開源框架Apache NiFi調研
- NiFi背景介紹
- 一、什么是NiFi
- 1.1 Apache NiFi特點:流管理、易用性、安全性、可擴展的體系結構和靈活的伸縮模型。
- 1.2 Apache NiFi特性
- 1.2 Apache NiFi核心概念
- 1.3架構
- 二、NiFi的誕生,要致力于解決的問題有哪些?
- 三、為什么使用NiFi?
- 常見處理器
NiFi背景介紹
2006年NiFi由美國國家安全局(NSA)的Joe Witt創建。2015年7月20日,Apache 基金會宣布Apache NiFi順利孵化成為Apache的頂級項目之一。NiFi初始的項目名稱是Niagarafiles,當NiFi項目開源之后,一些早先在NSA的開發者們創立了初創公司Onyara,Onyara隨之繼續NiFi項目的開發并提供相關的支持。Hortonworks公司收購了Onyara并將其開發者整合到自己的團隊中,形成HDF(Hortonworks Data Flow)平臺。2018年Cloudera與Hortonworks合并后,新的CDH整合HDF,改名為Cloudera Data Flow(CDF)。Cloudera將NiFi作為其新產品Cloudera Flow Management和Cloudera Edge Management的核心組件推出,可以方便地使用Cloudera Manager進行Parcel安裝和集成,而Apache NiFi就是CFM的核心組件。
一、什么是NiFi
Apache NiFi 是一個易于使用、功能強大而且可靠的數據處理和分發系統,在大數據生態中的定位是成為一個統一的,與數據源無關的大數據集成平臺。Apache NiFi是為數據流設計,它支持高度可配置的指示圖,來指示數據路由、轉換和系統中流轉關系,支持從多種數據源動態拉取數據(Data Lake、DB(Oracle、MySQL)、API等)。簡單地說,NiFi是為自動化系統之間的數據流而生。 這里的數據流表示系統之間的自動化和受管理的信息流。 基于WEB圖形界面,通過拖拽、連接、配置完成基于流程的編程,實現數據采集、處理等功能。未來NiFi有可能替換Flume、Sqoop等大數據導數據的工具。
NiFi官網地址:Apache NiFi:https://nifi.apache.org/
文檔:https://nifi.apache.org/docs.html
Nifi GitHub源碼地址 https://github.com/apache/nifi
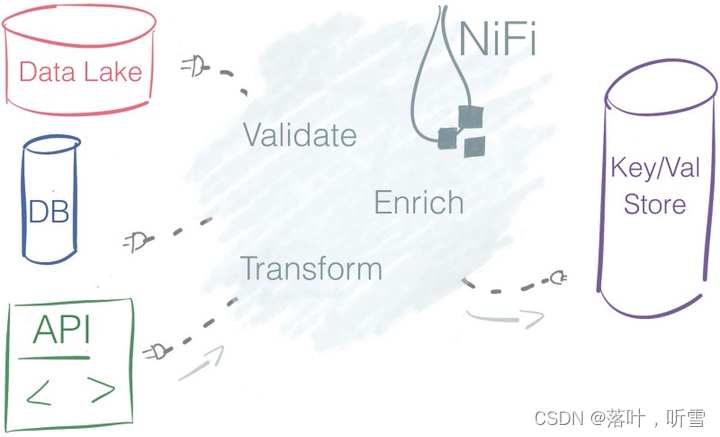
NiFi客戶處理各種各樣的數據源和數據格式。可以由一個數據源中獲取數據,對數據進行計算、轉化,把數據推送到其他的數據源進行存儲。
1.1 Apache NiFi特點:流管理、易用性、安全性、可擴展的體系結構和靈活的伸縮模型。
-
流量管理:
- 保證交付:NiFi的核心理念是,即使規模非常大,也必須保證交付。這是通過有效使用專門構建的持久預寫日志和內容存儲庫來實現的。它們一起被設計成這樣一種方式,允許非常高的事務率、有效的負載分散、寫時復制,并發揮傳統磁盤讀/寫的優勢。
- 帶背壓和壓力釋放的數據緩沖:NiFi支持對所有排隊的數據進行緩沖,并在這些隊列達到指定的限制時提供回壓,或者在數據達到指定的年齡(其值已經消亡)時使其老化。
- 優先隊列:NiFi允許為如何從隊列中檢索數據設置一個或多個優先級方案。默認情況下是最早的先提取,但有時應該先提取最新的數據,先提取最大的數據,或者其他一些自定義方案。
- 特定于流的QoS(延遲v吞吐量,損失容忍度等):在數據流中,有些點的數據是絕對關鍵的,并且是不能容忍損失的,需要實時處理和交付,才能具有任何價值,NiFi支持這些關注點的細粒度流特定配置。
-
易用性別: 多個處理器(Processors)被連接器(Connector)的箭頭鏈接在一起,創建了數據流程。NiFi提供fbp(基于流編程)的體驗。
- 可視化管理:數據流可能變得相當復雜。能夠可視化這些流程并以可視化的方式表達它們可以極大地幫助降低復雜性,并確定需要簡化的區域。NiFi不僅可以可視化地建立數據流,而且可以實時地實現。對數據流進行更改立即生效。
- 流模板:數據流往往是高度面向模式的,模板允許主題專家構建和發布他們的流設計,并讓其他人從中受益和協作。
- 數據源:當對象流經系統時,NiFi自動記錄、索引并提供來源數據,即使是在扇入、扇出、轉換等過程中也是如此。這些信息對于支持遵從性、故障排除、優化和其他場景非常重要。
- 恢復/記錄細粒度歷史的滾動緩沖區:NiFi的內容存儲庫被設計成歷史的滾動緩沖區。數據只有在內容存儲庫老化或需要空間時才會被刪除。這與數據來源功能相結合,形成了一個非常有用的基礎,可以在對象生命周期(甚至可以跨越幾代)的特定點上實現點擊內容、下載內容和重播。
-
安全性:
- 系統到系統:數據流需要安全保障,數據流中的每個點上的NiFi通過使用帶有加密協議(如2-way SSL)提供安全交換。此外,NiFi使流能夠加密和解密內容,并在發送方/接收方等式的任何一方使用共享密鑰或其他機制。
- 系統用戶:NiFi支持雙向SSL身份驗證,并提供可插拔授權,以便在特定級別(只讀、數據流管理器、管理)正確控制用戶的訪問。如果用戶將敏感屬性(如密碼)輸入到流中,它將立即在服務器端加密,并且即使以加密形式也不會再次在客戶端公開。
- 多租戶授權:給定數據流的權限級別應用于每個組件,允許admin用戶擁有細粒度級別的訪問控制。這意味著每個NiFi集群都能夠處理一個或多個組織的需求。與孤立的拓撲相比,多租戶授權支持數據流管理的自助服務模型,允許每個團隊或組織管理流,同時充分了解他們無法訪問的其余流。
-
可擴展體系結構:
- 擴展:NiFi的核心是為擴展而構建的,因此它是一個平臺,數據流進程可以在其上以可預測和可重復的方式執行和交互。擴展點包括:處理器、控制器服務、報告任務、優先級和客戶用戶界面。
- 類加載器隔離:對于任何基于組件的系統,依賴關系問題都可能很快發生。NiFi通過提供自定義類加載器模型來解決這個問題,確保每個擴展包只暴露給非常有限的一組依賴項。
- 點到點通信協議:NiFi實例之間的首選通信協議是NiFi Site-to-Site (S2S)協議。S2S可以輕松地將數據從一個NiFi實例傳輸到另一個NiFi實例,輕松、高效、安全。NiFi客戶端庫可以很容易地構建并捆綁到其他應用程序或設備中,通過S2S與NiFi通信。在S2S中,基于套接字的協議和HTTP(S)協議都被支持作為底層傳輸協議,這使得在S2S通信中嵌入代理服務器成為可能。
-
靈活縮放模型:
- 水平擴展(聚類):NiFi被設計為通過使用如上所述的群集多個節點來向外擴展。如果將單個節點配置為每秒處理數百MB,則可以將普通集群配置為每秒處理GB。
- 擴縮容:NiFi還被設計成以非常靈活的方式擴大和縮小,從NiFi框架的角度來看,在配置時,可以在Scheduling選項卡下增加處理器上并發任務的數量
NiFi是高度并發的,并將并發的復雜性封裝在自己內部。Processor為您提供了高級抽象,它隱藏了并行編程固有的復雜性。 Processor同步運行,可以為它分配多個線程來應對負載。
NiFi通過多種機制全面的跟蹤系統狀態,來實現了高度的可靠性。這些機制是可配置的,可以根據需求在延遲和吞吐量之間進行適當的權衡。
NiFi利用血緣和出處特征來跟蹤每條數據的歷史記錄。這使得NiFi具有追蹤每條數據發生什么轉變的能力。
Apache Nifi提出的數據血緣解決方案被證明是審計數據管道的出色工具。
1.2 Apache NiFi特性
Apache NiFi支持數據路由、轉換和系統中介邏輯的強大且可伸縮的有向圖。
- 基于瀏覽器的用戶界面:設計、控制、反饋和監控的無縫體驗。
- 數據來源跟蹤:完整從開始到結束跟蹤信息。
- 豐富的配置
- 容錯和保證交付
- 低延遲,高吞吐量
- 動態優先級
- 流配置的運行時修改
- 背壓控制
- 可擴展的設計
- 定制處理器和服務的組件體系結構
- 快速開發和迭代測試
- 安全通信
- HTTPS,具有可配置的身份驗證策略
- 多租戶授權和策略管理
- 用于加密通信的標準協議,包括TLS和SSH
1.2 Apache NiFi核心概念
-
FlowFile:表示在系統中移動的每個對象,對于每個對象,NiFi跟蹤鍵/值對屬性字符串的映射及其零或多字節的相關內容。
- 每一塊“用戶數據”(即用戶帶入NiFi進行處理和分發的數據)都被稱為一個FlowFile。
- 一個FlowFile由兩部分組成:屬性和內容。內容就是用戶數據本身。屬性是與用戶數據相關聯的鍵值對
-
FlowFile Processor:處理器實際執行工作,處理器是在系統之間進行數據路由、轉換或中介的某種組合。處理器可以訪問給定的FlowFile及其內容流的屬性。處理器可以在給定的工作單元中操作零個或多個flowfile,并提交該工作或回滾。
- 處理器是NiFi組件,負責創建、發送、接收、轉換、路由、拆分、合并和處理流文件。它是NiFi用戶用于構建數據流的最重要的構建塊。
-
Connection:連接提供處理器之間的實際鏈接。充當隊列,允許各種進程以不同的速率進行交互。這些隊列可以動態地劃分優先級,并且可以設置負載上限,從而啟用背壓。
Flow Controller:流控制器維護進程如何連接,并管理所有進程使用的線程及其分配。流控制器充當了促進處理器之間流文件交換的代理。 -
Process Group:進程組是一組特定的進程及其連接,這些進程可以通過輸入端口接收數據,通過輸出端口發送數據。通過這種方式,流程組允許通過簡單地組合其他組件來創建全新的組件。
這種設計模型幫助NiFi成為構建強大且可伸縮的數據流的非常有效的平臺,其好處如下:
- 很好地用于處理器有向圖的可視化創建和管理。
- 本質上是異步的,允許非常高的吞吐量和自然緩沖,即使處理和流速率波動。
- 提供了一個高度并發的模型,開發人員不必擔心并發性的典型復雜性。
- 促進內聚和松散耦合組件的開發,這些組件可以在其他上下文中重用,并促進可測試單元的開發。
- 資源受限的連接使得諸如回壓和壓力釋放等關鍵功能非常自然和直觀。
- 錯誤處理變得像快樂之路一樣自然,而不是粗粒度的一刀切。
- 數據進入和退出系統的點以及它如何流經系統都很容易理解和跟蹤。
1.3架構
NiFi的設計目的是充分利用它所運行的底層主機系統的功能,對IO、CPU、RAM高效使用,這種資源最大化在CPU和磁盤方面表現得尤為突出,詳細信息在管理指南中的最佳實踐和配置技巧中。
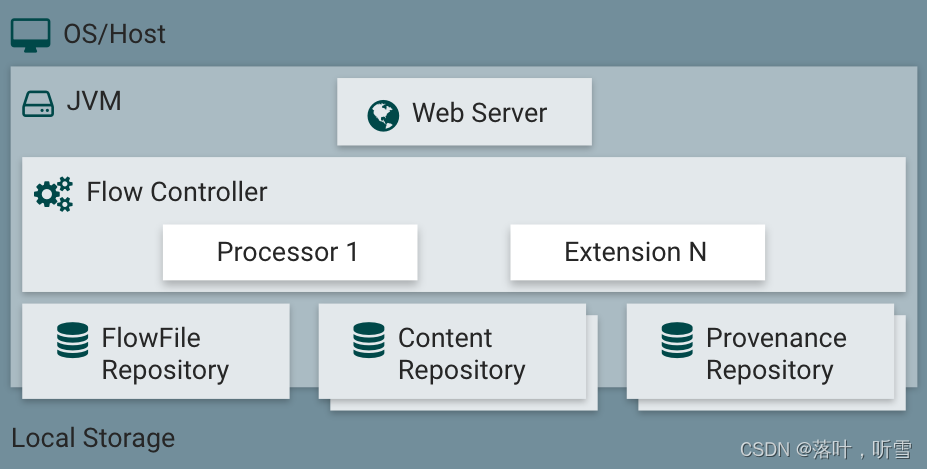
NiFi在主機操作系統上的JVM中執行,JVM上NiFi的主要組件如下:
- Web Server:web服務器的目的是承載NiFi基于http的命令和控制API。
- Flow Controller:流量控制器是操作的大腦,它為要運行的擴展提供線程,并管理擴展何時接收要執行的資源的調度。
- Extensions:各種類型的NiFi擴展,這里的關鍵點是擴展在JVM中操作和執行。
- FlowFile Repository:流文件存儲庫是NiFi跟蹤當前流中活動的給定流文件狀態的地方。存儲庫的實現是可插入的。默認方法是位于指定磁盤分區上的持久預寫日志。
- Content Repository:內容存儲庫是一個給定的FlowFile的實際內容字節所在的地方。存儲庫的實現是可插入的。默認的方法是一種相當簡單的機制,即在文件系統中存儲數據塊。可以指定多個文件系統存儲位置,以便使用不同的物理分區,以減少任何單個卷上的爭用。
- Provenance Repository:源頭存儲庫是存儲所有源頭事件數據的地方。存儲庫結構是可插入的,默認實現是使用一個或多個物理磁盤卷。在每個位置中,事件數據都被索引并可搜索。
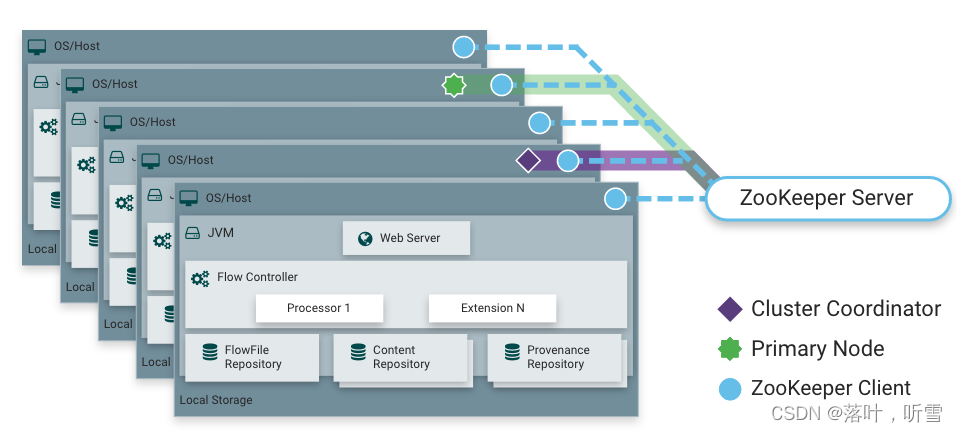
NiFi也能夠在集群中運行,NiFi 采用了零領導者集群,NiFi集群中的每個節點在數據上執行相同的任務,但每個節點操作不同的數據集。Apache ZooKeeper選擇一個節點作為Cluster Coordinator,故障轉移由ZooKeeper自動處理。所有集群節點都向集群協調器報告心跳和狀態信息。集群協調器負責斷開和連接節點。此外,每個集群都有一個主節點,也由ZooKeeper選舉產生。作為DataFlow管理器,可通過任何節點的用戶界面(UI)與NiFi集群交互,操作更改復制到集群中的所有節點,允許多個入口點。
二、NiFi的誕生,要致力于解決的問題有哪些?
- 因為網絡故障、磁盤故障、軟件崩潰、人為犯錯導致的系統錯誤
- 數據讀寫超出了自身系統的處理能力,有時,給定數據源的速度可能超過處理或交付鏈的某些部分,而只需要某一個環節出現問題,整個流程都會受到影響。
- 獲取的數據不具有規范性(即:超出邊界問題:總是會得到太大、太小、太快、太慢、損壞、錯誤或格式錯誤的數據。)
- 數據結構的優先級變化很快,啟用新流和更改現有流的速度必須非常快(現實業務或需求變化快:設計新的數據處理流程或者修改已有的數據處理流程必須要夠敏捷。)
- 數據結構化管理的可移植性與不同數據格式之間的依賴性
- 難以在測試環境模擬生產環境數據。
三、為什么使用NiFi?
- 大量 — 包括采集、存儲和計算的量都非常大。大數據的計量單位由TB、PB(1000)個T、EB(100萬個T)、ZB(10億個T)不斷發展。
- 多樣性 — 種類和來源多樣化。包括結構化、半結構化和非結構化數據,具體表現為網絡日志、音頻、視頻、圖片、地理位置信息等等,多類型的數據對數據的處理能力提出了更高的要求
- 高速 — 數據增長速度快,處理速度也快,時效性要求高
- 準確性 — 數據的準確性和可信賴度,即數據的質量
NiFi無縫地從多個數據源提取數據,并提供了處理不同模式數據的機制。 因此,當數據的“多樣性”較高時,它會發揮價值。并且NiFi提供了多個Processor來清理和格式化數據。
- 微服務很新潮。在那些松散耦合的服務中,服務之間的數據就是契約。 Nifi是在這些服務之間路由數據的可靠方法。
- 萬物互聯的時代,物聯網將大量數據帶到云中。從邊緣到云的數據攝取和驗證帶來了許多新挑戰,NiFi可以有效應對這些挑戰(主要通過[MiniFi],這是針對邊緣設備的NiFi子項目)。
- 制定了新的準則和法規促使大數據經濟重新調整。在日益增加的監控范圍內,對于企業來說,對其數據管道有清晰的總覽非常重要。例如,NiFi數據血緣可能有助于遵守法規。
簡單來說,NiFi是用來處理數據集成場景的數據分發。NiFi是基于Java的,使用Maven支持包的構建管理。 NiFi基于Web方式工作,后臺在服務器上進行調度。用戶可以為數據處理定義為一個流程,然后進行處理,后臺具有數據處理引擎、任務調度等組件。
常見處理器
想到創建數據流必須了解可供使用的處理器類型,NiFi包含許多開箱即用的不同處理器,這些處理器提供了從許多不同系統攝取數據、路由、轉換、處理、分割和聚合數據以及將數據分發到許多系統的功能。幾乎在每一個NiFi發行版中,可用的處理器數量都會增加。因此將不嘗試為每個可用的處理器命名,下面重點介紹一些最常用的處理器,并根據它們的功能對它們進行分類。
-
數據轉換
- CompressContent:壓縮或解壓縮內容。
- ConvertCharacterSet:將用于對內容進行編碼的字符集轉換為另一個字符集。
- EncryptContent:加密或解密內容。
- ReplaceText:使用正則表達式修改文本內容。
- TransformXml:對XML內容應用XSLT轉換。
- JoltTransformJSON:應用JOLT規范轉換JSON內容
-
路由和中介
- ControlRate:限制數據通過流的一部分的速率。
- DetectDuplicate:基于一些用戶定義的標準,監控重復的flowfile。通常與HashContent一起使用。
- DistributeLoad:通過僅將一部分數據分發到每個用戶定義的關系來實現負載平衡或示例數據。
- MonitorActivity:當用戶定義的一段時間過去了,沒有任何數據通過流中的特定點時,發送一個通知。可以選擇在數據流恢復時發送通知。
- RouteOnAttribute:基于屬性th的路由流文件。
- ScanAttribute:掃描FlowFile上的用戶定義屬性集,檢查是否有任何屬性與用戶定義字典中的術語匹配。
- RouteOnContent:搜索FlowFile的內容,看它是否匹配任何用戶定義的正則表達式。如果是,則將FlowFile路由到配置的Relationship。
- ScanContent:根據用戶定義的字典和路由中存在或不存在的術語搜索FlowFile的內容。字典可以由文本項或二進制項組成。
- ValidateXml:根據XML模式驗證XML內容;根據用戶定義的XML模式,根據FlowFile的內容是否有效來路由FlowFile。
-
數據庫訪問
- ConvertJSONToSQL:將JSON文檔轉換為SQL INSERT或UPDATE命令,然后傳遞給PutSQL處理器。
- ExecuteSQL:執行用戶定義的SQL SELECT命令,將結果以Avro格式寫入FlowFile。
- PutSQL:通過執行由FlowFile內容定義的SQL DDM語句來更新數據庫。
- SelectHiveQL:對Apache Hive數據庫執行用戶自定義的HiveQL SELECT命令,將結果以Avro或CSV格式寫入FlowFile。
- PutHiveQL:通過執行由FlowFile的內容定義的HiveQL DDM語句來更新Hive數據庫。
-
屬性提取
- EvaluateJsonPath:用戶提供JSONPath表達式(類似于XPath,用于XML解析/提取),然后根據JSON內容計算這些表達式,以替換FlowFile內容或將值提取到用戶命名的屬性中。
- EvaluateXPath:用戶提供XPath表達式,然后根據XML內容計算這些表達式,以替換FlowFile內容或將值提取到用戶命名的屬性中。
- EvaluateXQuery:用戶提供一個XQuery查詢,然后根據XML內容計算該查詢,以替換FlowFile內容或將值提取到用戶命名的屬性中。
- ExtractText:用戶提供一個或多個正則表達式,然后根據FlowFile的文本內容計算正則表達式,然后將提取的值作為用戶命名的屬性添加。
-
系統交互
- ExecuteProcess:執行用戶自定義的操作系統命令。流程的StdOut被重定向,這樣寫入StdOut的內容就變成了出站FlowFile的內容。這個處理器是一個源處理器——它的輸出預計會生成一個新的FlowFile,而系統調用預計不會接收任何輸入。為了向流程提供輸入,請使用ExecuteStreamCommand處理器。
- ExecuteStreamCommand:執行用戶自定義的操作系統命令。FlowFile的內容可選地流到進程的StdIn中。寫入StdOut的內容成為出站FlowFile的內容。
-
數據攝取
- GetFile:將本地磁盤(或網絡連接磁盤)中的文件內容流到NiFi中,然后刪除原始文件。此處理器預計將文件從一個位置移動到另一個位置,而不是用于復制數據。
- GetFTP:通過FTP將遠程文件的內容下載到NiFi,然后刪除原始文件。此處理器預計將數據從一個位置移動到另一個位置,而不是用于復制數據。
- GetHDFS:監控HDFS中用戶指定的目錄。每當有新文件進入HDFS時,它就會被復制到NiFi中,然后從HDFS中刪除。此處理器預計將文件從一個位置移動到另一個位置,而不是用于復制數據。如果在集群中運行,這個處理器也只能在主節點上運行。為了從HDFS復制數據并保留數據,或者從集群中的多個節點傳輸數據,請參閱ListHDFS處理器。
- GetKafka:從Apache Kafka中獲取消息,特別是對于0.8。x版本。消息可以作為每條消息的FlowFile發出,也可以使用用戶指定的分隔符將消息批處理在一起。
- GetMongo:對MongoDB執行用戶指定的查詢,并將內容寫入新的FlowFile。
-
數據發送
- PutFile:將FlowFile的內容寫入本地(或網絡連接)文件系統上的目錄。
- PutFTP:將FlowFile的內容復制到遠程FTP服務器。
- PutKafka:將FlowFile的內容作為消息發送給Apache Kafka,特別是0.8。x版本。FlowFile可以作為單個消息或分隔符發送,例如可以指定一個新行,以便為單個FlowFile發送多個消息。
- PutMongo:將FlowFile的內容作為INSERT或UPDATE發送到Mongo。
-
拆分和聚合
- SplitText:SplitText接收一個包含文本內容的FlowFile,并根據配置的行數將其拆分為1個或多個FlowFile。例如,處理器可以被配置為將一個FlowFile分割成許多個FlowFile,每個FlowFile只有1行。
- SplitJson:允許用戶將一個由數組或許多子對象組成的JSON對象拆分為每個JSON元素的FlowFile。
- MergeContent:這個處理器負責將多個FlowFile合并為一個FlowFile。可以通過將它們的內容連同可選的頁眉、頁腳和分界符連接在一起,或者通過指定歸檔格式(如ZIP或TAR)來合并flowfile。
NIFI介紹、安裝、實踐案例:
可參考:https://juejin.cn/post/7002031938328346654
NiFi分布式安裝:
可參考:https://cloud.tencent.com/developer/article/2206586
Jenkins項目配置-maven項目-全面
可參考:https://blog.csdn.net/xiaona0523/article/details/124271773
Maven多模塊使用及jenkins構建
可參考:https://blog.csdn.net/sinat_34974437/article/details/119926268
徹底理解maven + 配置私服 + 阿里云鏡像
可參考:https://blog.csdn.net/sjsh_csdn/article/details/119562070
NIFI監控及界面常見菜單說明:
可參考:https://cloud.tencent.com/developer/article/2209640
可視化編排的數據集成和分發開源框架Nifi輕松入門-上
可參考:https://blog.csdn.net/qq_20949471/article/details/128309679?spm=1001.2014.3001.5502
Apache NiFi vs 其他技術比較
參考:https://zhuanlan.zhihu.com/p/328060780
xsync同步腳本的使用:
參考:https://blog.csdn.net/nalw2012/article/details/98322637#%E7%AE%80%E4%BB%8B
Linux部署nifi
可參考:https://blog.csdn.net/weixin_53134351/article/details/132095066
zookeeper集群搭建(詳細步驟)
參考:https://blog.csdn.net/weixin_50642075/article/details/109613621
Hadoop安裝教程 Linux版
可參考:https://blog.csdn.net/qq_42855570/article/details/115180674
Linux安裝Hadoop超詳細教程
參考:https://blog.csdn.net/sinat_40875078/article/details/104099169
虛擬機(VMware)相關:
安裝VMware教程
參考:https://zhuanlan.zhihu.com/p/609472766
在VMware中安裝CentOS7(超詳細的圖文教程)
參考:https://blog.csdn.net/qq_45743985/article/details/121152504
VMware虛擬機安裝(非常詳細)從零基礎入門到精通,看完這一篇就夠了
參考:https://blog.csdn.net/leah126/article/details/131450225
【VMware虛擬機】Linux設置固定IP
參考:https://blog.csdn.net/Tiezhu_Wang/article/details/113822362
【linux】linux系統配置靜態IP地址(超詳細,手把手教會)
參考:https://blog.csdn.net/u010521062/article/details/114067036












)



)


