05.Spark--RDD詳解
RDD詳解--groupByKey--reduceByKey
[MapPartitionRDD單詞統計]
單詞統計
import org.apache.spark.{SparkConf,SparkContext}
object WordCountScala{def main(args:Array[String]):Unit={//創建spark配置對象val conf=new SparkConf()conf.setAppName("WCScala")conf.setMaster("local")//創建上下文val sc=new SparkContext(conf)//加載文檔,這個文件是文本文件,調的是hadoopFileval rdd1=sc.textFile("file:///d:/mr/word.txt")[textFile,hadoopFile]//K是longtegr hadoop里面的 pair hadoopFile(path,classOf[TextInputFormat],classOf[LognWritable],classOf[Test],minPartitions).map(pair=>pair._2.toString).setName(path)//map做的版面//壓扁val rdd2=rdd1.flatMap(_.split(" "))//標1成對val rdd3=rdd2.map(_,1)//聚合val rdd4=rdd3.reduceByKey(_+_)val arr=rdd4.collect()arr.foreach(println)//鏈式編程//sc.textFile("file:///d:/mr/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)}
}
RDD的依賴列表是如何呈現的?
//[T:ClassTag]主構造
abstract class RDD[T:ClassTag]{@transient private var _sc:SparContext,//體現出了依賴集合,RDD需要的依賴列表 什么時候創建的?@transient private var deps:Seq[Dependency[_]] //[Dependency[_]]泛型
}extends Serialiizable with Logging{...
}
//映射分區RDD
MapPartitionsRDD(org.apache.spark.rdd)
private[spark] class MapPartitionsRDD[U:ClassTag,T:ClassTag](var prev:RDD[T],f:(TaskCOntext,Int,Iterator[T])=>Iterator[U].preserversPartitioning:Boolean=false)//prev是上級的RDD
extends RDD[U](prev){//構造一個rdd用one-to-one依賴...此時RDD會調用 def this(@transoentoneParent:RDD[_])=this(oneParent.context,List(new OneToOneDependency(oneParent)))//一對一的依賴,OneToOneDependency總結:當它去調MapPartitionsRDD的時候,它繼承了父的RDD,而父RDD它只傳了一個上級RDD的prev這個屬性,因為它走的是(def this(@transoent oneParent:RDD[_]))輔助構造。輔助構造它把這個RDD的上下文(oneParent)取出,放入這里面.這里面創建了一個List(new OneToOneDependency(oneParent),創建了OneToOneDependency依賴。oneParent上級的RDD。
}
)class OneToOneDependency[T](rdd:RDD[T])extends NarrowDependency[T](rdd){override def getParents(partitionId:Int):List[Int]=List(partitionId)//其實它是一個鏈條,RDD本身是依賴列表。每一個依賴于上級關聯。所以不是MapPartitionRDD于preRDD之間直接關聯。是通過依賴走了一圈。}
如何判斷是寬依賴還是窄依賴的? MapPartitionsRDD就是窄依賴,在reduceByKey的時候就已經ShuffledRDD了。ShuffledRDD與依賴有啥關系?
那是因為在創建RDD的時候,就已經把依賴關聯進了去了。因為huffer依賴不是它劃分邊界的關鍵。它通過依賴,因為寬依賴就是Shuffer,窄依賴就不是Shuffer了。當它在創建RDD進來的時候,這個依賴就在這里面了。所以它是固定的。RDD它里面有一個分區列表,分區列表它是一個集合。可以理解為一個引用。集合里面放了一堆的依賴。其中RDD是一個抽象類,有一個是MapPartitionRDD,它是RDD的一個子類。它具備了RDD的特點。也得有RDD的分區列表。它創建了一對一的依賴。RDD中所傳的prev是上一家RDD,也是在構造里面。上一個RDD存放哪?為了構造MapPartitionRDD它是通過其它的RDD變換。MapPartitionRDD是如何與preRDD關聯起來的。是因為MapPartitionRDD它有依賴,而在這個依賴當中它有一個RDD的屬性(deps)關聯到preRDD的。從Hadoop到flatMap再到表一成對它們全都是窄依賴。到了reduceByKey它返回的是ShuffledRDD它用到的就是Shuffler依賴了。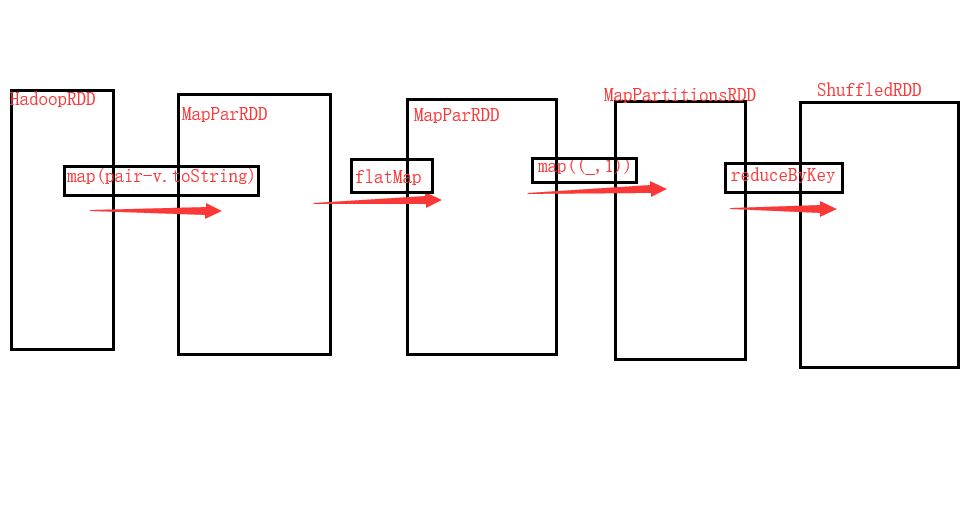

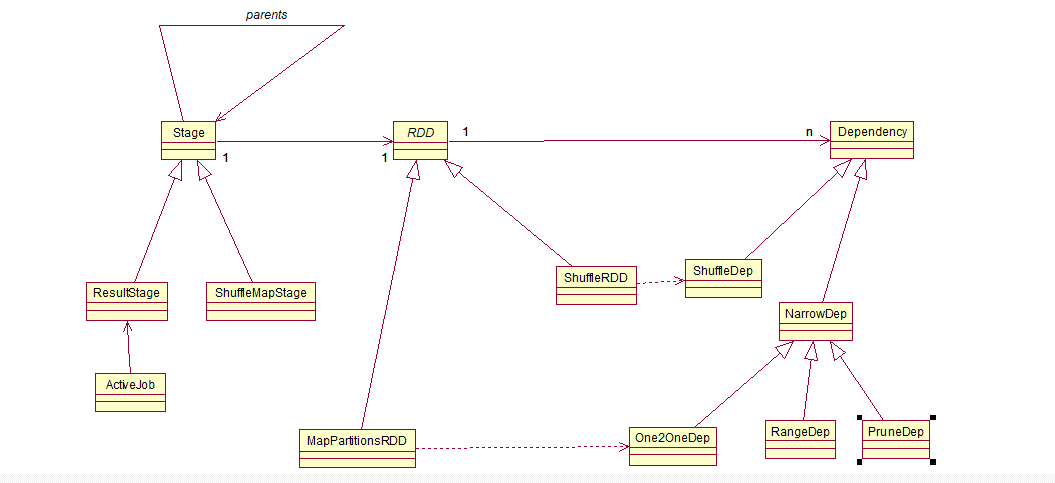
ShufflerdRDD:這個結果RDD,它是要通過Shuffle來產生的。參數是由上一個RDD還有分區類,K類.V類還有組合函數,ShuffledRDD也是繼承了RDD的。RDD是抽象的,它有兩個子類MapPartitionsRDD和ShuffleRDD.MapPartition和ShuffleRDD都繼承于RDD。RDD它有分區列表,作為Dependecy(依賴)。一個RDD它可以由多個Dependecy(依賴)。這種關系叫做多重性關系。Dependecy(依賴)分為兩種依賴,寬依賴(ShuffleDep)和窄依賴(NarrowDep)。寬依賴(NarrowDep)分為三種依賴,One2OneDep,RangeDep,PruneDep它們都繼承窄依賴(NarrowDep)。每一個RDD都和上一個RDD是有關系的。它是直接關聯上去 的嗎?不它不是,它是通過依賴Dependency(依賴關聯上去的)。所以1個RDD里面它會有多個依賴。那么每個依賴它有多少個RDD? asttract class Dependency[T]extebds Serializable{def rdd:RDD[T]}只有一個RDD。Dependecy(依賴)與RDD的關系是一對一的關系。對于每一RDD它是走依賴再找上一個RDD。ShuffleRDD是與ShuffleDep有關系的。ShuffledRDD它是重寫get依賴的方法。getDependencies,它的依賴它的方法里面List(new ShuffleDependency(prev,part,seralizer,keyOrdering,aggregator,mapSideCombine),它返回的是ShuffleDependency依賴。prev還給了上級。part分區。seralizer串行化類,keyOrdering排序以及aggregator聚合器以及mapSideCombine合成函數。ShuffleRDD是依賴于ShuffleDep。MapPartitionsRDD是依賴于One2OneDep。什么時候創建依賴?是在創建RDD的時候,就已經產生了依賴。Spark給了那么多的RDD。它們都有對應的。RDD的依賴是在RDD的構造函數中出現的。看看filter(過濾)它用的也是MapPartitionsRDD.
groupByKey和reduceByKey之間的區別?假如它們都能實現相同功能下優先使用?優先reduceByKey 為什么? 有一個合成過程,hadoop的合成鏈條是怎樣的?map分為三個階段,第一setup():做一些初始化的配置的。 第二 while() 找每一行,每一行都會經過while()循環。在調用map()函數的時候,第三cleanup()收尾工作的。Spark的分區和hadoop的分區一樣嗎?不一樣,hadoop的分區是指在map端的分區過程,map之后有一個分區。分區分多少個區,就是Reduce的個數。hadoop的分區只能是Reduce的個數。是Map過程中對key進行分發的目的地。hadoop的MR是map階段進行完后,它要經過hash。經過分發,分發到集合空間里面去。幾個空間就是幾個分區。這里的分區數和reduce的個數對應。reduce的個數是和程序來設置的。跟我們的切片沒有關系。Spark的是分區,Spark的分區就是切片,map的個數。當加載文件的時候,這個文件被切成了多少片,每一片要一般要對應一個任務。所以Spark的分區就是切片的個數。而且每一個RDD都有自己的分區數。這是它們的不同。Spark的分區就是切片。分成多少片,當你變換之后。也是產生新的RDD,它又有分區。groupByKey在hadoop中,map產生的K,V是要經過分發。要進入到分區,當分區完的下一步就Combiner(合成)。合成必須有嗎?不一定 合成的目的就是減少網絡負載。單詞統計中,hello統計了100萬,如果不做Combiner它就要分發做100萬遍了。但是如果它做了Combiner它只要做reduce個數了。因為每個分區里面都把數據先聚合起來了。假如有3個分區每個分區都有100萬數據它是標1的,如果它不做Combiner。它就要把300萬逗號1發走。所以這網絡負載是很大的。那就沒有必要了。Combiner是map端的聚合。Combiner是map端的Reduce,Combiner也叫做預聚合。這樣一來,每個map端就編程了“hell 1百萬“(數據格式)了,這樣就只要發送這一條數據就行了。因為它已經聚合好了。groupByKey合reduceByKey : groupByKey是沒有Combine過程的,reduceByKey是有Combiner過程。結果一定會變少,變少之后,再經過網絡分發。那就是網絡帶寬就占少了,就不用分發那么多了。它有一種數據的壓緊的工作。假如你用的分組是組成一個新的集合List[],這也是一個聚合過程。對于這樣的結果來講groupByKey和reduceByKey的結果相同嗎?也不相同 為什么?因為groupbyKey的話它就分到一個組上了。groupByKeyList它沒有Combiner所以它在Reduce
在很多map中,可以在map內聚合,可以在map內聚合。在map端聚合完后.不管是groupByKey還是reduceByKey都是調用combineByKeyWithClassTag(按類標記符來合成Key,按k合成)方法。mapSideCombine默認值是true.reduceByKey沒有傳遞這個參數,它就是默認值。groupByKey傳遞的值是false,所以它不進行map端聚合。groupByKey它可以改變V的類型。reduceByKey沒有機會。reduceByKey是兩V聚成一V,類型是相同的。如果想用reduceByKey來實現。 變換是沒有機會指定的,但是Shuffer是有機會指定的。MapPartitionsRDD當你在分組的時候getPartitions。numPartitions:Int這個是分區數。在這里是可以指定分區數的。而且來可以帶一個HashPartitioner(分區函數)默認的是Hash分區打散。















![koa --- [MVC實現之一]自定義路由讀取規則](http://pic.xiahunao.cn/koa --- [MVC實現之一]自定義路由讀取規則)


![koa --- [MVC實現之二]Controller層的實現](http://pic.xiahunao.cn/koa --- [MVC實現之二]Controller層的實現)
