1. 官網下載
wget?http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.7.tgz
?
2. 解壓

tar -zxvf?spark-2.0.1-bin-hadoop2.7.tgz
ln -s?spark-2.0.1-bin-hadoop2.7 spark2
?
3. 環境變量

vi /etc/profile
#Spark 2.0.1
export SPARK_HOME=/usr/local/spark2
export PATH=$PATH:$SPARK_HOME/bin
?
4. 配置文件(/usr/local/spark2/conf)
1)?spark-env.sh
cp -a spark-env.sh.template spark-env.sh

vi?spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8
export SPARK_MASTER_HOST=cdh01
2)?slaves
cp -a slaves.template slaves

vi slaves
cdh02
cdh03
?
5.?復制到其他節點
scp -r spark-2.0.1-bin-hadoop2.7?root@cdh02:/usr/local
scp -r?spark-2.0.1-bin-hadoop2.7?root@cdh03:/usr/local
?
6.?啟動
$SPARK_HOME/sbin/start-all.sh
?
7. 運行
1) 準備一個文本文件放在/logs/wordcount.log內容為:
hdfs hbase hive hdfs
hive hbase spark spark
spark spark spark
2) 運行spark-shell
3) 運行wordcount

?
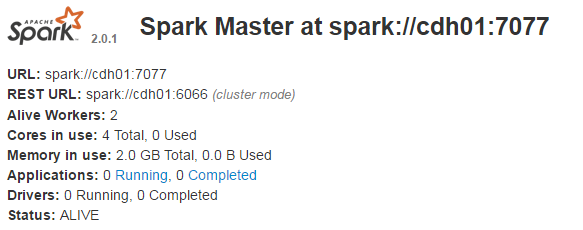
8. Web界面
http://cdh01:8080/jobs/
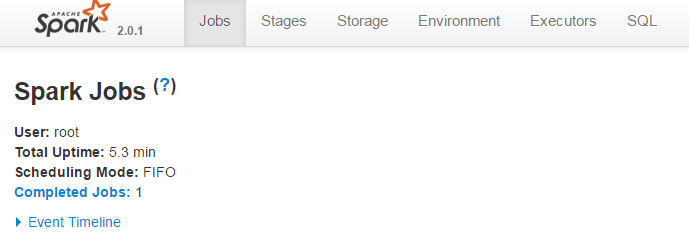
http://cdh01:4040/jobs/
?

應用在模板制作)
——構造函數和析構函數)



——友元)


—— 運算符重載)




—— 菱形繼承)


—— 多態)
![[轉]c++類的構造函數詳解](http://pic.xiahunao.cn/[轉]c++類的構造函數詳解)
