內核ida和idr機制分析(盤符分配機制)
ida和idr的機制在我個人看來,是內核管理整數資源的一種方法。在內核中,許多地方都用到了該結構(例如class的id,disk的id),更直觀的說,硬盤的sda到sdz的自動排序也是依靠該機制。使用該結構的好處是可以管理大量的整數資源并且檢索的時候非常高效。但是,使用該機制的另一個弊端就是:同一個槽位的硬盤進行拔插的時候,如果之前申請的整數資源沒有來得及釋放,那么可能會產生盤符漂移現象。這給上層軟件對盤符的管理帶來了困難。在本篇博文中,對具體如何解決盤符漂移不做說明。
在根據代碼說明之前,我想先介紹一下該機制對整型數的靈活應用。int數值一般來說,為4個字節。那么將一個int數分為4部分的結果就是每部分8bit。在idr的機制中,采用樹來管理資源,int數值的一個字節,被抽象成了樹中的一層。即:對某個int值從又向左數,分別是第一層、第二層、第三層、第四層。第一層必須要有,第一層一般是樹葉層。該idr樹的生長方式也是從樹葉開始,隨著不斷的生長,最開始,樹根就是樹葉,到最后,樹根處于第四層,樹葉還是第一層。特別注意說明的是,idr還有一個第0層的概念。在第0層上,可以比喻成樹葉上水珠。
之前的文字描述可能比較抽象,而且也可能不太準確。下面用一個圖來表示這種關系。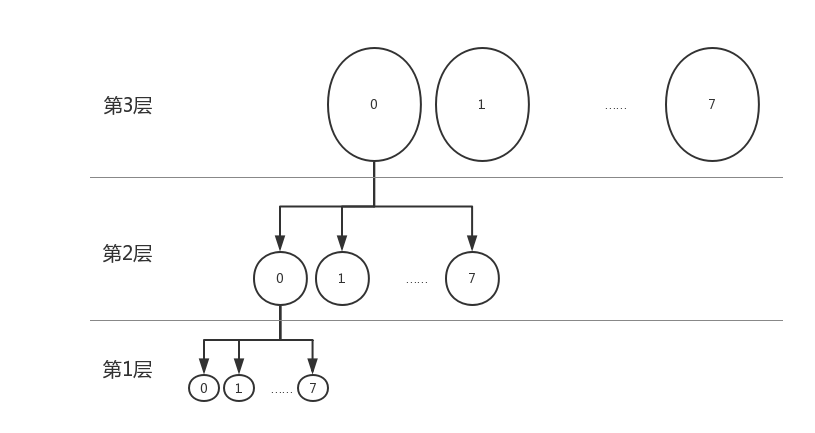
假設我們現在有個a=0x0001,那么a在圖中對應第一層中的1。如果有個b=0x0011,那么就必須從第二層的1上生長出一個和第一層一樣的結構,再在這上面找到1.如圖所示: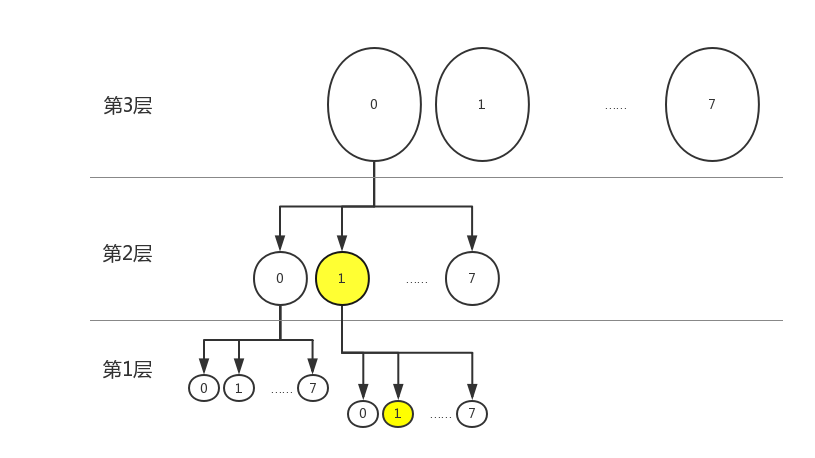
當然,如果該樹管理的最大資源,還沒有涉及到第三層,即最大的數第三個字節都是0,那么其實是沒有必要維護第三層的。
此外,該圖只是形象的說明了idr的思想,但與實際的代碼并不完全一樣,具體細節還需要接下來慢慢結合代碼分析。在分析代碼之前,再介紹一下常用運算符抑或。請觀察下面的運算式:((m >> 8) & (0xF) ^ (m >> 8) ^ (0x5)) << 8 該運算的作用是將m的第二個字節置為5,第三個第四個字節不變,第一個字節清零。
下面開始結合代碼分析,先分別給出ida和idr的結構說明:
168 struct ida {
169 struct idr idr;
170 struct ida_bitmap *free_bitmap;
171 };163 struct ida_bitmap {
164 long nr_busy;
165 unsigned long bitmap[IDA_BITMAP_LONGS];
166 };idr代表著上面介紹的那一棵樹,因此可見,ida只是對這棵樹的封裝,在idr樹的基礎上,統一了管理辦法。
42 struct idr { 43 struct idr_layer __rcu *hint; /* the last layer allocated from */44 struct idr_layer __rcu *top;45 int layers; /* only valid w/o concurrent changes */46 int cur; /* current pos for cyclic allocation */47 spinlock_t lock;48 int id_free_cnt;49 struct idr_layer *id_free;50 };30 struct idr_layer {31 int prefix; /* the ID prefix of this idr_layer */32 int layer; /* distance from leaf */33 struct idr_layer __rcu *ary[1<<IDR_BITS];34 int count; /* When zero, we can release it */35 union {36 /* A zero bit means "space here" */37 DECLARE_BITMAP(bitmap, IDR_SIZE);38 struct rcu_head rcu_head;39 };40 };idr代表圖中的那棵樹,idr_layer代表著圖上的每個圓球,而其中的ary數組代表著每個圓球下的箭頭,bitmap位圖用來記錄該位置下的子layer是否還有空位,如果沒有將置1.
獲取idr資源主要由兩個api來管理。ida_pre_get和ida_get_new_above。前者負責按照該樹可承載的最多layer數量申請layer資源,并存放到資源池中。后者可以指定從某個id開始,尋找下一個未被使用的id。
896 int ida_pre_get(struct ida *ida, gfp_t gfp_mask) 897 {898 /* allocate idr_layers */899 if (!__idr_pre_get(&ida->idr, gfp_mask))900 return 0;901 902 /* allocate free_bitmap */903 if (!ida->free_bitmap) {904 struct ida_bitmap *bitmap;905 906 bitmap = kmalloc(sizeof(struct ida_bitmap), gfp_mask);907 if (!bitmap)908 return 0;909 910 free_bitmap(ida, bitmap);911 }912 913 return 1;914 }192 static int __idr_pre_get(struct idr *idp, gfp_t gfp_mask) 193 {194 while (idp->id_free_cnt < MAX_IDR_FREE) {195 struct idr_layer *new;196 new = kmem_cache_zalloc(idr_layer_cache, gfp_mask);197 if (new == NULL)198 return (0);199 move_to_free_list(idp, new);200 }201 return 1;202 }160 static void move_to_free_list(struct idr *idp, struct idr_layer *p) 161 {162 unsigned long flags;163 164 /*165 * Depends on the return element being zeroed.166 */167 spin_lock_irqsave(&idp->lock, flags);168 __move_to_free_list(idp, p);169 spin_unlock_irqrestore(&idp->lock, flags);170 }153 static void __move_to_free_list(struct idr *idp, struct idr_layer *p) 154 {155 p->ary[0] = idp->id_free;156 idp->id_free = p;157 idp->id_free_cnt++;158 }868 static void free_bitmap(struct ida *ida, struct ida_bitmap *bitmap) 869 { 870 unsigned long flags;871 872 if (!ida->free_bitmap) {873 spin_lock_irqsave(&ida->idr.lock, flags);874 if (!ida->free_bitmap) {875 ida->free_bitmap = bitmap;876 bitmap = NULL;877 } 878 spin_unlock_irqrestore(&ida->idr.lock, flags);879 }880 881 kfree(bitmap);882 }899行調用__idr_pre_get分配layer。在該函數內,分配MAX_IDR_FREE個layer,之后使用move_to_free_list函數進行保存。153行可以看出,所有的未使用layer都通過idr里的id_free連接起來,layer之間通過ary[0]連接。這樣,創建的資源,在之后需要使用的時候,直接取就可以了,可以節省運行時間,提高性能。
ida內還有個free_bitmap域,由于該域的操作涉及到競爭,因此,放到自旋鎖中處理。881行的free是因為,防止某個線程申請好了資源,但是有一個線程比他還快,已經進入了874行。那么等之后他獲取到鎖后,直接不需要進入if分支,釋放之前申請的資源即可。
932 int ida_get_new_above(struct ida *ida, int starting_id, int *p_id)933 {934 struct idr_layer *pa[MAX_IDR_LEVEL + 1];935 struct ida_bitmap *bitmap;936 unsigned long flags;937 int idr_id = starting_id / IDA_BITMAP_BITS;938 int offset = starting_id % IDA_BITMAP_BITS;939 int t, id;940 941 restart:942 /* get vacant slot */943 t = idr_get_empty_slot(&ida->idr, idr_id, pa, 0, &ida->idr);944 if (t < 0)945 return t == -ENOMEM ? -EAGAIN : t;946 947 if (t * IDA_BITMAP_BITS >= MAX_IDR_BIT)948 return -ENOSPC;949 950 if (t != idr_id)951 offset = 0;952 idr_id = t;953 954 /* if bitmap isn't there, create a new one */955 bitmap = (void *)pa[0]->ary[idr_id & IDR_MASK];956 if (!bitmap) {957 spin_lock_irqsave(&ida->idr.lock, flags);958 bitmap = ida->free_bitmap;959 ida->free_bitmap = NULL;960 spin_unlock_irqrestore(&ida->idr.lock, flags);961 962 if (!bitmap)963 return -EAGAIN;964 965 memset(bitmap, 0, sizeof(struct ida_bitmap));966 rcu_assign_pointer(pa[0]->ary[idr_id & IDR_MASK],967 (void *)bitmap);968 pa[0]->count++;969 }970 971 /* lookup for empty slot */972 t = find_next_zero_bit(bitmap->bitmap, IDA_BITMAP_BITS, offset);973 if (t == IDA_BITMAP_BITS) { 974 /* no empty slot after offset, continue to the next chunk */975 idr_id++;976 offset = 0;977 goto restart;978 }979 980 id = idr_id * IDA_BITMAP_BITS + t;981 if (id >= MAX_IDR_BIT)982 return -ENOSPC;983 984 __set_bit(t, bitmap->bitmap);985 if (++bitmap->nr_busy == IDA_BITMAP_BITS)986 idr_mark_full(pa, idr_id);987 988 *p_id = id;989 990 /* Each leaf node can handle nearly a thousand slots and the991 * whole idea of ida is to have small memory foot print.992 * Throw away extra resources one by one after each successful993 * allocation.994 */995 if (ida->idr.id_free_cnt || ida->free_bitmap) {996 struct idr_layer *p = get_from_free_list(&ida->idr);997 if (p)998 kmem_cache_free(idr_layer_cache, p);999 }
1000
1001 return 0;
1002 }289 static int idr_get_empty_slot(struct idr *idp, int starting_id, 290 struct idr_layer **pa, gfp_t gfp_mask,291 struct idr *layer_idr)292 {293 struct idr_layer *p, *new;294 int layers, v, id;295 unsigned long flags;296 297 id = starting_id;298 build_up:299 p = idp->top;300 layers = idp->layers;301 if (unlikely(!p)) {302 if (!(p = idr_layer_alloc(gfp_mask, layer_idr)))303 return -ENOMEM;304 p->layer = 0;305 layers = 1;306 }307 /*308 * Add a new layer to the top of the tree if the requested309 * id is larger than the currently allocated space.310 */311 while (id > idr_max(layers)) {312 layers++; 313 if (!p->count) {314 /* special case: if the tree is currently empty,315 * then we grow the tree by moving the top node316 * upwards.317 */318 p->layer++;319 WARN_ON_ONCE(p->prefix);320 continue;321 }322 if (!(new = idr_layer_alloc(gfp_mask, layer_idr))) {323 /*324 * The allocation failed. If we built part of325 * the structure tear it down.326 */327 spin_lock_irqsave(&idp->lock, flags);328 for (new = p; p && p != idp->top; new = p) {329 p = p->ary[0];330 new->ary[0] = NULL;331 new->count = 0;332 bitmap_clear(new->bitmap, 0, IDR_SIZE);333 __move_to_free_list(idp, new);334 }335 spin_unlock_irqrestore(&idp->lock, flags);336 return -ENOMEM;337 }338 new->ary[0] = p;339 new->count = 1;340 new->layer = layers-1;341 new->prefix = id & idr_layer_prefix_mask(new->layer);342 if (bitmap_full(p->bitmap, IDR_SIZE))343 __set_bit(0, new->bitmap);344 p = new;345 }346 rcu_assign_pointer(idp->top, p);347 idp->layers = layers;348 v = sub_alloc(idp, &id, pa, gfp_mask, layer_idr); 349 if (v == -EAGAIN)350 goto build_up;351 return(v);352 }220 static int sub_alloc(struct idr *idp, int *starting_id, struct idr_layer **pa,221 gfp_t gfp_mask, struct idr *layer_idr)222 {223 int n, m, sh;224 struct idr_layer *p, *new;225 int l, id, oid;226 227 id = *starting_id;228 restart:229 p = idp->top;230 l = idp->layers;231 pa[l--] = NULL;232 while (1) {233 /*234 * We run around this while until we reach the leaf node...235 */236 n = (id >> (IDR_BITS*l)) & IDR_MASK;237 m = find_next_zero_bit(p->bitmap, IDR_SIZE, n);238 if (m == IDR_SIZE) {239 /* no space available go back to previous layer. */240 l++;241 oid = id;242 id = (id | ((1 << (IDR_BITS * l)) - 1)) + 1;243 244 /* if already at the top layer, we need to grow */245 if (id > idr_max(idp->layers)) {246 *starting_id = id;247 return -EAGAIN;248 }249 p = pa[l];250 BUG_ON(!p);251 252 /* If we need to go up one layer, continue the253 * loop; otherwise, restart from the top.254 */255 sh = IDR_BITS * (l + 1);256 if (oid >> sh == id >> sh)257 continue;258 else259 goto restart;260 } 261 if (m != n) {262 sh = IDR_BITS*l;263 id = ((id >> sh) ^ n ^ m) << sh;264 }265 if ((id >= MAX_IDR_BIT) || (id < 0))266 return -ENOSPC;267 if (l == 0)268 break;269 /*270 * Create the layer below if it is missing.271 */272 if (!p->ary[m]) {273 new = idr_layer_alloc(gfp_mask, layer_idr);274 if (!new)275 return -ENOMEM;276 new->layer = l-1;277 new->prefix = id & idr_layer_prefix_mask(new->layer);278 rcu_assign_pointer(p->ary[m], new);279 p->count++;280 }281 pa[l--] = p;282 p = p->ary[m];283 }284 285 pa[l] = p;286 return id;287 }由于代碼較長。為了方便敘述,假設當前idr樹中沒有被使用的id。現在調用ida_get_new_above從0開始找下一個可用的id。由于我們給出了假設,因此可以預期到得到的結果是0.我們帶著這樣的假設去分析代碼。
943行進入idr_get_empty_slot。301行由于是第一次申請id,因此將進入該分支,分配一個top,即根節點。此時,304行看出根節點層數為第0層。305行layers表示總層數,為1層。由于是從0開始分配,因此311行循環不進入,直接跳過。346行通過rcu方式配置了top域。348行開始真正分配。
該函數工作開始,保存了幾個量,如227~230所示。考慮到我們從0開始,則id=0,p為剛剛分配的根節點,l=1。232行的循環是為了使l>1時,能不斷遍歷到第0層。237行得到m=0.if分支顯然不會進入,跳過。由于231行l--,所以267行的時候,跳出循環。285行保存了根節點,之后返回0.
回到943行,t取到0.pa[0]內保存的一定是葉子節點的地址。我們這里因為只有1層,根節點就是葉子節點。955行顯然取到一個NULL,那么將ida中的free_bitmap轉交給它,并在966行轉交給根節點的ary[0]。972行檢測當前層數是否還有剩余空位,這里需要說明的是,一般情況下,一個節點(layer)管理8*128個id,這種管理就是直接通過數組進行管理的。這個數組就是ida申請的數組,在該函數內通過強轉保存到了ary[0]內。那么此時,肯定返回0. 980行id=0.984行配置相應位為1. 985~986行判斷該節點是否已滿,如果之后沒有空閑了,將設置為該位置已滿。這是通過根節點下的bitmap去設置的。988行將id值賦給p_id,之后返回。
在這里,將對之前的假設做出一個糾正。我們開始假設是從0開始尋找,是假設ida_get_new_above里的參數staring_id是從哪個數開始查找的意思。實際上,通過走讀分析,我們可以看到,該starting_id其實代表某個layer。
通過這樣的分析,相信對于整個流程已經有了簡單的認知。代碼其他部分主要涉及到stating_id指定的layer不存在,分配新的layer。或者starting_id超過了當前層數所能提供的最大id,則idr必須開始生長的過程。對于這些部分,相信經過前面的分析,這些都已經變的很簡單,本文不再詳細說明。留給讀者自行分析。





:Path結合屬性動畫, 讓圖標動起來!)





![[LeetCode_5] Longest Palindromic Substring](http://pic.xiahunao.cn/[LeetCode_5] Longest Palindromic Substring)


)


)
)
![數據倉庫事實表分類[轉]](http://pic.xiahunao.cn/數據倉庫事實表分類[轉])