本文介紹了北京大學人工智能研究院梁一韜助理教授所帶領的 CraftJarvis 團隊在「我的世界」環境下探索通用智能體設計的新進展,題為“GROOT: Learning to Follow Instructions by Watching Gameplay Videos”。
 ?
? 該研究的核心目標是探索能否擺脫文本數據的標注以及與環境的在線交互,而是僅通過觀看游戲視頻的方式來教會智能體理解世界、遵循指令,進而在開放世界下解決無窮的任務。考慮到視頻數據廣泛分布于互聯網,而高質量的“文本-視頻”數據對則難以獲得,因此團隊創新地提出使用一段“參考視頻”作為指令的描述形式,并設計一套簡潔的架構和自監督訓練方法來聯合學習指令空間和指令跟隨策略。通過在本文提出的 Minecraft SkillForge 基準上進行細致的評測,該方法超過了目前現有的基線方法,并拉近了與人類玩家之間的差距。這對于復雜環境下通用智能體的設計有重要意義。
本文的第一作者是由梁一韜助理教授指導的博士生蔡少斐,通訊作者為梁一韜。論文的作者還包括北京大學的張博為、王子豪,UCLA 的劉安吉以及北京通用人工智能研究院的馬曉健研究員。
 ?
?
?
論文題目: GROOT: Learning to Follow Instructions by Watching Gameplay Videos
論文鏈接:?https://arxiv.org/abs/2310.08235?
項目網站:GROOT: Learning to Follow Instructions by Watching Gameplay Videos
01. 研究背景
在開放世界下開發類人級別的具身智能體以解決開放式任務一直是人工智能領域長期以來追求的目標。隨著 ChatGPT 的流行,近年來涌現了一批利用大語言模型(LLM)的規劃推理能力來解決「我的世界」中復雜長期任務的嘗試,如 DEPS、Voyager、GITM 等工作。然而,與理想的通用智能體相比,這些基于 LLM 的工作主要強調發掘語言模型的潛力而忽略了提升底層控制器(low-level controller)的重要性。事實上,底層控制器負責將 LLM 規劃出來的 plan 映射到具體動作空間(鍵盤與鼠標操作),并與環境直接進行交互。因此,其掌握的技能庫中技能的數量和質量決定了智能體能力上限。該團隊的此項研究旨在構建具備指令理解能力的基礎決策大模型。通過將技能庫從有限推廣至無限,實現了由封閉式指令向開放式指令理解的邁進。
02. 研究動機
2.1 自監督預訓練范式促進大規模任務學習
自監督預訓練范式已經相繼在自然語言處理(NLP)和計算機視覺(CV)領域展現出了極強的泛化能力,大有統一深度學習的趨勢。然而,在強化學習(RL)和決策控制領域的相關研究則相對滯后。本文作者認為預訓練的學習范式對于構建決策大模型來說至關重要。考慮到任務的多樣性,為每個任務單獨定義一套獎勵函數并讓智能體在與環境交互的方式中學習是非常昂貴且不安全的。因此,利用網上的海量視頻數據對智能體進行自監督預訓練使其大規模“領悟”技能的道路則非常有前景。
2.2 “視頻”做指令表達能力強,數據易收集
為了使預訓練出來智能體能夠理解人類的指令并執行相應的任務,必須對指令空間的形式進行定義。目前主流的指令形式主要包括「任務指示器」、「未來的結果」(又分為「未來的狀態」、「預期的累計獎勵」等)、「自然語言」。本文作者認為,盡管在這些指令形式下智能體容易使用“后見經驗重放”之類的技巧學習,然而指令的表達能力卻十分有限。以「未來的狀態」舉例,一張房屋的照片并不能告訴智能體房子是如何被建造出來的,因為其缺乏細致的過程性描述。此外,這種指令也存在很強的歧義性,例如一張站在房屋前的圖片并不能讓智能體區分是要構建這樣一座房屋還是找到這樣一座房屋。盡管對于過程描述足夠細致的自然語言指令可以規避上述所說的問題,然而互聯網上并不存在如此多高質量的“視頻-文本”數據對可供訓練。
觀察到主流指令形式的局限性之后,研究團隊旨在找到指令的表達能力與智能體學習的成本之間的平衡。作者發現視頻形式的指令則可以同時兼顧這兩個要求。一方面,一段“參考”視頻可以描述完成任務所需的所有細節信息,具備極強的表達能力;另一方面,視頻模態數據大規模分布在互聯網上,因此訓練數據十分易于收集。
03. 研究方法
 ?
?
 ?
? 遵循上述設計原則,研究團隊采用了流行的編碼器-解碼器架構來實現整個模型,并命名為 GROOT。具體來說,研究團隊采用了非因果 Transformer 來實現視頻編碼器,用于提取視頻中蘊含的語義信息;采用了一個因果 Transformer 作為解碼器(即策略)用于遵照指令的語義信息在環境中做出相應的行為。在訓練過程中,輸入到編碼器的視頻和送到解碼器中狀態序列是完全一致的,模型在 KL 散度的約束下使用行為克隆進行自我模仿。在推理過程中,將輸入到編碼器中的視頻換成任意一段描述某個任務執行過程的參考視頻,智能體便可與環境進行交互從而完成相應的任務。
04. 評測基準
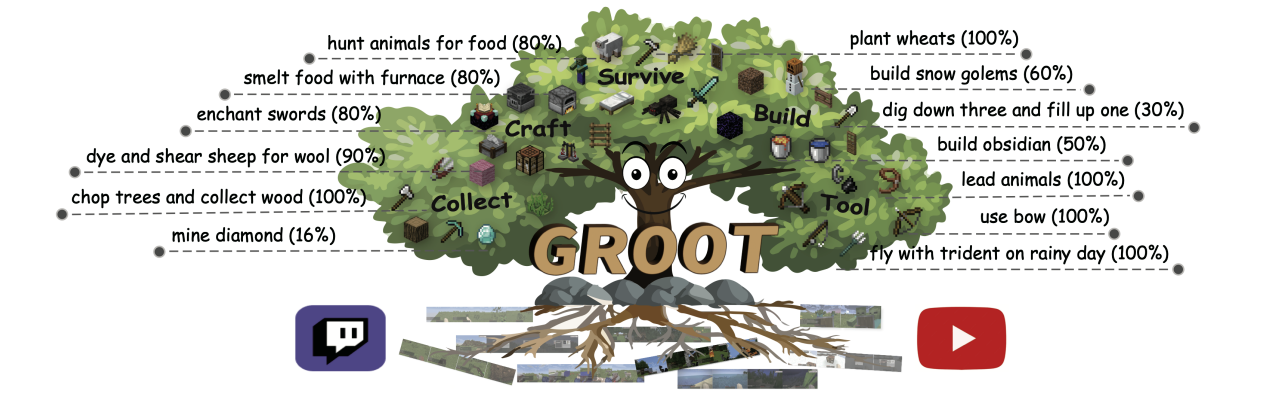
「我的世界」 環境具備極高的自由度,為了全面評估 GROOT 在解決復雜多樣化任務上的能力。研究團隊提出了一組新的評測基準「Minecraft SkillForge」。該基準包含了 「我的世界」 環境中的 30 個基礎任務,涵蓋「資源收集」、「生存維持」、「物品制作」、「自由探索」、「工具使用」和「結構建造」6 大類別。以下展示了「結構建造」、「對敵戰斗」和「資源收集」三大類任務。
 ?
?  ?
?  ?
?  ?
? ?
 ?
?  ?
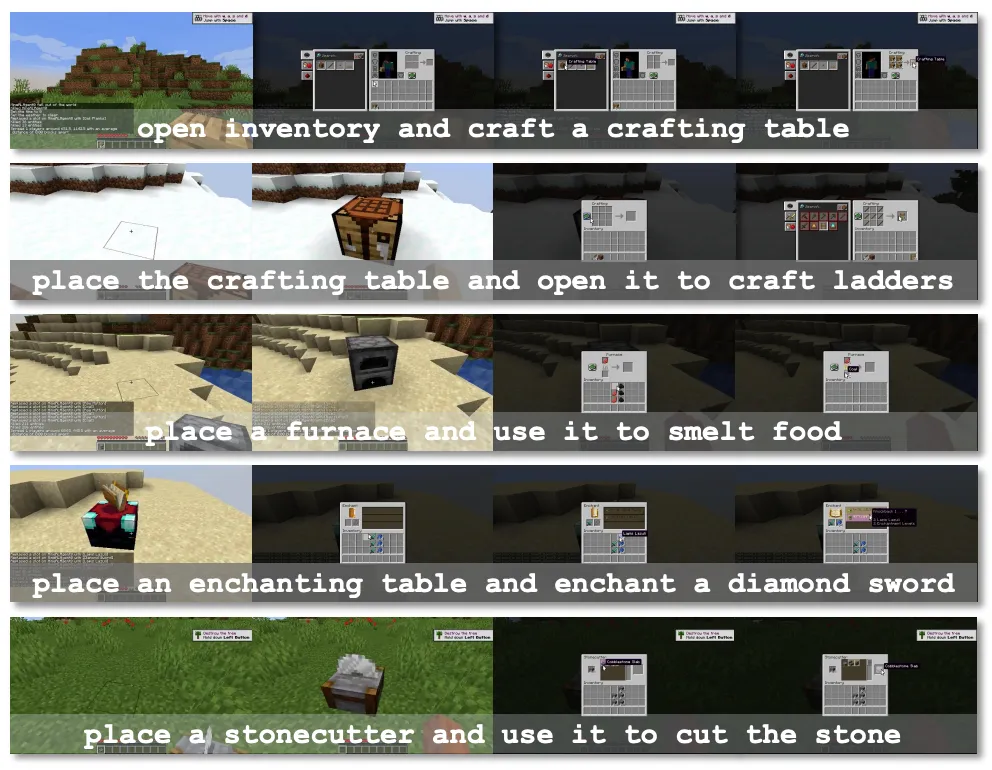
? 「挖三填一」是 「我的世界」 中安全度過黑夜的有效方法,它描述了構建一個簡易庇護所所需的步驟:垂直向下挖掘 3 個泥土,抬頭將 1 個泥土放置在上方做成封閉空間。
「蜘蛛進行搏斗」指玩家需要在保證生存的情況下使用鉆石劍擊殺盡可能多的蜘蛛。
「收集水草」任務指的是玩家需要跳進海中,潛泳游到海底破壞水草方塊。
該評測基準既包含一些常見的任務(如收集木頭、羊毛、草),也包含一些十分罕見的任務(如挖三填一、建造雪傀儡、切割石塊)。因此該基準可以充分反應模型的泛化能力,對未來 「我的世界」 下多任務智能體的研究也有較大的意義。
05. 實驗結果
5.1 天梯系統與人工評測
由于任務的多樣性,并不存在一種統一的指標來評估所有任務。因此,研究團隊使用 Elo Rating 系統結合人工比較的方式評估了 GROOT 與現有基線在「Minecraft SkillForge」基準上的性能差異。如圖所示,可以發現 GROOT (1829 分)顯著超越了目前所有的基線方法(1679 分),進一步縮小了與人類玩家(2034 分)的差異。如中間圖所示,在一些不常見的任務(如「架構建造」和「工具使用」)上,相比之前的最優方法 STEVE-1,GROOT 獲得了很高的對戰勝率(>83%)。
 ?
? 5.2 程序性任務評測結果
右圖展示了 GROOT 和基線方法在 9 種代表性任務上的成功率對比。GROOT 除了在所有任務上都取得領先優勢之外,也是唯一一個在「裝備附魔」、「挖三填一」、「建造雪傀儡」任務上取得非零成功率的智能體。
5.3 指令空間 t-SNE 可視化結果
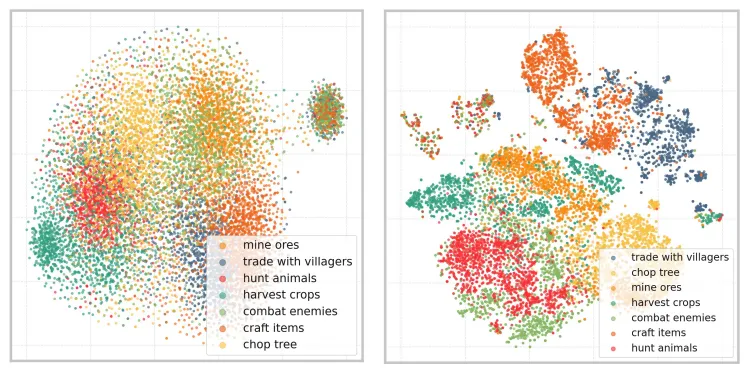 ?
? 為了直觀了解指令空間的學習情況,研究團隊額外展示了訓練前后指令空間在 7 種類別任務視頻上的編碼效果。可以發現,經過自監督訓練之后,指令空間的表達能力得到了極大的提升。在沒有任何語義標簽輔助下,僅通過自監督預訓練就可以較好地提取視頻中存在的語義信息。
5.4 組合多個指令解決復雜長期任務
 ?
? 「我的世界」 中存在很多任務需要串行執行多個指令才可以解決,其中最經典的就是「鉆石挑戰」。鉆石稀疏地分布于 「我的世界」 地下 7-12 層的位置。為了方便展現 GROOT 在解決「鉆石挑戰」上的表現,作者通過給智能體一把鐵鎬簡化了鉆石挑戰任務,即省略了制作鐵鎬的過程。現在智能體只需向下挖掘到指定層數,再水平挖掘(可能需要很久)挖到💎即可。作者初始化給智能體的指令是一段向下挖掘的視頻,并實時檢測智能體高度,當高度到達 12 時,將給智能體的指令切換為一段描述水平挖掘的視頻。研究團隊發現 GROOT 可以以 16% 的較高成功率挖到💎。而相較而言,以「未來的結果」作為指令形式的STEVE-1 則無法獲得鉆石。作者推測,這可能是由于「未來的結果」無法表達水平挖掘這一概念,因此容易掉到基巖層并卡住,從而導致任務失敗。
06. 結論與展望
本文提出了一種通過觀看游戲視頻來學習遵循指令的預訓練范式。作者認為視頻指令是一個很好的目標空間形式,它不僅表達了開放式任務,還可以通過自我監督進行訓練。基于此,研究團隊在 「我的世界」 中構建了一個名為 GROOT 的編碼器-解碼器 Transformer 架構智能體。無需依賴任何標注數據,GROOT 表現出非凡的指令跟隨能力并霸榜 Minecraft SkillForge 基準。此外,作者還展示了它在「鉆石挑戰」任務中作為下游控制器的潛力。研究團隊相信這種架構和訓練范式具有很強的應用前景,并希望將其應用于更復雜的開放世界環境。
07. 相關工作
CraftJarvis 團隊長期關注于在開放世界下構建自主智能體。除了構建指令跟隨智能體 GROOT 完成開放世界下的短期任務,團隊還使用預訓練的大語言模型作為 Planner 來增強智能體完成長期任務的能力。
7.1 DEPS
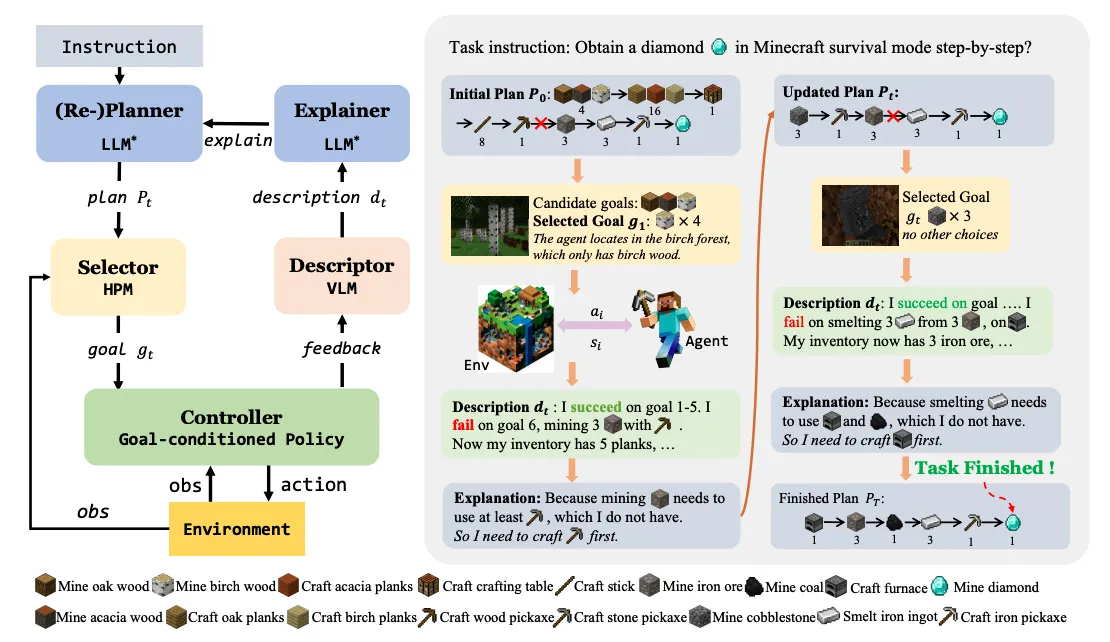
DEPS 是第一個使用大語言模型在開放世界 「我的世界」 上進行任務規劃和任務執行的智能體。DEPS 基于大語言模型設計了一個包括“描述、解釋、規劃并選擇”的流程,通過整合計劃執行過程的描述并在規劃階段遇到失敗時大語言模型提供的自我解釋反饋,從而在初步 LLM 生成的計劃失敗時更好的修正錯誤并重新規劃。此外,它還包括一個目標選擇器,這是一個可學習的模塊,根據預估完成步驟來對候選子目標進行排序,從而提高語言計劃在開放世界下的可執行性。DEPS 可以在「我的世界」環境中零樣本的實現長序列任務,例如在生存模式下從頭開始獲得鉆石。
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents?
arXiv:?https://arxiv.org/pdf/2302.01560.pdf?Code:https://github.com/CraftJarvis/MC-Planner?
該文章被收錄于NeurIPS 2023,并在ICML 2023的TEACH Workshop上被評選為最佳論文。
 ?
? 7.2 JARVIS-1
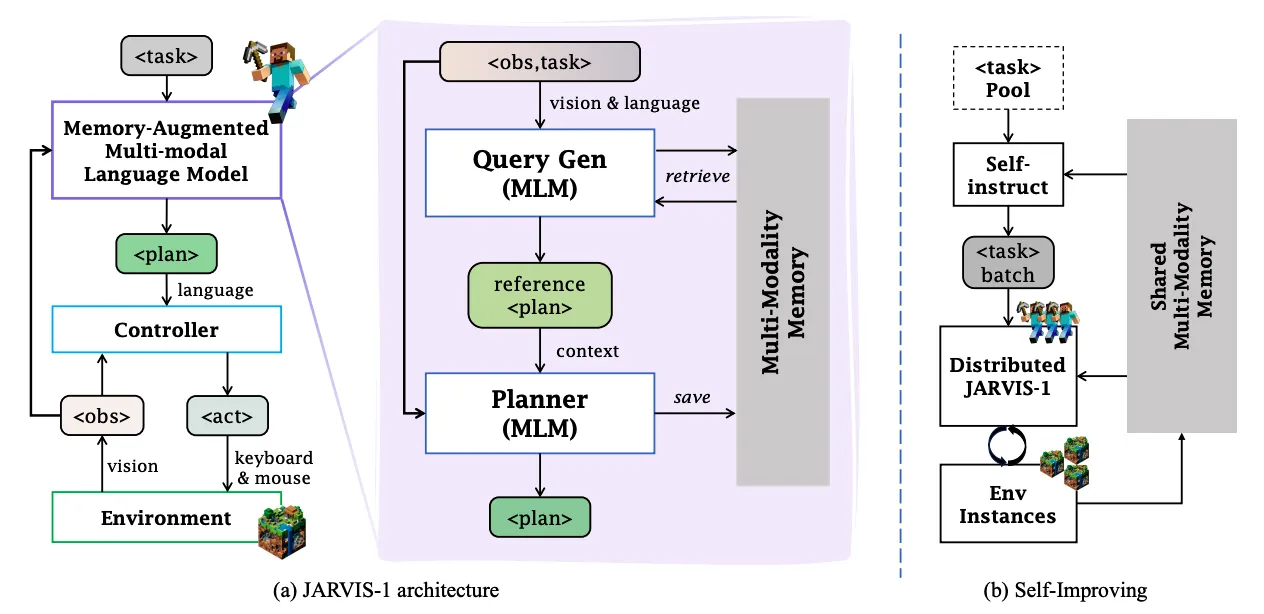
JARVIS-1?是一個開放世界智能體,基于預訓練的多模態語言模型,能夠感知多模態輸入(視覺觀察和人類指令),生成復雜計劃,并在「我的世界」中執行具身控制。JARVIS-1?還配備了一個多模態記憶,它利用預訓練知識和實際游戲生存經驗來提高規劃能力。JARVIS-1?是現有「我的世界」中最通用的智能體,能夠使用與人類一致的控制和觀察空間完成200多個不同任務,從短期任務(例如“砍樹”)到長期任務(例如“獲得一把鉆石鎬”)。在經典的長期任務“獲得鉆石鎬”中,JARVIS-1?的成功率為當前最先進智能體的5倍,并能成功完成更長時間跨度和更具挑戰性的任務。
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models?
arXiv:?https://arxiv.org/pdf/2311.05997.pdf?Project:?JARVIS-1: Open-world Multi-task Agents with Memory-Augmented Multimodal Language Models
 ?
? 08. 本文作者
蔡少斐,北京大學人工智能研究院博士生,CraftJarvis 研究團隊成員之一,導師是梁一韜教授。他的研究興趣主要包括決策大模型、語言大模型以及游戲智能。他已在 CVPR 、NeurIPS 等人工智能頂會上發表過多篇論文,并專注于開放世界下智能體決策控制研究。擔任 ICML、NeurIPS 、 ICLR 等國際學術會議審稿人。
個人主頁:https://phython96.github.io
王子豪,北京大學人工智能研究院博士生,CraftJarvis 研究團隊成員之一,導師為梁一韜教授。曾獲國家獎學金、北京市優秀畢業生等榮譽。主要研究方向為開放世界下多任務智能體的構建,尤其關心基于基礎模型的智能體的泛化能力。近年來在CVPR、NeurIPS等人工智能頂會上發表多篇論文,曾獲ICML研討會最佳論文獎。擔任ICML、NeurIPS、ICLR等多個國際機器學習會議審稿人。
個人主頁: https://zhwang4ai.github.io
關于TechBeat人工智能社區
▼
TechBeat(www.techbeat.net)隸屬于將門創投,是一個薈聚全球華人AI精英的成長社區。
我們希望為AI人才打造更專業的服務和體驗,加速并陪伴其學習成長。
期待這里可以成為你學習AI前沿知識的高地,分享自己最新工作的沃土,在AI進階之路上的升級打怪的根據地!
更多詳細介紹>>TechBeat,一個薈聚全球華人AI精英的學習成長社區?
)
:代碼生成、執行和調試)
)














)

