點擊@計算機視覺,關注更多CV干貨
論文已打包,點擊進入—>下載界面
點擊加入—>CV計算機視覺交流群
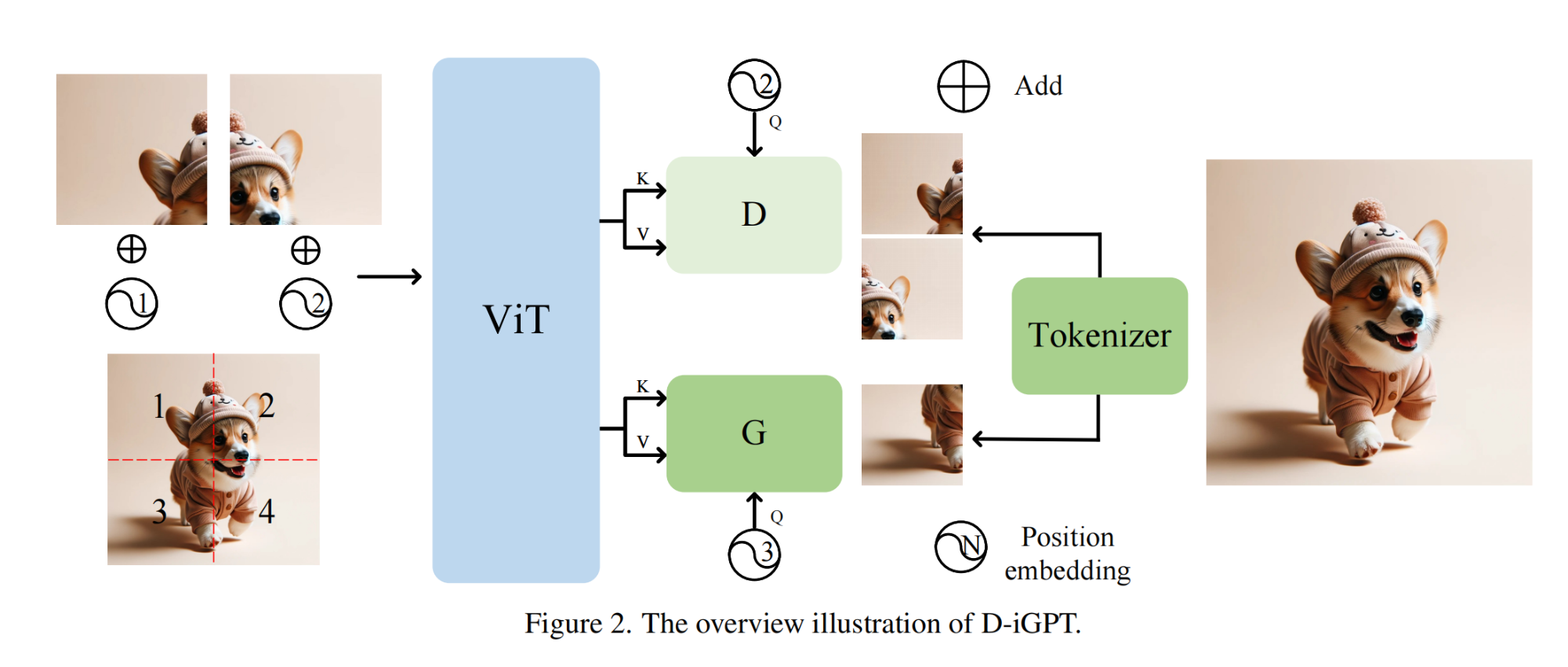
1.【基礎網絡架構:Transformer】Rejuvenating image-GPT as Strong Visual Representation Learners
-
論文地址:https://arxiv.org//pdf/2312.02147
-
開源代碼:https://github.com/OliverRensu/D-iGPT
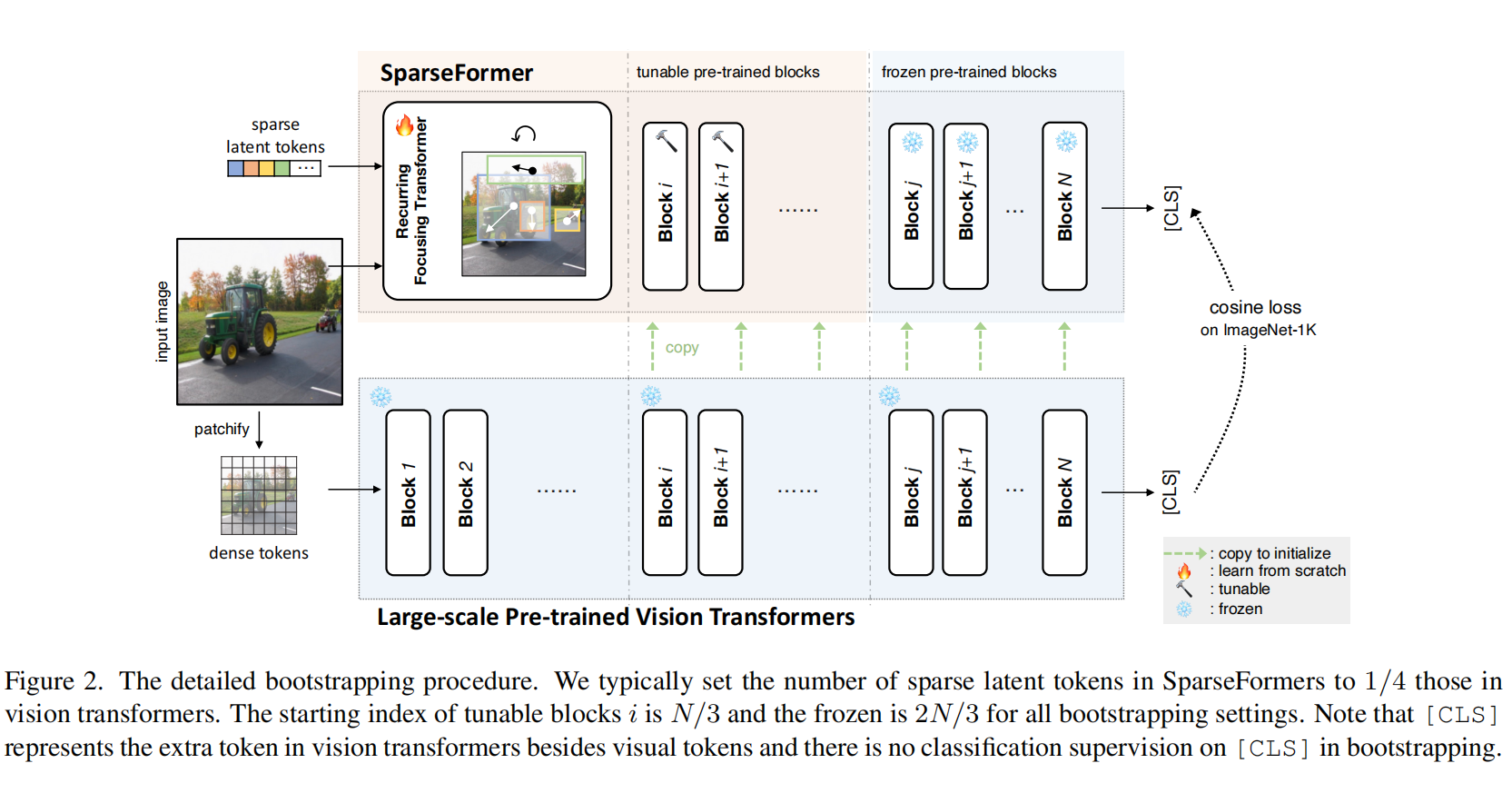
2.【基礎網絡架構:Transformer】Bootstrapping SparseFormers from Vision Foundation Models
-
論文地址:https://arxiv.org//pdf/2312.01987
-
開源代碼:https://github.com/showlab/sparseformer
3.【異常檢測】Unsupervised Anomaly Detection using Aggregated Normative Diffusion
-
論文地址:https://arxiv.org//pdf/2312.01904
-
開源代碼:https://github.com/alexanderfrotscher/ANDi

4.【視頻異常檢測】Dynamic Erasing Network Based on Multi-Scale Temporal Features for Weakly Supervised Video Anomaly Detection
-
論文地址:https://arxiv.org//pdf/2312.01764
-
開源代碼(即將開源):https://github.com/ArielZc/DE-Net

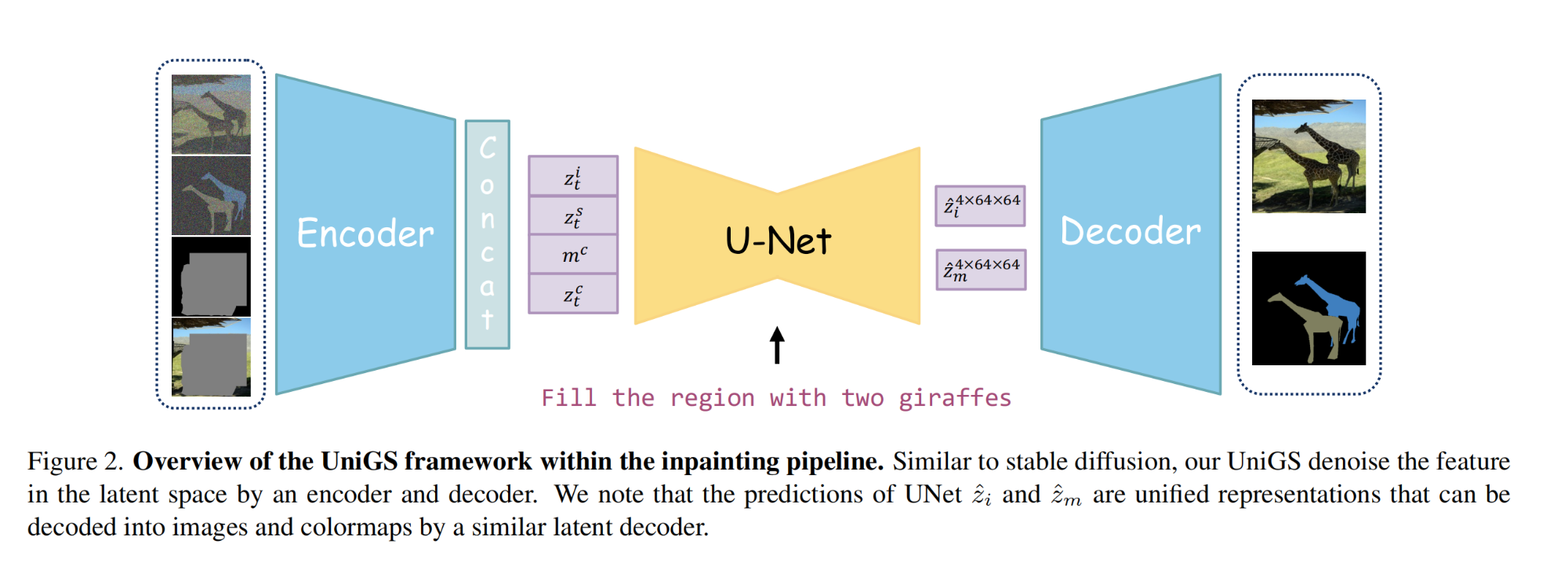
5.【圖像分割】UniGS: Unified Representation for Image Generation and Segmentation
-
論文地址:https://arxiv.org//pdf/2312.01985
-
開源代碼(即將開源):https://github.com/qqlu/Entity
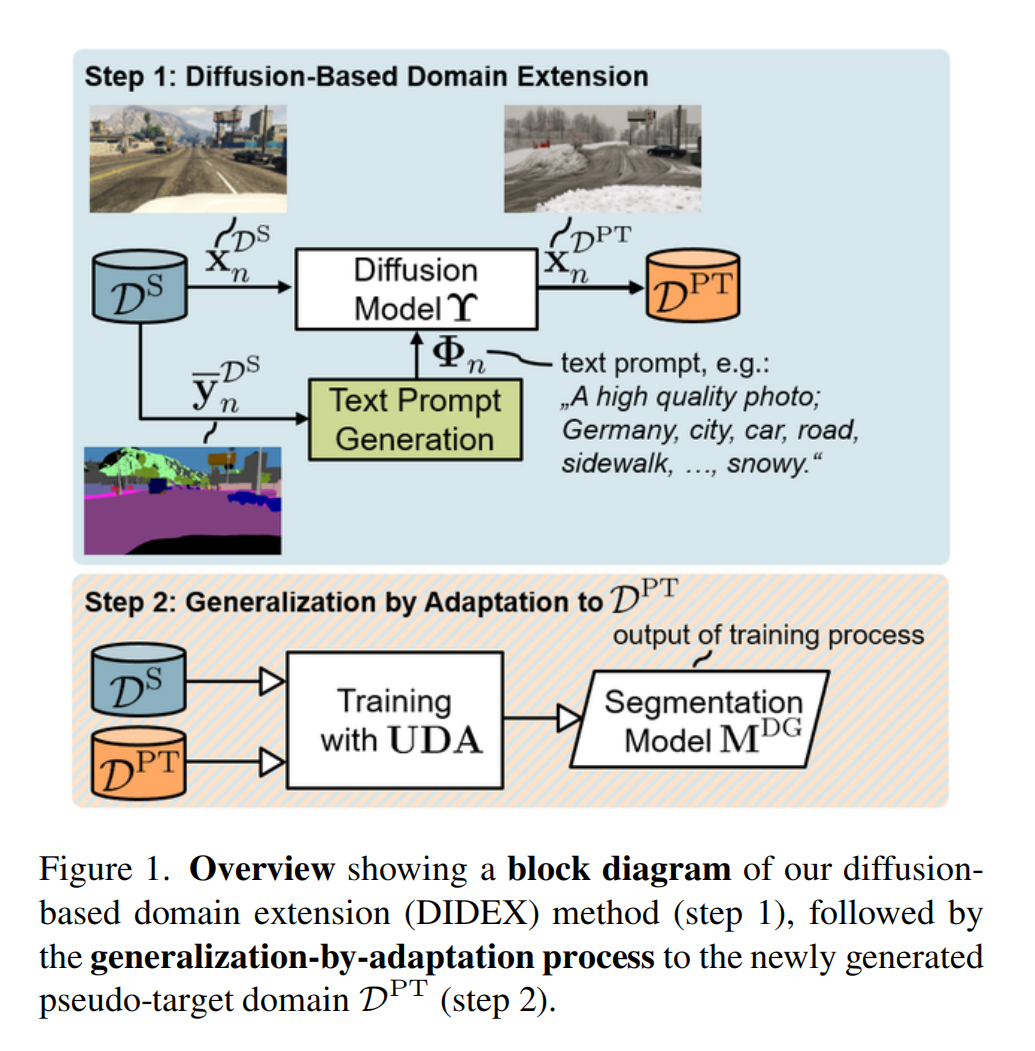
6.【語義分割】Generalization by Adaptation: Diffusion-Based Domain Extension for Domain-Generalized Semantic Segmentation
-
論文地址:https://arxiv.org//pdf/2312.01850
-
開源代碼(即將開源):https://github.com/JNiemeijer/DIDEX
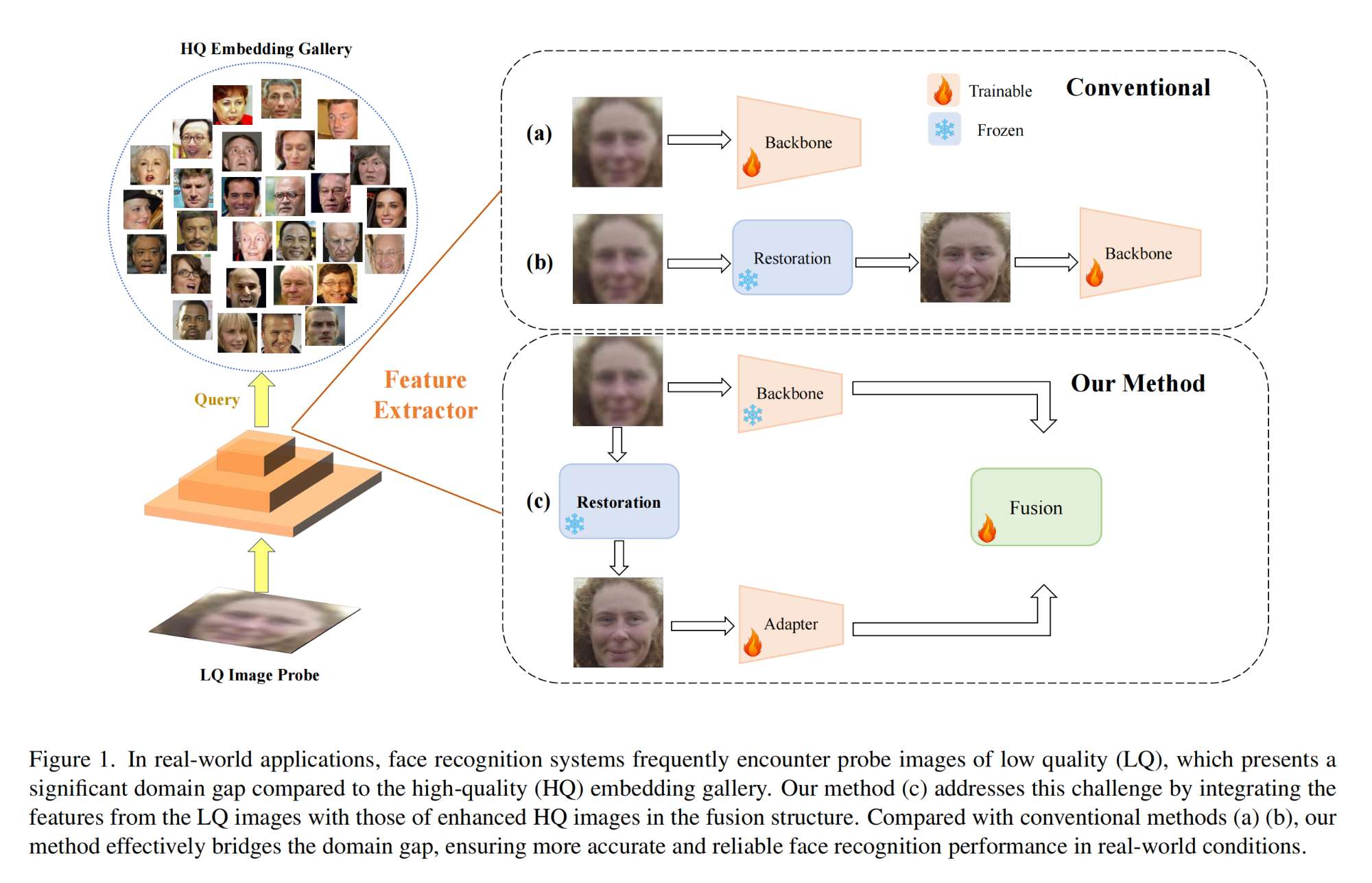
7.【人臉識別】Effective Adapter for Face Recognition in the Wild
-
論文地址:https://arxiv.org//pdf/2312.01734
-
工程主頁:Effective Adapter for Face Recognition in the Wild
-
開源代碼(即將開源):https://github.com/liuyunhaozz/faceadapter/
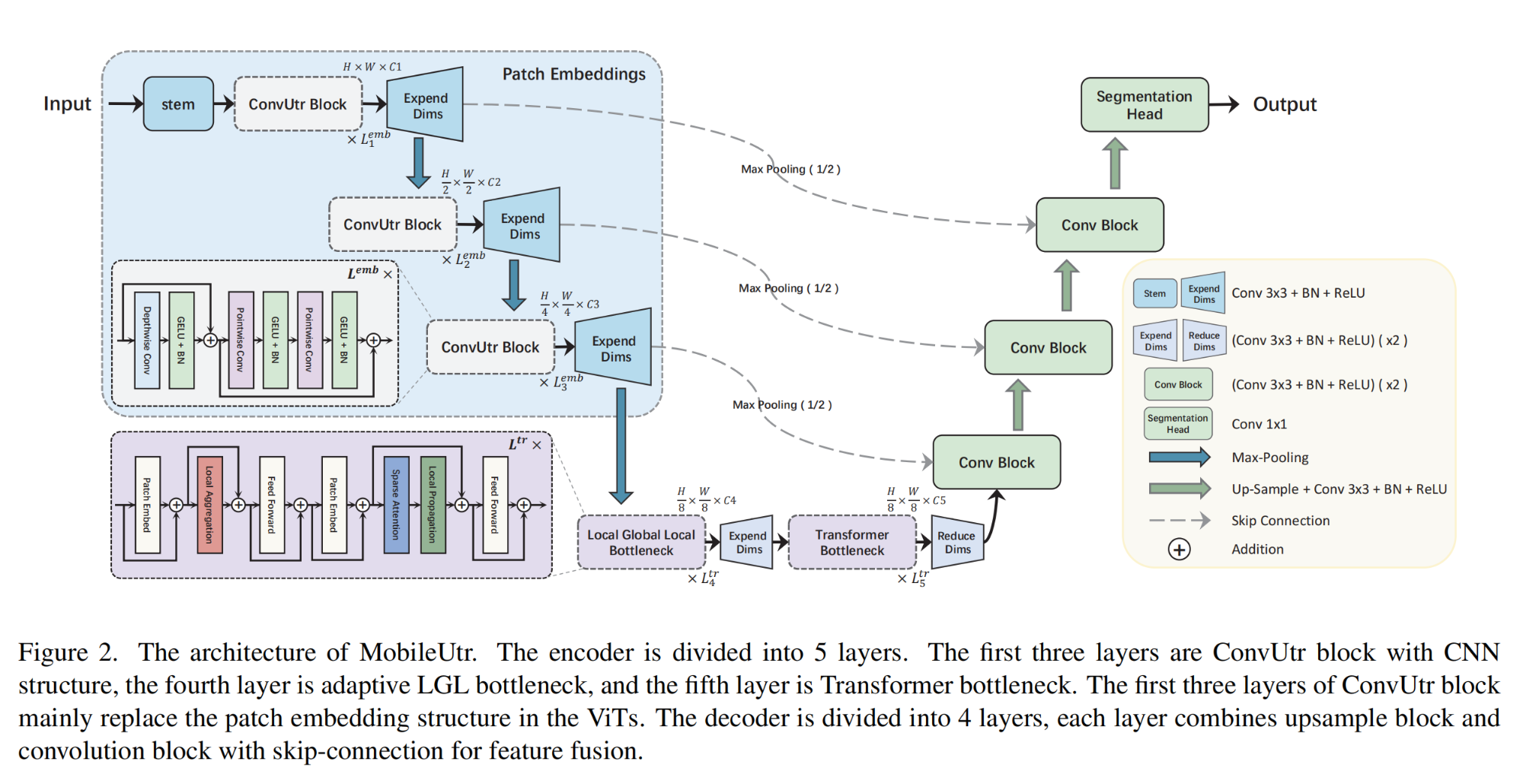
8.【醫學圖像分割】MobileUtr: Revisiting the relationship between light-weight CNN and Transformer for efficient medical image segmentation
-
論文地址:https://arxiv.org//pdf/2312.01740
-
開源代碼(即將開源):https://github.com/FengheTan9/MobileUtr
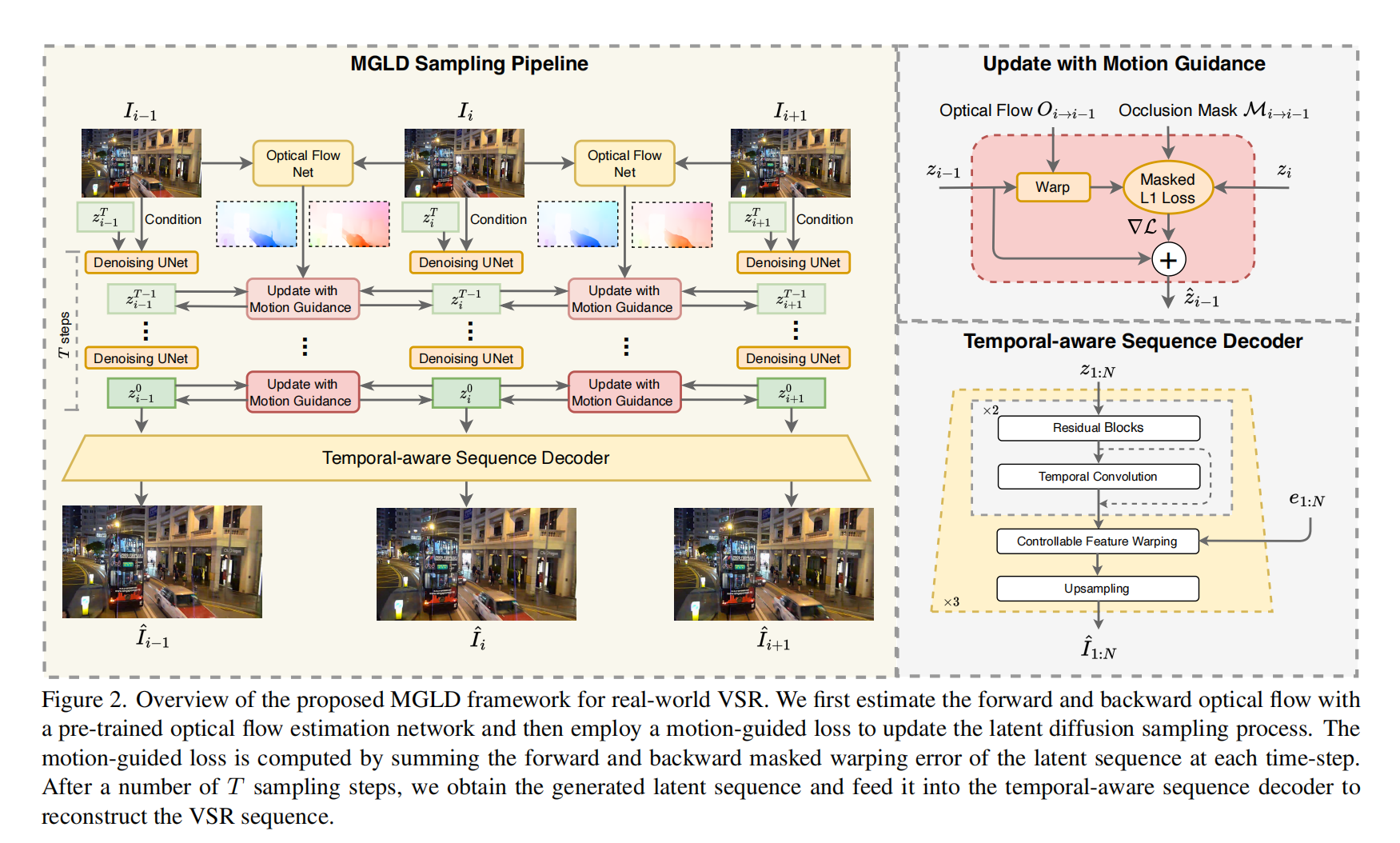
9.【視頻超分辨率重建】Motion-Guided Latent Diffusion for Temporally Consistent Real-world Video Super-resolution
-
論文地址:https://arxiv.org//pdf/2312.00853
-
開源代碼(即將開源):https://github.com/IanYeung/MGLD-VSR
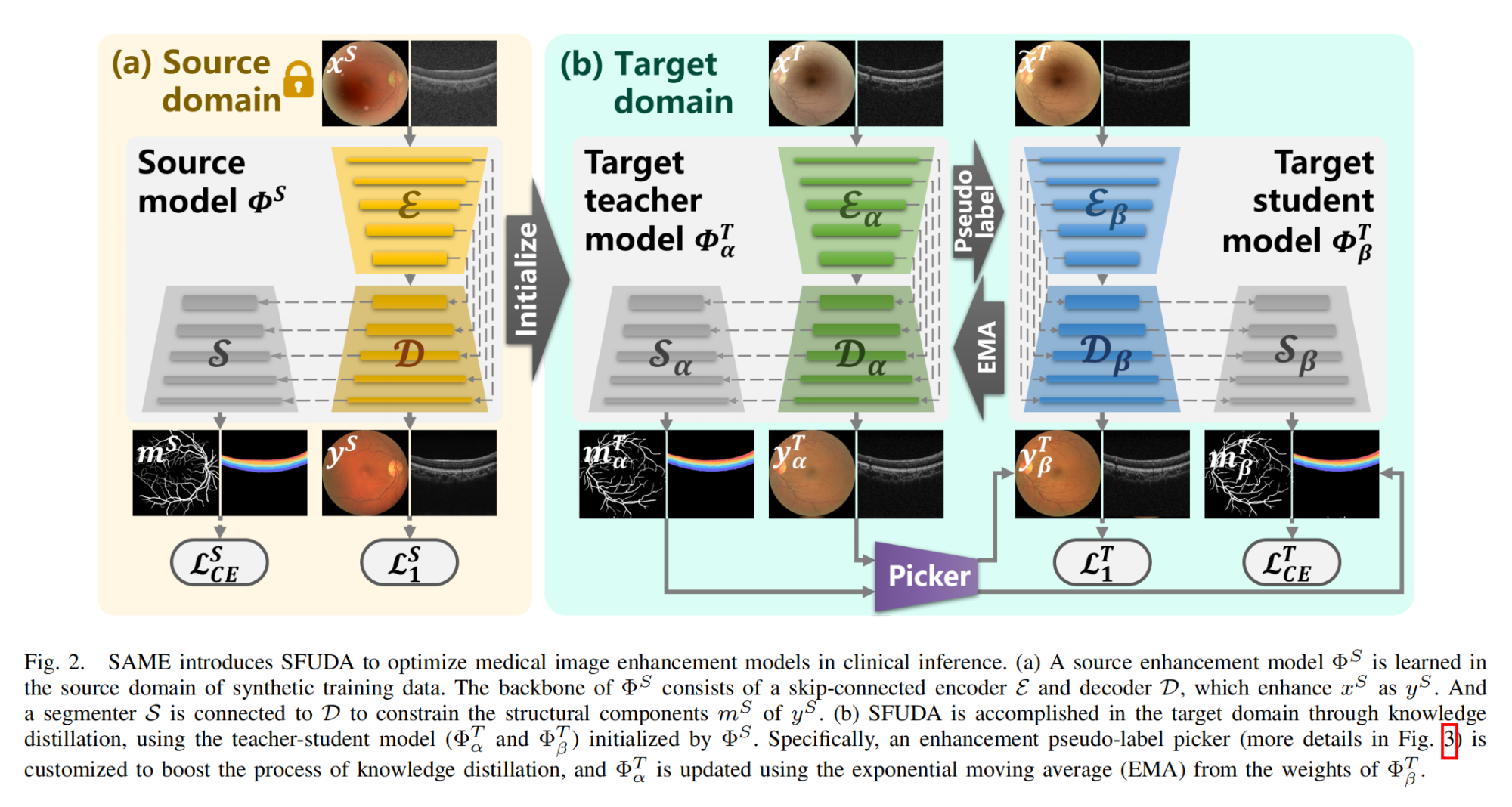
10.【圖像增強】Enhancing and Adapting in the Clinic: Source-free Unsupervised Domain Adaptation for Medical Image Enhancement
-
論文地址:https://arxiv.org//pdf/2312.01338
-
開源代碼:https://github.com/liamheng/Annotation-free-Medical-Image-Enhancement
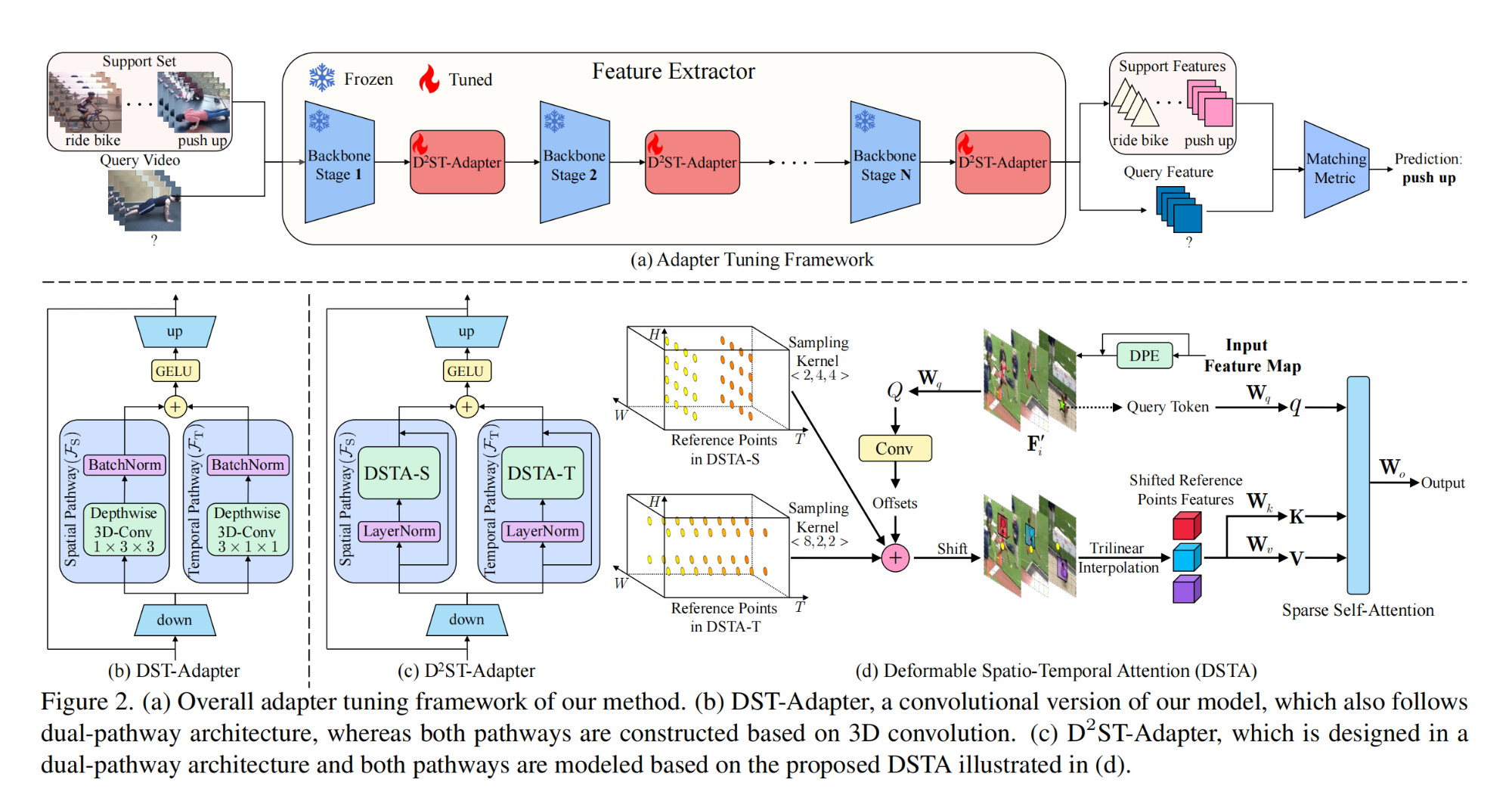
11.【動作識別】DST-Adapter: Disentangled-and-Deformable Spatio-Temporal Adapter for Few-shot Action Recognition
-
論文地址:https://arxiv.org//pdf/2312.01431
-
開源代碼(即將開源):https://github.com/qizhongtan/D2ST-Adapter
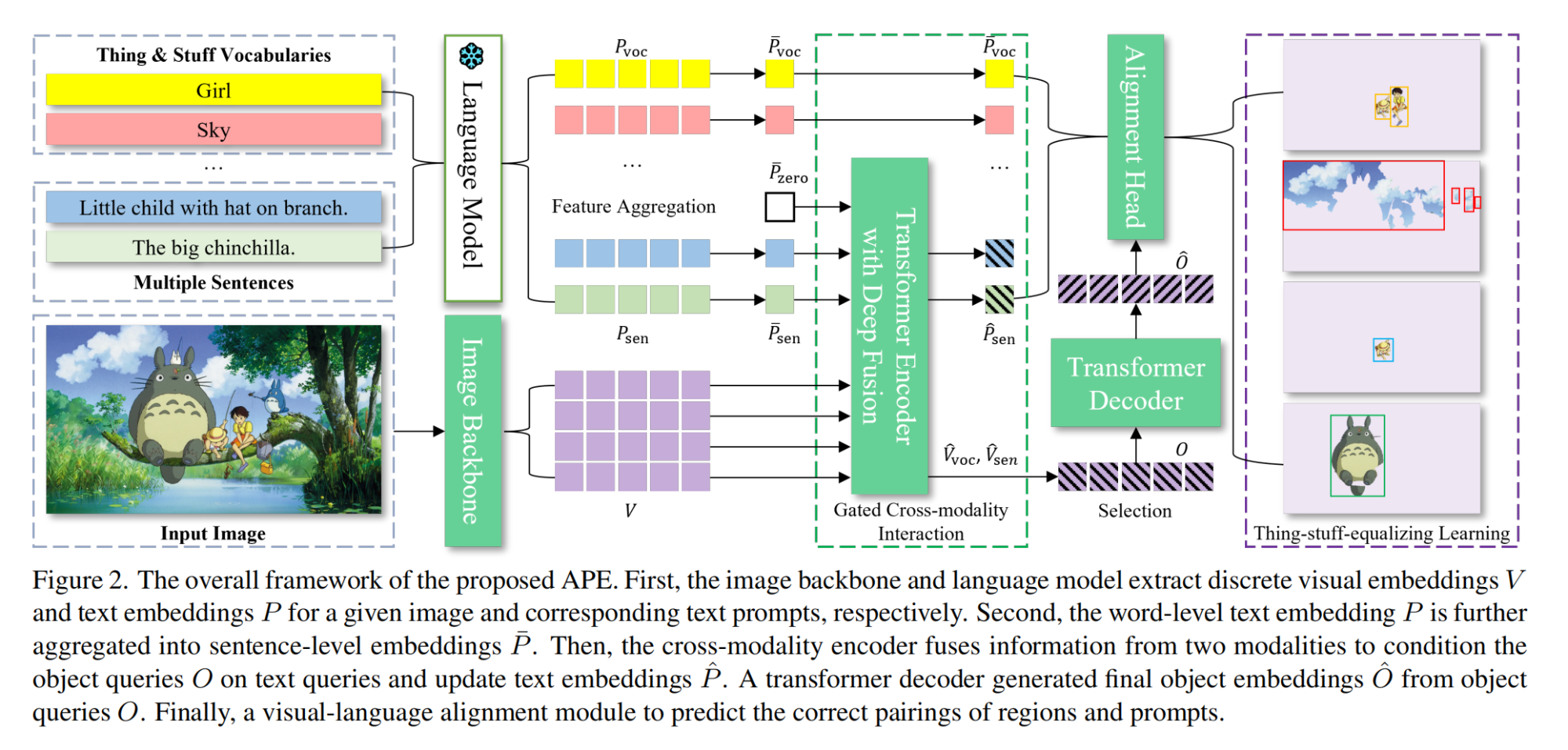
12.【多模態】Aligning and Prompting Everything All at Once for Universal Visual Perception
-
論文地址:https://arxiv.org//pdf/2312.02153
-
開源代碼:https://github.com/shenyunhang/APE
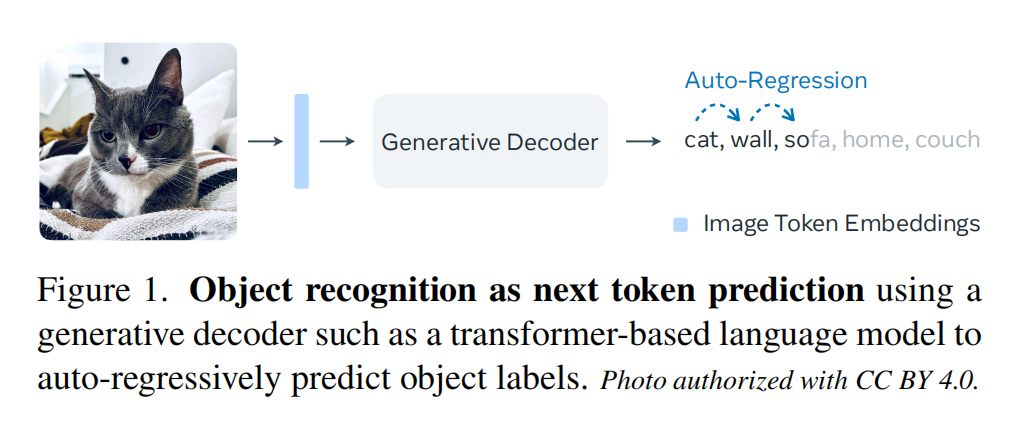
13.【多模態】Object Recognition as Next Token Prediction
-
論文地址:https://arxiv.org//pdf/2312.02142
-
開源代碼:https://github.com/kaiyuyue/nxtp
14.【多模態】Mitigating Fine-Grained Hallucination by Fine-Tuning Large Vision-Language Models with Caption Rewrites
-
論文地址:https://arxiv.org//pdf/2312.01701
-
開源代碼:https://github.com/Anonymousanoy/FOHE

15.【多模態】Good Questions Help Zero-Shot Image Reasoning
-
論文地址:https://arxiv.org//pdf/2312.01598
-
開源代碼:https://github.com/kai-wen-yang/QVix

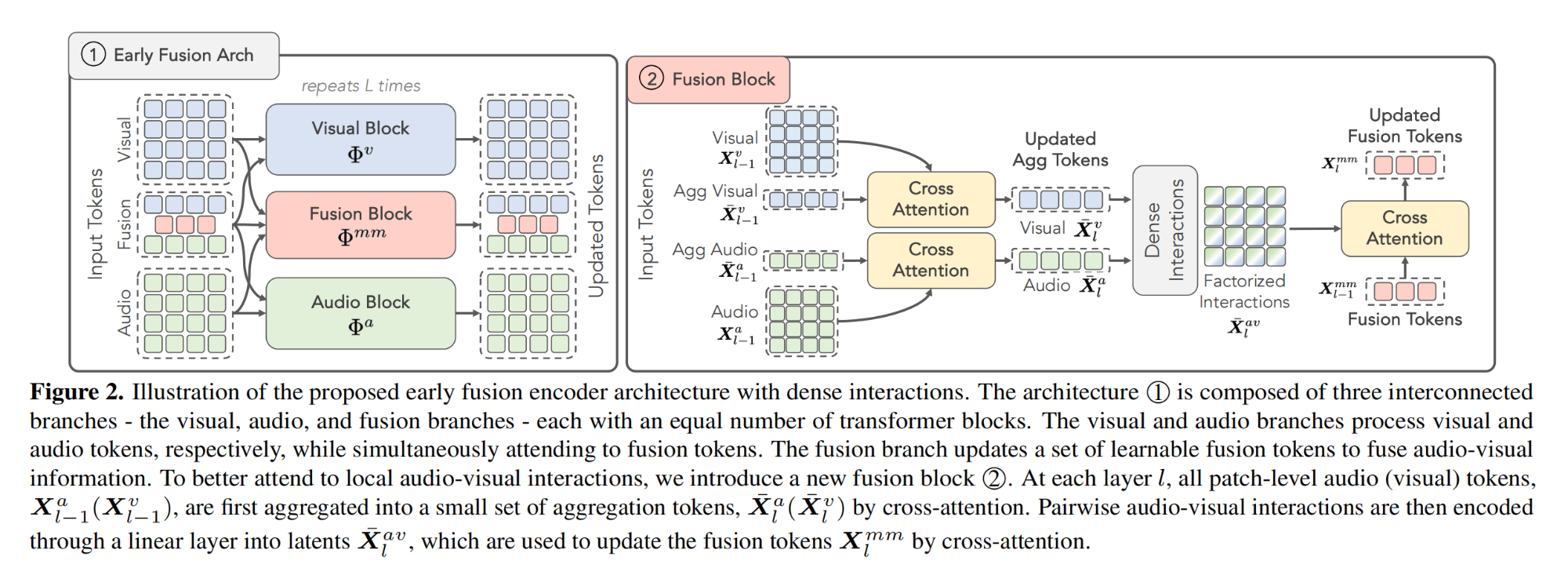
16.【多模態】Unveiling the Power of Audio-Visual Early Fusion Transformers with Dense Interactions through Masked Modeling
-
論文地址:https://arxiv.org//pdf/2312.01017
-
開源代碼(即將開源):https://github.com/stoneMo/DeepAVFusion
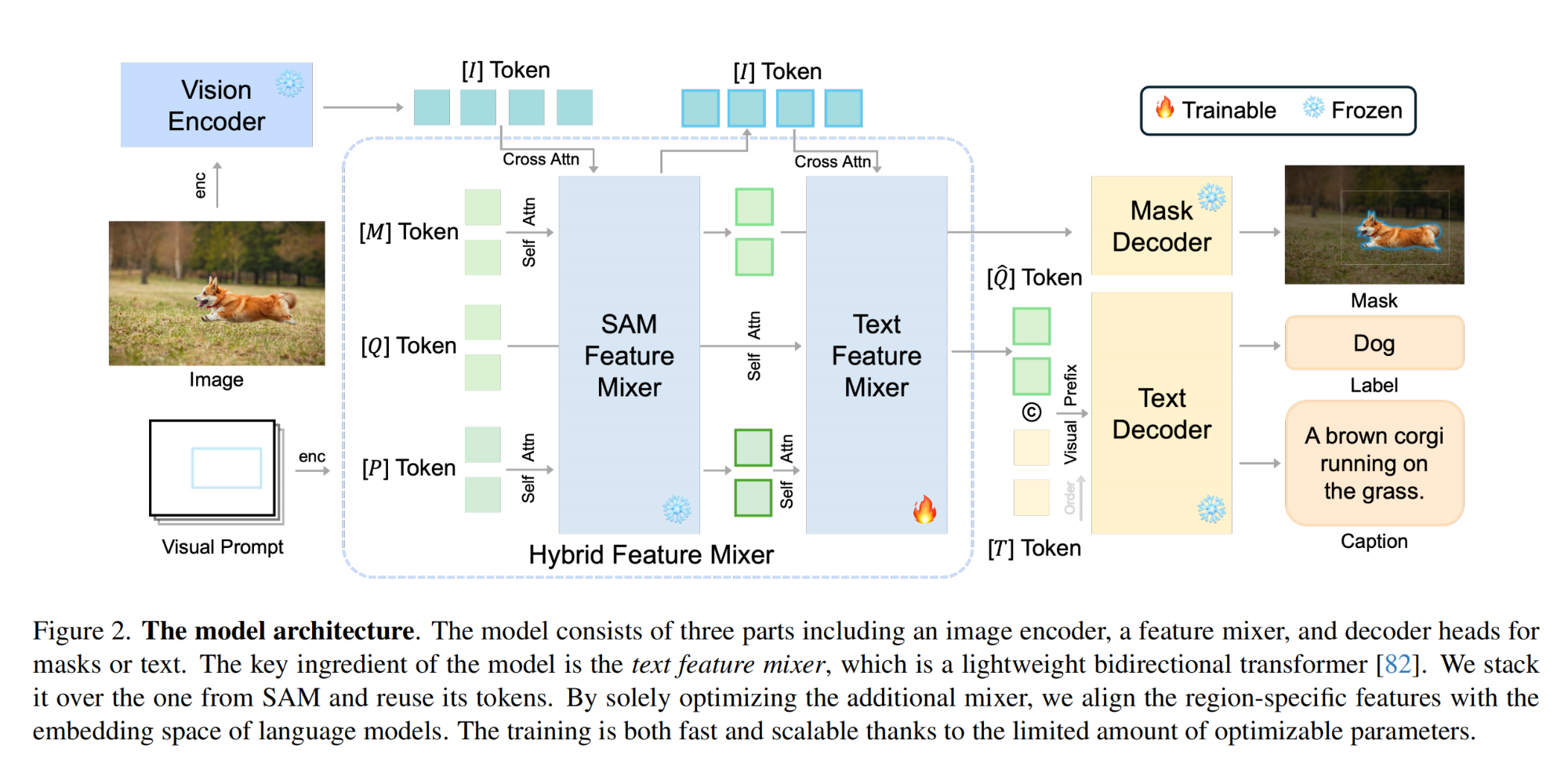
17.【多模態】Segment and Caption Anything
-
論文地址:https://arxiv.org//pdf/2312.00869
-
工程主頁:Segment and Caption Anything
-
開源代碼:https://github.com/xk-huang/segment-caption-anything
18.【多模態】VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models
-
論文地址:https://arxiv.org//pdf/2312.00845
-
工程主頁:VMC
-
開源代碼:https://github.com/HyeonHo99/Video-Motion-Customization

19.【多模態】A Challenging Multimodal Video Summary: Simultaneously Extracting and Generating Keyframe-Caption Pairs from Video
-
論文地址:https://arxiv.org//pdf/2312.01575
-
開源代碼:https://github.com/keitokudo/Multi-VidSum

20.【數字人】GaussianAvatar: Towards Realistic Human Avatar Modeling from a Single Video via Animatable 3D Gaussians
-
論文地址:https://arxiv.org//pdf/2312.02134
-
工程主頁:Projectpage of GaussianAvatar
-
開源代碼(即將開源):https://github.com/huliangxiao/GaussianAvatar

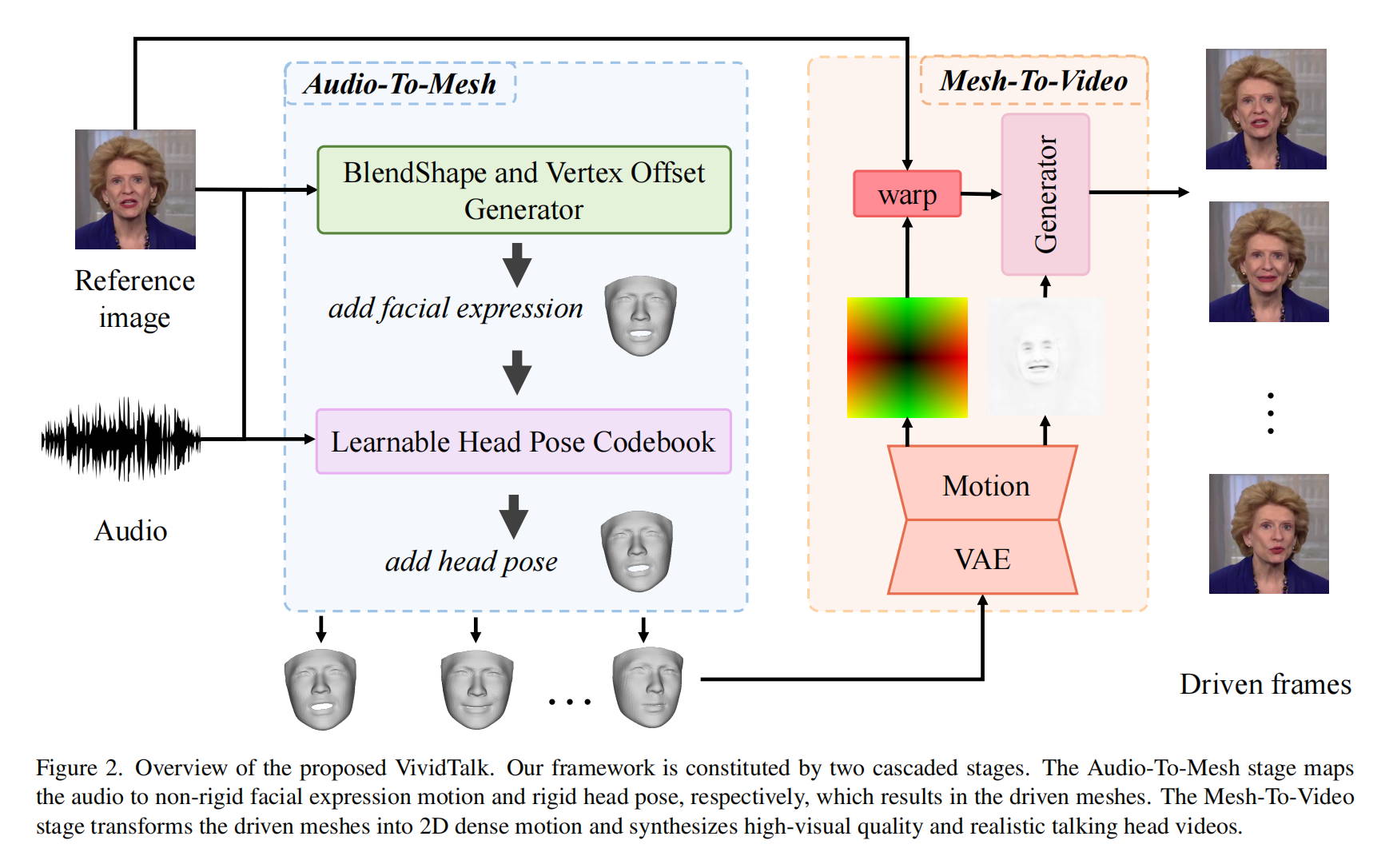
21.【數字人】VividTalk: One-Shot Audio-Driven Talking Head Generation Based on 3D Hybrid Prior
-
論文地址:https://arxiv.org//pdf/2312.01841
-
工程主頁:VividTalk: One-Shot Audio-Driven Talking Head Generation Based 3D Hybrid Prior
-
開源代碼(即將開源):https://github.com/HumanAIGC/VividTalk
22.【數字人】3DiFACE: Diffusion-based Speech-driven 3D Facial Animation and Editing
-
論文地址:https://arxiv.org//pdf/2312.00870
-
工程主頁:3DiFACE: Diffusion-based Speech-driven 3D Facial Animation and Editing
-
開源代碼(即將開源):https://github.com/bala1144/3DiFACE

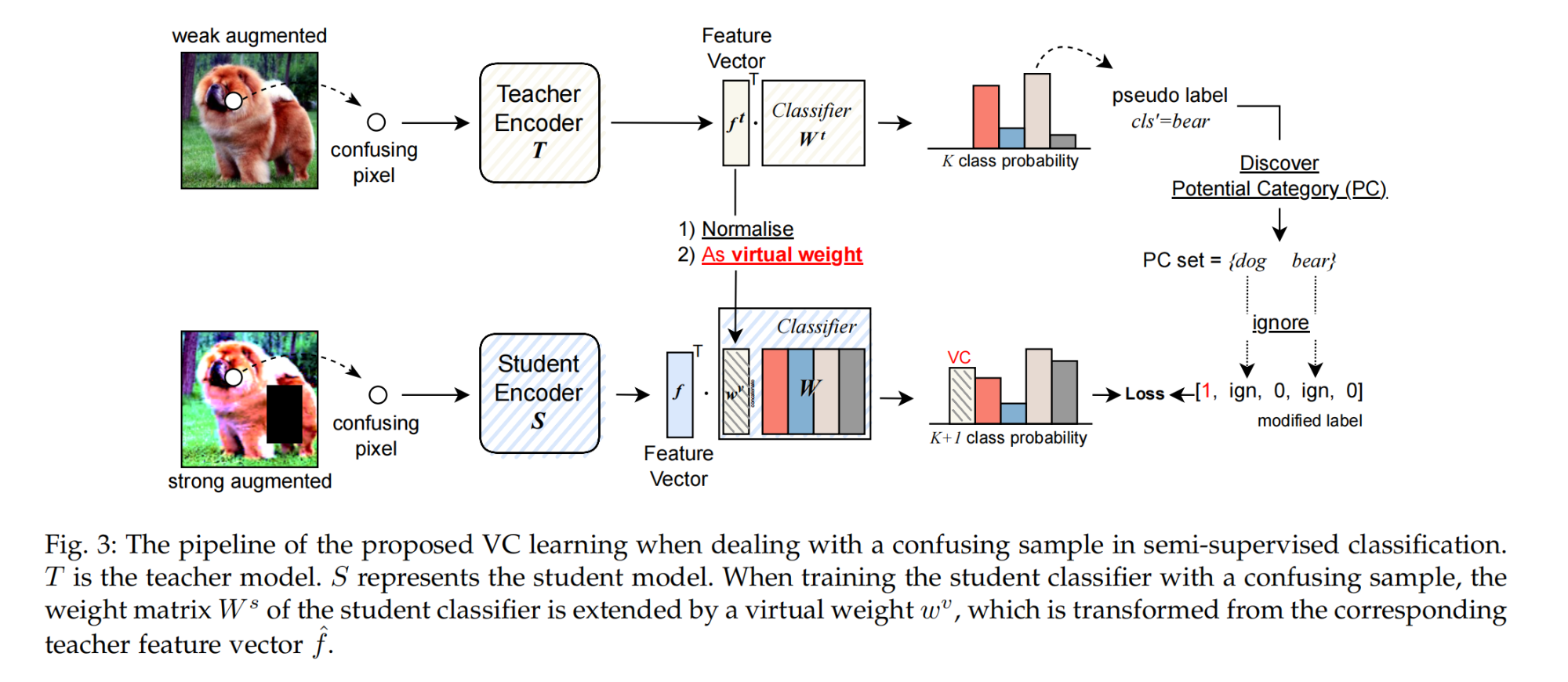
23.【半監督學習】Virtual Category Learning: A Semi-Supervised Learning Method for Dense Prediction with Extremely Limited Labels
-
論文地址:https://arxiv.org//pdf/2312.01169
-
開源代碼:https://github.com/GeoffreyChen777/VC
24.【深度估計】Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
-
論文地址:https://arxiv.org//pdf/2312.02145
-
工程主頁:Marigold: Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
-
開源代碼:https://github.com/prs-eth/marigold

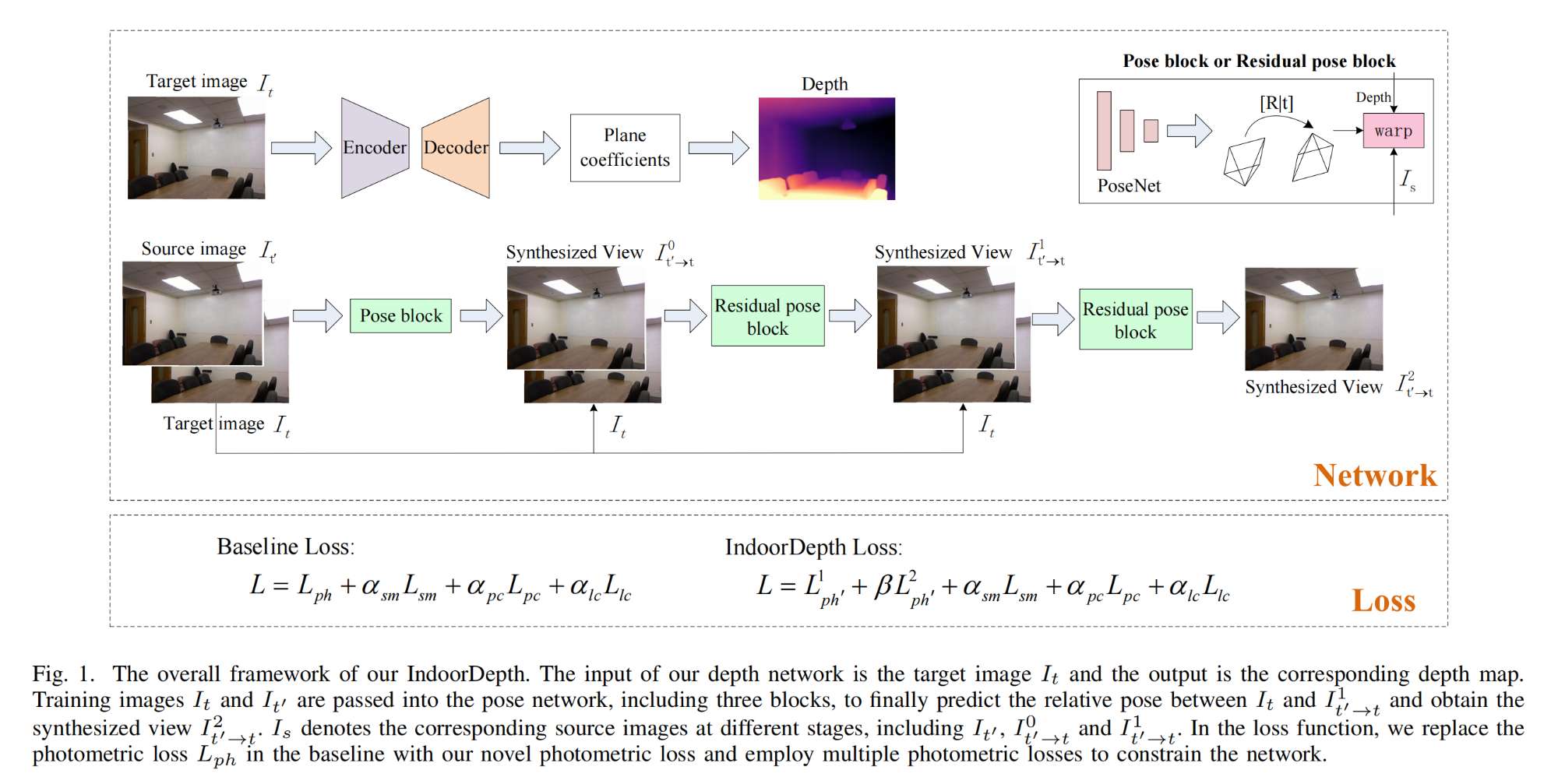
25.【深度估計】Deeper into Self-Supervised Monocular Indoor Depth Estimation
-
論文地址:https://arxiv.org//pdf/2312.01283
-
開源代碼:https://github.com/fcntes/IndoorDepth
26.【場景補全】PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
-
論文地址:https://arxiv.org//pdf/2312.02158
-
工程主頁:PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
-
開源代碼(即將開源):https://github.com/astra-vision/PaSCo
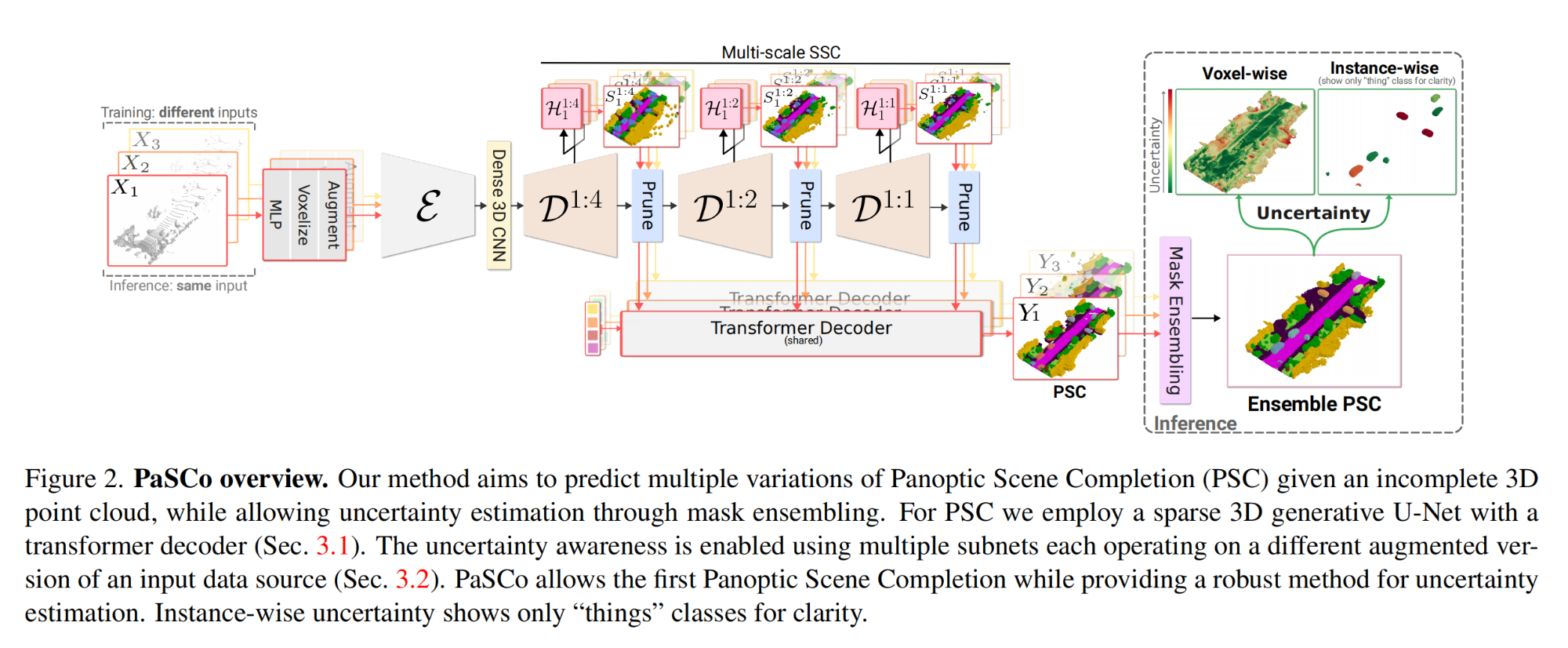
27.【風格遷移】Multimodality-guided Image Style Transfer using Cross-modal GAN Inversion
-
論文地址:https://arxiv.org//pdf/2312.01671
-
工程主頁:Multimodality-guided Image Style Transfer using Cross-modal GAN Inversion
-
代碼即將開源
28.【Diffusion】Readout Guidance: Learning Control from Diffusion Features
-
論文地址:https://arxiv.org//pdf/2312.02150
-
工程主頁:Readout Guidance: Learning Control from Diffusion Features
-
代碼即將開源

29.【Diffusion】ResEnsemble-DDPM: Residual Denoising Diffusion Probabilistic Models for Ensemble Learning
-
論文地址:https://arxiv.org//pdf/2312.01682
-
開源代碼(即將開源):https://github.com/nkicsl/ResEnsemble-DDPM
30.【Diffusion】DeepCache: Accelerating Diffusion Models for Free
-
論文地址:https://arxiv.org//pdf/2312.00858
-
開源代碼:https://github.com/horseee/DeepCache

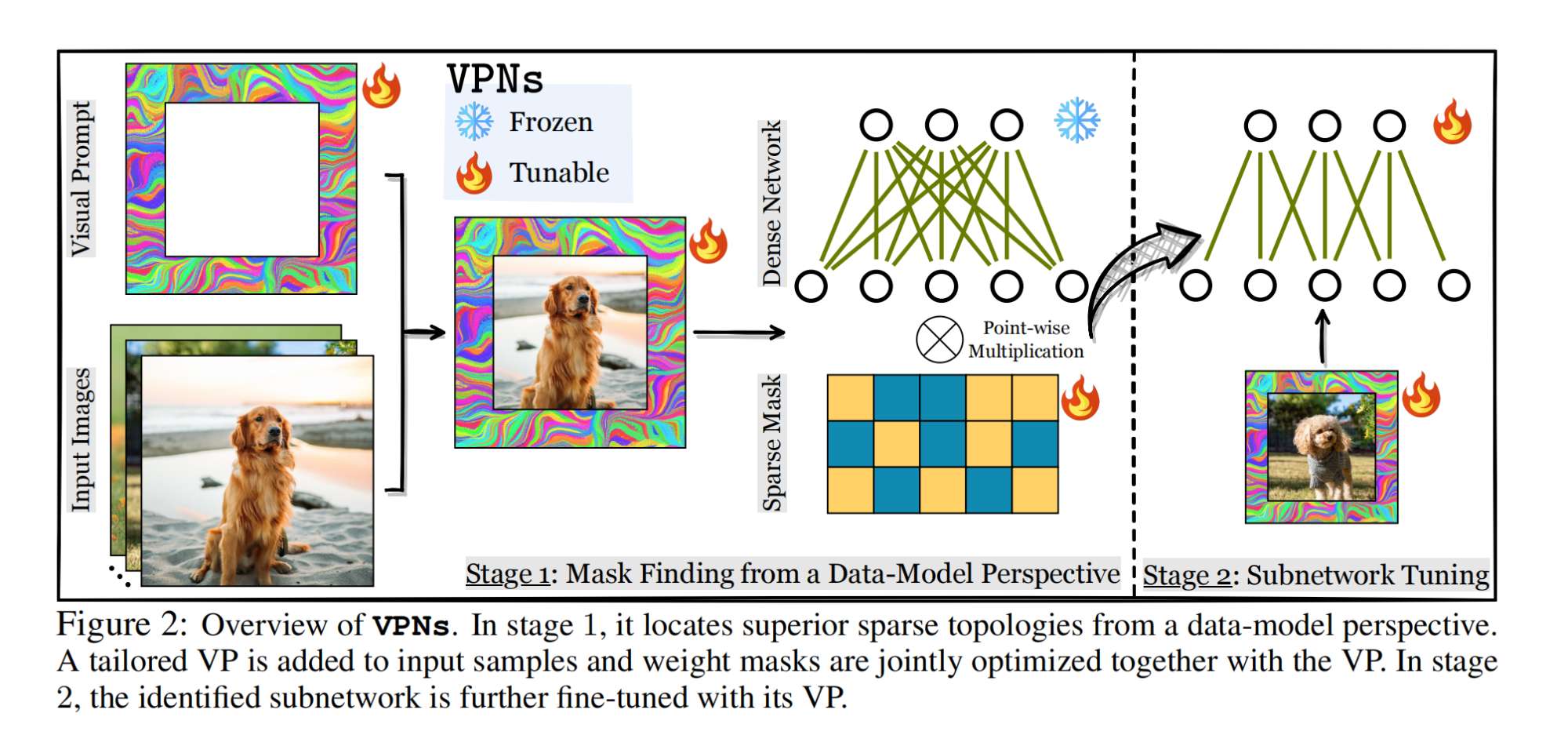
31.【網絡剪枝】Visual Prompting Upgrades Neural Network Sparsification: A Data-Model Perspective
-
論文地址:https://arxiv.org//pdf/2312.01397
-
開源代碼:https://github.com/UNITES-Lab/VPNs
32.【網絡剪枝】Physics Inspired Criterion for Pruning-Quantization Joint Learning
-
論文地址:https://arxiv.org//pdf/2312.00851
-
開源代碼:https://github.com/fanxxxxyi/PIC-PQ

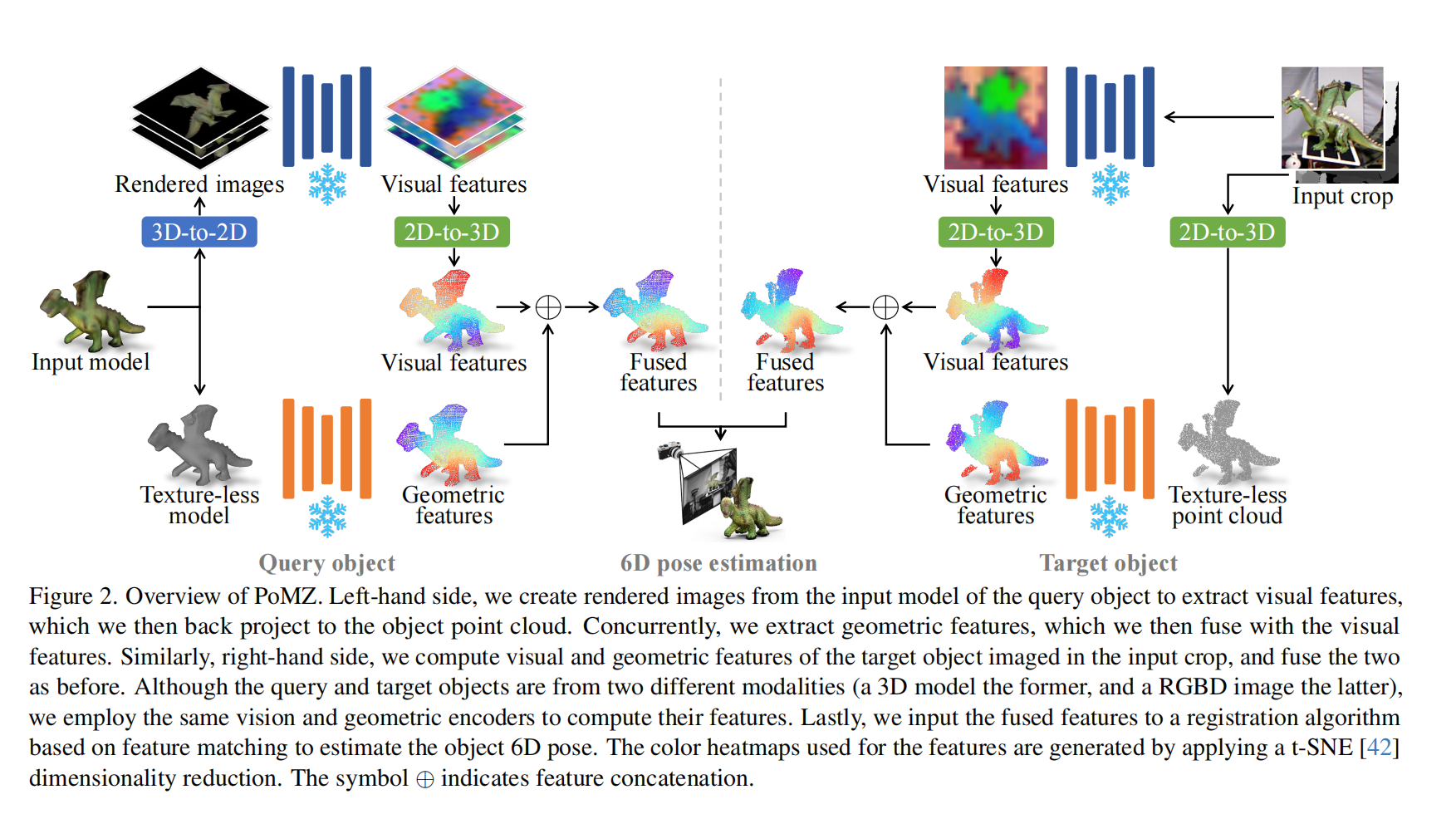
33.【姿態估計】Object 6D pose estimation meets zero-shot learning
-
論文地址:https://arxiv.org//pdf/2312.00947
-
工程主頁:PoMZ: Object 6D Pose Estimation Meets Zero-Shot Learning
-
代碼即將開源
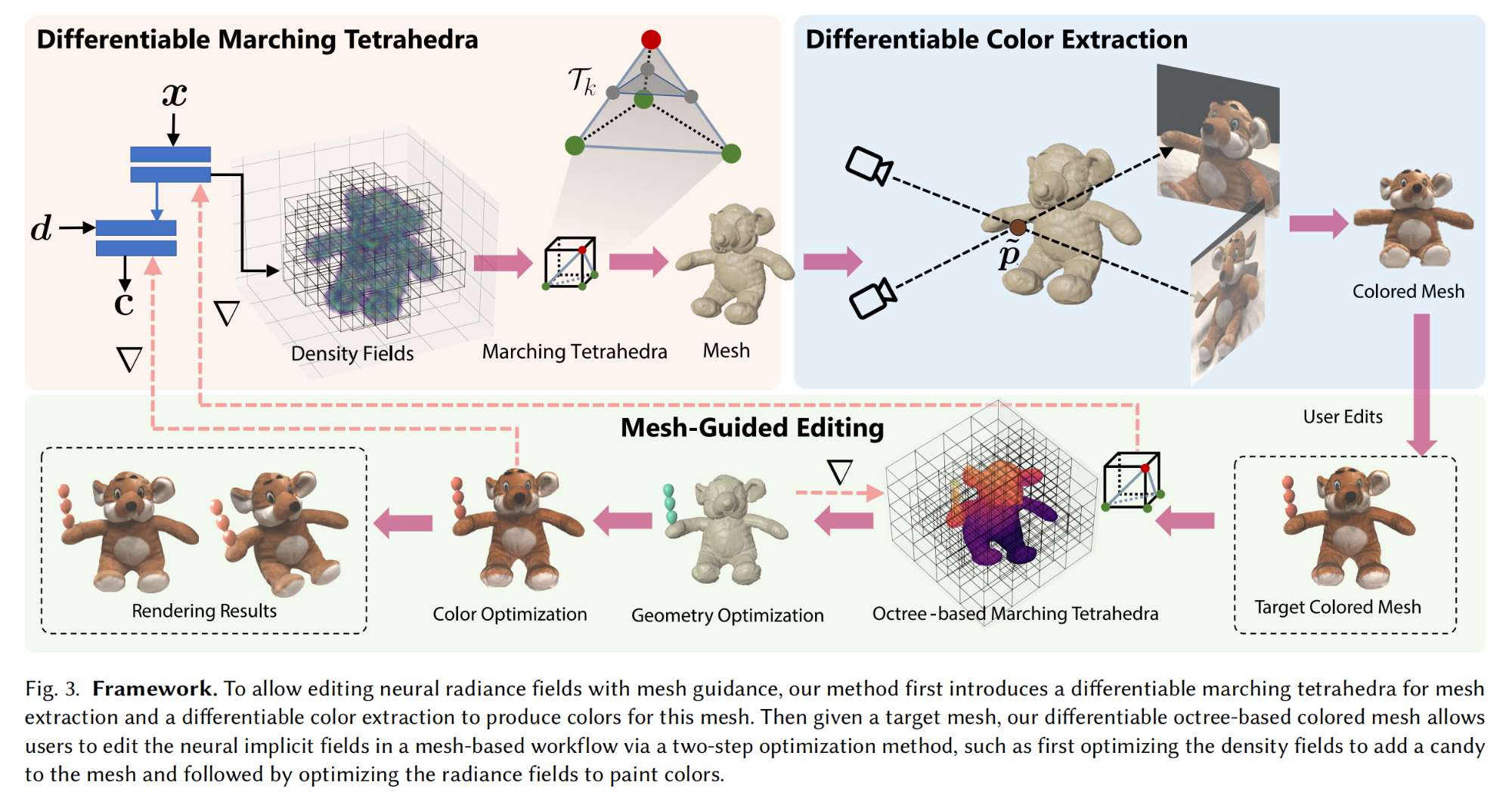
34.【NeRF】Mesh-Guided Neural Implicit Field Editing
-
論文地址:https://arxiv.org//pdf/2312.02157
-
工程主頁:Mesh-Guided Neural Implicit Field Editing
-
開源代碼(即將開源):https://github.com/cassiePython/MNeuEdit/tree/master
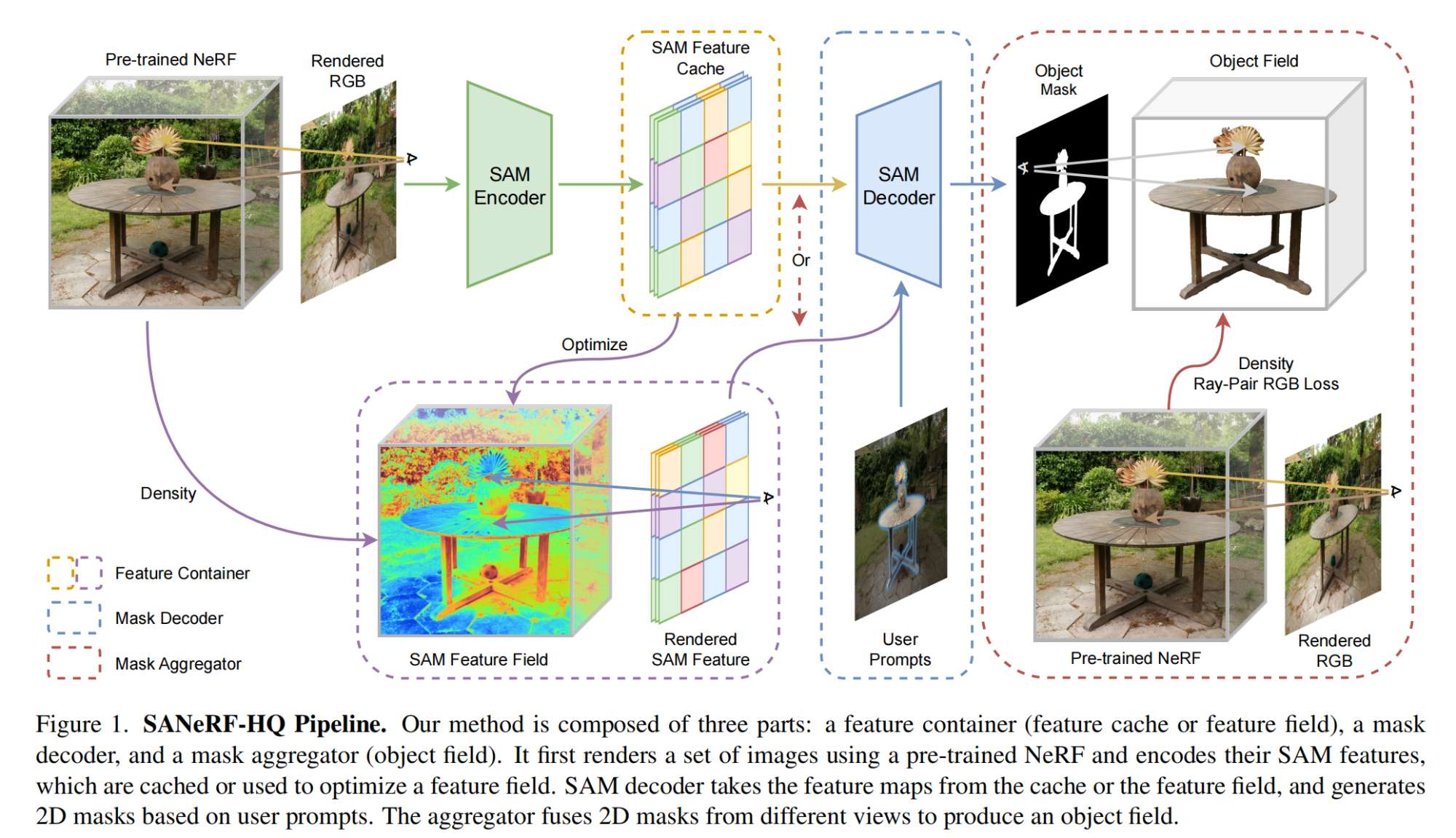
35.【NeRF】SANeRF-HQ: Segment Anything for NeRF in High Quality
-
論文地址:https://arxiv.org//pdf/2312.01531
-
工程主頁:SANeRF-HQ
-
開源代碼(即將開源):https://github.com/lyclyc52/SANeRF-HQ
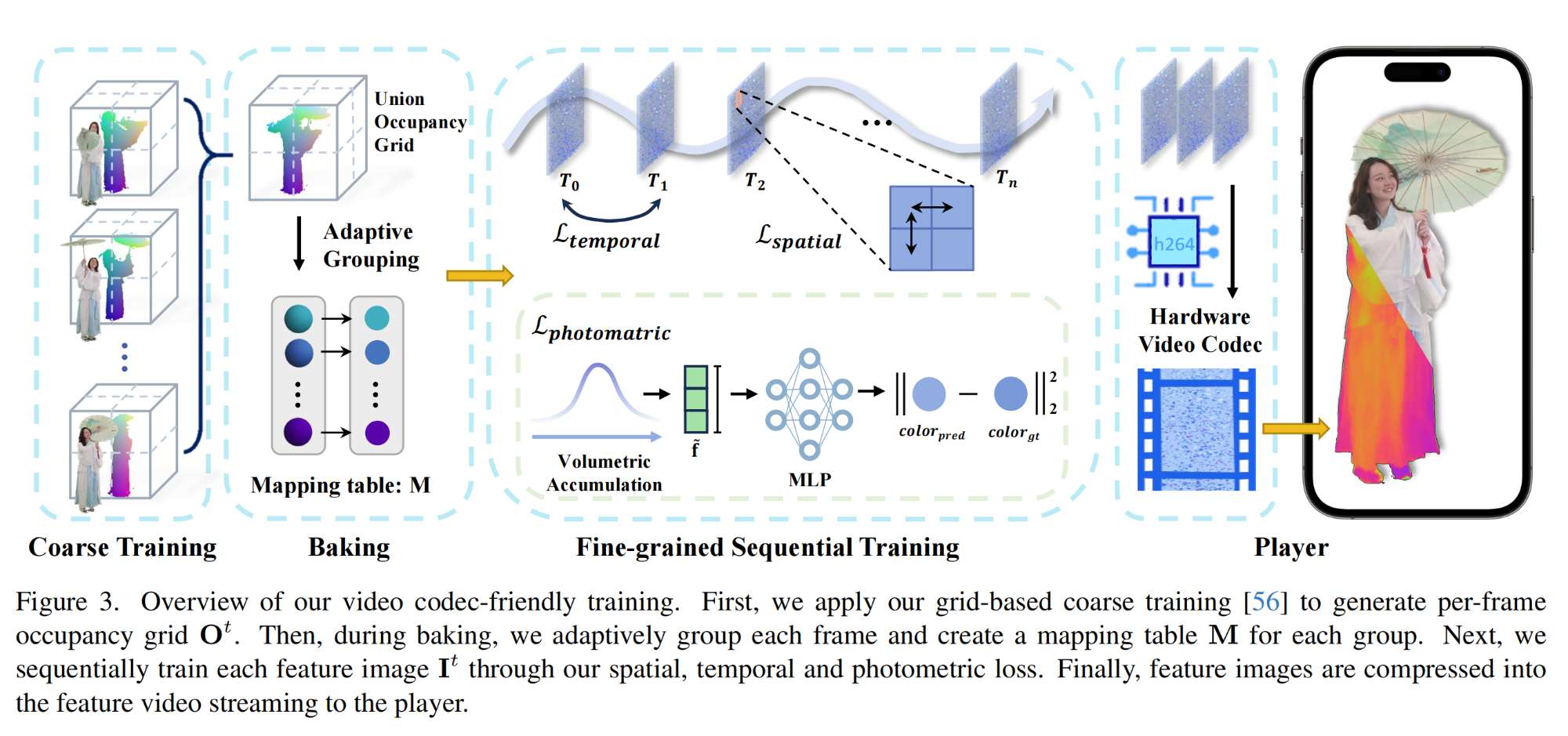
36.【NeRF】VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
-
論文地址:https://arxiv.org//pdf/2312.01407
-
工程主頁:VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
-
開源代碼(即將開源):https://github.com/aoliao12138/VideoRF
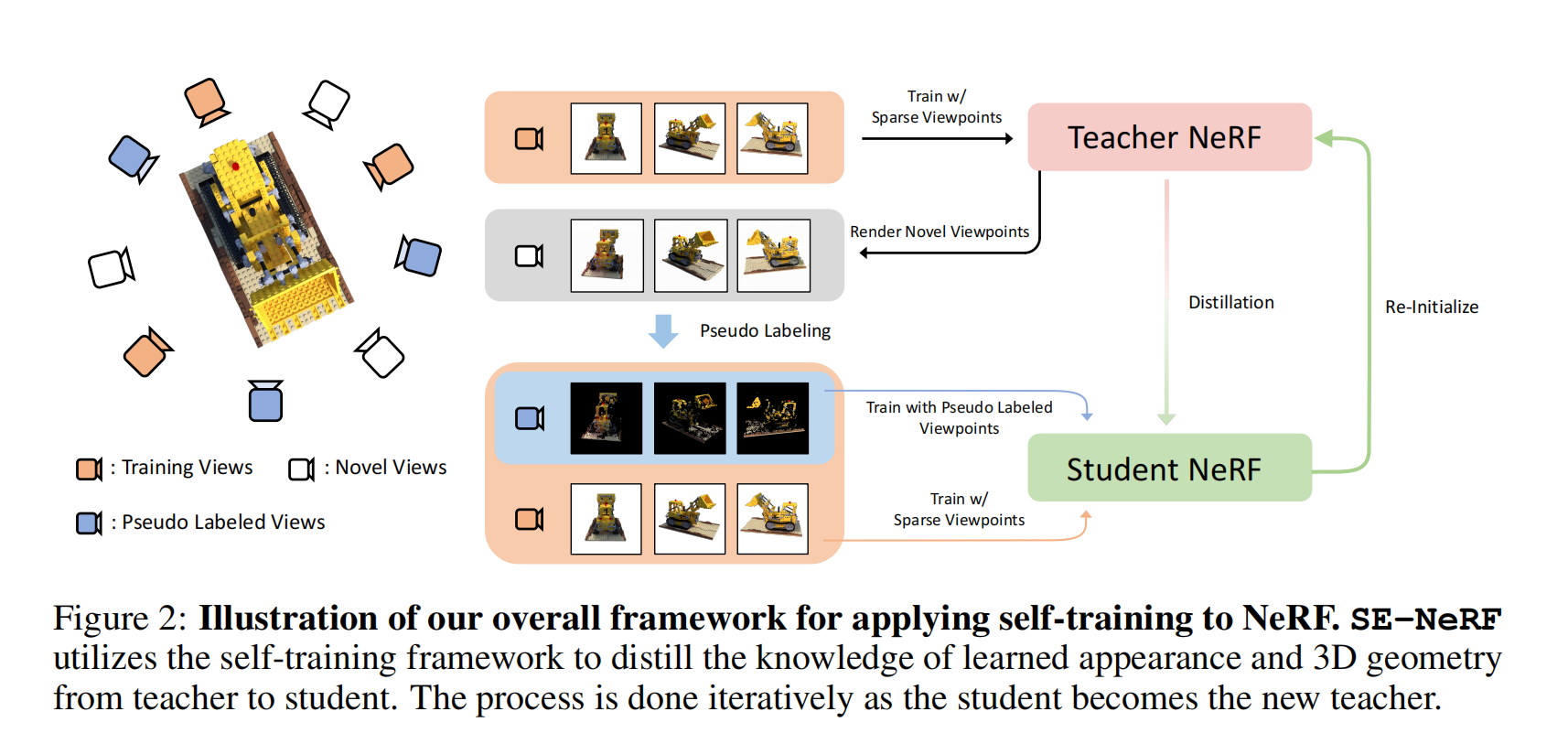
37.【NeRF】Self-Evolving Neural Radiance Fields
-
論文地址:https://arxiv.org//pdf/2312.01003
-
工程主頁:SE-NeRF
-
開源代碼(即將開源):https://github.com/KU-CVLAB/SE-NeRF
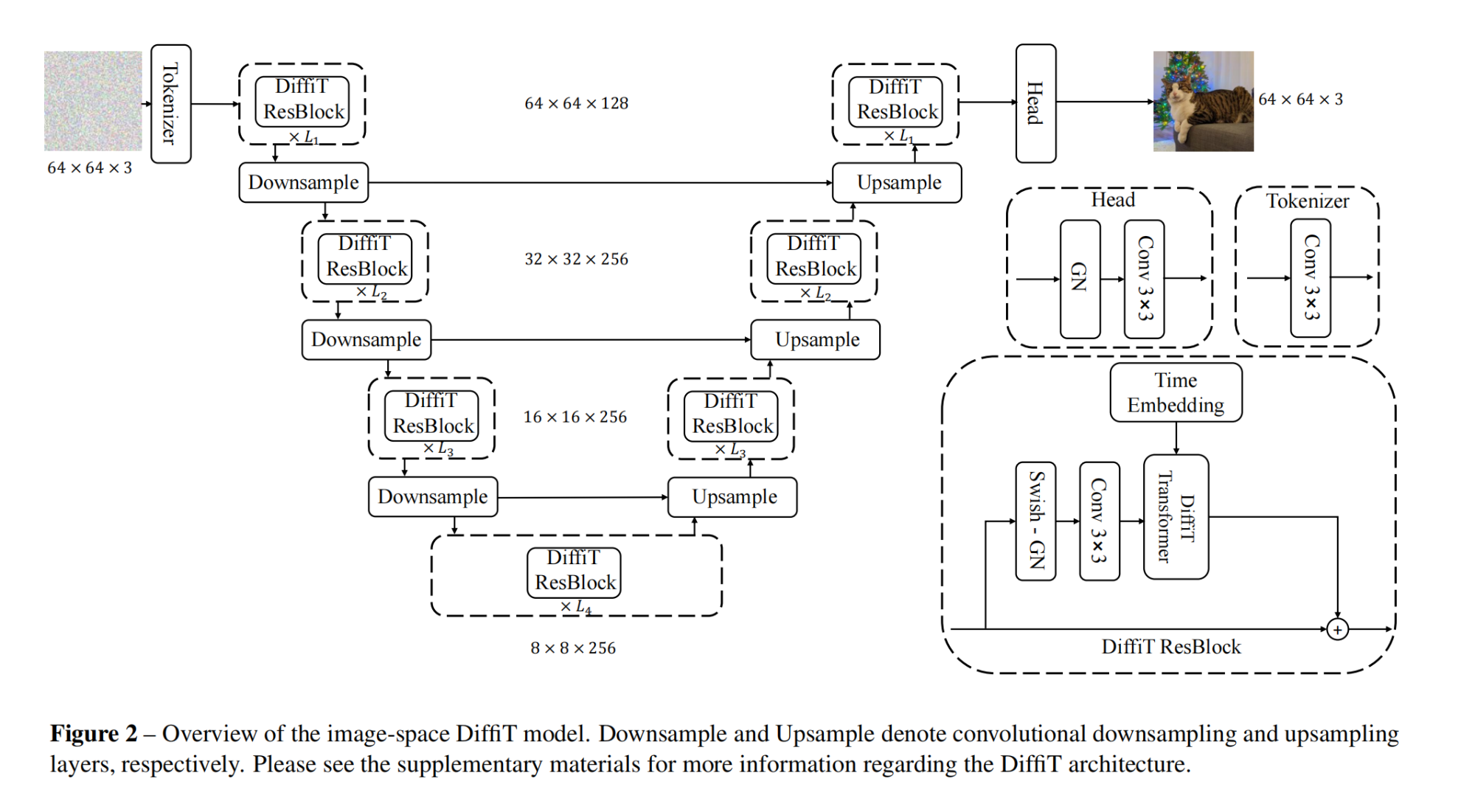
38.【圖像合成】DiffiT: Diffusion Vision Transformers for Image Generation
-
論文地址:https://arxiv.org//pdf/2312.02139
-
開源代碼:https://github.com/NVlabs/DiffiT
39.【圖像合成】Style Aligned Image Generation via Shared Attention
-
論文地址:https://arxiv.org//pdf/2312.02133
-
工程主頁:StyleAlign
-
開源代碼:https://github.com/google/style-aligned/

40.【人臉重建】DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
-
論文地址:https://arxiv.org//pdf/2312.01068
-
工程主頁:DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
-
開源代碼(即將開源):https://github.com/tangjiapeng/DPHMs

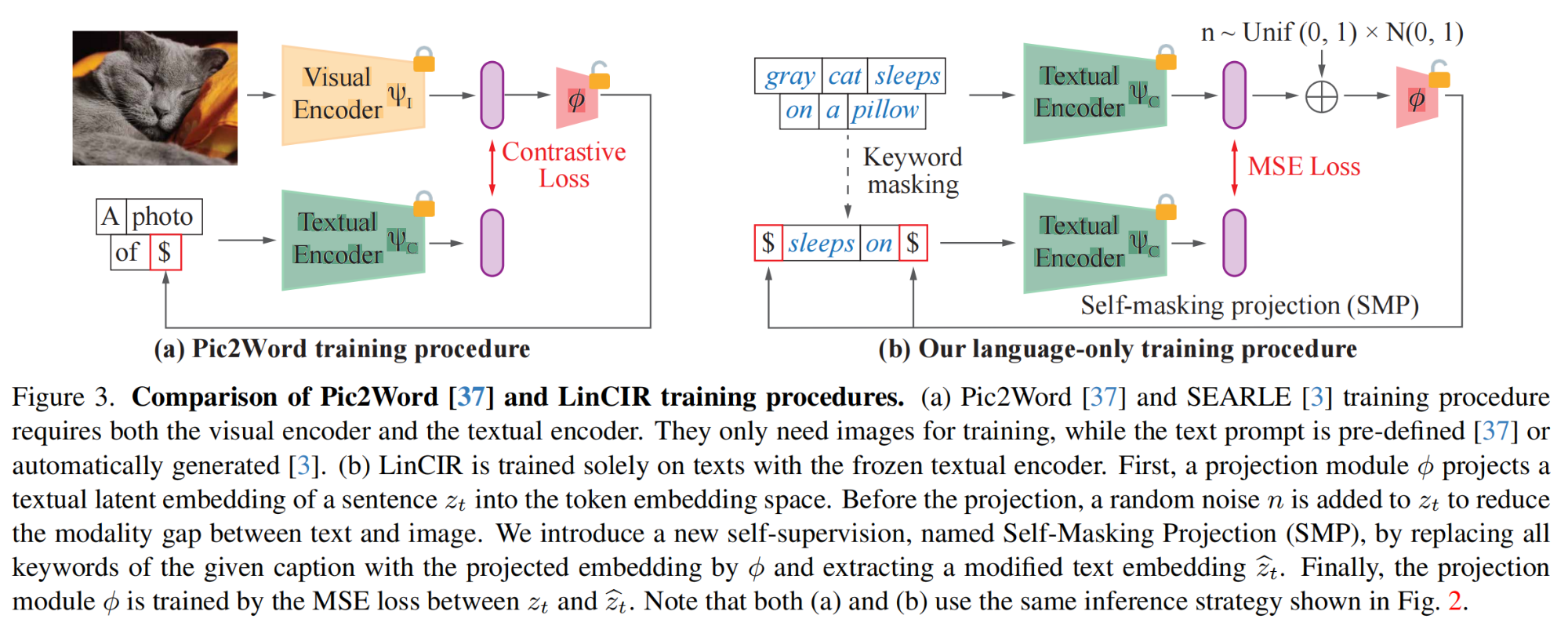
41.【圖像檢索】Language-only Efficient Training of Zero-shot Composed Image Retrieval
-
論文地址:https://arxiv.org//pdf/2312.01998
-
開源代碼:https://github.com/navervision/lincir
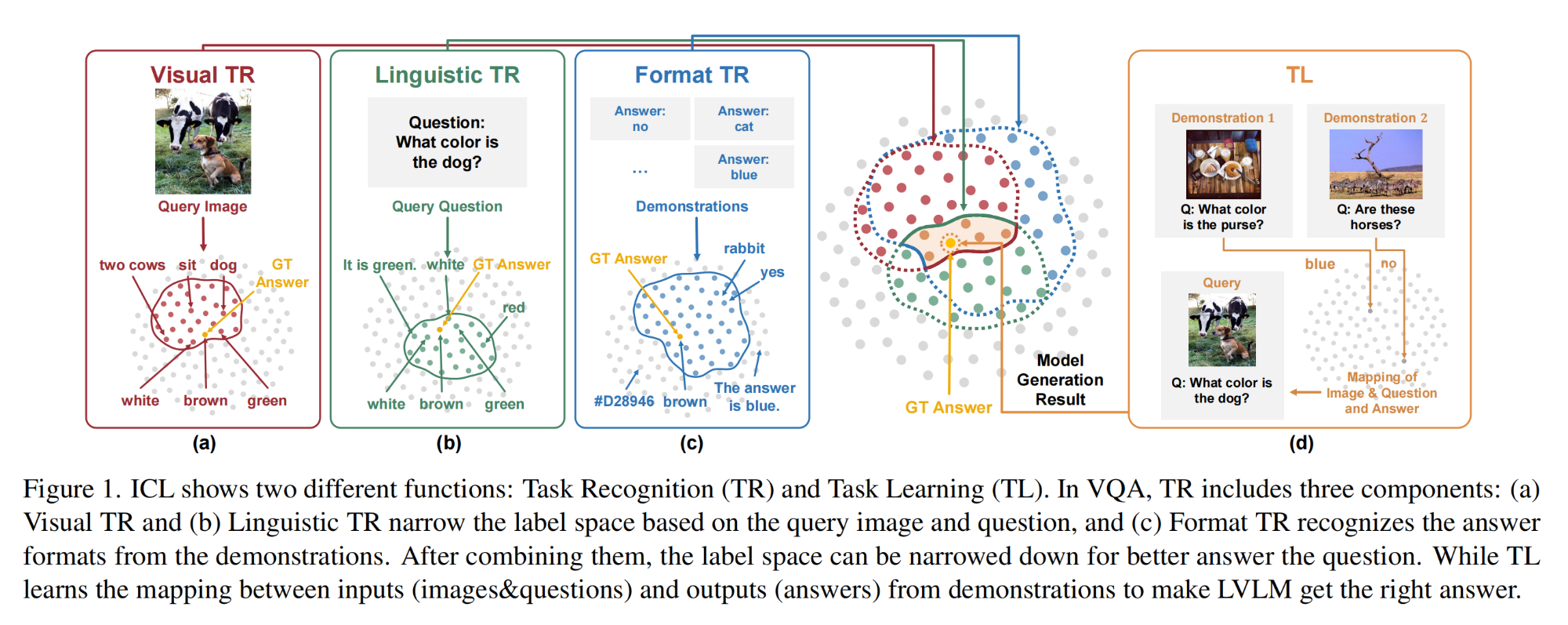
42.【Visual Question Answering】How to Configure Good In-Context Sequence for Visual Question Answering
-
論文地址:https://arxiv.org//pdf/2312.01571
-
開源代碼:https://github.com/GaryJiajia/OFv2_ICL_VQA
論文已打包,下載鏈接
CV計算機視覺交流群
群內包含目標檢測、圖像分割、目標跟蹤、Transformer、多模態、NeRF、GAN、缺陷檢測、顯著目標檢測、關鍵點檢測、超分辨率重建、SLAM、人臉、OCR、生物醫學圖像、三維重建、姿態估計、自動駕駛感知、深度估計、視頻理解、行為識別、圖像去霧、圖像去雨、圖像修復、圖像檢索、車道線檢測、點云目標檢測、點云分割、圖像壓縮、運動預測、神經網絡量化、網絡部署等多個領域的大佬,不定期分享技術知識、面試技巧和內推招聘信息。
想進群的同學請添加微信號聯系管理員:PingShanHai666。添加好友時請備注:學校/公司+研究方向+昵稱。
推薦閱讀:
CV計算機視覺每日開源代碼Paper with code速覽-2023.12.5
CV計算機視覺每日開源代碼Paper with code速覽-2023.12.4
CV計算機視覺每日開源代碼Paper with code速覽-2023.12.1

:RBAC 權限管理設計)






)










![[基礎IO]文件描述符{C庫函數\系統接口\初識fd}](http://pic.xiahunao.cn/[基礎IO]文件描述符{C庫函數\系統接口\初識fd})