Go json 差異比較 json-diff(RFC 6902)
畢業設計中過程中為了比較矢量圖的差異而依據 RFC 6902 編寫的一個包,現已開源: Json-diff
使用
go get -u github.com/520MianXiangDuiXiang520/json-diff
序列化與反序列化
與官方 json 包的序列化和反序列化不同,官方包序列化需要指定一個 interface{}, 像:
package mainimport "json"func main() {jsonStr := "{}"var jsonObj interface{}node := json.Unmarshal(&jsonObj, []byte(jsonStr))// ...
}
json-diff 可以將任意的 json 串轉換成統一的 JsonNode 類型,并且提供一系列的增刪查改方法,方便操作對象:
func ExampleUnmarshal() {json := `{"A": 2,"B": [1, 2, 4],"C": {"CA": {"CAA": 1}}}`jsonNode := Unmarshal([]byte(json))fmt.Println(jsonNode)
}
差異比較
通過對比兩個 Json 串,輸出他們的差異或者通過差異串得到修改后的 json 串
func ExampleAsDiffs() {json1 := `{"A": 1,"B": [1, 2, 3],"C": {"CA": 1}}`json2 := `{"A": 2,"B": [1, 2, 4],"C": {"CA": {"CAA": 1}}}`res, _ := AsDiffs([]byte(json1), []byte(json2), UseMoveOption, UseCopyOption, UseFullRemoveOption)fmt.Println(res)
}
func ExampleMergeDiff() {json2 := `{"A": 1,"B": [1, 2, 3, {"BA": 1}],"C": {"CA": 1,"CB": 2}}`diffs := `[{"op": "move", "from": "/A", "path": "/D"},{"op": "move", "from": "/B/0", "path": "/B/1"},{"op": "move", "from": "/B/2", "path": "/C/CB"}]`res, _ := MergeDiff([]byte(json2), []byte(diffs))fmt.Println(res)
}
輸出格式
輸出一個 json 格式的字節數組,類似于:
[{ "op": "test", "path": "/a/b/c", "value": "foo" },{ "op": "remove", "path": "/a/b/c" },{ "op": "add", "path": "/a/b/c", "value": [ "foo", "bar" ] },{ "op": "replace", "path": "/a/b/c", "value": 42 },{ "op": "move", "from": "/a/b/c", "path": "/a/b/d" },{ "op": "copy", "from": "/a/b/d", "path": "/a/b/e" }]
其中數組中的每一項代表一個差異點,格式由 RFC 6092 定義,op 表示差異類型,有六種:
add: 新增replace: 替換remove: 刪除move: 移動copy: 復制test: 測試
其中 move 和 copy 可以減少差異串的體積,但會增加差異比較的時間, 可以通過修改 AsDiff() 的 options 指定是否開啟,options 的選項和用法如下:
// 返回差異時使用 Copy, 當發現新增的子串出現在原串中時,使用該選項可以將 Add 行為替換為 Copy 行為// 以減少差異串的大小,但這需要額外的計算,默認不開啟UseCopyOption JsonDiffOption = 1 << iota// 僅在 UseCopyOption 選項開啟時有效,替換前會添加 Test 行為,以確保 Copy 的路徑存在UseCheckCopyOption// 返回差異時使用 Copy, 當發現差異串中兩個 Add 和 Remove 的值相等時,會將他們合并為一個 Move 行為// 以此減少差異串的大小,默認不開啟UseMoveOption// Remove 時除了返回 path, 還返回刪除了的值,默認不開啟UseFullRemoveOption
相等的依據
對于一個對象,其內部元素的順序不作為相等判斷的依據,如
{"a": 1,"b": 2,
}
和
{"b": 2,"a": 1,
}
被認為是相等的。
對于一個列表,元素順序則作為判斷相等的依據,如:
{"a": [1, 2]
}
和
{"a": [2, 1]
}
被認為不相等。
只有一個元素的所有子元素全部相等,他們才相等
原子性
根據 RFC 6092,差異合并應該具有原子性,即列表中有一個差異合并失敗,之前的合并全部作廢,而 test 類型就用來在合并差異之前檢查路徑和值是否正確,你可以通過選項開啟它,但即便不使用 test,合并也是原子性的。
json-diff 在合并差異前會深拷貝源數據,并使用拷貝的數據做差異合并,一旦發生錯誤,將會返回 nil, 任何情況下都不會修改原來的數據。
實現
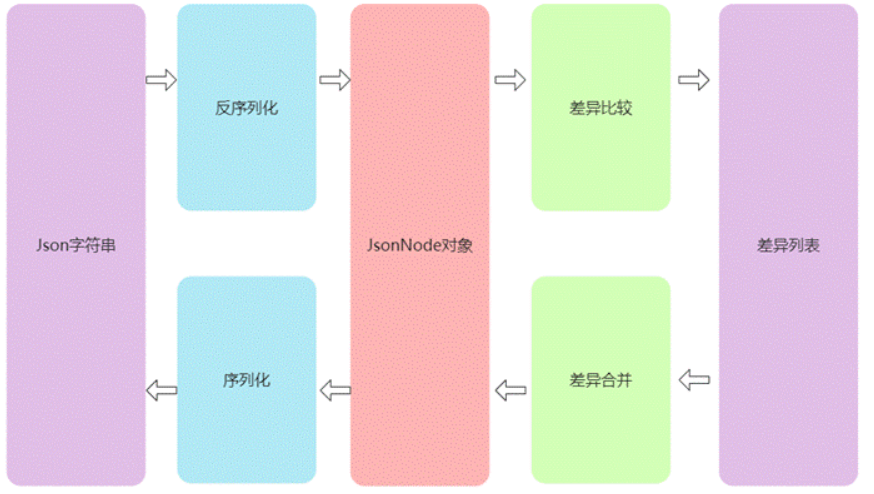
本章節主要介紹Json-Diff 算法以及完整實現過程,該算法包含三部分內容,分別是用來序列化和反序列化Json 字符串的格式化模塊;用于比較兩個Json字符串差異的差異比較模塊,用于合并差異的差異合并模塊,三個模塊的關系如下圖4.1所示:
格式化
Json 的特點
Json 全稱JavaScript Object Notation[12](JavaScript對象標記法)是一種輕量級的數據交換格式,一般以文本的形式存儲或傳輸,具有較高的可讀性,它有構造字符,值,空白符組成,其中,構造字符有六個,分別是:“{”, “}”, “[”, “]”, “,”和“:”.Json中值也有六種,分別是數字,布爾,字符串,列表,對象和null, 此外構造字符前后允許多個空白符,他們沒有任何意義,主要用于提高可讀性,這些空白符包括回車,換行,空格,制表。
Json的六種值中,數字,字符串,布爾和null是四個基本類型,列表和對象由這些基本類型組合而成,其中,數字類型可以包括正數,負數,虛數,小數等,也可以使用科學計數法表示,如“2e3”;字符串類型由一對英文引號包圍,可以是單引號也可以是雙引號,但不能使用反引號 “`”;布爾包括兩個值true和false,區分大小寫;null 類似于布爾,屬于內建類型,表示空。
Json中對象由“{}”表示,對象中的每一項由鍵,值和構造字符“:”組成,其中鍵必須是字符串類型,而值可以是六種值中的任意一種,鍵值之間使用構造字符“:”連接,同一對象中的多個鍵值對之間使用構造字符“,”分隔,如果某鍵值對是該對象中的最后一項,值后面則不允許使用“,”一個典型的“對象”如下所示:
{"a": 1e2,"b": "1e2","c": false,"d": null,"e": {},"f": []
}
值得注意的是對象中的鍵值對是無序的,如{"a":1, "b":2}和{"b":2, "a":1}被認為是相等的。
Json中列表由[]表示,列表中的元素同樣可以是六種值中的任意一種,值與值之間使用構造字符,分隔,最后一個值不允許攜帶,一個典型的列表如下所示:
[1e2, "1e2", false, null, {}, []]
列表中的元素是有序的,也就是說“[1, 2]”和“[2, 1]”是不相等的。
反序列化
Json本質上來說就是一種特殊格式的字符串,要想得到兩個Json串的差異,最簡單的辦法就是一一對比兩個字符串每一位上的字符,但這種算法無法利用Json的有序性,可能導致得到的差異列表過大,甚至可能超過原Json串,適得其反,并且逐一比較也會導致過高的時間復雜度,浪費大量時間。因此需要將Json字符串轉換為特定的數據結構,再遞歸比較對象的每個鍵值對。
根據上面的介紹,不難發現,Json是一個樹型結構,對象({})和列表([])構成了這棵樹的非葉子節點,他們可以包含一個和多個子節點,每個子節點由鍵和值組成(列表的鍵可以看作是下標);而字符串,數值,布爾,null等無法包含子節點的對象構成了這棵樹的葉子節點(空的列表或對象也可以作為葉子節點)。
因此,本系統Json對象分成三類:Object,Slice和Value,分別用來表示對象,列表及其他類型的值,這三類都由JsonNode類派生而來,他們的公共屬性包括:
-
Type: uint8類型,用來標識該節點的類型。
-
Hash: 該節點的哈希值,第一次比較到該節點時,會遞歸計算該節點包括其所有子節點的哈希值,到第二次需要比較該節點時,只需要比較其哈希值即可。
-
Value: 該節點的值,類型是interface{},因此可以用來存儲六種值類型中的任意一種。
-
Level: 該節點在整顆Json樹中所處的層級。
-
Key: 用來保存該值對應的Key,可為空。
除此之外,Object類型的節點還包含ChildrenMap字段,它的類型為map[string]interface{},用來存儲該節點的所有子節點,其中,Object的Key作為ChildrenMap的Key, Object的Value作為ChildrenMap的Value,由于Go中的map本身是無序的,正好對應Json的Object無序的特點,且map底層使用的是開放地址的哈希表,因此其查詢效率是O(1), 這將大大提高比較的速度。:
類似的,Slice類型的節點也包含Children字段,其類型為[]interface{}, 用來表示列表中的所有子元素,由于Go中的切片([]interface{})是有序的,正好可以滿足Json數組有序的要求。
為了方便后續的差異比較和差異合并,JsonNode還提供了一系列增刪查改的方法,如下:
-
Find: 用來根據路徑找到對應的節點,它接收一個字符串類型的路徑,并返回一個JsonNode對象的引用,如果找不到,返回nil.
-
Add: 如果該節點是Object或Slice類型,Add將一個新的節點作為其子節點。
-
Replace: 接收一組key和value, 用來將該節點下key對應的值替換為value并返回舊值,如果當前節點是Object類型,key應該是string類型,如果當前節點是Slice類型,key應該是int類型,用來表示要替換的值的下標,如果沒找到對應的值,返回一個Not Find異常。
-
Remove: 刪除當前 JsonNode 中 key 對應的節點并返回被刪除的值,該方法只能刪除父節點的某個子節點,節點不能刪除它自己,因此,Value類型的節點不能使用 Remove 方法。
-
Equal: 用來判斷給定的JsonNode是否與當前節點相等。
? 除了上面這五個JsonNode的方法外,為了方便對JsonNode進行操作,還提供了下面幾個公共函數:
-
CopyPath: 接受兩個string類型的path1和path2,用來將path1對應的值復制到path2.
-
MovePath: 接受兩個string類型的path1和path2,用來將path1對應的值移動到path2.
-
ATestPath: 用來判斷給定路徑處的值是否等于給定的值。
-
AddPath: 用來給某個路徑對應的值添加一個新節點。
-
ReplacePath: 用一個新值替換源路徑對應的值。
-
RemovePath: 用來刪除某路徑對應的值。
以上六個函數實質上是對JsonNode五個基本方法的進一步封裝,但在減少后續工作代碼量,提高代碼可讀性和降低系統復雜度上,他們起了重要作用。
反序列化具體實現
Go語言官方本身提供了一個Json序列化和反序列化的包json, 但它只能將Json字符串反序列化為一個已知的對象或map,且無法對序列化好的對象進行操作,由于本系統的Json都是動態生成的,無法用確定的數據結構來表示,同時本系統需要對反序列化后的對象進行大量操作,因此官方的json包不能滿足要求,本系統的反序列是在使用官方包將json字符串轉換為map后,對該map對象進行遍歷得到的,首先介紹官方json包反序列化的規則:
-
對象會被轉換為map[string]interface{}
-
數組會被轉換為[]interface{}
-
數值會根據具體值轉化為int或float
-
布爾會轉換為bool
-
Null會轉換為nil
-
字符串會轉換為string
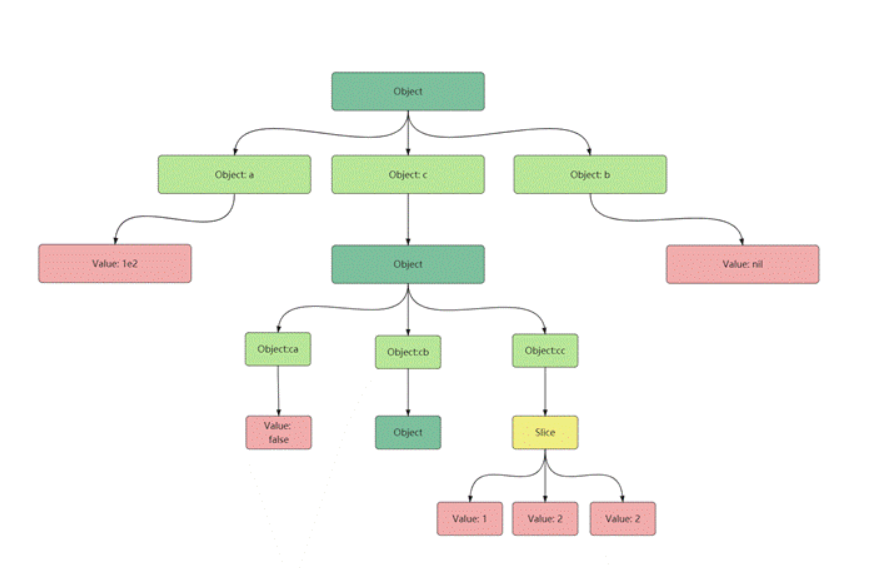
? 由于每個Json都是一個對象,所以最終的轉換結果就是一個map,如下面這個json字符串:
{"a": 1e2,"d": null,"c": {"ca": false,"cb": {},"cc": [1, "e", {}]},
}
? 就會被轉換為:
map[a:100 b:<nil> c:map[ca:false cb:map[] cc:[1 e map[]]]]
? 然后通過遍歷該map內的所有元素,就可以將其轉換為我們需要的JsonNode對象,具體parse方法如下:
? 如果遍歷到map類型的元素,就建立一個Object類型的節點root,并再遍歷該map內的所有元素,對每一個遍歷到的元素遞歸調用parse方法,將得到的的JsonNode作為root的一個子節點。
? 如果遍歷到slice類型的元素,就建立一個Slice類型的節點root,同樣對切片內的每一個元素遞歸調用parse, 將得到的節點追加到root的Children里。
? 否則,如果遍歷到的元素不屬于上面兩種,就建立一個Value類型的節點,將值保存到該節點的Value中,并將該節點添加到其父節點的ChildrenMap中。
? 如上面的例子經過parse就會轉化成如圖4.2的樹:
序列化
序列化相比反序列簡單的多,它的目的是將JsonNode對象轉換為Json字符串,實現的具體思路是先將JsonNode對象轉換為map,再使用官方的json包實現序列化,JsonNode轉map主要還是使用遞歸的思想,主要由三個函數實現,其中前兩個是遞歸函數:
-
marshalObject:用來將一個Object類型的節點序列化成map,他會先創建一個新map,然后遍歷該節點的ChildrenMap,然后根據子節點的類型調用對應的序列化函數,比如遍歷到Object類型的節點,就遞歸調用 marshalObject,如果遍歷到Slice類型,就調用marshalSlice得到序列化后的結果,并將其保存在新創建的map中。
-
marshalSlice:與marshalObject類似,它會新創建一個slice, 然后遍歷該節點的Children, 對其中的每一個子節點根據節點類型調用不同的方法得到序列化后的結果并將之保存在slice中。
-
marshalValue: 用于將Value類型的節點序列化,由于Value類型沒有子節點,只需要返回JsonNode.Value即可。
路徑轉義
在本系統設計中,使用斜杠“/”作為路徑分隔符,如“/a/b/1”表示從根節點出發,找到其key為a的子節點,再找到子節點的key為b的子節點,再找到該孫子節點的key(或下標,取決于孫子節點是Object類型還是Slice類型)為1的節點。但Json自身沒有限制key中的特殊字符,也就是 { " a/b":1}是完全合法的,為了避免原來key中包含斜杠導致分隔錯誤,需要對原Json字符串中的Key做轉移,具體做法如下:
將原來Key中包含的所有斜杠轉義為~1,將原來Key中包含的~1全部轉義為~01,原來的~01轉義為~001……每次轉義都添加一個0,比如原來有一個Key為a/~01b就會被轉義為a~1~001b,在最后差異合并時,只需要去掉0即可得到原來的Key,具體實現比較簡單,可以使用正則匹配加字符串替換實現。
格式化總結
本系統的格式化模塊包含序列化和反序列化兩個子模塊,提供了兩個公共方法:Unmarshal和Marshal,分別用于將Json字符串轉換為JsonNode對象和將JsonNode對象轉換回Json字符串,JsonNode對象提供了許多方法以實現對Json的動態修改,方便后續操作。
差異比較
差異比較是基于上一章節的反序列化實現的,其核心工作是比較兩個JsonNode對象src(表示原Json串)和tar(表示改變后的Json串)的差異,并輸出一個Json格式的差異報告告訴用戶tar可以在src的基礎上進行了些操作后得到。,本章節將從輸出格式以及比較算法兩個方面介紹差異對比模塊的具體實現。
輸出格式
首先為了降低Diff算法的可移植性,該系統同樣使用Json作為最終的輸出格式,由于每次比較會有多個差異,所以輸出結果應該是一個列表,列表中的每一項表示一處差異,類似于下面這樣 [{}, {}, {}, {}, {}] 表示比較后得到了五處差異, 每一項中應該包含以下內容:
-
Op: 表示差異類型;可選值有add, remove, replace, copy, move, test六種;對一個數據的操作無非增、刪、查、改四種,而對于差異比較來說,定義增、刪、改三種操作即可,在此基礎上,添加拷貝和移動兩種復合操作,但他們可以使用增和先增后刪表示,但使用復合操作可以進一步減少最終輸出的數據量。除此之外 test 用于保證后面差異合并時的原子性,會在下一章節介紹。
-
Path:表示差異發生的位置,Path是針對src而言的。
-
Value:主要用于增加和修改操作,用來表示新增的值和要修改的新值,Test也會攜帶該字段,主要用來比較,保證原子性;另外,刪除操作如果攜帶該參數表示被刪除的值。
-
From:用于拷貝和移動操作,表示被拷貝或移動的數據來自哪個路徑。
? 所以,差異比較后的輸出應該類似于下面這樣:
[{ "op": "add", "path": "/a/b/c", "value": "{}" },{ "op": "remove", "path": "/a/b/c" },{ "op": "raplace", "path": "/a/b/c", "value": {} },{ "op": "move", "from": "/a/b/c", "path": "/a/b/d" },{ "op": "copy", "from": "/a/b/d", "path": "/a/b/e" }{ "op": "test", "path": "/a/b/c", "value": {"d": 1} }
]
實現概述
本系統提供一個公共函數AsDiff,他接受src和tar兩個Json比特串和一組控制選項,并且返回兩個值res和error 分別表示差異比較結果和過程中發生的錯誤,正常情況下,error應該是空的(nil),一旦比較過程出現異常,就會將異常作為返回值返回,而res會被置為nil.
能夠傳入的控制參數有四個,分別是:
-
UseCopyOption:啟用Copy,如果傳入該參數,差異比較后會遍歷整個結果集中的add操作,如果該操作對應的值能在src中找到,就使用copy替代該add操作,啟用該選項會減少結果集大小但也會增加差異比較的時間,默認不開啟。
-
UseCheckCopyOption:僅在Copy選項開啟時有效,他會在Copy操作前插入一條Test操作,表示合并時檢查值是否相等,只有值相等才繼續合并。
-
UseMoveOption:啟用Move,如果傳入該選項,差異比較結束后會遍歷所有的add和remove操作,如果找到add的值和remove的值相等,則使用move替換add操作,并刪除remove操作,該選項同樣是以時間換空間,開啟后會減少結果集大小,但同樣會增加比較時間,默認不開啟。
-
UseFullRemoveOption:開啟該選項后,remove操作將攜帶value,表示被刪除的值,開啟后會增加結果集大小,默認不開啟。
使用者可以權衡業務數據的特點選擇是否開啟這四個選項。
AsDiff會對接收到的src和tar做反序列化,然后調用GetDiffNode對兩個JsonNode對象做差異比較,GetDiffNode方法調用了diff做差異比較,并根據可選選項對結果集做進一步處理,所以diff方法是差異比較的核心,diff首先會進行邊界條件的判斷,如src和tar中src為空對象,但tar不為空,就可以直接得出并返回add操作,反之,如果src不為空,tar為空,也可以直接得出并返回remove操作,如果兩者都為空,也可以斷言未發生任何修改,應該返回空的結果集;如果二者都不為空,則使用下面的策略具體比較二者差異:
-
如果二者都是Object類型,調用diffObject方法比較差異。
-
如果二者都是Slice類型,調用diffSlice方法比較差異。
-
如果二者都是Value類型,判斷值是否相等,如果不相等,則產生一個replace操作,并將其追加到結果集中。
-
如果二者類型不相等,直接生成一個replace操作,值為tar的值。
diffObject和diffSlice是兩個遞歸函數,他們會根據不同的策略遞歸調用diff來比較其中的子節點,直到得出最終的結果。
而對可選選項的處理會在doOption函數中完成,后續章節會介紹這三個主要函數的具體實現。
Object差異比較
兩個Object類型節點的差異比較由遞歸函數diffObject實現,diffObject首先會遍歷src中的每一組鍵值對,然后根據遍歷到的鍵去tar的ChildrenMap中找tar中該鍵對應的值,如果沒找到,則說明tar之于src刪除了該鍵值對;如果找到,則判斷兩個節點是否相等,不相等再根據值得類型遞歸調用diff比較值的差異,遍歷完src之后,會同樣遍歷一遍tar的ChildrenMap, 如果src的子節點中沒有找到該Key, 則說明tar之于src通過add操作增加了值。不同的是,遍歷tar時不需要判斷兩個節點是否相等,也不需要遞歸調用diff進行比較。也就是說,通過遍歷src,可以找到關于這個節點的所有刪除和更新操作,而遍歷tar可以找到關于這個節點的所有添加操作。
Slice差異比較
Slice類型的節點比較需要考慮順序,考慮到會出現下面這種情況:
Src: [1, 2, 3, 4, 5]Tar: [1, 3, 4, 5]
如果繼續按照Object類型比較的思路,從左到右逐一遍歷比較,那么得到的差異結果就是第一位由2變成了3,第二位由3變成了4,第三位由4變成了5,刪除了第五位。即便是開啟move選項,差異結果也會包含四條記錄,但實際上,上面的例子可以直接看作刪除了第一位,這樣差異結果只包含一條記錄,可以大大減少結果集的大小。除此之外,Slice的子節點使用列表存儲,列表查詢時間復雜度為O(n), 如果繼續采用Object的比較方法,總復雜度會達到O(n2),為此,本系統在比較Slice類型的節點時,會先使用動態規劃[16]求出兩個節點Children的最長公共子序列[17][18]lcsNodes, 然后根據該序列再與src和tar對比得到最終差異數據,具體方法如下:
一個序列的子序列是指在不改變原序列中元素順序的情況下從原序列中刪除零個或多個元素所得到的子序列,如有原序列S1={1, 2, 3, 4},在不改變順序的情況下從中刪除第一號元素后得到新的序列S2={1, 3, 4},那么就說S2是S1的一個子序列,而S3={2, 1, 4}由于改變了元素順序,所以S3不是S1的子序列;最長公共子序列是指給定兩個序列L1,L2,分別設他們的全部子序列集合為S1和S2,那么L1,L2的最長公共子序列LCS就是S1和S2的交集中元素個數最多的那個,記為:
KaTeX parse error: Undefined control sequence: \and at position 15: LCS = Max(S1 \?a?n?d? ?S2)
求兩個序列最長公共子序列一般使用動態和規劃法,之所以可以使用動態規劃,是基于該問題的以下特征:
設給定兩個序列A={a1, a2, …, an}和B={b1, b2, …, bm},他們的最長公共子序列為S={s1, s2, …, sk}那么:
-
若an=bm 則an=sk=bm且必定存在S2={s1, …, sk-1} 是序列A2={a1, …, an-1}和序列B2={b1, …, bm-1}的最長公共子序列。
-
若an!=bm且an!=sk則S必然是序列A2={s1, …, sk-1}和序列B={b1, b2, …, bm}的最長公共子序列。
-
若an!=bm且bm!=sk則S必然是序列A={a1, a2, …, an}和序列B2={b1, …, bm-1}的最長公共子序列。
? 根據上面三條特征,可以發現兩個序列的最長公共子序列實質上是他們子串的最長公共子序列再加上剩余的公共元素組成的,因此該問題可以轉換為求兩個序列子串的最長公共子序列的子問題,這使得該問題具備了動態規劃的重疊子問題和最優子結構的性質[16],其狀態轉移方程如下所示:
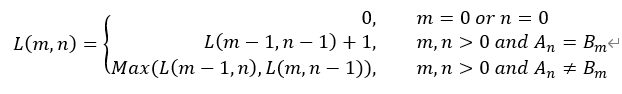
其中,AB表示要求解的兩個序列,m, n表示兩個序列的長度,An (Bm)表示序列A (B) 中從第0位到第n (m)位的子串;L(m, n)表示An和Bm的最長公共子序列的長度。
假設序列A, B 分別為{1, 2, 3, 4, 5, 9}和{1, 3, 5, 7, 8},根據以上狀態轉移方程,可得如表4.1所示的DP數組:
表4.1 DP數組
| 1 | 2 | 3 | 4 | 5 | 9 | |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 2 | 2 | 2 | 2 |
| 5 | 1 | 1 | 2 | 2 | 3 | 3 |
| 7 | 1 | 1 | 2 | 2 | 3 | 3 |
| 8 | 1 | 1 | 2 | 2 | 3 | 3 |
數組中的元素DP[i][j]就表示L[i][j], 最后一個元素表示的就是要求的兩個序列的最長公共子序列的長度,根據DP數組中每一位都表示其對應兩個子串的最長公共子序列,所以,設右下角的坐標為只需要從DP數組的右下角按以下規則尋找即可找到原序列的最長公共子序列:
-
若DP[x] [y]等于DP[x-1] [y]且DP[x] [y]等于DP[x] [y-1],如上例中的(4, 5)位置,說明8和9都不屬于最終的公共子序列,則沿對角線向上移動(x和y都減1)。
-
若DP[x] [y]等于DP[x-1] [y]但DP[x] [y]不等于DP[x] [y-1],則向上移動(x減1)
-
若DP[x] [y]不等于DP[x-1] [y]但DP[x] [y]等于DP[x] [y-1],則向左移動(y減1)
-
若DP[x] [y]不等于DP[x-1] [y]且DP[x] [y]不等于DP[x] [y-1],如上例(0, 1), (1, 2)和(2, 3)位置,說明他們對應的1,3,5是最終的公共子序列,只不過這樣得到結果的順序正好是反著的,需要在返回時反轉一遍。
找出最長公共子序列后,就可以對比src, tar以及lcs得出兩個Slice類型節點的差異了:
把節點Children中的子節點抽象為簡單的數字,假設比較的兩個節點的值分別為src=[1, 2, 3, 4, 5]和tar=[1, 3, 4, 5, 6],那這兩者計算得到的lcs=[1, 3, 4, 5], 使用三個指針同時從頭遍歷src, tar和lcs如果三個指針對應的值都相等,則說明該對象未發生改變,三個指針同時向后移動一位,如果lcs指針與src指針對應的值相等,但與tar對應的值不相等,說明tar在src的基礎上插入了一個新值,就往結果集中添加一條add操作,同時lcs和src指針保持不變,tar指針向后移動一位;如果lcs指針對應的值和tar指針對應的值相等但與src對應的不相等,說明tar在src的基礎上刪除了一個值,就往結果集中插入一條刪除操作,同時src指針向后移動一位,直到lcs遍歷結束。由于lcs的長度一定小于或等于src或tar的長度,lcs遍歷完后src和tar中可能還有未被遍歷到的子節點,如果src和tar中都有沒被遍歷的值,那就可以看作是修改操作,如果src中沒遍歷的節點數多于tar中的,那多出來就可以看作是被刪除的,反之少的就可以看作是新添加的
Value差異比較
前面的diffObject和diffSlice對比的只是子節點的差異,但子節點的比較最終會落在具體值的比較上,Value的差異比較只涉及修改,不涉及增刪,只需要判斷二者值是否相等,不相等即是產生了修改操作,在diff函數中實現。
Copy和Move合并
如果在執行AsDiff時傳入了Copy和Move選項,差異比較結束后還要遍歷整個結果集,看是否有操作可以合并成Copy或Move。
Copy合并是看結果集中add操作的value是否可以使用一個路徑替換,為此必須找到兩個Json串中未被修改的部分,然后看每一個add操作的value是否可以在這個未被修改的序列中找到,尋找未修改部分的過程與Object差異比較的過程類似,尋找Slice中未改變的節點時,必須考慮后續操作對路徑的影響,因此不能像Slice差異比較那樣使用最長公共子序列,只能按下標一一對比。找到未修改的序列后,遍歷結果集中的add操作就可以找到可以使用Copy替換的操作了。
Move合并是看結果集中是否有刪除操作的值和添加操作的值相等,只需要兩重循環遍歷兩種操作類型的值即可,在這過程中,可以對一方的值做哈希,然后以哈希值為key建立緩存,比較前先查詢緩存,判斷是否能找到,命中后再去比較具體的值,以此降低時間復雜度。
差異比較總結
差異比較主要用于找到兩個Json串之間的差異,并輸出一個標準的比較結果,主要由差異比較和結果集合并兩部分組成,前者用來找到兩個Json串中基本的增刪改操作,后者根據可選選項將可能的增刪合并為Copy和Move。
差異合并
差異合并主要是根據原Json串和通過差異比較得到的差異列表還原出修改后的串,他需要滿足順序性、準確性和原子性的要求,所謂順序性和準確性是指合并的過程應該嚴格按照差異列表中的操作順序執行,保證結果的正確性,而原子性是要求合并過程中一旦有一個操作出錯,那整個合并過程應該立刻停止并將原串還原到執行合并前的狀態。
由于輸入的差異列表本來就是一個有序列表,所以順序性和準確性很容易保證,這部分功能實現主要依賴于JsonNode對象的一系列怎刪改查方法,這些方法在本章第一節已經有所介紹,不再贅述。而為了保證原子性,就不能直接對原串進行修改,需要復制一份原串的副本,然后對該副本進行修改,一旦發生錯誤,就返回原串丟棄副本,而如果一帆風順,也只需要使用副本覆蓋原串即可。
深拷貝的母的是得到與原來JsonNode完全一致的一份副本,一般深拷貝都使用序列化再反序列實現,具體就是先將對象序列化成json或其他中間格式,再將中間格式反序列化出一個新對象,這種做法的優點是實現簡單,代碼量少且適用性強,缺點是速度慢,考慮到本項目中深拷貝只用于拷貝JsonNode對象,不需要很強的適用性,為了更好的性能,本系統通過深度優先遍歷逐一復制每一個子節點,為JsonNode對象實現了一個專用的深拷貝方法,
總結
Json-Diff主要由格式化,差異比較,差異合并三個模塊組成:
格式化模塊按照Json的特點將其中的對象分為Object, Slice和Value三種,前兩者包含子對象,Object中的子對象無序,Slice中的子對象有序,并且將這三種對象都抽象為統一的JsonNode對象;在官方json包的基礎上,格式化模塊提供了序列化和反序列化方法,用于實現Json字符串和JsonNode對象之間的互相轉換。
差異比較模塊根據節點類型的不同,使用不同的比較策略,針對Object和Slice類型,只比較他們的子節點,由于Object無序,可以使用哈希表存儲,比較時根據key獲取value比較即可,Slice是有序的,暴力比較會導致很高的時間復雜度和很龐大的輸出,因此先通過動態規劃求出LCS,再遍歷LCS得到最后的差異列表。
差異合并主要使用JsonNode的增刪查改方法,為了保證原子性,實現了一個基于DFS的深拷貝方法,合并差異時先合并到拷貝的副本上,中途一旦出錯,就丟棄副本返回原Json串,如果全部合并成功,再使用副本覆蓋原串。
參考
https://github.com/flipkart-incubator/zjsonpatch

)
:集成 Spring Security (上))

用eNSP實驗來認識什么是OSPF及OSPF配置?)








)
移植LVGL官方的例程(還沒寫完,有問題 排查中))

)


