作者:十歲的小男孩? ?
凡心所向,素履可往
目錄
監督學習—混淆矩陣
是什么?有什么用?怎么用?
非監督學習—匹配矩陣
混淆矩陣

矩陣每一列代表預測值,每一行代表的是實際的類別。這個名字來源于它可以非常容易的表明多個類別是否有混淆(也就是一個class被預測成另一個class)。
假設有一個用來對貓(cats)、狗(dogs)、兔子(rabbits)進行分類的系統,混淆矩陣就是為了進一步分析性能而對該算法測試結果做出的總結。假設總共有?27?只動物:8只貓,?6條狗,?13只兔子。結果的混淆矩陣如上圖:
在這個混淆矩陣中,實際有8只貓,但是系統將其中3只預測成了狗;對于6條狗,其中有1條被預測成了兔子,2條被預測成了貓。從混淆矩陣中我們可以看出系統對于區分貓和狗存在一些問題,但是區分兔子和其他動物的效果還是不錯的。所有正確的預測結果都在對角線上,所以從混淆矩陣中可以很方便直觀的看出哪里有錯誤,因為他們呈現在對角線外面。
tf.confusion_matrix
定義:
tf.confusion_matrix(labels,predictions,num_classes=None,dtype=tf.int32,name=None,weights=None )
ARGS:
labels:Tensor分類任務的1-D?真實標簽。predictions:Tensor給定分類的1-D?預測。num_classes:分類任務可能具有的標簽數量。如果未提供此值,則將使用預測和標簽數組計算該值。dtype:混淆矩陣的數據類型。name:范圍名稱。weights:可選Tensor的形狀匹配predictions。
返回:
甲Tensor類型的dtype具有形狀[n, n]表示所述混淆矩陣,其中n是在分類任務可能的標簽的數量。
例子:
tf.confusion_matrix([1, 2, 4], [2, 2, 4]) ==>[[0 0 0 0 0][0 0 1 0 0][0 0 1 0 0][0 0 0 0 0][0 0 0 0 1]]
請注意,假設可能的標簽是[0, 1, 2, 3, 4],導致5x5混淆矩陣。
我的圖片分類項目中遇到的實例:
1.定義兩個矩陣,用于放真實的標簽和預測的標簽,大小根據測試的次數計算,全為0.[1,test_num]
Y_true=np.zeros(len(test_num))#真實的標簽
Y_predict=np.zeros(len(test_num))#預測的標簽 2.將每步訓練的標簽放在矩陣中,我的項目中預測的的為標簽,類似[0,0,0,1,0,0,0],取出最大的,即為4,本步在循環中,記錄每步訓練。
Y_true[step_test]=np.argmax(testing_ys)
Y_predict[step_test]=np.argmax(predict) 3.調用TensorFlow的混淆矩陣函數,這一步需要將矩陣轉換為tensor,在TensorFlow中運行的單元為tensor
confuse_martix=sess.run(tf.convert_to_tensor(tf.confusion_matrix(Y_true,Y_predict))) print(confuse_martix)
4.結果
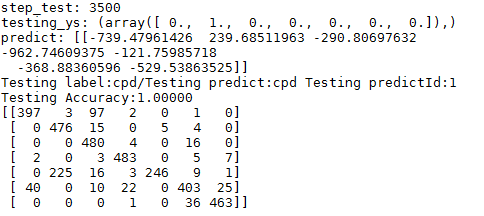
匹配矩陣
在預測分析中,混淆表格(有時候也稱為混淆矩陣),是由false positives,falsenegatives,true positives和true negatives組成的兩行兩列的表格。它允許我們做出更多的分析,而不僅僅是局限在正確率,對于上面的矩陣,可以表示為下面的表格

?
查準率 = 精度 = precision?
查全率 = 召回率 = recall
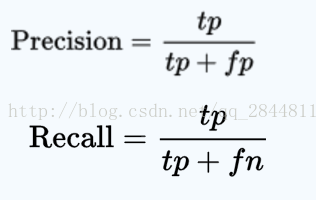
?
本文僅用于學習研究,非商業用途,歡迎大家指出錯誤一起學習
本文參考了以下地址的講解,萬分感謝,如有侵權,請聯系我會盡快刪除,929994365@qq.com:
TensorFlow API網站:https://tensorflow.google.cn/api_docs/python/tf/confusion_matrix,TensorFlow的api在這個網站都可以查到
https://blog.csdn.net/qq_28448117/article/details/78219549

說明)





)




實現萬年歷)

)
 tree shaking與不同mode)

代碼分割 Code Splitting)
)
