InnoDB引擎:
提供了對數據庫ACID事務的支持,并且實現了SQL標準的四種隔離級別
提供了行級鎖和外鍵約束。
它的設計的目標是處理大容量數據庫系統,用于緩沖數據和索引。
不支持FULLTEXT類型的數據,沒有保存表的行數,當select count(*) from table ?時需要掃描全表。
使用數據庫事務時,該引擎是首選。
由于鎖的粒度更小,寫操作不會鎖定全表,所以在并發較高時,使用InnoDB效率會提升。
行級鎖也不是絕對的, 如果只在執行一個SQL語句時不能確定要掃描的范圍,InnoDB同樣會鎖定全表。
?
MyIASM引擎:
沒有提供對數據庫事務的支持,也不支持行級鎖和外鍵
因此在insert 或update時需要鎖定全表,效率會降低。
存儲了表的行數,當select count(*) from table 時只需要直接讀取已經保存好的值而不用掃描全表。
如果讀操作遠遠多于寫操作且不需要數據庫事務的支持,那么MyIASM也是很好的選擇。
兩種引擎的比較:
大尺寸的數據集趨向于選擇InnoDB引擎,因為它支持事務處理和故障恢復。數據庫大小決定了故障恢復的時間長短。InnoDB引擎可以利用事務日志進行數據恢復。
主鍵查詢在InnoDB引擎下會相當快
大批量的insert語句(在每個insert語句中寫入多行,批量插入)在MyISAM下會快一點。
Update語句在InnoDB下會更快一點。
?
?
?數據結構:
B-Tree:
?
每個節點最多可以有d個分支,d成為B-Tree的度
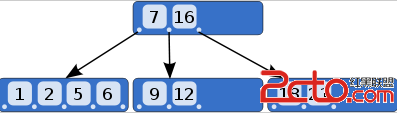
B-Tree中的元素都是有序的,比如圖中元素7左邊的指針指向的節點中的元素都小于7,而元素7和16之間的指針指向的結點中的元素都處于7和16之間。正是滿足這樣的關系,才能實現高效的查找:首先從根節點進行二分查找,找到就返回對應的值,否則就進入相應的區間結點遞歸查找,直到找到對應的元素或找到null指針,找到null指針則表示查找失敗。時間復雜度為O(logN).
?
?
?
?
?
?
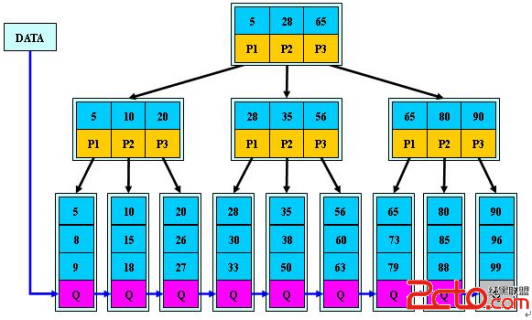
B+Tree:
?
?
?
?
?
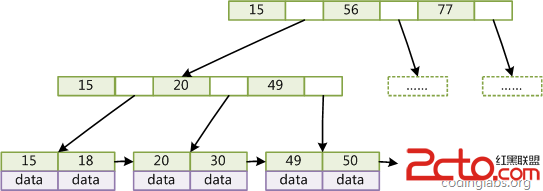
B+tree內部節點不存儲數據,只存儲指針,而葉子節點則只存儲數據,不存儲指針。
MyISAM的 B+Tree的葉子節點上的data,并不是數據本身,而是數據存放的地址。
?
InnoDB引擎的索引結構同樣是B+Tree,但InnoDB的索引文件本身就是數據文件,即B+Tree的數據區域存儲的就是實際的數據,這種索引就是聚簇索引。
聚簇索引的數據的物理結構存放順序與索引順序是一致的,即:只要索引的事相鄰的,那么對應的數據一定也是相鄰地存放在磁盤上。
—— 多態)
![[轉]c++類的構造函數詳解](http://pic.xiahunao.cn/[轉]c++類的構造函數詳解)



![datatable綁定comboBox顯示數據[C#]](http://pic.xiahunao.cn/datatable綁定comboBox顯示數據[C#])
——堆區內存開辟數組和二級指針)



—— Lambda表達式的應用)




—— 容器和容器適配器)
)


