深度學習自然語言處理 原創
作者:yy

很多年前,你一定在互聯網上看過這張圖,展示了人腦能夠閱讀和理解打亂順序的單詞和句子!而最近東京大學的研究發現,大語言模型(LLMs) 尤其是 GPT-4,也可以讀懂打亂順序的單詞,甚至是在人腦都難以分辨的情況下!
接下來就讓我們來具體介紹一下這個違反直覺的發現吧!
論文:Unnatural Error Correction: GPT-4 Can Almost Perfectly Handle Unnatural Scrambled Text
地址:https://arxiv.org/pdf/2311.18805.pdf
代碼:https://github.com/ccqq77/unnatural-error-correction.
前言
“Typoglycemia” 這個詞曾在互聯網上風靡一時,它是由“打字錯誤(Typo)”和“低血糖(Hypoglycemia)” 這兩個單詞拼湊而成。通俗地講,”Typoglycemia“ 指一個有趣的現象:只要每個單詞的首尾字母正確,即使中間的字母順序是完全打亂的,也不影響人類的正常閱讀與理解。
而這篇研究發現,大多數強大的 LLMs 都具備類似于 “typoglycemia” 的超能力。更令人驚訝的是,作者發現,即使每個單詞中的所有字母都是亂序, 仍有且并僅有 GPT-4 能近乎完美地從亂序中恢復原始句子,將編輯距離減少 95%!盡管亂碼文本對輸入 tokenization 造成了嚴重破壞,但 LLMs 仍能表現出如此強大的恢復能力!
任務設計
為了評估 LLMs 處理亂序文本的能力,作者提出了 Scrambled Bench ,包含兩個任務(如圖所示)。

1. 亂序句子恢復(ScrRec)
提供包含亂序詞的句子,要求LLMs恢復出原始句子。這項任務可以直接評估 LLMs 識別和重建句子中亂序詞的能力。
2. 亂序問題解答(ScrQA)
如果模型在 ScrRec 任務中表現不佳,可能有兩個原因:
(1) 模型難以遵循指令;
(2) 模型無法恢復句子。
為了區分這兩種情況,作者設計了 ScrQA 任務來評估模型在亂序語境下完成標準任務(即 QA )的能力。具體而言,作者將包含了回答問題所需基本信息的文本打亂,并根據模型表現的差異對其進行評估。
數據集構建
RealtimeQA(2022年)
RealtimeQA 是一個動態的問題解答數據集,每周都會公布有關近期新聞的問題。為了緩解數據污染,作者從 RealtimeQA 中收集最近的數據(2023/03/17-2023/08/04),并對證據句進行加擾處理,以構建 ScrRec 和 ScrQA 任務的樣本。
DREAM(2019年)
DREAM 是一個基于對話的多選閱讀理解數據集。作者對每個問題的對話部分進行了加擾處理。
AQuARAT(2017年)
AQuA-RAT 是一個數學單詞問題數據集,需要多步推理才能解決。作者采用了 few-shot Chain of Thought(CoT),并對主問題和示例問題都加入擾動。
對于每個數據集,作者使用不同的擾動類型和比例生成擾動文本。
1. 隨機擾動(RS)
對于每個句子,隨機選擇一定比例(20%、50%、100%)的單詞,并隨機擾亂每個選定單詞中的所有字母(阿拉伯數字保持不變)。
2. 保留第一個字母(KF)
保持每個單詞的第一個字母不變,并隨機擾亂其他位置的字母。
3. 保留首尾字母(KFL)
保持每個單詞的第一個和最后一個字母不變,并隨機擾亂其他位置的字母。
評價指標
Recovery Rate (RR)
對于 ScrRec 任務,原始句子與恢復句子之間的平均編輯距離(ED)是一種自然的性能度量指標。
此外,作者還定義了 Recovery Rate(RR)來衡量 ED 在恢復的句子中所占的比例,從而可以更簡明地比較不同設置下模型的性能:
Relative Performance Gain (RPG)
對于 ScrQA 而言,accuracy 是衡量性能的一個自然指標。但是由于不同模型在處理原始問題時的能力存在差異,很難比較不同模型的性能。
因此,作者引入了 Relative Performance Gain(RPG),將評估重點放在與原始文本相比,模型理解擾動文本的能力上:
實驗設置
作者評估了最強大的閉源 LLM,包括 text-davinci-003、GPT-3.5-turbo 和 GPT-4,以及 Falcon 系列、Llama-2 系列、MPT 系列、UL2 系列、T5 系列等開源模型。對于各數據集和任務,采取了以下設置:
RealtimeQA
ScrRec:zero-shot + few-shot
ScrQA:zero-shot
DREAM
ScrQA :zero-shot
AQuA
ScrQA :few-shot COT
結果分析
由于篇幅等原因,僅展示性能最好的五種 LLM(即 GPT4、GPT-3.5-turbo、text-davinci-003、Falcon-180b 和 Llama-2-70b)的結果。
結果 1:擾動類型
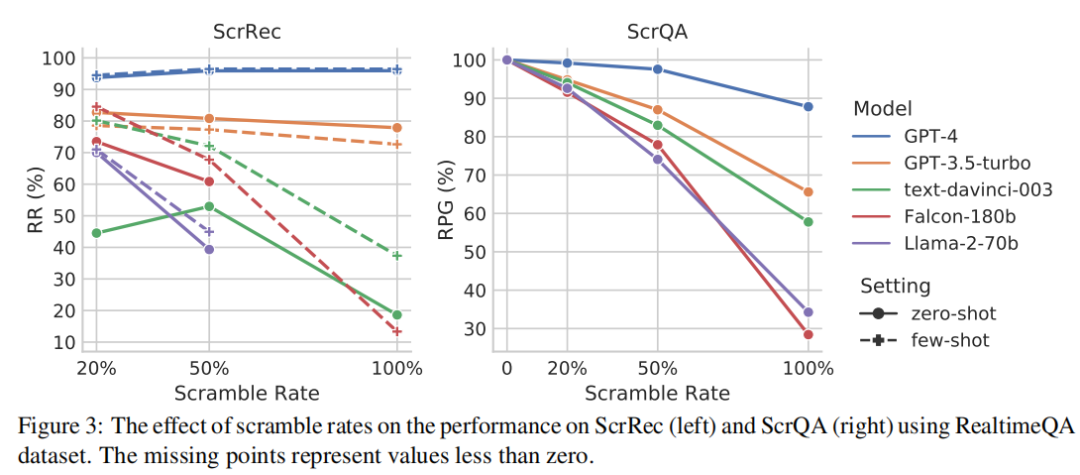
實驗結果表明,在 KFL 設置下,各模型之間的性能差距不大。然而,除 GPT-4 外,隨著擾動類型難度的增加(KFL ? KF ? RS),模型性能明顯下降。相比之下,GPT-4 的性能始終保持在較高水平,而與擾動類型無關。在 ScrRec 任務上,GPT-4 的 RR 在所有設置下都保持在 95% 以上。在 ScrQA 任務上,GPT-4 的表現一直優于其他模型,即使擾動的難度增加,也能保持較高的準確率。

結果 2:擾動比例
隨著擾動比例的增加,text-davinci-003、Falcon-180b 和 Llama-2-70b 的 RR 會降低。GPT-3.5-turbo 和 GPT-4 的 RR 變化不大。GPT-4 的表現遠遠優于其他模型,大多數設置下的 RR 都高于 95%(20% 擾動率除外)。
所有模型的 RPG 都隨著擾動比例的增加而下降。但 GPT-4 即使在 100%加擾證據的情況下,仍能保持 87.8% 的原有性能。隨著擾動比例的增加,不同模型之間的性能差距也越來越大。
結果 3:其他數據集
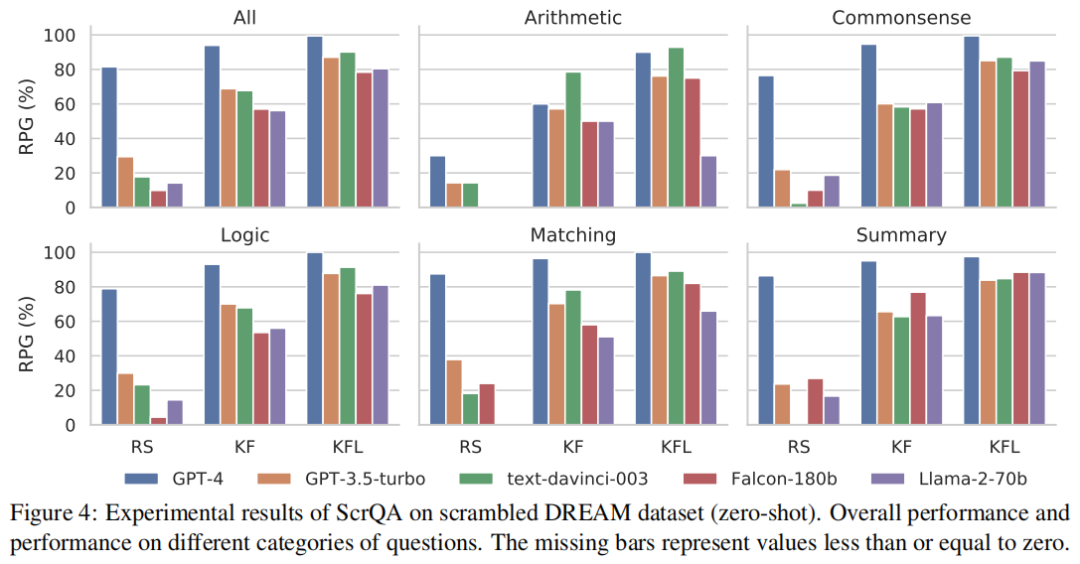
在加擾的 DREAM 數據集上,除了評估整體性能,作者還評估了不同類別問題的性能。結果顯示,GPT-4 與其他模型間的差異比在 RealtimeQA 上更加突出,這可能由于 DREAM 需要對較長文本進行深層次理解。與其他類別相比,模型在算術問題上的表現往往更容易受到亂序文本的影響,即使是 GPT-4 也是如此。
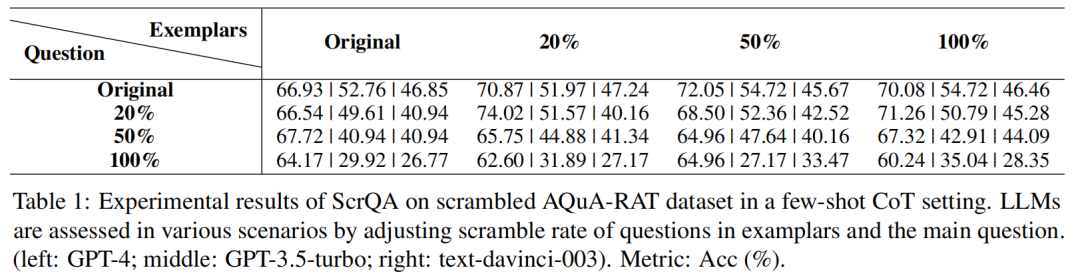
下表展示了在加擾的 AQuA-RAT 數據集上進行 4-shot CoT 設置的實驗結果。結果表明,加擾示例的影響相對較小。但當主問題的加擾率達到 100%時,GPT-3.5-turbo 和 text-davinci-003 的性能明顯下降,而 GPT-4 基本保持了最初的性能。
結論
本研究提出了 Scrambled Bench 來衡量 LLMs 處理亂序文本的能力,包括兩個任務(亂序句子恢復 ScrRec 和亂序問題解答 ScrQA),并基于 RealtimeQA、DREAM 和 AQuA-RAT 構建了亂序數據集。盡管亂序文本顯著改變了 tokenization,大多數強大的 LLMs 仍能在不同程度上處理亂序文本,不過它們在面對極端亂序的文本時會顯得力不從心。在這兩項任務中,GPT-4 都表現出了良好的性能,顯著優于其他模型。
未來的改進空間也很大。首先,對于 LLMs,還有多種方法可以破壞單詞的 tokenization(如插入字母、替換字母等)。其次,ScrRec 和 ScrQA 這兩項任務適用于多種數據集且易于擴展分析。最后,由于無法直接訪問閉源模型,作者沒有總結出 LLMs 能夠處理這些任務的具體原因。特別地,GPT-4 可以近乎完美地完成任務,其背后的原因值得深究!
備注:昵稱-學校/公司-方向/會議(eg.ACL),進入技術/投稿群

id:DLNLPer,記得備注呦











:RBAC 權限管理設計)






)
