一、數倉建模方法論
1.1 ER模型(Entity Relationship、實體關系模型、范式模型)
ER模型是Bill Inmon提出的一種建模方法,實體關系模型將復雜的數據抽象為兩個概念 ---- 實體和關系
該模型在范式理論上符合3NF,這種模型目的是減少數據冗余,保證數據的一致性,這種模型不適合直接用于分析統計
范式一共有6種,范式級別越高,數據冗余越低:
第一范式(1NF)、第二范式(2NF)、第三范式(3NF)
巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)
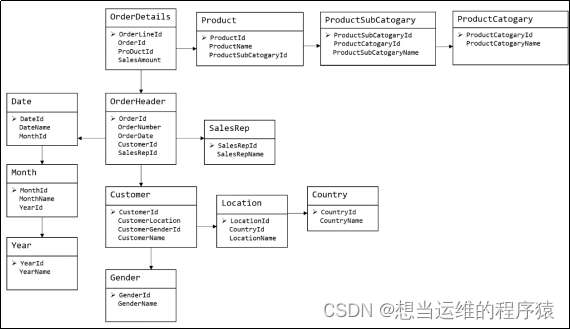
如下圖為根據ER模型所建立的模型,較為松散,物理表多(需多表join,所以不適合分析統計)
1.1.1 第一范式(1NF)
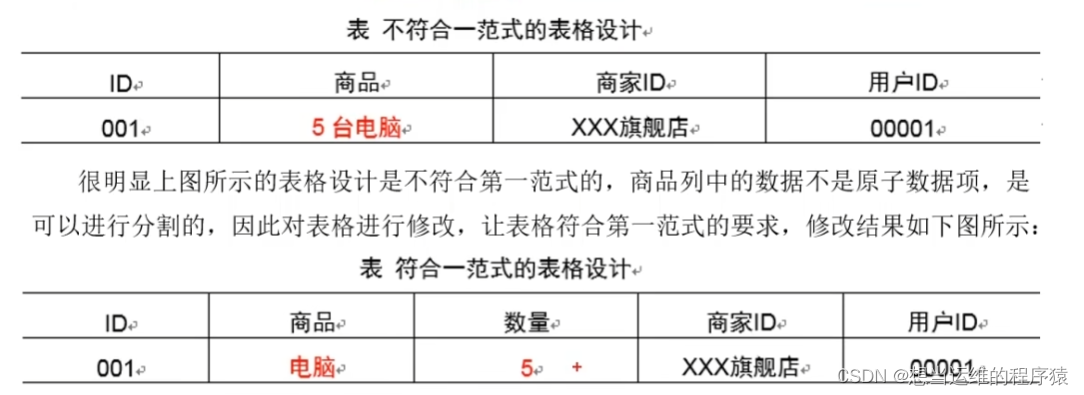
第一范式(1NF)的核心原則:屬性不可切割
如下圖,“5臺電腦”要拆分為數量“5”和商品“電腦”兩個字段
1.1.2 第二范式(2NF)
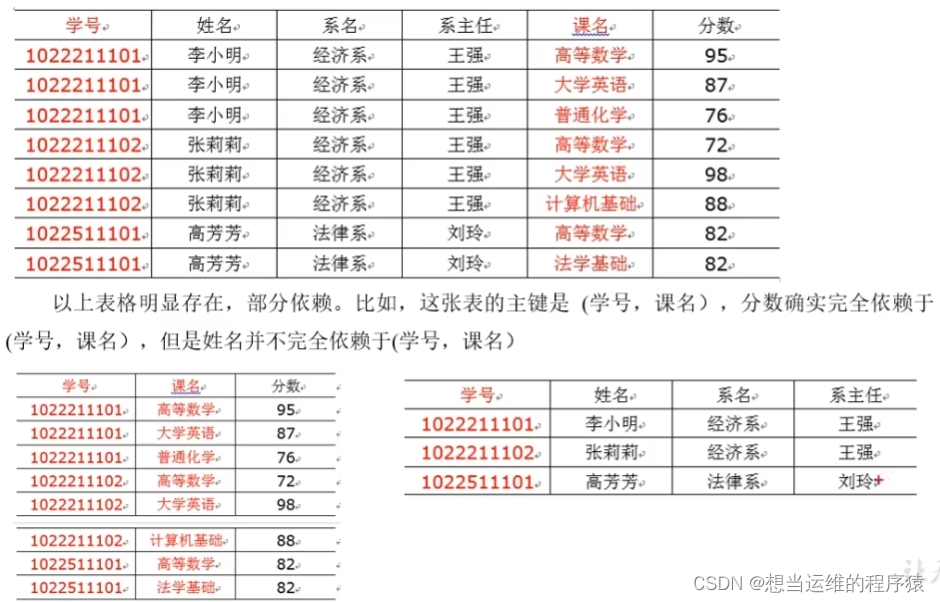
第二范式(1NF)的核心原則:不能存在非主鍵字段“部分函數依賴”于主鍵字段【除主鍵外其他字段完全依賴于主鍵】
如下圖,主鍵是(學號,課名),姓名完全依賴于學號,部分依賴于(學號,課名),因此是不滿足第二范式的,需將姓名拆分出來
1.1.3 第三范式(3NF)
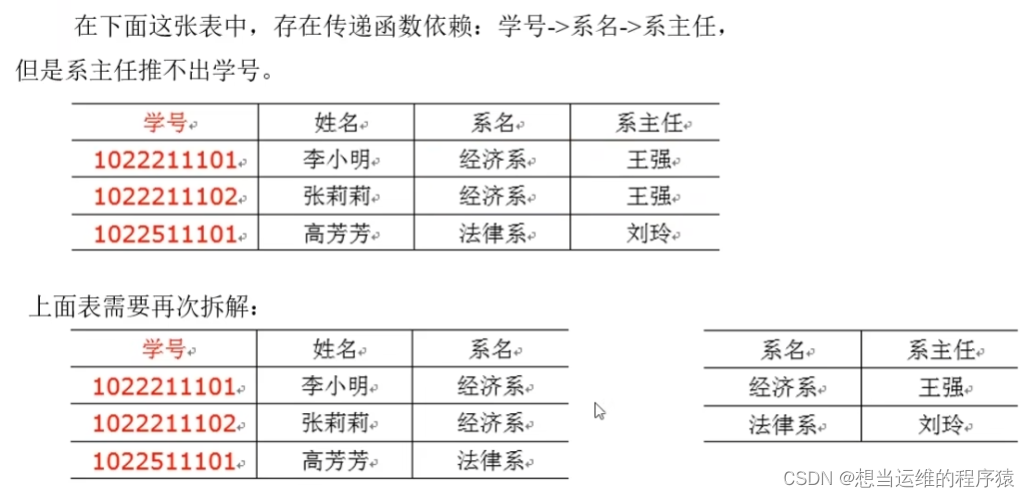
第三范式(1NF)的核心原則:不能存在傳遞函數依賴【決定某字段值的必須是主鍵】
如下圖,系主任傳遞依賴于學號(系主任依賴于系名,系名依賴于學號,因此為傳遞依賴)
1.2 維度模型(重點)
維度模型是Ralph Kimball提出的一種建模方法,維度模型將復雜的業務抽象為兩個概念 ---- 事實和維度
該模型關注的重點在于用戶如何更快的完成需求分析及數據分析
如下圖為根據維度模型所建立的模型,中間是事實表,周圍是一圈維度表,模型更清晰、簡潔
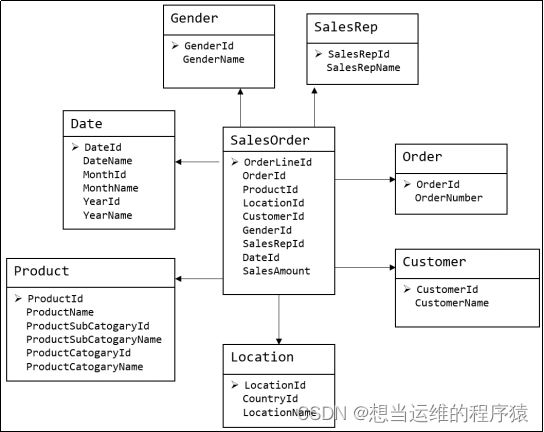
1.2.1 事實表
事實表是數據倉庫維度建模的核心,緊緊圍繞著業務過程來設計,其包含與該業務過程有關的維度引用(維度表外鍵)以及該業務過程的度量(通常是數字類型)
以上圖為例,維度表外鍵對應OderId,ProductId,LocationId等,度量對應SalesAmount
事實表的三種類型分為:事務事實表、周期快照事實表、累計快照事實表
事務事實表(重點)
事務型事實表用來記錄各業務過程,它保存的是各業務過程的最細粒度的操作事件。
設計事務事實表時一般可遵循以下四個步驟:
選擇業務過程→聲明粒度→確認維度(維度外鍵)→確認事實(度量)
周期快照事實表
周期快照事實表以具有規律性的、可預見的時間間隔來記錄事實,主要用于分析一些存量型(例如商品庫存,賬戶余額)或者狀態型(空氣溫度,行駛速度)指標。一般是直接從業務系統同步獲得。
比如有一張記錄賬戶余額變動的表,每次計算賬戶余額要進行聚合操作,而使用周期快照事實表則可以直接獲得其余額,不用再進行聚合操作
對于空氣溫度、行駛速度這些狀態型指標,由于它們的值是連續的,所以無法使用事務型事實表統計而只能定期對其進行采樣,構建周期型快照事實表。
累計快照事實表
累計快照事實表是基于一個業務流程中的多個關鍵業務過程聯合處理而構建的事實表,如交易流程中的下單、支付、發貨、確認收貨業務過程。
累積型快照事實表通常具有多個日期字段,每個日期對應業務流程中的一個關鍵業務過程(里程碑)。
| 訂單id | 用戶id | 下單日期 | 支付日期 | 發貨日期 | 確認收貨日期 | 訂單金額 | 支付金額 |
|---|---|---|---|---|---|---|---|
| 1001 | 1234 | 2020-06-14 | 2020-06-15 | 2020-06-16 | 2020-06-17 | 1000 | 1000 |
累積型快照事實表主要用于分析業務過程(里程碑)之間的時間間隔等需求。使用累積型快照事實表進行統計,就能避免事務事實表的關聯操作,從而變得十分簡單高效。
1.2.2 維度表
事實表圍繞業務過程進行設計,而維度表則圍繞業務過程所處的環境進行設計
維度表主要包含一個主鍵和各種維度字段,維度字段稱為維度屬性。
設計維度表時一般可遵循以下三個步驟:
確定維度表→確定主維表和相關維表→確定維度屬性
1)確定維度表:
確定與每個事實表相關的維度
- 如果存在多個事實表與同一個維度都相關的情況,這種情況需保證維度的唯一性,即只創建一張維度表。
- 如果某些維度表的維度屬性很少,例如只有一個**名稱,則可不創建該維度表,而把該表的維度屬性直接增加到與之相關的事實表中,這個操作稱為維度退化。
2)確定主維表和相關維表:
主維表與相關維表指的是業務系統中某維度相關的表
3)確定維度屬性:
確定維度屬性即確定維度表字段。維度屬性主要來自于業務系統中與該維度對應的主維表和相關維表。維度屬性可直接從主維表或相關維表中選擇,也可通過進一步加工得到。
1.3 維度表的星型模型、雪花模型
規范化是指使用一系列范式設計數據庫的過程,其目的是減少數據冗余,增強數據的一致性。通常情況下,規范化之后,一張表的字段會拆分到多張表。
反規范化是指將多張表的數據冗余到一張表,其目的是減少join操作,提高查詢性能。
在設計維度表時,如果對其進行規范化,得到的維度模型稱為雪花模型,如果對其進行反規范化,得到的模型稱為星型模型。
雪花模型與星型模型是針對于維度表來說的,區別在于是否進行規范化
如下圖,item表和location表,雪花模型對其進行了規范化,拆分出來了一張表
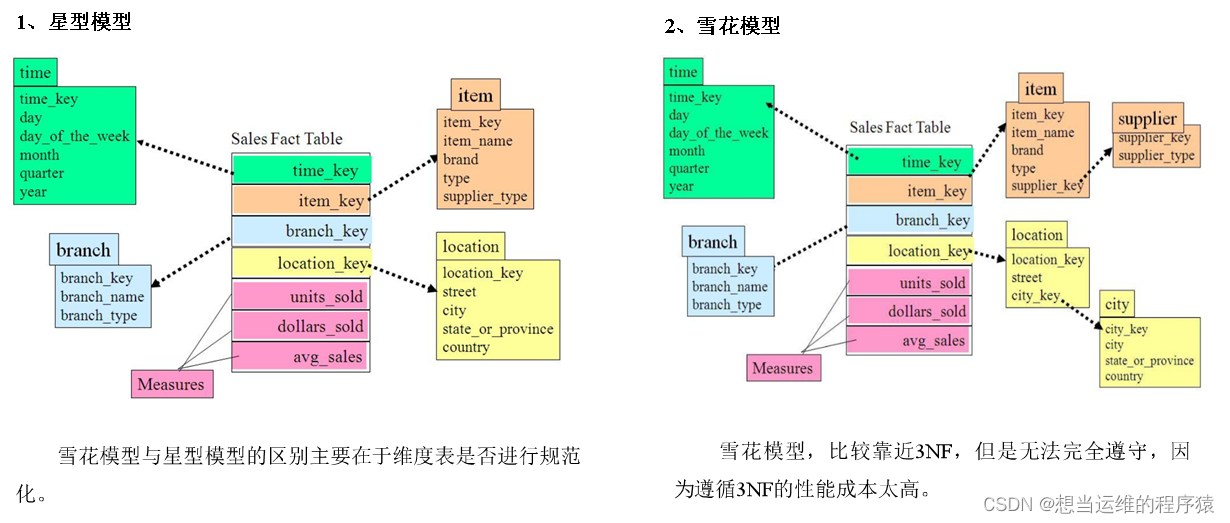
數據倉庫系統的主要目的是用于數據分析和統計,所以是否方便用戶進行統計分析決定了模型的優劣。采用雪花模型,用戶在統計分析的過程中需要大量的關聯操作,而采用星型模型,則方便、易用且性能好。所以出于易用性和性能的考慮,維度表一般是很不規范化的。
1.4 維度表的變化
維度屬性是會隨時間變化的,比如客戶的手機號。
保存維度數據的歷史狀態,通常有以下兩種做法,分別是全量快照表和拉鏈表。
全量快照表
離線數據倉庫的計算周期通常為每天一次,所以可以每天保存一份全量的維度數據。
優點: 簡單有效,方便理解和使用
缺點: 浪費存儲空間,尤其是當數據的變化比例比較低時。
拉鏈表
拉鏈表,記錄每條信息的生命周期,一旦生命周期結束,就重新開始一條新的記錄,把當前日期放入生效開始日期,如果當前信息至今有效,在生效結束日期中填入一個極大值(如9999-12-31)。
該方式更加高效的保存維度信息的歷史狀態。
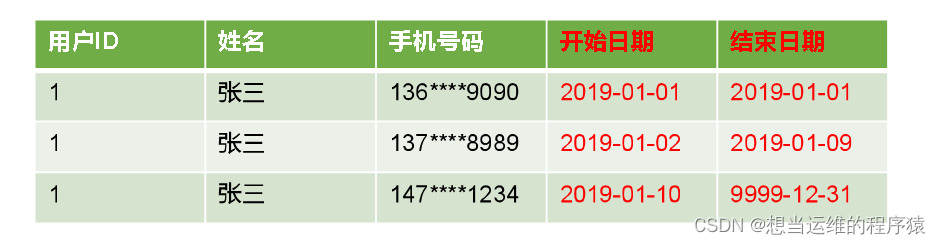
拉鏈表適合于:數據會發生變化,但是變化頻率不高的維度。
二、數據的同步策略
數據的同步策略有全量同步和增量同步
2.1 全量同步
全量同步,就是每天都將業務數據庫中的全部數據同步一份到數據倉庫,這是保證兩側數據同步的最簡單的方式。
2.2 增量同步
增量同步,就是每天只將業務數據中的新增及變化數據同步到數據倉庫。采用每日增量同步的表,通常需要在首日先進行一次全量同步。
通常維度表使用全量同步,事實表使用增量同步
| 表 | 同步策略 |
|---|---|
| 事務事實表 | 增量同步 |
| 周期快照事實表 | 全量同步 |
| 累計快照事實表 | 增量同步 |
| 維度表中的全量快照表 | 全量同步 |
| 維度表中的拉鏈表 | 增量同步 |
三、數倉設計
1.1 數倉分層規劃
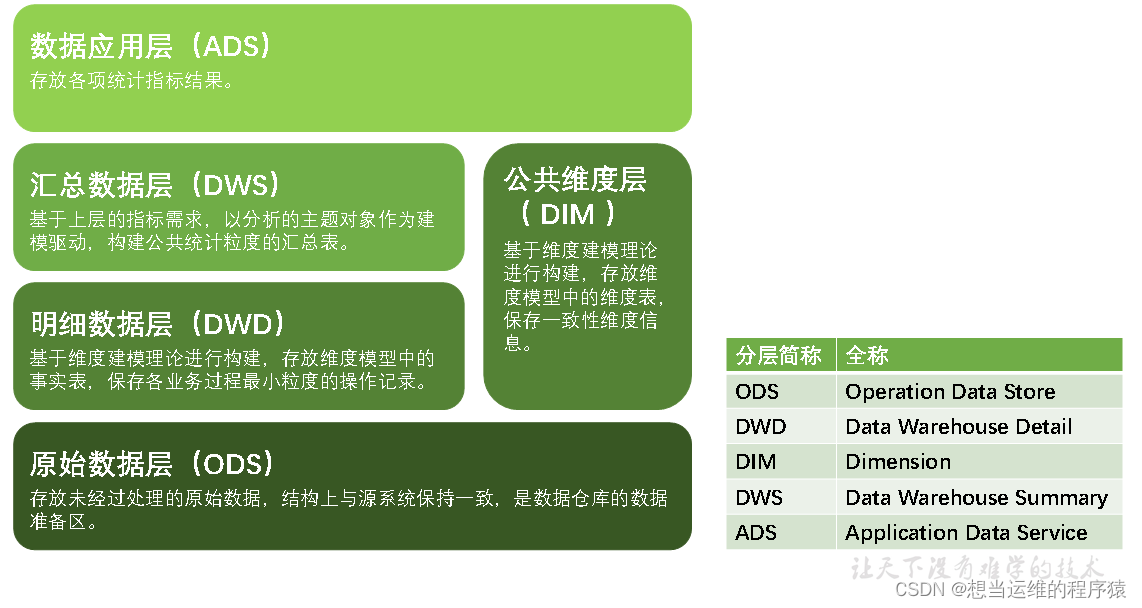
維度建模的事實表存放在DWD層,維度表存放在DIM層
1.2 數倉構建流程
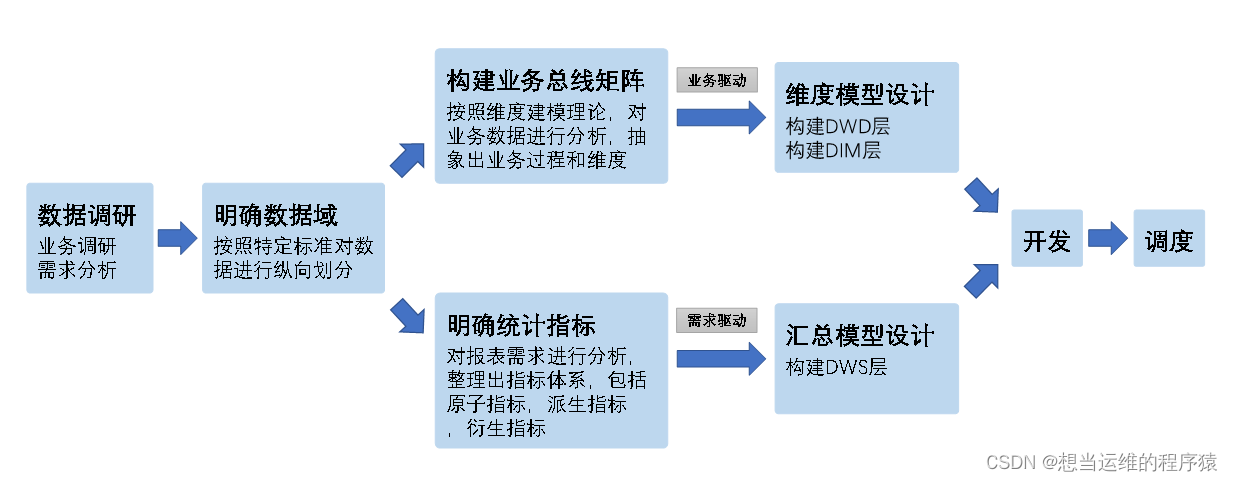
數據倉庫模型設計除橫向的分層外,通常也需要根據業務情況進行縱向劃分數據域。
劃分數據域的意義是便于數據的管理和應用。
通常可以根據業務過程或者部門進行劃分。
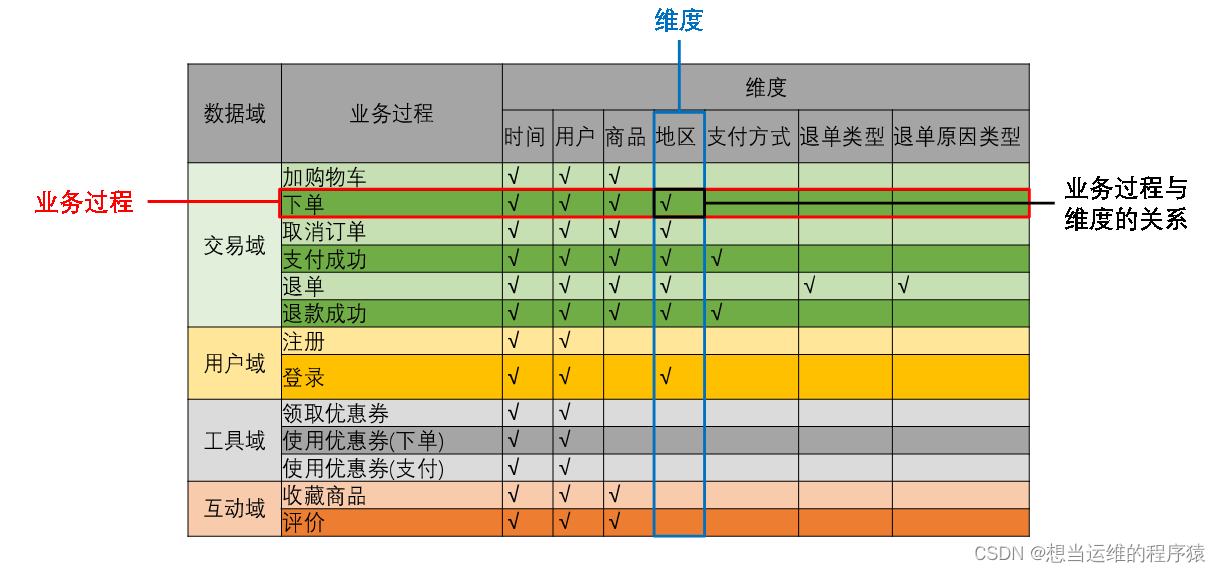
1.3 業務總線矩陣
業務總線矩陣中包含維度模型所需的所有事實(業務過程)以及維度,以及各業務過程與各維度的關系。
矩陣的行是一個個業務過程,矩陣的列是一個個的維度,行列的交點表示業務過程與維度的關系。



![[基礎IO]文件描述符{C庫函數\系統接口\初識fd}](http://pic.xiahunao.cn/[基礎IO]文件描述符{C庫函數\系統接口\初識fd})






)
——Dueling Network(DQN改進))


)




