- 1、HDFS的API操作
- 1.1 客戶端環境準備
- 1.2 API創建文件夾
- 1.3 API上傳
- 1.4 API參數的優先級
- 1.5 API文件夾下載
- 1.6 API文件刪除
- 1.7 API文件更名和移動
- 1.8 API文件詳情和查看
- 1.9 API文件和文件夾判斷
- 2、HDFS的讀寫流程(面試重點)
- 2.1 HDFS寫數據流程
- 2.2 網絡拓撲-節點距離計算
- 2.3 機架感知(副本存儲節點選擇)
- 2.4 讀數據流程
1、HDFS的API操作
1.1 客戶端環境準備
- 首先要配置環境變量


- 其次在IDEA中創建一個Maven工程HdfsClientDemo,并導入相應的依賴坐標+日志添加
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.hamcrest</groupId><artifactId>hamcrest-core</artifactId><version>1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency></dependencies>
</project>
1.2 API創建文件夾
package com.wenxin.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;/*** @author Susie-Wen* @version 1.0* @description:客戶端代碼常用套路* 1、獲取一個客戶端對象* 2、執行相關的操作命令* 3、關閉資源* HDFS zookeeper* @date 2023/12/11 12:27*/
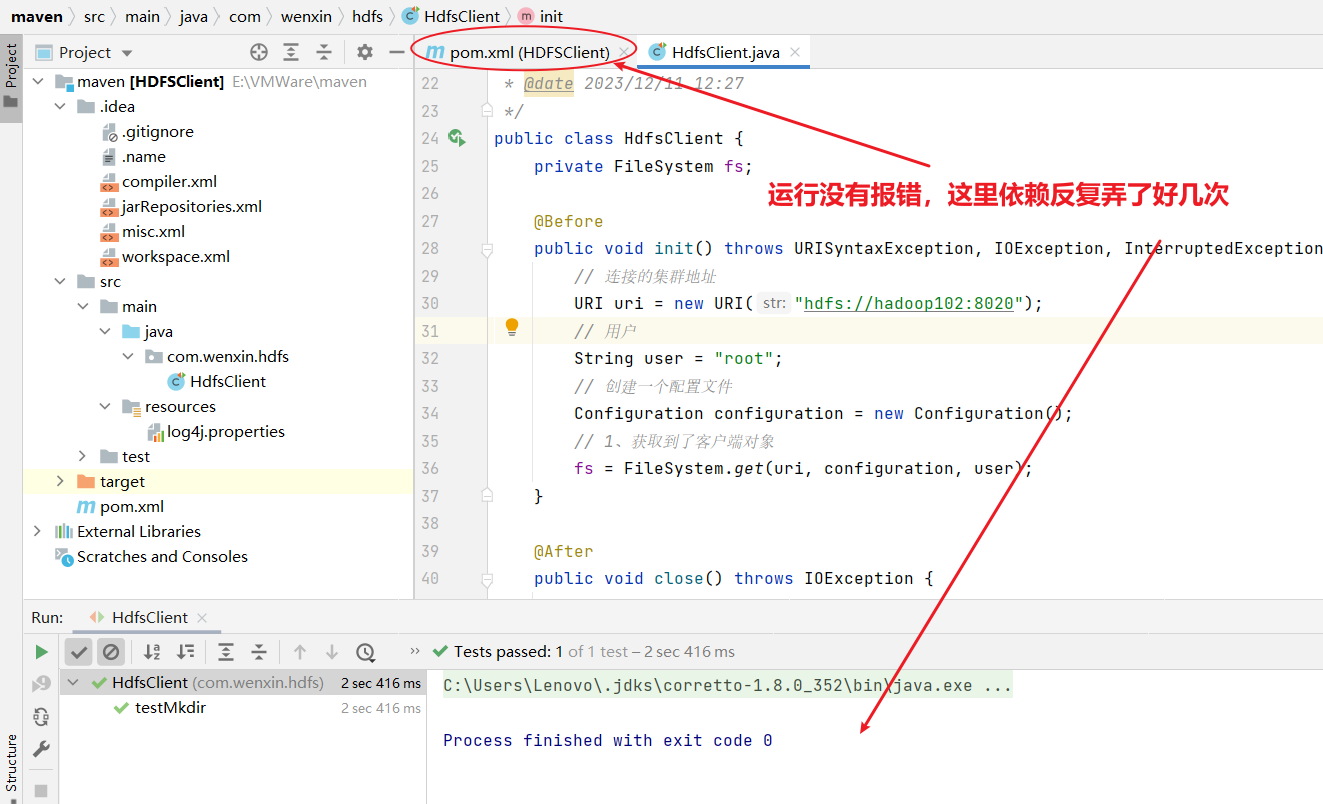
public class HdfsClient {private FileSystem fs;@Beforepublic void init() throws URISyntaxException, IOException, InterruptedException {// 連接的集群地址URI uri = new URI("hdfs://hadoop102:8020");// 用戶String user = "root";// 創建一個配置文件Configuration configuration = new Configuration();// 1、獲取到了客戶端對象fs = FileSystem.get(uri, configuration, user);}@Afterpublic void close() throws IOException {// 3、關閉資源fs.close();}@Testpublic void testMkdir() throws IOException {// 2、創建一個文件夾fs.mkdirs(new Path("/xiyou/huaguoshan"));}
}上面這段代碼把連接和關閉資源都進行了封裝,更加方便。
@Before注解標識的方法 init() 是一個在測試方法執行之前會被調用的初始化方法。@After注解標識的方法 close() 是一個在測試方法執行之后會被調用的清理方法。
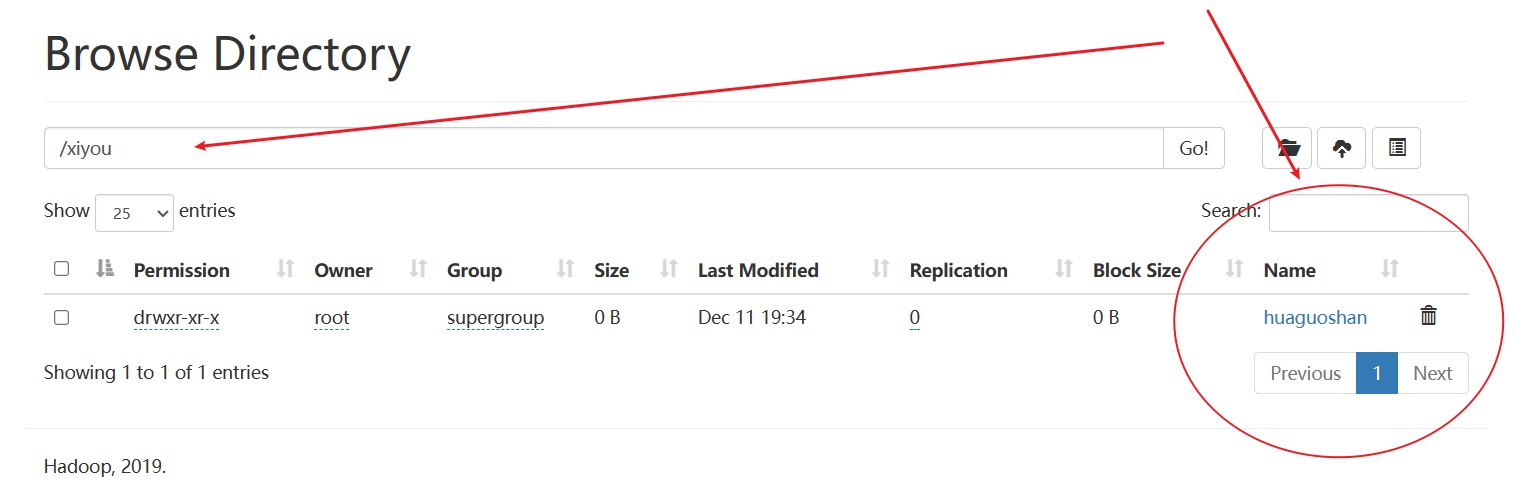
如下所示,確實創建了文件夾
1.3 API上傳
接下來進行API上傳操作:使用客戶端遠程訪問HDFS,之后上傳文件。
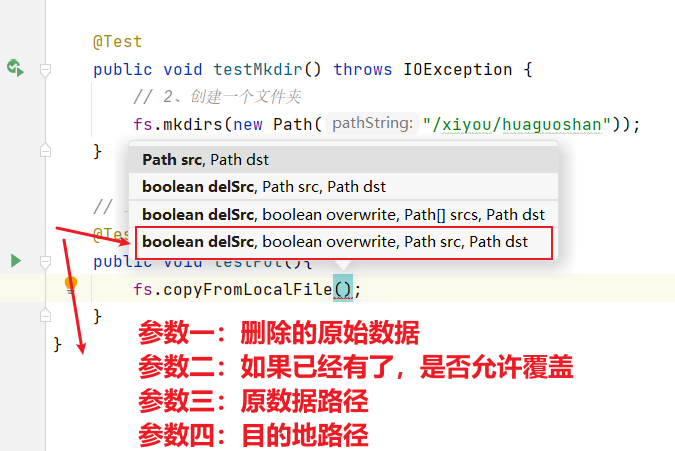
// 上傳:客戶端遠程訪問HDFS,之后上傳文件@Testpublic void testPut() throws IOException {fs.copyFromLocalFile(false,false,new Path("E:\\VMWare\\Centos\\sunwukong.txt"),new Path("hdfs://hadoop102/xiyou/huaguoshan"));}
1.4 API參數的優先級
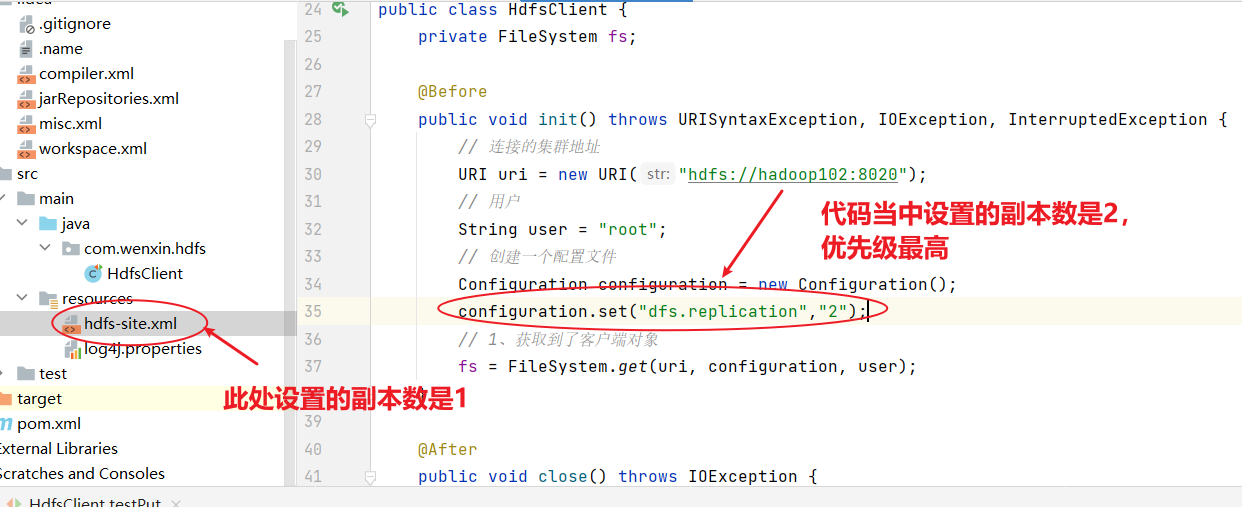
HDFS文件上傳(測試參數優先級)
1)編寫源代碼
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {// 1 獲取文件系統Configuration configuration = new Configuration();configuration.set("dfs.replication", "2");FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");// 2 上傳文件fs.copyFromLocalFile(new Path("d:/sunwukong.txt"), new Path("/xiyou/huaguoshan"));// 3 關閉資源fs.close();
}2)將hdfs-site.xml拷貝到項目的resources資源目錄下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property>
</configuration>
參數優先級排序:(1)客戶端代碼中設置的值 >(2)ClassPath下的用戶自定義配置文件 >(3)然后是服務器的自定義配置(xxx-site.xml) >(4)服務器的默認配置(xxx-default.xml)
1.5 API文件夾下載
下載相當于從HDFS將文件下載到windows本地:
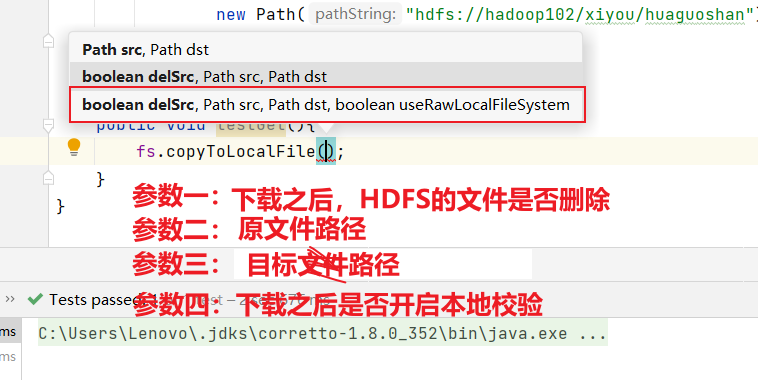
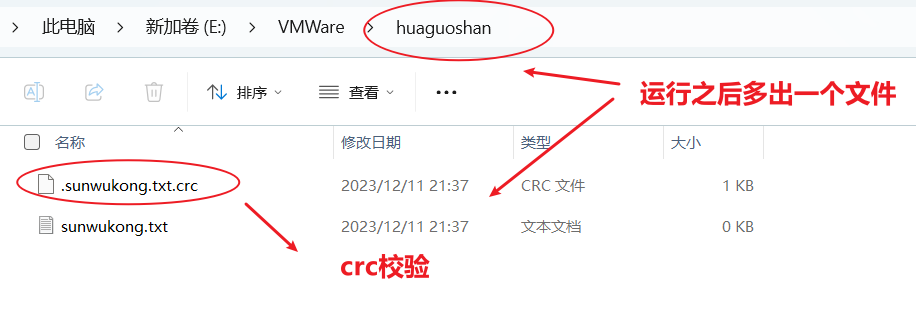
//下載:將文件從HDFS下載到windows當中public void testGet() throws IOException {fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou/huaguoshan"),new Path("E:\\VMWare\\"),false);}
- 如果參數四設置為true的話,就不會進行crc校驗
1.6 API文件刪除
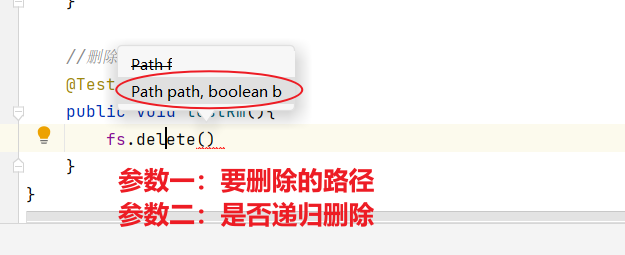
//刪除@Testpublic void testRm() throws IOException {fs.delete(new Path("/xiyou/huaguoshan/sunwukong.txt"),false);}
- 除了刪除文件之外,我們還可以刪除空目錄以及非空目錄
- 多個文件如果是非遞歸刪除的話,會報錯
//刪除@Testpublic void testRm() throws IOException {//1.刪除文件fs.delete(new Path("/xiyou/huaguoshan/sunwukong.txt"),false);//2.刪除空目錄fs.delete(new Path("/xiyou"),false);//3.刪除非空目錄fs.delete(new Path("/xiyou/huaguoshan/"),false);}
1.7 API文件更名和移動

- 包括文件名稱的修改,文件的移動和更名以及目錄的更名
//文件的更名和移動@Testpublic void testMove() throws IOException {//1.文件名稱的修改fs.rename(new Path("/input/word.txt"),new Path("/input/ss.txt"));//2.文件的移動和更名:從input目錄移動到根目錄下并修改姓名fs.rename(new Path("/input/ss.txt"),new Path("/wenxin.txt"));//3.目錄的更名fs.rename(new Path("/input"),new Path("/output"));}
1.8 API文件詳情和查看
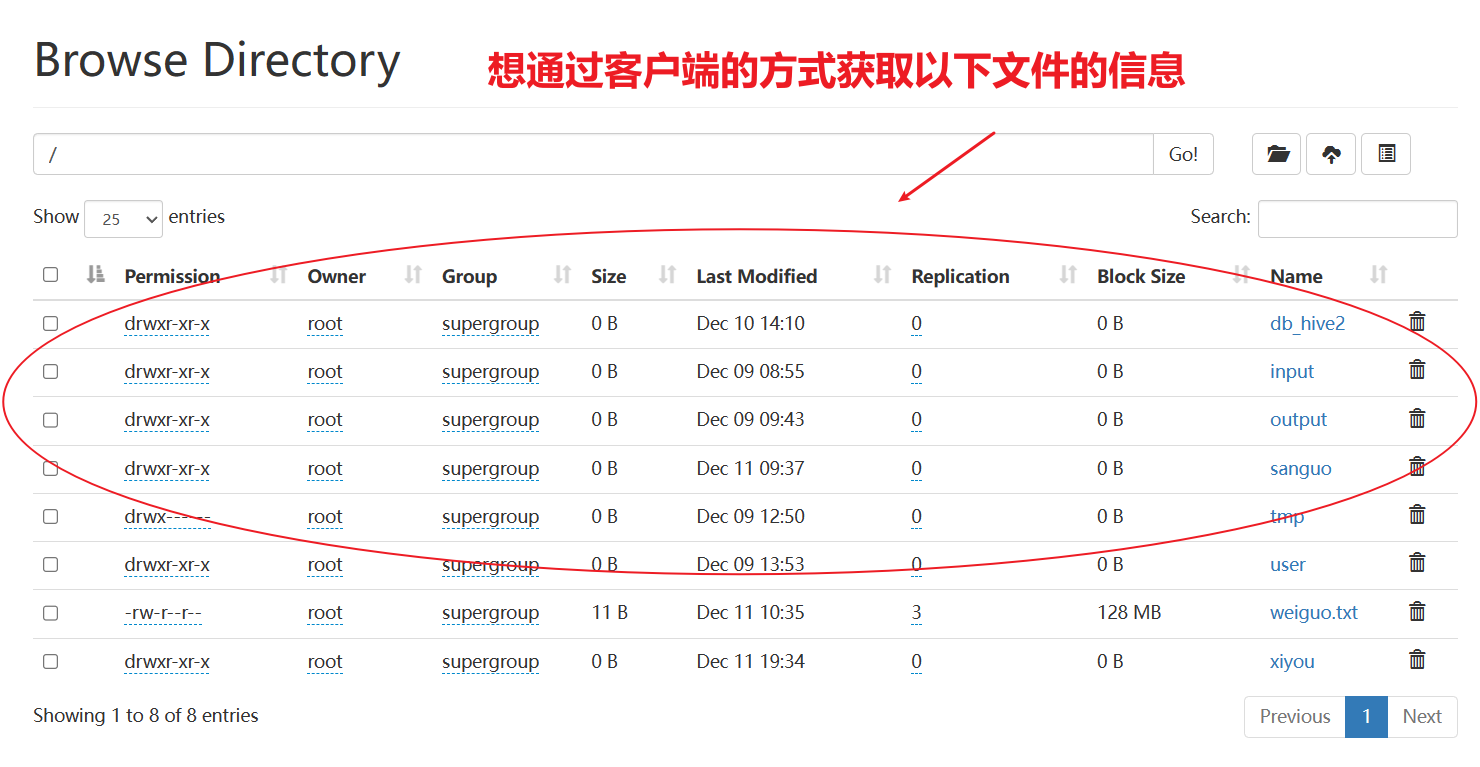

查看文件名稱、權限、長度、塊信息
//獲取文件詳情信息@Testpublic void fileDetail() throws IOException {//1.獲取所有文件信息RemoteIterator<LocatedFileStatus> listFiles=fs.listFiles(new Path("/"), true);//2.遍歷文件while(listFiles.hasNext()){LocatedFileStatus fileStatus=listFiles.next();System.out.println("====="+fileStatus.getPath()+"=====");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getPath());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockLocations());System.out.println(fileStatus.getPath().getName());}}
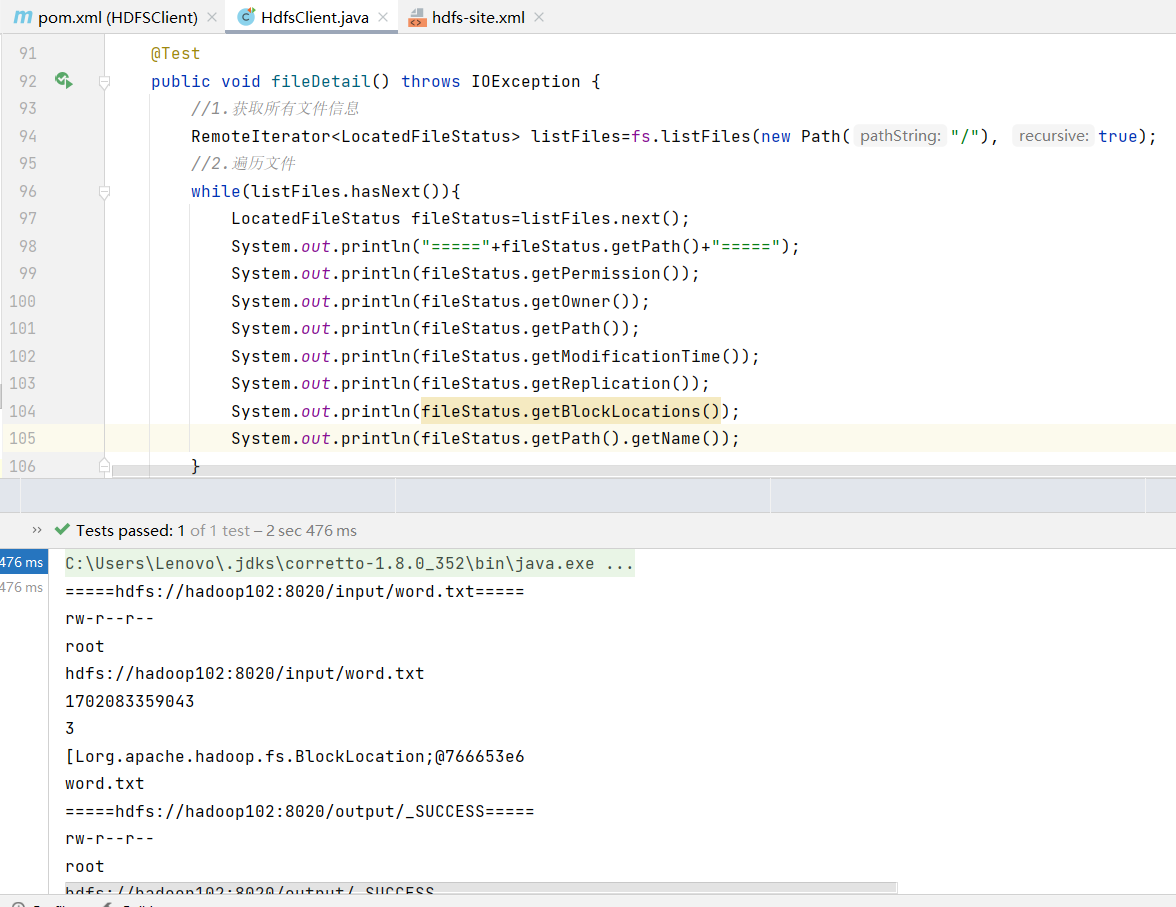
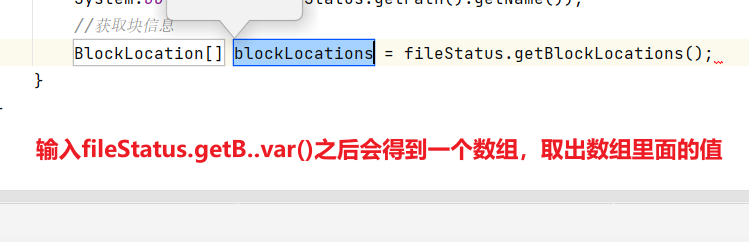
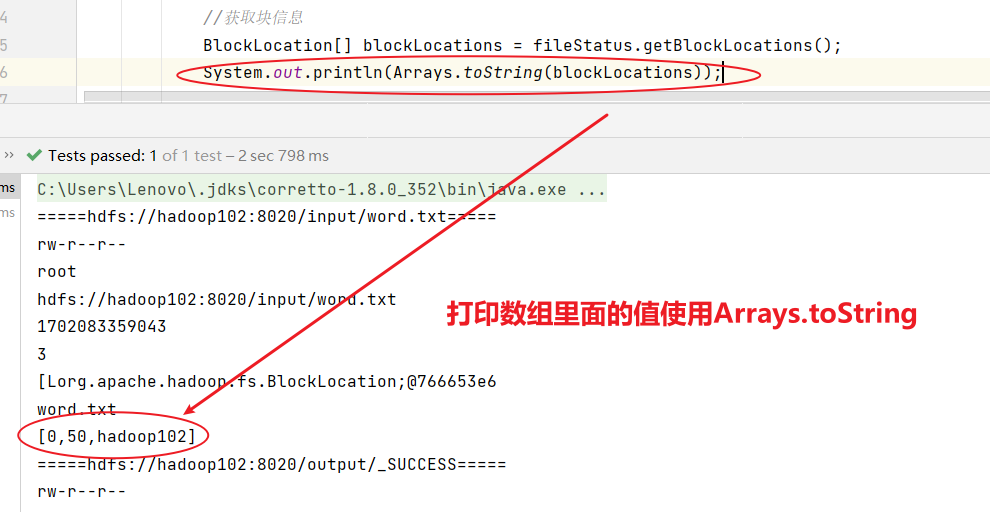
//獲取文件詳情信息@Testpublic void fileDetail() throws IOException {//1.獲取所有文件信息RemoteIterator<LocatedFileStatus> listFiles=fs.listFiles(new Path("/"), true);//2.遍歷文件while(listFiles.hasNext()){LocatedFileStatus fileStatus=listFiles.next();System.out.println("====="+fileStatus.getPath()+"=====");System.out.println(fileStatus.getPermission());System.out.println(fileStatus.getOwner());System.out.println(fileStatus.getPath());System.out.println(fileStatus.getModificationTime());System.out.println(fileStatus.getReplication());System.out.println(fileStatus.getBlockLocations());System.out.println(fileStatus.getPath().getName());//獲取塊信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println(Arrays.toString(blockLocations));}}
1.9 API文件和文件夾判斷
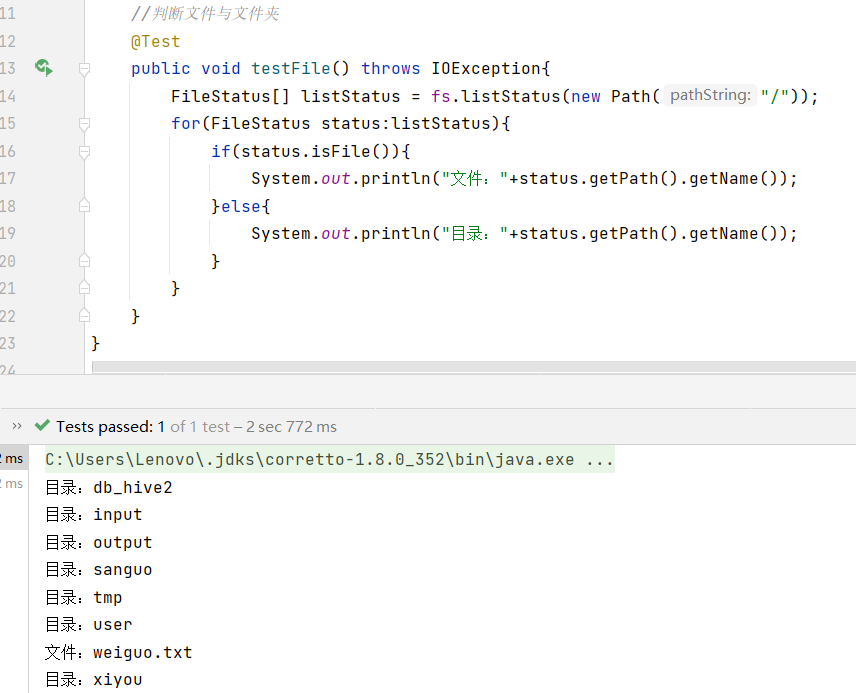
判斷根目錄那個是文件,那個是文件夾
//判斷文件與文件夾@Testpublic void testFile() throws IOException{FileStatus[] listStatus = fs.listStatus(new Path("/"));for(FileStatus status:listStatus){if(status.isFile()){System.out.println("文件:"+status.getPath().getName());}else{System.out.println("目錄:"+status.getPath().getName());}}}
2、HDFS的讀寫流程(面試重點)
2.1 HDFS寫數據流程
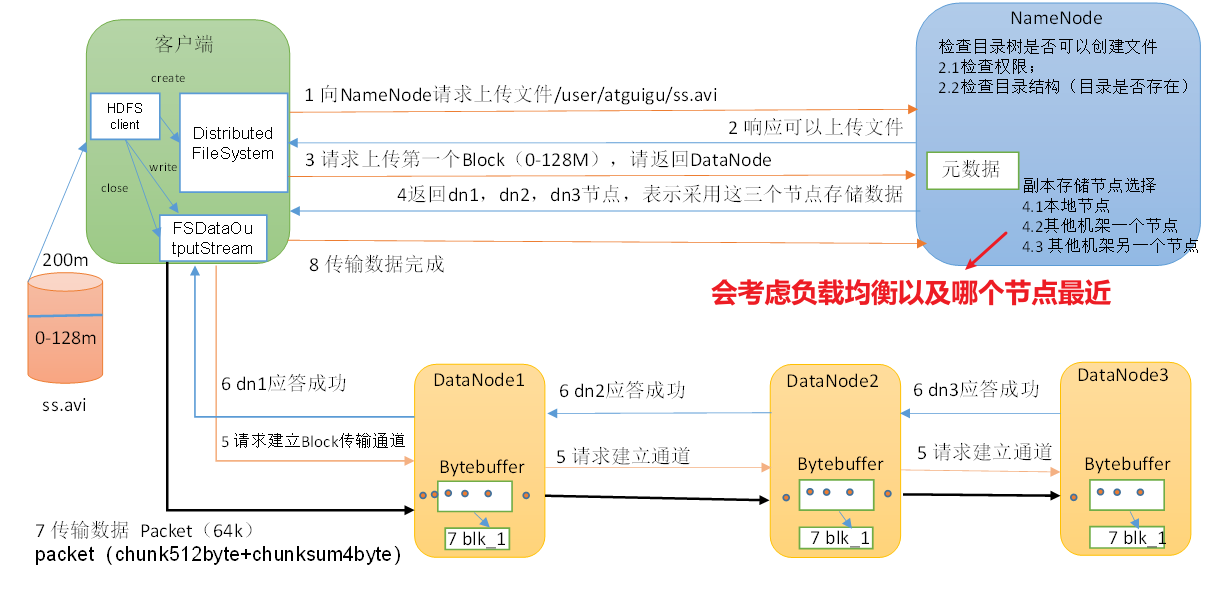 (1)客戶端通過Distributed FileSystem模塊向NameNode請求上傳文件,NameNode檢查目標文件是否已存在,父目錄是否存在。
(1)客戶端通過Distributed FileSystem模塊向NameNode請求上傳文件,NameNode檢查目標文件是否已存在,父目錄是否存在。
(2)NameNode返回是否可以上傳。
(3)客戶端請求第一個 Block上傳到哪幾個DataNode服務器上。
(4)NameNode返回3個DataNode節點,分別為dn1、dn2、dn3。
(5)客戶端通過FSDataOutputStream模塊請求dn1上傳數據,dn1收到請求會繼續調用dn2,然后dn2調用dn3,將這個通信管道建立完成。
(6)dn1、dn2、dn3逐級應答客戶端。
(7)客戶端開始往dn1上傳第一個Block(先從磁盤讀取數據放到一個本地內存緩存),以Packet為單位,dn1收到一個Packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答隊列等待應答。
(8)當一個Block傳輸完成之后,客戶端再次請求NameNode上傳第二個Block的服務器。(重復執行3-7步)。
2.2 網絡拓撲-節點距離計算
在HDFS寫數據的過程中,NameNode會選擇距離待上傳數據最近距離的DataNode接收數據。那么這個最近距離怎么計算呢?
節點距離:兩個節點到達最近的共同祖先的距離總和。
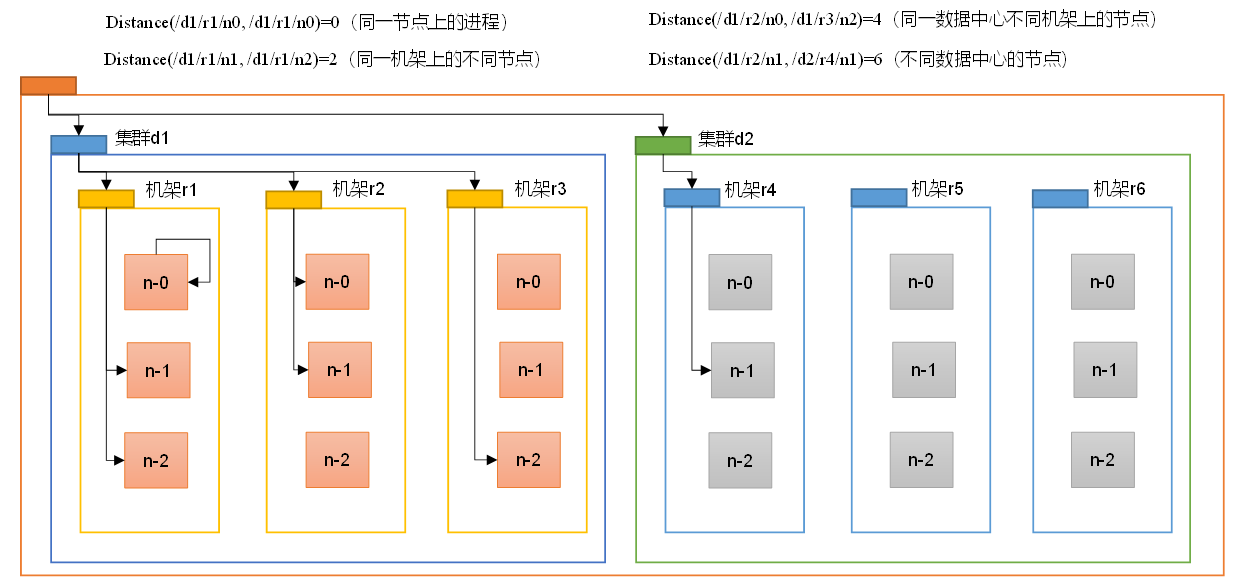
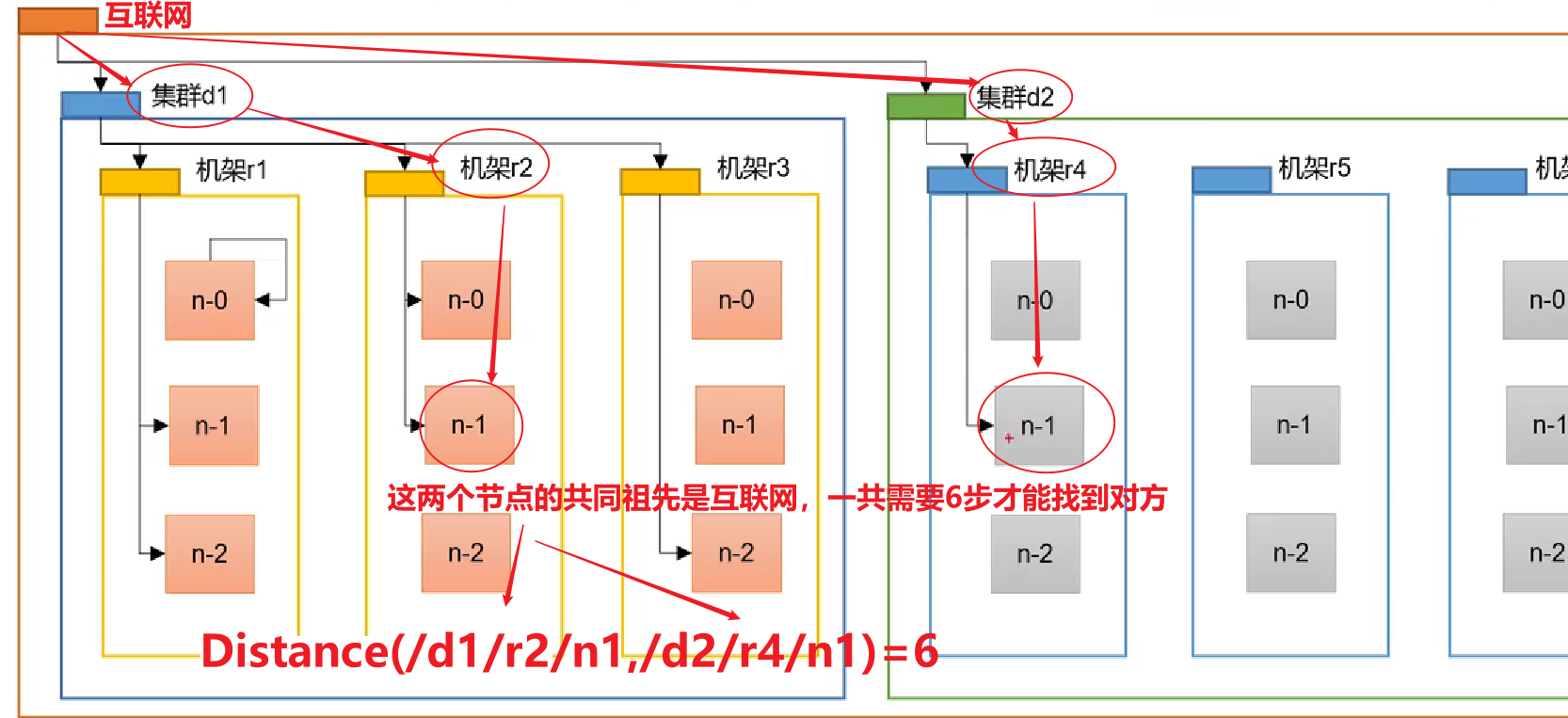
例如,假設有數據中心d1機架r1中的節點n1。該節點可以表示為/d1/r1/n1。利用這種標記,這里給出四種距離描述。
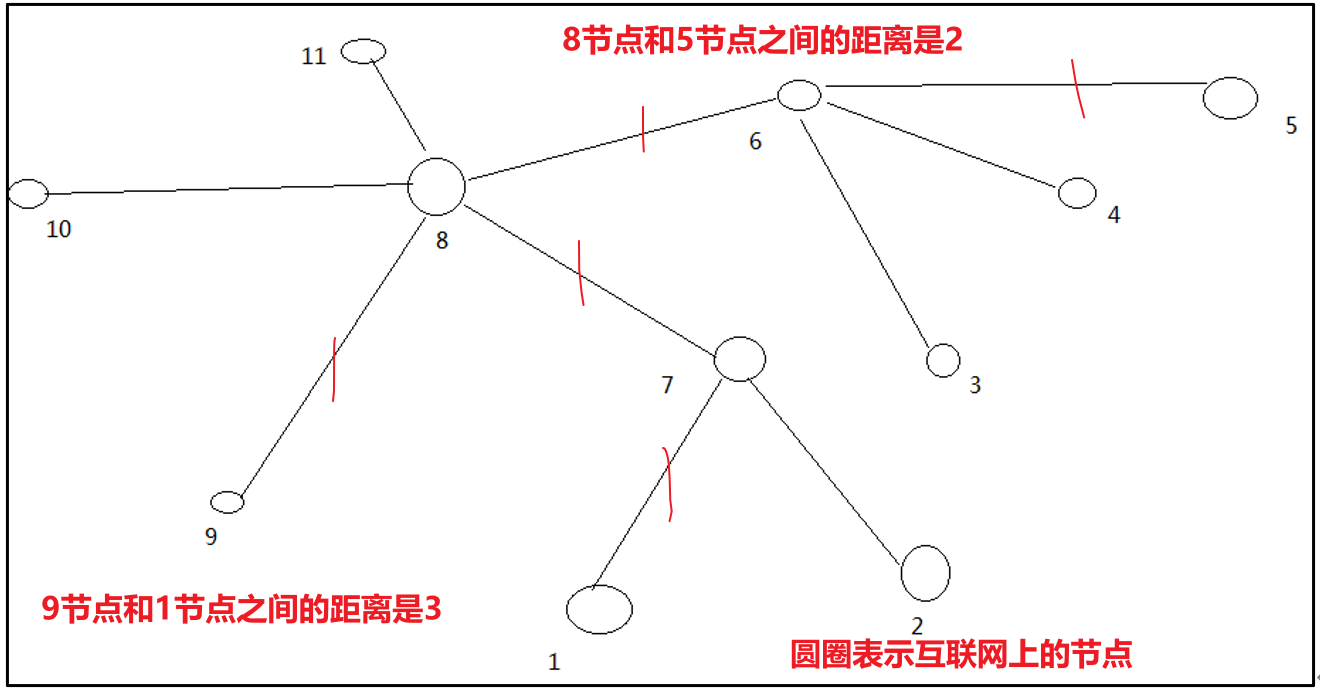
算一算每兩個節點之間的距離:
2.3 機架感知(副本存儲節點選擇)
官方說明:
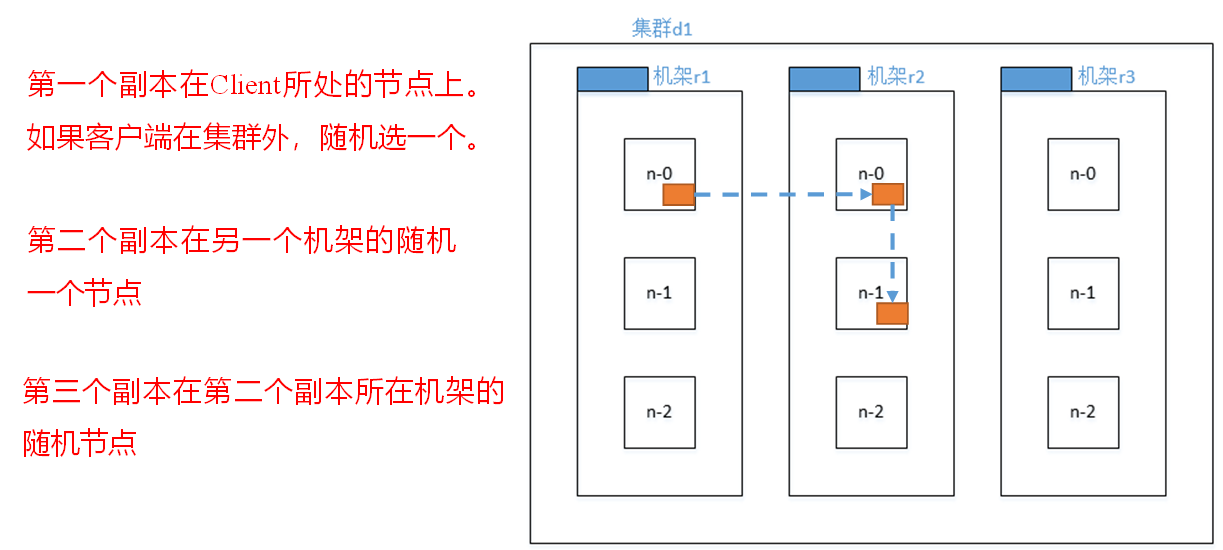
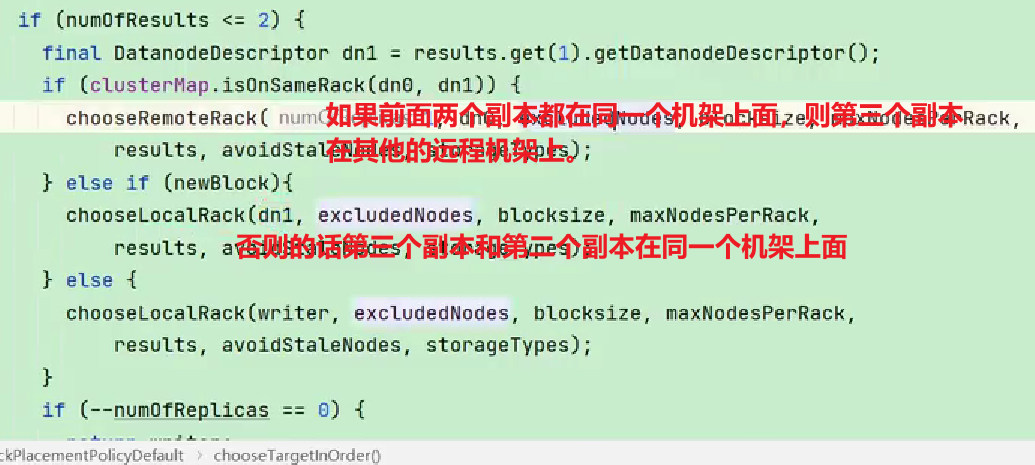
對于常見情況,當副本為3時,HDFS的放置策略是,如果編寫器在datanode上,則將一個副本放在本地計算機上,否則放在隨機datanode上,另一個副本放在不同(遠程)機架中的節點上,最后一個放在同一遠程機架中的不同節點上。此策略減少了機架間的寫入流量,從而總體上提高了寫入性能。機架故障的幾率遠小于節點故障的幾率;該策略不影響數據可靠性和可用性保證。但是,它確實減少了讀取數據時使用的聚合網絡帶寬,因為一個數據塊只放在兩個不同的機架中,而不是三個。使用此策略,文件的副本不會均勻分布在機架上。三分之一的副本位于一個節點上,三分之二的副本位于一個機架上,另外三分之一的副本均勻分布在其余機架上。該策略提高了寫入性能,而不影響數據可靠性或讀取性能。
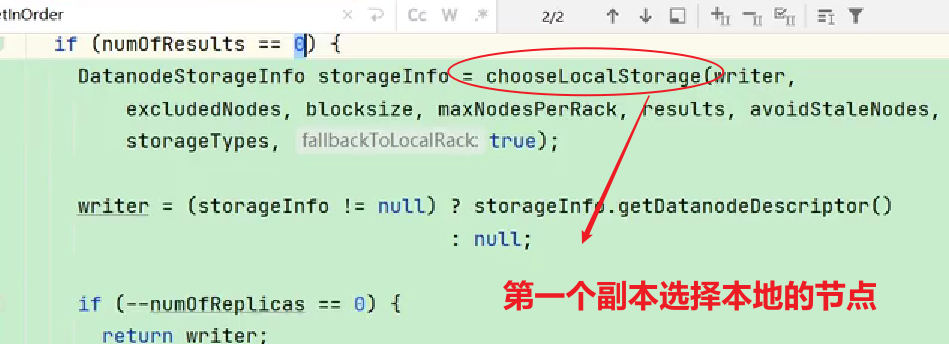
- 第一個副本考慮的是節點距離最近,上傳速度最快。
- 第二個節點保證數據的可靠性。
- 第三個節點在保證數據可靠性的前提下兼顧效率。
查看源碼:
Crtl + n 查找BlockPlacementPolicyDefault,在該類中查找chooseTargetInOrder方法。

2.4 讀數據流程
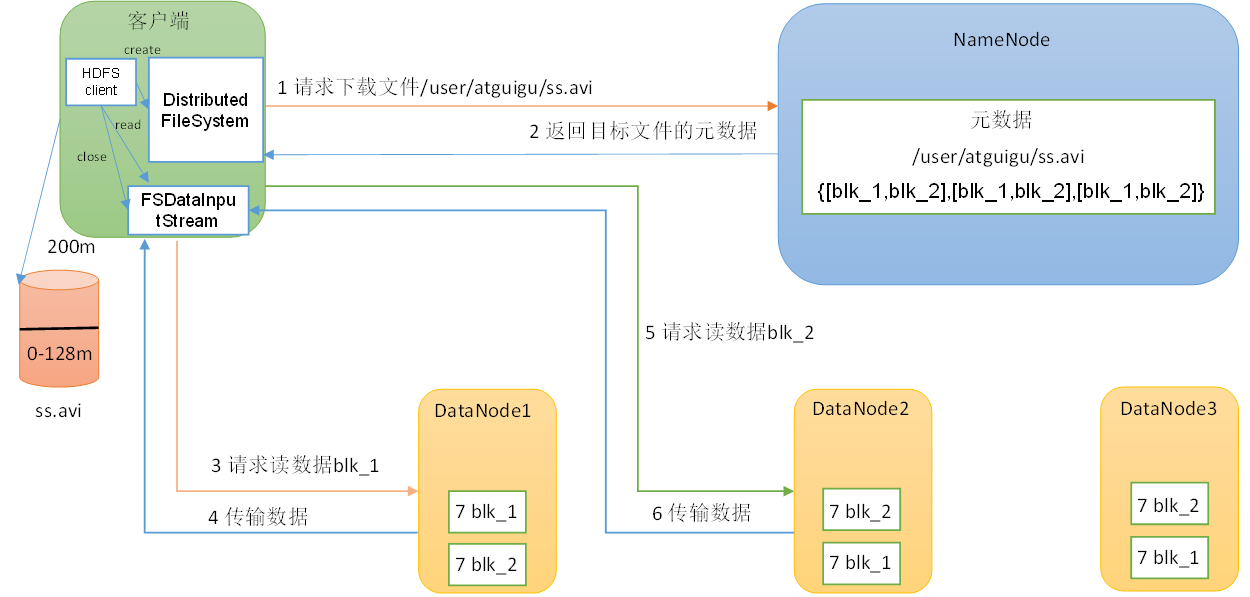
(1)客戶端通過DistributedFileSystem向NameNode請求下載文件,NameNode通過查詢元數據,找到文件塊所在的DataNode地址。【DistributedFileSystem是分布式文件系統對象】
(2)挑選一臺DataNode(就近原則,然后隨機)服務器,請求讀取數據。【除了考慮節點最近之外,還會考慮當前節點的負載能力】
(3)DataNode開始傳輸數據給客戶端(從磁盤里面讀取數據輸入流,以Packet為單位來做校驗)。
(4)客戶端以Packet為單位接收,先在本地緩存,然后寫入目標文件。
- 這里讀取數據采用的是串行讀取,而不是并行讀取。




)
)




)


)




)
