本文概要
這是Android系統進程系列的第四篇文章,本文以自述的方式來介紹logd進程,通過本文您將了解到logd進程存在的意義,以及日志系統的實現原理。(文中的代碼是基于android13)
Android系統進程系列的前三篇文章如下:
我是init進程
Android-屬性服務的設計魅力
Android帝國之進程殺手–lmkd
我是誰
init:“大家好,我是你們的老朋友init進程,今天我把我的出生最早的孩子‘logd進程‘介紹給各位認識,logd那我就把舞臺交給你了,不要緊張,你的二弟‘logd進程‘在介紹自己的時候表現的非常棒,父親相信你你也可以做的更棒!“
logd:“大家好啊!我是logd進程,可以直接叫我logd,‘logd’這不是一個單詞而是‘log daemon’的縮寫,翻譯為中文是‘日志守護進程’。”
一個進程迫不及待地說:“不好意思logd,我先插句話,我想起來了,我們每個進程都有打印日志的需求,在java層使用Log.i、Log.d、Log.e等Log類的方法來打印日志,在native層用ALOGI、ALOGD等方法來打印日志,這些打印日志的方法是不是都和你有關?”
“是的,剛剛這位進程提到的這些打印日志的方法都和我有關,別看你們在使用的時候特別簡單,其實這些日志信息在到達我這的時候要經過‘千山萬水的旅程‘。回歸正題,我的名字叫logd(日志守護進程),主要的功能是給除了init、logd進程的所有用戶空間進程提供日志打印的功能,這些日志信息我會收集起來,以便日志消費者進行消費(如logcat展示日志信息)”
大家對我應該有了一個初步的印象了,我雖然不像你們人類的偉人那么偉大,但是我覺得有必要介紹下我的出生。
我的出生
我出生在一個"單親家庭",我只有父親沒有母親,我的父親是init進程,我的父親是一個“不稱職的父親“,為啥這樣說呢,它對于我何時創建、創建后叫啥名字等這些信息,它統統不知道,你們說它負責嗎,我只需要把這些信息用init腳本語言配置好后交給它即可,剩下的事就全權交給它了,腳本語言配置的信息如下:
//文件路徑:/system/logging/logd/logd.rc//logd是進程的名字,/system/bin/logd 代表當init進程fork logd成功后,需要執行的可執行文件
service logd /system/bin/logd//下面三個socket分別代表需要創建的三個server socketsocket logd stream 0666 logd logdsocket logdr seqpacket 0666 logd logdsocket logdw dgram+passcred 0222 logd logd//kmsg代表內核會把內核的日志信息存儲在這個文件中file /proc/kmsg rfile /dev/kmsg wuser logdgroup logd system package_info readproccapabilities SYSLOG AUDIT_CONTROLpriority 10task_profiles ServiceCapacityLowonrestart setprop logd.ready false省略其他信息......//文件路徑:/system/core/rootdir/init.rc,下面的內容是該文件的其中一部分//on init:代表init觸發器觸發的時候會執行下面的各種命令
on init省略其他命令......//start logd:start命令會創建進程,logd與上面logd.rc中service后面的logd一致start logd我的出生是不是非常的簡單啊,這其實是腳本語言和init進程的功勞,可以點擊 我是init進程 這篇文章來了解init進程的知識、以及如何通過腳本語言來創建子進程。
當init把我創建成功后,執行下面的方法后,我才可以為各進程提供日志功能。
//文件路徑:/system/logging/logd/main.cpp
int main(int argc, char* argv[]) {// We want EPIPE when a reader disconnects, not to terminate logd.signal(SIGPIPE, SIG_IGN);省略其他代碼.....return EXIT_SUCCESS;
}
從雛形說起
在介紹我是誰的時候提到了我的主要功能是給除了init、logd進程的所有用戶空間進程提供日志打印的功能,這些日志信息我會收集起來,以便日志消費者進行消費(如logcat展示日志信息),我給這個功能起了一個高大上的名字日志系統,那我接下來就來介紹下日志系統的實現原理,這應該也是大家最感興趣的內容了。
我計劃先從日志系統的“雛形”講起,從雛形講起的主要原因:一方面是我在設計日志系統的時候也是從雛形開始設計,雛形先有一個大概的模塊劃分以及模塊之間的相互關系,進而再對每個模塊內部進行詳細設計,最終才有了日志系統;第二方面是遵循你們人類學習知識的一個過程,你們人類在學習知識的時候比如學習一門編程語言的時候需要先看下大綱都有哪些內容,進而再有針對性的去學習相應章節的內容,而不要一上來就開始摳細節。
雛形起源
“我先問大家一個問題:如何實現一個進程內的日志打印、顯示功能呢?給大家幾分鐘的考慮時間。”
一個進程高高的舉起了手:“這個我會啊,要實現進程內的日志打印、顯示功能這還是很簡單的,首先需要用到生產者/消費者模式,日志打印功能就是日志生產者,日志顯示功能就是日志消費者。這就是大概的思路了。”
“這位仁兄回答的很好,我用一幅圖來總結下實現該功能的邏輯”
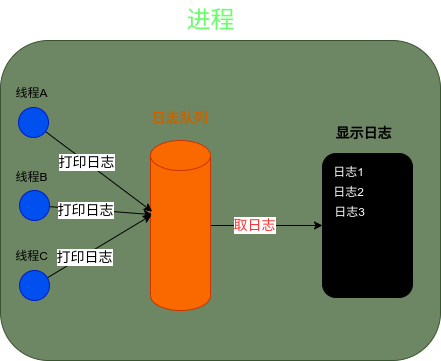
如上圖,進程內實現日志打印、顯示功能主要涉及到以下三部分:
- 日志生產者:進程中的各線程調用相應的方法把需要打印的日志放入日志隊列
- 日志隊列:主要用來存放日志,是按日志存放的先后順序存放在隊列中,需要做好同步處理
- 日志消費者:顯示日志的模塊從日志隊列中把日志按時間先后順序取出來,進行顯示
雛形形成
日志系統解決的是進程之間的日志打印、顯示需求,它和進程內日志打印、顯示的雛形基本是差不多的,只不過前者日志生產者是其他進程,而日志消費者也是其他進程,日志隊列是logd進程。如下圖:

如上圖,日志系統雛形涉及到以下三部分:
- 日志生產者:日志的生產者是其他進程,通過進程通信的方式把日志傳遞到日志收集分發中心
- 日志收集分發中心:位于logd進程內,其中日志隊列是用來存放收集到的日志,同時還會把收集到的日志分發給日志消費者
- 日志消費者:日志的消費者也是其他進程,同樣也是通過進程通信的方式把日志傳遞給消費者
日志生產者會有多個同時日志消費者也有多個,日志收集分發中心、日志生產者、日志消費者形成了日志系統的雛形,那我就從這三部分來介紹雛形是如何一步步衍化為日志系統的。
日志收集分發中心
日志收集分發中心從名字上大家就能明白它的作用,日志收集分發中心存在于我logd進程內,主要作用是從日志生產者生產的日志收集起來,同時把收集到的日志分發給日志消費者。日志收集分發中心是日志系統的最重要的模塊,它的設計的好壞會嚴重影響到日志系統,因此在設計的時候我logd花了非常大的精力,日志收集分發中心又可以分為三部分:日志隊列、日志收集中心、日志分發中心,因此會從這三部分入手來進行介紹。
日志隊列
日志隊列從名字上就可以顯而易見知道它是用來存儲日志的,這個日志隊列可不是像你們想象的那種簡單的日志隊列,它面對的環境可是非常復雜的:首先存儲的日志是非常非常多的,可不是僅僅只存儲一個進程內的日志,它存儲的是除了init和logd之外所有的用戶空間進程的所有日志;其次每時每刻都會有各種日志需要存儲。因此日志隊列的性能、存儲量的大小會影響到日志系統。
日志隊列有以下幾個要求:
- 日志隊列中的日志需要存儲在內存中,不會因為日志消費者消費了對應日志,該日志就從日志隊列中刪除
- 可以通過命令來控制日志隊列的狀態比如清除某些日志等
- 日志隊列中存儲的日志總量是有最大限制的,不可能無上限的存下去如果這樣肯定會出現內存溢出的
日志分類
先從一個問題講起
如果日志隊列存儲的日志總量達到了最大上限,那采取的措施肯定是需要先把舊的日志清除掉以便騰出更多的存儲空間,但是如果按這個策略執行的話,就有可能出現一個問題:假如有一些重要的日志比如crash日志,并且它們在日志隊列中是最老的日志,那如果達到日志上限的時候,就會把這些重要的日志清理掉。這個問題肯定會遭到開發者罵娘的,明明出現了crash,但是卻沒有抓到。其實這個問題如果是完全解決掉,那是完全不可能的,因為存儲上限的存在,老的日志肯定會被清除掉,對于這個問題能做的就是讓這種概率降到最低最低并且對于crash這種類型的日志盡量保存更多的日志,那如何能做到呢?
logd自信的說:“先不要慌,遇到問題咱們就想辦法,辦法總比問題多。”
一個進程說:“我想到一個辦法:能不能消費者消費掉了對應日志后,把對應日志從隊列中清除掉,這樣的話就可以大大的降低這個問題的概率。”
logd:“這個辦法行不通,因為日志隊列中的日志,它面對的消費者是很多的,日志隊列中的日志對于所有消費者來說是公共資源,如果因為某個消費者消費了對應日志而把這些日志刪掉,那其他的消費者不就取不到這些被刪掉的日志了。這肯定是有問題的。”
這個進程接著問“那如果把存儲日志的上限值設置大些呢?”
“這個確實可以降低問題概率,但是我覺得這個概率還沒到更低更低。咱們可以從查找問題的根源入手,找到問題根源進而想對策。”
問題的根源其實是不管什么樣的日志(crash、kernel、app日志)都混雜在一起,就是因為它們都混雜在一起,所有的日志都共用一個最大上限值。那如果我們采用分而治之的策略呢,分而治之就是對日志進行分類,每種類型的日志分別有自己的內存最大上限值,因為每種類型的日志使用了自己的內存上限值,那就可以保存更多的日志了,進而就可以非常大非常大的降低此問題的概率。同時對日志分類也可以帶來別的好處比如消費者可以針對性的關注自己關心的類別日志,在生產者生產日志的時候可以增加權限控制(比如某種類型的日志只有生產者經過權限校驗后才可以把它生產的日志放入隊列)。
可以把日志分類為LOG_ID_MAIN、LOG_ID_RADIO、LOG_ID_EVENTS、LOG_ID_SYSTEM、LOG_ID_CRASH、LOG_ID_SECURITY、LOG_ID_KERNEL,其中LOG_ID_MAIN是app進程的日志(開發者在開發app的時候打印的日志就是這種類型),LOG_ID_EVENTS是event類型日志(比如Activity生命周期),LOG_ID_SYSTEM是systemserver進程的日志,LOG_ID_CRASH是崩潰類型日志,LOG_ID_KERNEL是kernel類型日志。
下面是代碼,有興趣可以看下:
//文件路徑:/system/logging/liblog/include/android/log.h
typedef enum log_id {LOG_ID_MIN = 0,//app進程的日志/** The main log buffer. This is the only log buffer available to apps. */LOG_ID_MAIN = 0,/** The radio log buffer. */LOG_ID_RADIO = 1,//event類型日志,比如activity生命周期之類的/** The event log buffer. */LOG_ID_EVENTS = 2,//systemserver進程的日志,比如AMS/** The system log buffer. */LOG_ID_SYSTEM = 3,//崩潰日之惠/** The crash log buffer. */LOG_ID_CRASH = 4,/** The statistics log buffer. */LOG_ID_STATS = 5,/** The security log buffer. */LOG_ID_SECURITY = 6,//kernel日志/** The kernel log buffer. */LOG_ID_KERNEL = 7,LOG_ID_MAX,/** Let the logging function choose the best log target. */LOG_ID_DEFAULT = 0x7FFFFFFF
} log_id_t;
每種類型的日志在初始化的時候都會分配最大內存上限值,如下代碼:
//文件路徑:/system/logging/logd/SimpleLogBuffer.cpp , SimpleLogBuffer是其中一種日志隊列
void SimpleLogBuffer::Init() {//log_id_for_each方法會遍歷上面 所有的日志分類log_id_for_each(i) {//調用SetSize方法設置每種類型的最大內存值if (!SetSize(i, GetBufferSizeFromProperties(i))) {SetSize(i, kLogBufferMinSize);}}省略代碼......
}bool SimpleLogBuffer::SetSize(log_id_t id, size_t size) {省略代碼......auto lock = std::lock_guard{logd_lock};max_size_[id] = size;return true;
}簡單日志隊列
logd:“介紹完日志的分類,問大家個問題,你們認為簡單的日志隊列應該是啥樣的?”
一個進程說:“這題我會啊,簡單日志隊列首先可以選用列表list來存儲日志,新的日志會加入到list的尾部位置,越是老的日志越是位于list的頭部位置。”
logd:“這位兄弟答的非常正確,我剛好也設計了一個類來實現簡單日志隊列的功能,它的名字是SimpleLogBuffer。我用一張圖總結了下它的結構和工作流程。”
SimpleLogBuffer的結構和工作流程圖:

如上圖,SimpleLogBuffer的屬性logs_是一個list隊列,list中存放的元素是LogBufferElement,LogBufferElement包含了日志信息及log_id(它是上面介紹的日志分類的id)等其他信息。屬性max_size_是一個數組,數組的索引是log_id(日志分類id),它存儲了每種類型日志的內存最大上限值。
當有新的LogBufferElement數據加入logs_隊列的時候,會從max_size_取到該類別日志的最大上限值,進而去檢測該類型的日志總量是否達到了最大上限值,達到了就開始清理老的日志。
下面是對應代碼,有興趣可以看下:
//文件路徑:/system/logging/logd/SimpleLogBuffer.cpp//添加日志到隊列,log_id日志類別id
int SimpleLogBuffer::Log(log_id_t log_id, log_time realtime, uid_t uid, pid_t pid, pid_t tid,const char* msg, uint16_t len) {省略代碼......auto lock = std::lock_guard{logd_lock};//每條日志都對應一個sequence,從1開始每次加1auto sequence = sequence_.fetch_add(1, std::memory_order_relaxed);//log_id, realtime, uid, pid, tid, sequence, msg, len生成LogBufferElement對象LogInternal(LogBufferElement(log_id, realtime, uid, pid, tid, sequence, msg, len));return len;
}//添加LogBufferElement到隊列
void SimpleLogBuffer::LogInternal(LogBufferElement&& elem) {log_id_t log_id = elem.log_id();//添加到logs_隊列中logs_.emplace_back(std::move(elem));stats_->Add(logs_.back().ToLogStatisticsElement());//如若達到上限嘗試去清除老的日志MaybePrune(log_id);//通知監聽者有新日志reader_list_->NotifyNewLog(1 << log_id);
}void SimpleLogBuffer::MaybePrune(log_id_t id) {unsigned long prune_rows;//ShouldPrune返回true則代表需要清理該日志類別的舊日志if (stats_->ShouldPrune(id, max_size_[id], &prune_rows)) {//清理舊日志,id為日志類別,prune_rows需要清理多少行Prune(id, prune_rows, 0);}
}bool SimpleLogBuffer::Prune(log_id_t id, unsigned long prune_rows, uid_t caller_uid) {省略代碼......return true;
}
壓縮功能的日志隊列
簡單日志隊列正常工作是完全沒有任何問題的,但是為了在有限的內存下存儲更多的日志,我設計了具有壓縮功能的日志隊列,它的名字是SerializedLogBuffer,下面是它結構和工作流程圖:
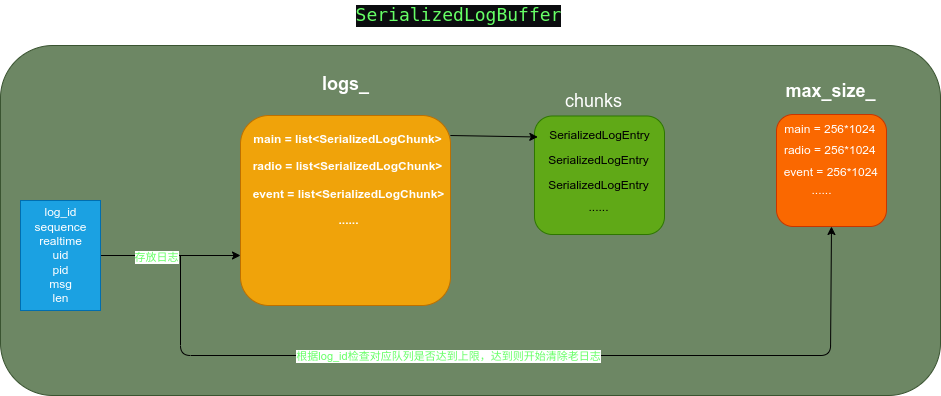
如上圖,SerializedLogBuffer的屬性logs_它是一個數組,數組的索引是log_id(日志類別id),它的每個元素是一個list隊列,隊列中包含的元素是SerializedLogChunk;
SerializedLogChunk是一個具有日志壓縮功能的類,它的每個元素是SerializedLogEntry,SerializedLogChunk在創建的時候會分配一個size,當要寫入的SerializedLogEntry超過了這個size值后,就會把當前的SerializedLogChunk的contents_進行壓縮,壓縮后的數據存放在compressed_log_。
具體代碼如下,有興趣可以看下:
//文件路徑:/system/logging/logd/SerializedLogBuffer.cpp//存放日志,log_id日志類別id
int SerializedLogBuffer::Log(log_id_t log_id, log_time realtime, uid_t uid, pid_t pid, pid_t tid,const char* msg, uint16_t len) {省略代碼......//生成sequence,每個日志都對應一個sequenceauto sequence = sequence_.fetch_add(1, std::memory_order_relaxed);auto lock = std::lock_guard{logd_lock};//調用LogToLogBuffer開始加入日志auto entry = LogToLogBuffer(logs_[log_id], max_size_[log_id], sequence, realtime, uid, pid, tid,msg, len);stats_->Add(entry->ToLogStatisticsElement(log_id));//若超過上限值,則開始清除該日志類別的老的日志MaybePrune(log_id);//通知監聽者有新的日志可以讀取了reader_list_->NotifyNewLog(1 << log_id);return len;
}//開始加入日志
static SerializedLogEntry* LogToLogBuffer(std::list<SerializedLogChunk>& log_buffer,size_t max_size, uint64_t sequence, log_time realtime,uid_t uid, pid_t pid, pid_t tid, const char* msg,uint16_t len) {//若為empty,則push一個SerializedLogChunk,它的大小是max_size / SerializedLogBuffer::kChunkSizeDivisorif (log_buffer.empty()) {log_buffer.push_back(SerializedLogChunk(max_size / SerializedLogBuffer::kChunkSizeDivisor));}auto total_len = sizeof(SerializedLogEntry) + len;//若最后的SerializedLogChunk沒有空間存儲當前日志if (!log_buffer.back().CanLog(total_len)) {//調用FinishWriting方法會對最后的SerializedLogChunk進行壓縮log_buffer.back().FinishWriting();//往log_buffer重新push一個SerializedLogChunklog_buffer.push_back(SerializedLogChunk(max_size / SerializedLogBuffer::kChunkSizeDivisor));}//調用SerializedLogChunk的Log方法把新日志寫入return log_buffer.back().Log(sequence, realtime, uid, pid, tid, msg, len);
}//文件路徑:/system/logging/logd/SerializedLogChunk.cpp
SerializedLogEntry* SerializedLogChunk::Log(uint64_t sequence, log_time realtime, uid_t uid,pid_t pid, pid_t tid, const char* msg, uint16_t len) {auto new_log_address = contents_.data() + write_offset_;auto* entry = new (new_log_address) SerializedLogEntry(uid, pid, tid, sequence, realtime, len);memcpy(entry->msg(), msg, len);write_offset_ += entry->total_len();highest_sequence_number_ = sequence;return entry;
}
不管是SerializedLogBuffer還是SimpleLogBuffer都會在我logd啟動后,選擇其中一種作為日志系統的日志隊列,當然還有一種類型的日志隊列ChattyLogBuffer(不是很常用就不贅述了),相關代碼如下:
//文件路徑:/system/logging/logd/main.cpp
int main(int argc, char* argv[]) {省略其他代碼......//獲取logd.buffer_type屬性對應的值,默認值是serializedstd::string buffer_type = GetProperty("logd.buffer_type", "serialized");// LogBuffer is the object which is responsible for holding all log entries.LogBuffer* log_buffer = nullptr;//根據buffer_type的值,來對日志隊列log_buffer進行初始化,一般情況下都會初始化SerializedLogBuffer的日志隊列if (buffer_type == "chatty") {log_buffer = new ChattyLogBuffer(&reader_list, &log_tags, &prune_list, &log_statistics);} else if (buffer_type == "serialized") {log_buffer = new SerializedLogBuffer(&reader_list, &log_tags, &log_statistics);} else if (buffer_type == "simple") {log_buffer = new SimpleLogBuffer(&reader_list, &log_tags, &log_statistics);} else {LOG(FATAL) << "buffer_type must be one of 'chatty', 'serialized', or 'simple'";}省略其他代碼......
}
總結
日志隊列為了在有限的內存能夠存放更多的日志:首先采用分而治之的辦法,對日志進行了分類分為LOG_ID_MAIN、LOG_ID_RADIO、LOG_ID_EVENTS、LOG_ID_SYSTEM、LOG_ID_CRASH、LOG_ID_SECURITY、LOG_ID_KERNEL,每種類型的日志分別有自己的內存最大上限值,因為每種類型的日志使用了自己的內存上限值,那就可以保存更多的日志了;其次設計了具有壓縮功能的日志隊列SerializedLogBuffer,它可以對日志進行壓縮,這樣就能存儲更多的日志了。
日志收集中心
日志收集中心的作用就是把生產者生產的日志收集起來放入日志隊列中,因為日志的生產者是位于其他進程,而日志收集中心是位于logd進程,因此要想把它們生產的日志收集起來就需要一個收集渠道,你們人類有句話是那樣說的“要想富先修路”,因此要想收集日志,就需要把收集渠道先“修好”。
收集渠道
收集渠道其實就是解決生產日志進程如何與logd進程通信,進程通信的方法有socket、signal、binder、共享內存等,咱們還是按照老慣例先結合咱們的使用場景進而在決定使用哪種方法。咱們的使用場景是:生產者把生產的日志傳遞給logd進程,對于傳遞過程有以下要求:首先是傳遞是串行的,也就是只要收到日志我就會直接放入日志隊列中,我不需要關心是按照時間或者別的因素對放入日志隊列的日志進行排序;其次是對于傳遞快慢沒有要求必須非常快;最后傳遞渠道是一對多的關系,也就是logd進程是server端,日志生產進程是client端,也就是C/S模式。
因此基于以上使用場景,收集渠道應該使用socket通信方式,socket首先是C/S模式,logd是socket的server端,其他生產者進程是socket的client端;其次socket通信是串行的,需要傳遞了一個數據再傳遞下個數據。而binder通信方式雖然也可以做到C/S模式,但是它的通信是并行的,也就是會出現多個數據同時傳遞,如若采用binder通信就需要對于收到的日志按時間或者別的因素重新排序,而我可不想做這種出力不討好的工作。
收集渠道會啟動一個名字為logdw的server socket,server socket啟動后還會啟動一個單獨的線程,不斷循環監聽日志生產者發送過來的日志。
收集渠道的相關代碼如下,有興趣可以看下:
//文件路徑:/system/logging/logd/main.cpp
int main(int argc, char* argv[]) {省略其他代碼......// LogListener listens on /dev/socket/logdw for client// initiated log messages. New log entries are added to LogBuffer// and LogReader is notified to send updates to connected clients.// 實例化LogListenerLogListener* swl = new LogListener(log_buffer);//調用StartListener方法會啟動一個線程并且不斷循環監聽收到的日志數據if (!swl->StartListener()) {return EXIT_FAILURE;}省略其他代碼......
}//文件路徑:/system/logging/logd/LogListener.cpp
//GetLogSocket()方法會把server socket名字為logdw的server獲取到,對socket_進行初始化
LogListener::LogListener(LogBuffer* buf) : socket_(GetLogSocket()), logbuf_(buf) {}//啟動一個線程,調用ThreadFunction方法
bool LogListener::StartListener() {if (socket_ <= 0) {return false;}auto thread = std::thread(&LogListener::ThreadFunction, this);thread.detach();return true;
}//該方法會進入循環,不斷地從socket client端讀取日志信息
void LogListener::ThreadFunction() {prctl(PR_SET_NAME, "logd.writer");while (true) {HandleData();}
}void LogListener::HandleData() {省略代碼......//把從socket client端獲取的日志信息放入logbuf中logbuf_->Log(logId, header->realtime, cred->uid, cred->pid, header->tid, msg,((size_t)n <= UINT16_MAX) ? (uint16_t)n : UINT16_MAX);
}int LogListener::GetLogSocket() {//server socket的名字是logdwstatic const char socketName[] = "logdw";int sock = android_get_control_socket(socketName);省略代碼......return sock;
}
收集協議
既然收集渠道已經“修好了”,那來定下在渠道上傳遞的協議吧,協議格式如下:
//文件路徑:system/logging/liblog/include/android/log.h
struct __android_log_message {/** Must be set to sizeof(__android_log_message) and is used for versioning. */size_t struct_size;//日志類別id/** {@link log_id_t} values. */int32_t buffer_id;//優先級/** {@link android_LogPriority} values. */int32_t priority;//tag 日志對應的tag/** The tag for the log message. */const char* tag;//暫時用不到,可以忽略/** Optional file name, may be set to nullptr. */const char* file;/** Optional line number, ignore if file is nullptr. */uint32_t line;//日志具體信息/** The log message itself. */const char* message;
};
日志分發中心
日志分發中心的作用是把日志隊列中的日志分發給日志消費者,而日志消費者是位于其他進程與logd不是同一進程,因此也需要一個“分發渠道”把日志隊列中的日志分發出去。
分發渠道
與收集渠道類似,分發渠道也使用socket通信,主要原因是:首先日志隊列會對應多個日志消費者,這明顯是C/S模式;其次日志消費者它是非常省心的,只是一味的接收發送過來的日志即可也不需要對收到的日志進行排序等處理,因此需要串行傳遞日志,而socket發送接收數據是串行的。基于以上原因分發渠道選用了socket通信。
收集渠道會啟動一個名字為logdr的server socket,server socket啟動后還會啟動一個單獨的線程,不斷循環監聽與logdr建立連接的client端并且把它保存。日志隊列中的日志就會通過socket通信發送到client端。
對應代碼如下:
//文件路徑:/system/logging/logd/main.cpp
int main(int argc, char* argv[]) {省略其他代碼......// LogReader listens on /dev/socket/logdr. When a client// connects, log entries in the LogBuffer are written to the client.//創建LogReader實例LogReader* reader = new LogReader(log_buffer, &reader_list);//調用startListener方法,會創建一個線程,不斷循環去監聽建立連接的client端if (reader->startListener()) {return EXIT_FAILURE;}省略其他代碼......
}//文件路徑:/system/logging/logd/LogReader.cpp
LogReader::LogReader(LogBuffer* logbuf, LogReaderList* reader_list): SocketListener(getLogSocket(), true), log_buffer_(logbuf), reader_list_(reader_list) {}//獲取server socket
int LogReader::getLogSocket() {//server socket name logdrstatic const char socketName[] = "logdr";int sock = android_get_control_socket(socketName);if (sock < 0) {sock = socket_local_server(socketName, ANDROID_SOCKET_NAMESPACE_RESERVED, SOCK_SEQPACKET);}return sock;
}//若有socket client連接的話,會調用這個方法,進而把client保存
bool LogReader::onDataAvailable(SocketClient* cli) {static bool name_set;省略代碼......return true;
}
總結
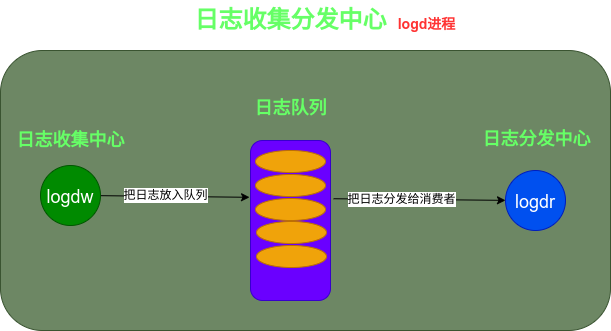
日志隊列、日志收集中心、日志分發中心它們三部分組成了日志收集分發中心。日志隊列對日志進行了分類,同時還為了能夠在有限的內存下存儲更多的日志,設計了具有壓縮功能的日志隊列–SerializedLogBuffer;日志收集中心會啟動一個名為logdw的server socket,用來不斷地監聽日志生產者發送的日志并且會把收到的日志放入日志隊列中;日志分發中心也會啟動一個名為logdr的server socket,用來不斷地監聽建立socket連接的client端,并且會把日志隊列中的日志發送給這些client。
日志生產者
我為了讓日志生產者非常非常容易的生產日志,我把底層的實現細節全部都給隱藏掉,使用者只需要調用簡單的方法就可以生產一條日志,并且把這條日志通過socket發送到logd進程的日志收集中心。比如Java層只需要簡單的調用Log.i(tag,msg)的方法就可以生產一條main類型的日志,systemserver進程的代碼只需要調用Slog.i(tag,msg)方法就以生產一條system類型的日志,native層代碼只需要調用ALOGI(msg)方法就可以生產一條main類型的日志。
像上面的log.i、Slog.i這些方法最終都會調用到__android_log_buf_write(/system/logging/liblog/logger_write.cpp)方法,而像ALOGI等native方法最終會調用到__android_log_print/system/logging/liblog/logger_write.cpp),無論是__android_log_buf_write還是__android_log_print方法殊途同歸最終調用到__android_log_write_log_message(/system/logging/liblog/logger_write.cpp)方法把封裝好的日志信息通過socket(socket與名字為logdw的server建立連接)發送到logd的日志收集中心。
如下代碼:
//文件路徑:/system/logging/liblog/logger_write.cppint __android_log_buf_write(int bufID, int prio, const char* tag, const char* msg) {省略代碼......//構造__android_log_message對象__android_log_message log_message = {sizeof(__android_log_message), bufID, prio, tag, nullptr, 0, msg};//由于代碼量太大,關于__android_log_write_log_message及后續的代碼就不貼出來了__android_log_write_log_message(&log_message);return 1;
}int __android_log_print(int prio, const char* tag, const char* fmt, ...) {ErrnoRestorer errno_restorer;if (!__android_log_is_loggable(prio, tag, ANDROID_LOG_VERBOSE)) {return -EPERM;}va_list ap;__attribute__((uninitialized)) char buf[LOG_BUF_SIZE];va_start(ap, fmt);vsnprintf(buf, LOG_BUF_SIZE, fmt, ap);va_end(ap);//構造__android_log_message對象,日志類別為LOG_ID_MAIN__android_log_message log_message = {sizeof(__android_log_message), LOG_ID_MAIN, prio, tag, nullptr, 0, buf};//由于代碼量太大,關于__android_log_write_log_message及后續的代碼就不貼出來了__android_log_write_log_message(&log_message);return 1;
}日志消費者
最常用的日志消費者就是logcat了,在終端輸入adb logcat命令后,終端上就會顯示出所有的日志,是不是非常的簡單好用啊,其實在執行adb logcat命令后,會創建一個logcat進程,這個進程會與logd進程的日志分發中心的logdr server socket建立連接,從而把傳遞過來日志顯示在終端。
相應代碼如下:
//文件路徑:/system/logging/logcat/logcatd ,在終點輸入 adb logcat命令后會執行logcatd shell腳本文件
#! /system/bin/sh
省略代碼......
//下面代碼會執行logcat.cpp的main方法,同時會把adb logcat攜帶的參數傳遞過去
exec logcat "${ARGS[@]}"//文件路徑:/system/logging/logcat/logcat.cpp
int main(int argc, char** argv) {Logcat logcat;return logcat.Run(argc, argv);
}int Logcat::Run(int argc, char** argv) {省略代碼......//從logd接收日志并顯示while (!max_count_ || print_count_ < max_count_) {struct log_msg log_msg;int ret = android_logger_list_read(logger_list.get(), &log_msg);省略代碼......//若是二進制則走這if (print_binary_) {WriteFully(&log_msg, log_msg.len());} else {//顯示拿到的日志ProcessBuffer(&log_msg);if (blocking && output_file_ == stdout) fflush(stdout);}}return EXIT_SUCCESS;
}總結
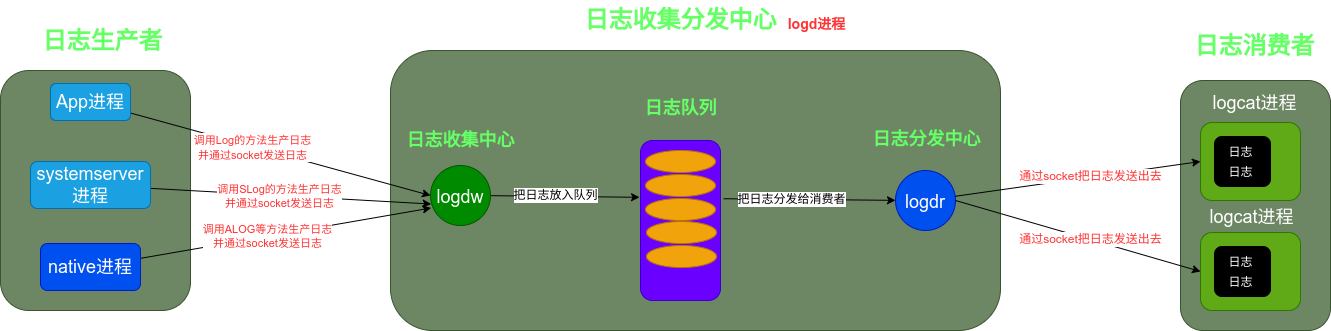
日志收集分發中心、日志生產者、日志消費者三部分組成了日志系統。
日志收集分發中心位于logd進程,logd進程會被init進程創建,日志收集分發中心又可以分為三部分日志收集中心、日志分發中心、日志隊列。日志收集中心會啟動一個名字為logdw的server socket,等待日志生產者建立連接,收到日志后會把它們放入日志隊列中;日志隊列為了在有限的內存下存儲更多了日志,對日志進行了分類,同時也設計了具有壓縮功能的日志隊列SerializedLogBuffer從而可以存儲更多的日志;日志分發中心也會啟動一個名字為logdr的server socket,如果日志消費者(比如logcat)想要消費日志那就需要與之建立socket連接,進而收到日志進行顯示等處理。
日志生產者只需要調用Log、Slog、ALOGI等方法,就可以生產一條日志,并且把這條日志通過socket發送到日志收集中心。
日志消費者比如logcat使用起來也非常方便,只需要在終端輸入adb logcat命令即可把日志顯示在終端,adb logcat命令會創建一個logcat進程,這個進程會與日志分發中心建立socket連接,進而接收日志并且顯示。
好了關于日志系統,關于我logd進程的介紹到此為止,感謝大家的觀看。
歡迎大家關注我的公眾號–牛曉偉
)







:迭代器、拷貝、線程及底層結構)
![[古劍山2023] pwn](http://pic.xiahunao.cn/[古劍山2023] pwn)







)

