再贅述,基本的還是三個步驟,首先是下載鏡像,然后使用ultraISO刻錄至u盤,最后通過U盤引導進行安裝。安裝過程中,會要求你輸入用戶名和密碼,一定要牢記,因為后續軟件的安裝都需要密碼。
-
然后,login進入系統之后,開始進行用戶界面的安裝。首先輸入如下命令:
sudo apt-get install xinit。安裝時的界面如下所示。
 步驟閱讀
步驟閱讀 -
上述安裝完畢之后,再安裝環境管理器。本人親測安裝的是GNOME。使用如下命令安裝:
sudo apt-get install gdm
安裝時的界面如下所示。
 步驟閱讀
步驟閱讀 -
然后,安裝桌面環境。本人親測安裝的是KUbuntu。安裝命令如下:
sudo apt-get install kubuntu-desktop
安裝時的界面如下所示。
步驟閱讀步驟閱讀
-
網上有人還說要安裝一些必要的包,如新立得軟件包管理器,中文支持等,如果你嫌麻煩,可以不進行安裝。上述安裝完畢之后,直接重啟。重啟完成后,再進入系統,便是圖形界面了,如圖所示。
 步驟閱讀步驟閱讀END
步驟閱讀步驟閱讀END
?
注意事項
- 一定要保證上述步驟每一個步驟都執行成功,否則會影響最后的結果
1. 安裝JDK
解壓jdk安裝包到/usr/lib目錄:
1 sudo cp jdk-7u67-linux-x64.gz /usr/lib 2 cd /usr/lib 3 sudo tar -xvzf jdk-7u67-linux-x64.gz 4 sudo gedit /etc/profile
在/etc/profile文件的末尾添加環境變量:
1 export JAVA_HOME=/usr/lib/jdk1.7.0_67 2 export JRE_HOME=/usr/lib/jdk1.7.0_67/jre 3 export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH 4 export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
保存并更新/etc/profile:
1 source /etc/profile
測試jdk是否安裝成功:
1 java -version

?
2. 安裝及配置SSH
1 sudo apt-get update 2 sudo apt-get install openssh-server 3 sudo /etc/init.d/ssh start
生成并添加密鑰:
1 ssh-keygen -t rsa -P "" 2 /root/.ssh/
3 cd /root/.ssh/ 4 cat id_rsa.pub >> authorized_keys
ssh登錄:
1 ssh localhost
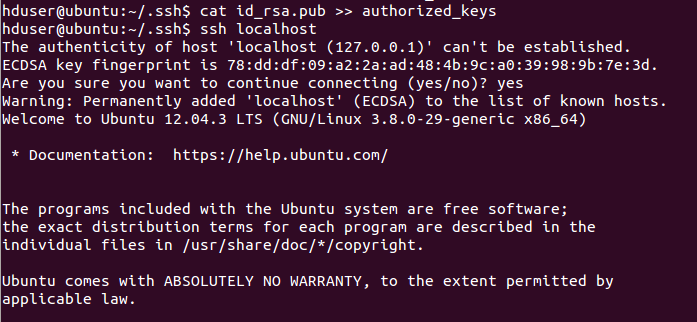
?
3. 安裝hadoop2.4.0
采用偽分布模式安裝hadoop2.4.0。解壓hadoop2.4.0到/usr/local目錄:
1 sudo cp hadoop-2.4.0.tar.gz /usr/local/ 2 sudo tar -xzvf hadoop-2.4.0.tar.gz
在/etc/profile文件的末尾添加環境變量:
1 export HADOOP_HOME=/usr/local/hadoop-2.4.0 2 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH 3 4 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native 5 export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
保存并更新/etc/profile:
1 source /etc/profile
在位于/usr/local/hadoop-2.4.0/etc/hadoop的hadoop-env.sh和yarn-env.sh文件中修改jdk路徑:
1 cd /usr/local/hadoop-2.4.0/etc/hadoop 2 sudo gedit hadoop-env.sh 3 sudo gedit yarn-evn.sh
hadoop-env.sh:

yarn-env.sh:

修改core-site.xml:
1 sudo gedit core-site.xml
在<configuration></configuration>之間添加:

1 <property> 2 <name>fs.default.name</name> 3 <value>hdfs://localhost:9000</value> 4 </property> 5 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <value>/app/hadoop/tmp</value> 9 </property>
修改hdfs-site.xml:
1 sudo gedit hdfs-site.xml
在<configuration></configuration>之間添加:
1 <property>2 <name>dfs.namenode.name.dir</name>3 <value>/app/hadoop/dfs/nn</value>4 </property>5 6 <property>7 <name>dfs.namenode.data.dir</name>8 <value>/app/hadoop/dfs/dn</value>9 </property> 10 11 <property> 12 <name>dfs.replication</name> 13 <value>1</value> 14 </property>
修改yarn-site.xml:
1 sudo gedit yarn-site.xml
在<configuration></configuration>之間添加:
1 <property> 2 <name>mapreduce.framework.name</name> 3 <value>yarn</value> 4 </property> 5 6 <property> 7 <name>yarn.nodemanager.aux-services</name> 8 <value>mapreduce_shuffle</value> 9 </property>
復制并重命名mapred-site.xml.template為mapred-site.xml:
1 sudo cp mapred-site.xml.template mapred-site.xml 2 sudo gedit mapred-site.xml
在<configuration></configuration>之間添加:
1 <property> 2 <name>mapreduce.jobtracker.address </name> 3 <value>hdfs://localhost:9001</value> 4 </property>
在啟動hadoop之前,為防止可能出現無法寫入log的問題,記得為/app目錄設置權限:
1 sudo mkdir /app 2 sudo chmod -R hduser:hduser /app
格式化hadoop:
1 sbin/hadoop namenode -format
啟動hdfs和yarn。在開發Spark時,僅需要啟動hdfs:
1 sbin/start-dfs.sh 2 sbin/start-yarn.sh
? 在瀏覽器中打開地址http://localhost:50070/可以查看hdfs狀態信息:
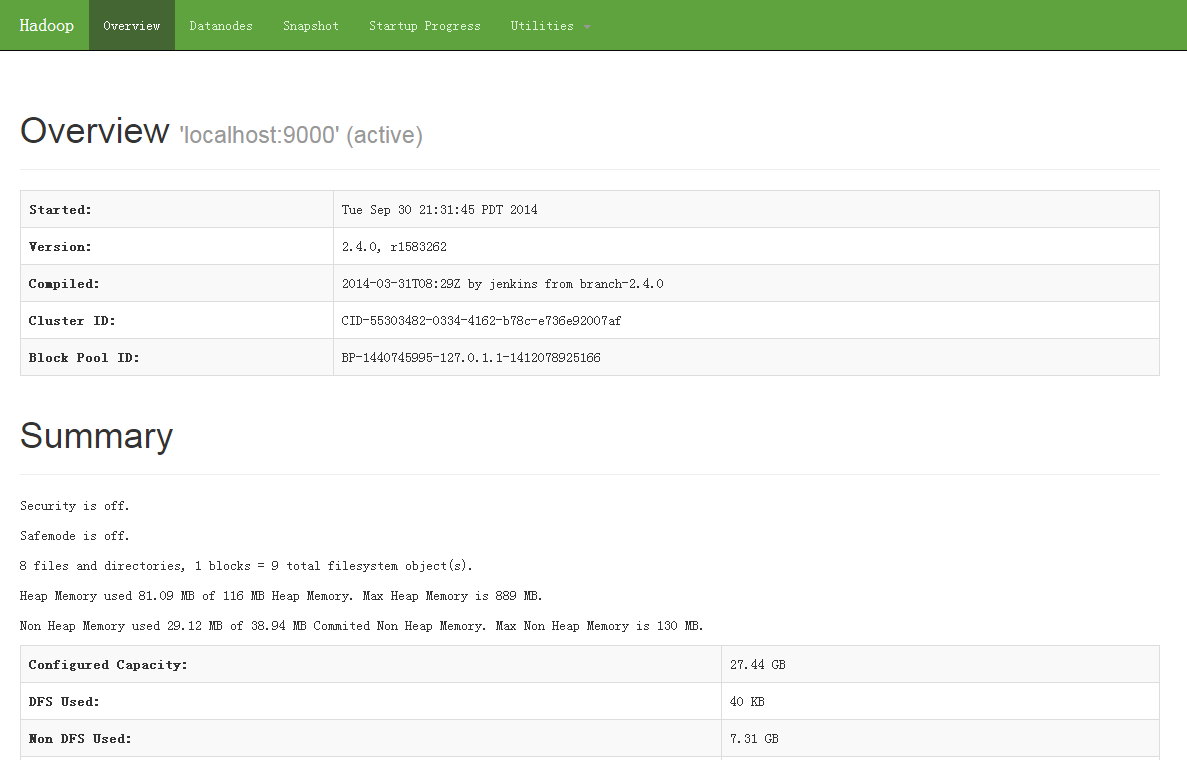
?
4. 安裝scala
1 sudo cp /home/hduser/Download/scala-2.9.3.tgz /usr/local 2 sudo tar -xvzf scala-2.9.3.tgz
在/etc/profile文件的末尾添加環境變量:
1 export SCALA_HOME=/usr/local/scala-2.9.3 2 export PATH=$SCALA_HOME/bin:$PATH
保存并更新/etc/profile:
1 source /etc/profile
測試scala是否安裝成功:
1 scala -version
?
5. 安裝Spark
1 sudo cp spark-1.1.0-bin-hadoop2.4.tgz /usr/local 2 sudo tar -xvzf spark-1.1.0-bin-hadoop2.4.tgz
在/etc/profile文件的末尾添加環境變量:
1 export SPARK_HOME=/usr/local/spark-1.1.0-bin-hadoop2.4 2 export PATH=$SPARK_HOME/bin:$PATH
保存并更新/etc/profile:
1 source /etc/profile
復制并重命名spark-env.sh.template為spark-env.sh:
1 sudo cp spark-env.sh.template spark-env.sh 2 sudo gedit spark-env.sh
在spark-env.sh中添加:
1 export SCALA_HOME=/usr/local/scala-2.9.3 2 export JAVA_HOME=/usr/lib/jdk1.7.0_67 3 export SPARK_MASTER_IP=localhost 4 export SPARK_WORKER_MEMORY=1000m
啟動Spark:
1 cd /usr/local/spark-1.1.0-bin-hadoop2.4 2 sbin/start-all.sh
測試Spark是否安裝成功:
1 cd /usr/local/spark-1.1.0-bin-hadoop2.4 2 bin/run-example SparkPi
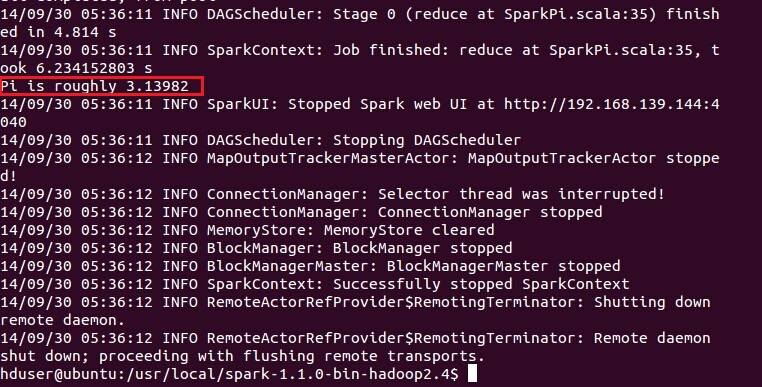
?
6. 搭建Spark開發環境
本文開發Spark的IDE推薦IntelliJ IDEA,當然也可以選擇Eclipse。在使用IntelliJ IDEA之前,需要安裝scala的插件。點擊Configure:
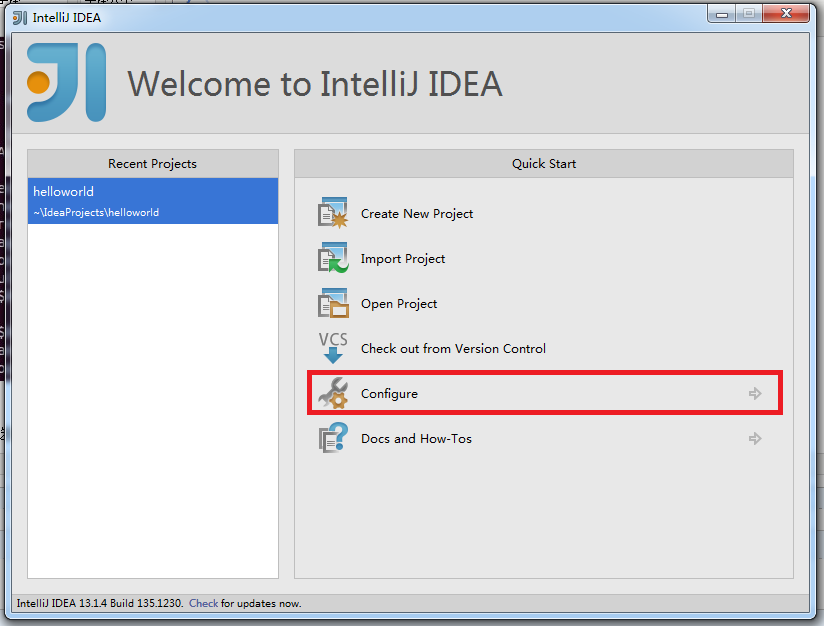
點擊Plugins:

點擊Browse repositories...:
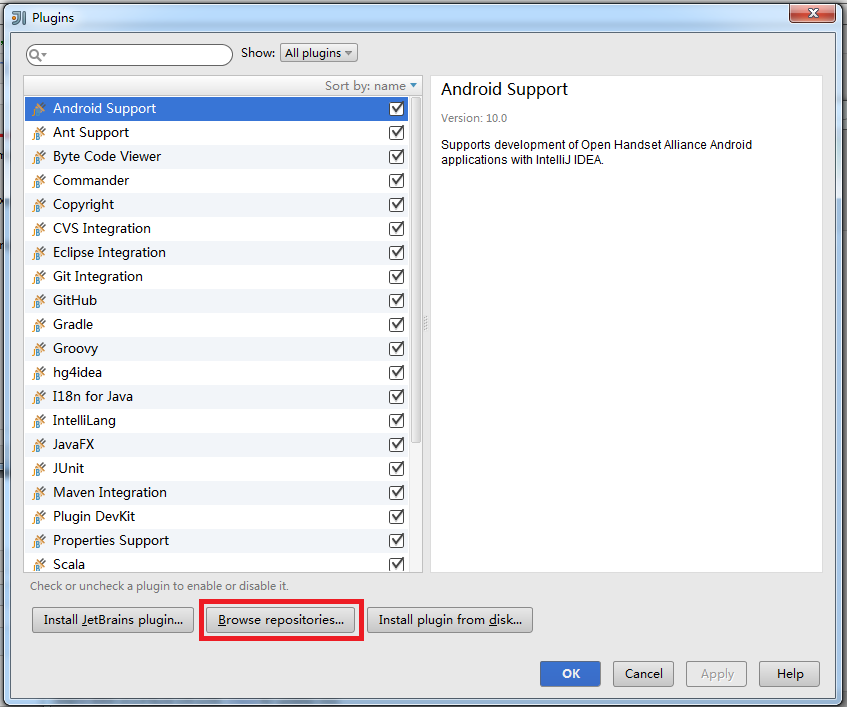
在搜索框內輸入scala,選擇Scala插件進行安裝。由于已經安裝了這個插件,下圖沒有顯示安裝選項:
安裝完成后,IntelliJ IDEA會要求重啟。重啟后,點擊Create New Project:

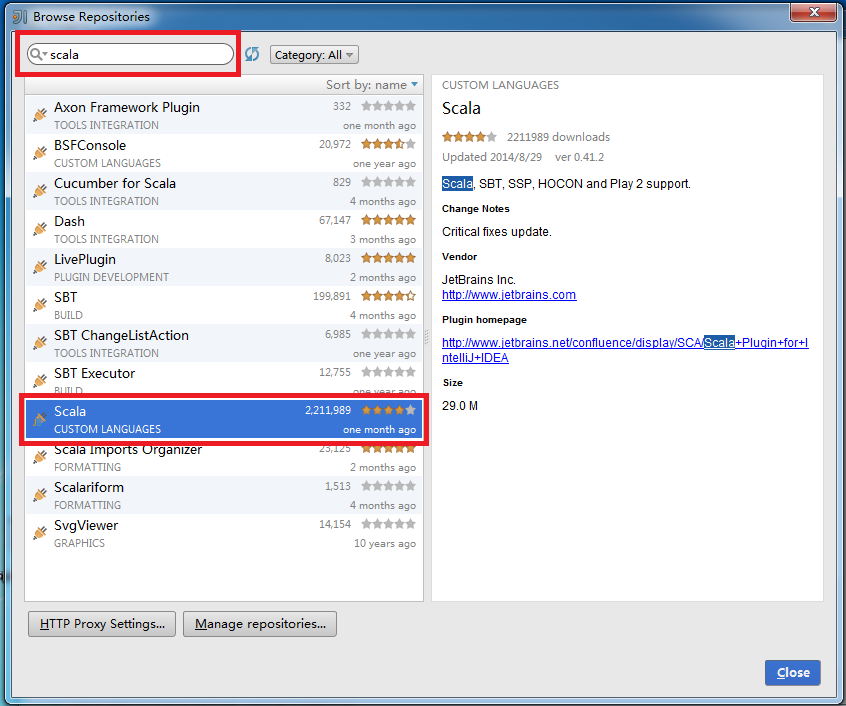
Project SDK選擇jdk安裝目錄,建議開發環境中的jdk版本與Spark集群上的jdk版本保持一致。點擊左側的Maven,勾選Create from archetype,選擇org.scala-tools.archetypes:scala-archetype-simple:
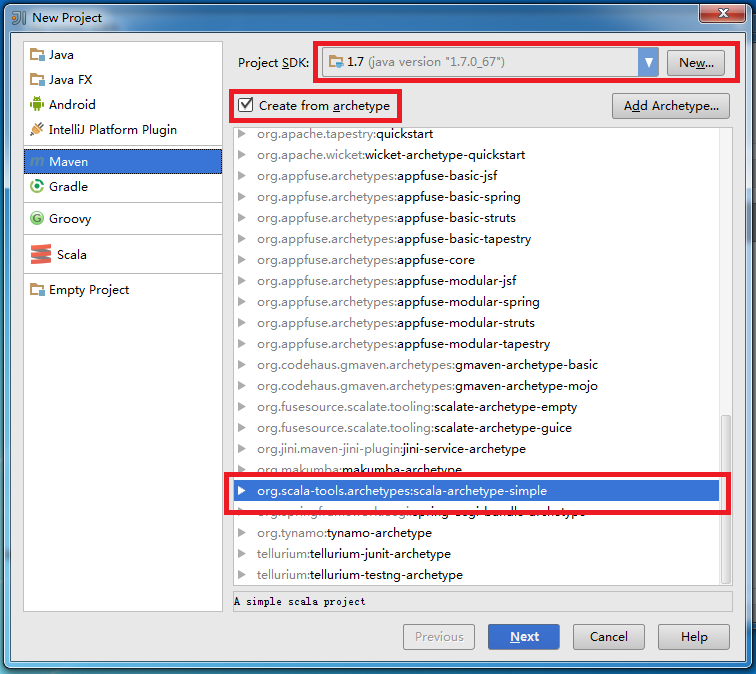
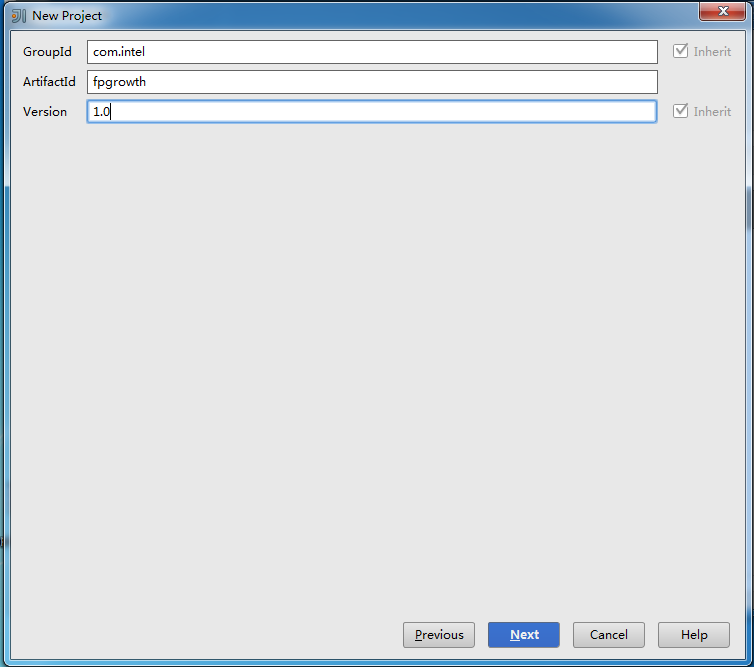
? 點擊Next后,可根據需求自行填寫GroupId,ArtifactId和Version:
? 點擊Next后,如果本機沒有安裝maven會報錯,請保證之前已經安裝maven:
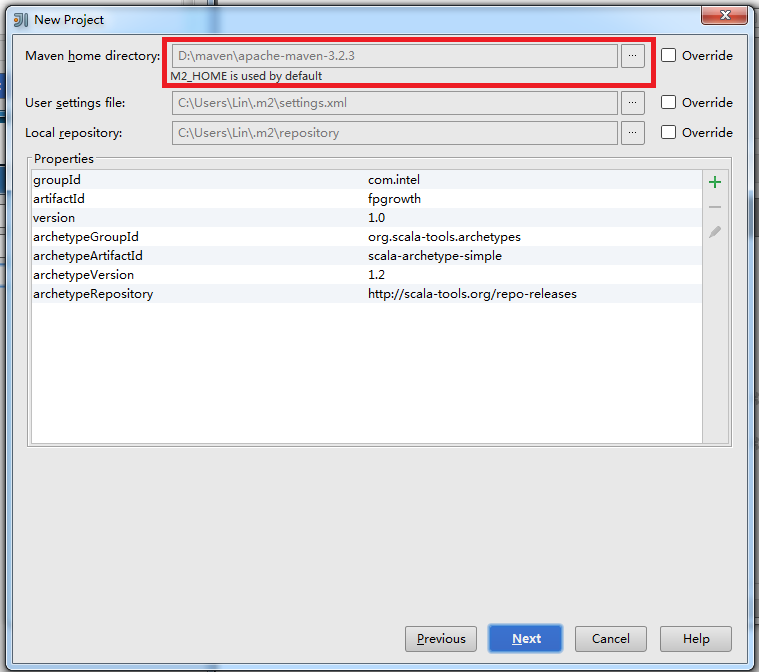
點擊Next后,輸入文件名,完成New Project的最后一步:
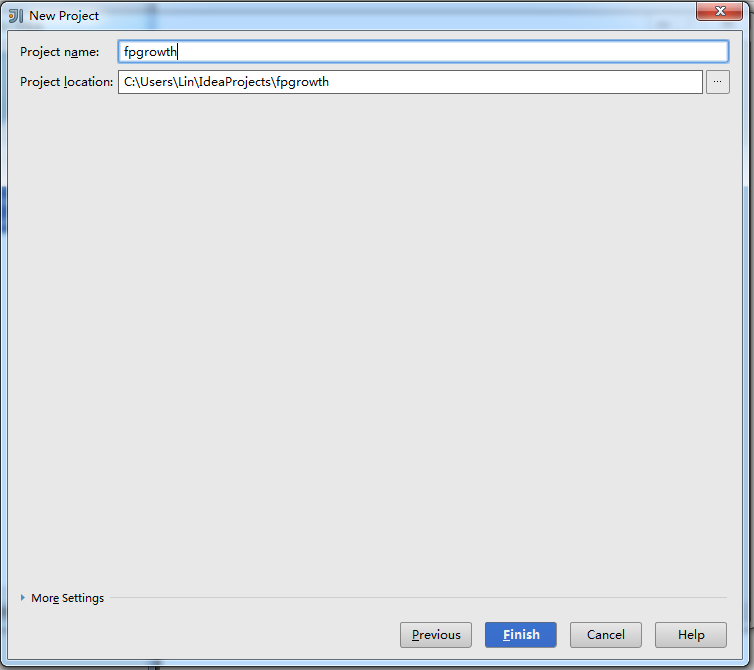
點擊Finish后,maven會自動生成pom.xml和下載依賴包。我們需要修改pom.xml中scala的版本:
1 <properties> 2 <scala.version>2.10.4</scala.version> 3 </properties>
在<dependencies></dependencies>之間添加配置:
1 <!-- Spark -->2 <dependency>3 <groupId>org.apache.spark</groupId>4 <artifactId>spark-core_2.10</artifactId>5 <version>1.1.0</version>6 </dependency>7 8 <!-- HDFS -->9 <dependency> 10 <groupId>org.apache.hadoop</groupId> 11 <artifactId>hadoop-client</artifactId> 12 <version>2.4.0</version> 13 </dependency>
在<build><plugins></plugins></build>之間添加配置:
1 <plugin>2 <groupId>org.apache.maven.plugins</groupId>3 <artifactId>maven-shade-plugin</artifactId>4 <version>2.2</version>5 <executions>6 <execution>7 <phase>package</phase>8 <goals>9 <goal>shade</goal> 10 </goals> 11 <configuration> 12 <filters> 13 <filter> 14 <artifact>*:*</artifact> 15 <excludes> 16 <exclude>META-INF/*SF</exclude> 17 <exclude>META-INF/*.DSA</exclude> 18 <exclude>META-INF/*.RSA</exclude> 19 </excludes> 20 </filter> 21 </filters> 22 <transformers> 23 <transformer 24 implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> 25 <mainClass>mark.lin.App</mainClass> // 記得修改成你的mainClass 26 </transformer> 27 <transformer 28 implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> 29 <resource>reference.conf</resource> 30 </transformer> 31 </transformers> 32 <shadedArtifactAttached>true</shadedArtifactAttached> 33 <shadedClassifierName>executable</shadedClassifierName> 34 </configuration> 35 </execution> 36 </executions> 37 </plugin>
Spark的開發環境至此搭建完成。One more thing,wordcount的示例代碼:
1 package mark.lin //別忘了修改package2 3 import org.apache.spark.{SparkConf, SparkContext}4 import org.apache.spark.SparkContext._5 6 import scala.collection.mutable.ListBuffer7 8 /**9 * Hello world!
10 *
11 */
12 object App{
13 def main(args: Array[String]) {
14 if (args.length != 1) {
15 println("Usage: java -jar code.jar dependencies.jar")
16 System.exit(0)
17 }
18 val jars = ListBuffer[String]()
19 args(0).split(",").map(jars += _)
20
21 val conf = new SparkConf()
22 conf.setMaster("spark://localhost:7077").setAppName("wordcount").set("spark.executor.memory", "128m").setJars(jars)
23
24 val sc = new SparkContext(conf)
25
26 val file = sc.textFile("hdfs://localhost:9000/hduser/wordcount/input/input.csv")
27 val count = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)
28 println(count)
29 count.saveAsTextFile("hdfs://localhost:9000/hduser/wordcount/output/")
30 sc.stop()
31 }
32 } ?
7. 編譯&運行
使用maven編譯源代碼。點擊左下角,點擊右側package,點擊綠色三角形,開始編譯。

? 在target目錄下,可以看到maven生成的jar包。其中,hellworld-1.0-SNAPSHOT-executable.jar是我們需要放到Spark集群上運行的。
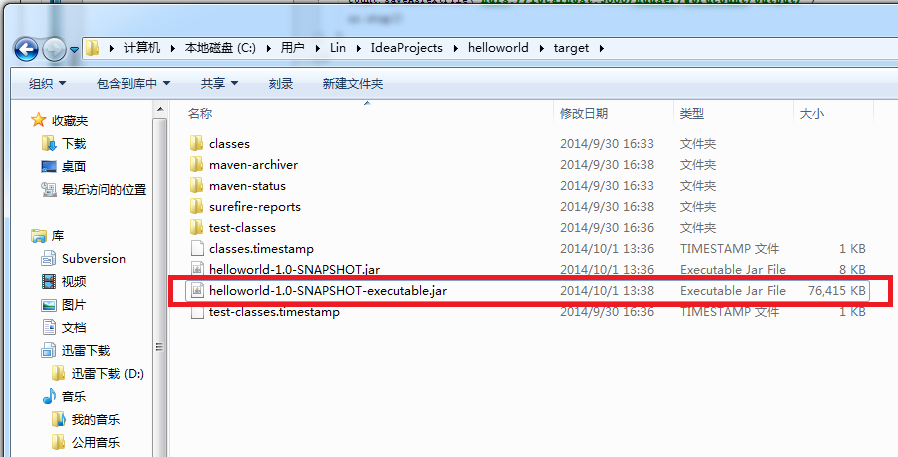 ?
?
在運行jar包之前,保證hadoop和Spark處于運行狀態:
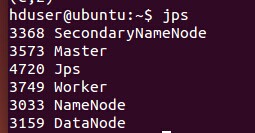
將jar包拷貝到Ubuntu的本地文件系統上,輸入以下命令運行jar包:
1 java -jar helloworld-1.0-SNAPSHOT-executable.jar helloworld-1.0-SNAPSHOT-executable.jar
在瀏覽器中輸入地址http://localhost:8080/可以查看任務運行情況:

?
8. Q&A
Q:在Spark集群上運行jar包,拋出異常“No FileSystem for scheme: hdfs”:

A:這是由于hadoop-common-2.4.0.jar中的core-default.xml缺少hfds的相關配置屬性引起的異常。在maven倉庫目錄下找到hadoop-common-2.4.0.jar,以rar的打開方式打開:
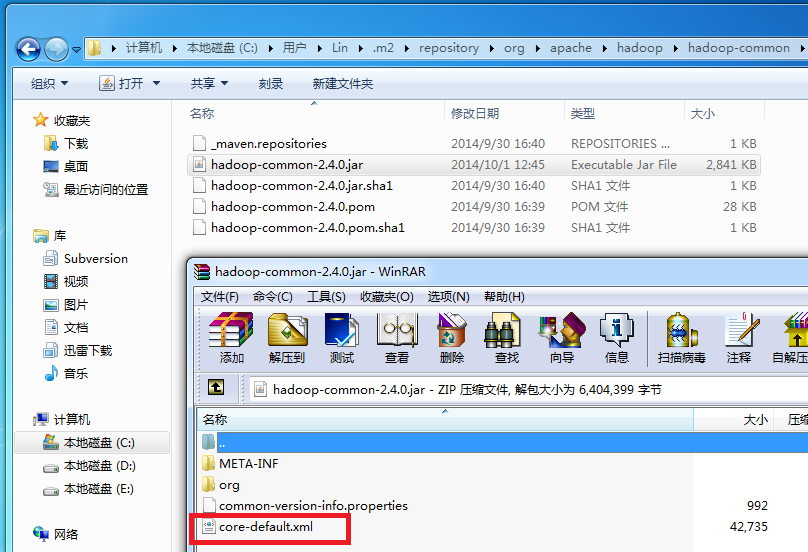
將core-default.xml拖出,并添加配置:
1 <property> 2 <name>fs.hdfs.impl</name> 3 <value>org.apache.hadoop.hdfs.DistributedFileSystem</value> 4 <description>The FileSystem for hdfs: uris.</description> 5 </property>
再將修改后的core-default.xml替換hadoop-common-2.4.0.jar中的core-default.xml,重新編譯生成jar包。
?
Q:在Spark集群上運行jar包,拋出異常“Failed on local exception”:

A:檢查你的代碼,一般是由于hdfs路徑錯誤引起。
?
Q:在Spark集群上運行jar包,重復提示“Connecting to master spark”:

A:檢查你的代碼,一般是由于setMaster路徑錯誤引起。
?
Q:在Spark集群上運行jar包,重復提示“Initial job has not accepted any resource; check your cluster UI to ensure that workers are registered and have sufficient memory”:

A:檢查你的代碼,一般是由于內存設置不合理引起。此外,還需要檢查Spark安裝目錄下的conf/spark-env.sh對worker內存的設置。
?
Q:maven報錯:error: org.specs.Specification does not have a constructor
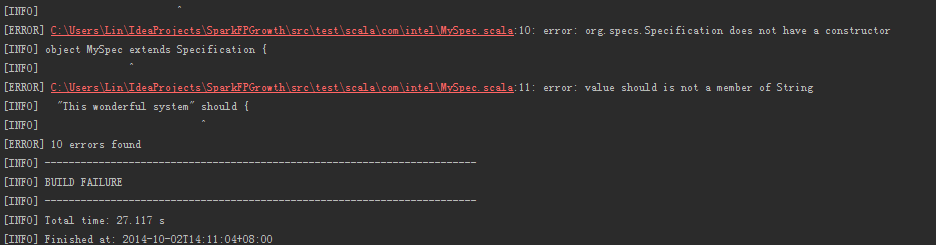
A: 刪除test目錄下的文件,重新編譯。
?
9. 參考資料
?[1] Spark Documentation from Apache. [Link]
?











 遞推 斐波拉數列的應用...)







![兩個數組a[N],b[N],其中A[N]的各個元素值已知,現給b[i]賦值,b[i] = a[0]*a[1]*a[2]…*a[N-1]/a[i];...](http://pic.xiahunao.cn/兩個數組a[N],b[N],其中A[N]的各個元素值已知,現給b[i]賦值,b[i] = a[0]*a[1]*a[2]…*a[N-1]/a[i];...)