一、Softmax回歸關鍵思想
1、回歸問題和分類問題的區別
? ? ? ?Softmax回歸雖然叫“回歸”,但是它本質是一個分類問題。回歸是估計一個連續值,而分類是預測一個離散類別。

2、Softmax回歸模型
???????Softmax回歸跟線性回歸一樣將輸入特征與權重做線性疊加。與線性回歸的一個主要不同在于,Softmax回歸的輸出值個數等于標簽里的類別數。比如一共有4種特征和3種輸出動物類別(貓、狗、豬),則權重包含12個標量(帶下標的),偏差包含3個標量(帶下標的
),且對每個輸入計算
這三個輸出:
最后,再對這些輸出值進行Softmax函數運算。
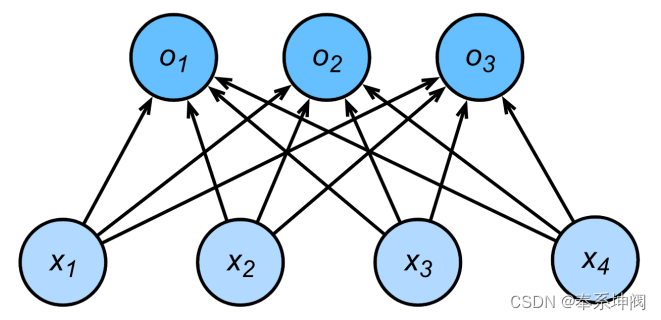
???????softmax回歸同線性回歸一樣,也是一個單層神經網絡。由于每個輸出的計算都要依賴于所有的輸入
,所以softmax回歸的輸出層也是一個全連接層。
3、Softmax函數
???????Softmax用于多分類過程中,它將多個神經元的輸出(比如)映射到(0,1)區間內,可以看成概率來理解,從而來進行多分類!它通過下式將輸出值變換成值為正且和為1的概率分布:
其中:
,?
,?
???????容易看出??且?
,因此?
?是一個合法的概率分布。此外,我們注意到:
?因此softmax運算不改變預測類別輸出。
? ? ? ?下圖可以更好的理解Softmax函數,其實就是取自然常數e的指數相加后算比例,由于自然常數的指數()在
單調遞增,因此softmax運算不改變預測類別輸出。

4、交叉熵損失函數
? ? ? ?假設我們希望根據圖片動物的輪廓、顏色等特征,來預測動物的類別,有三種可預測類別:貓、狗、豬。假設我們當前有兩個模型(參數不同),這兩個模型都是通過sigmoid/softmax的方式得到對于每個預測結果的概率值:
模型1:
| 模型1 | |||||||
|---|---|---|---|---|---|---|---|
| 預測 | 真實 | 是否正確 | |||||
| 0.3 | 0.3 | 0.4 | 0 | 0 | 1 | 豬 | 正確 |
| 0.3 | 0.4 | 0.3 | 0 | 1 | 0 | 狗 | 正確 |
| 0.1 | 0.2 | 0.7 | 1 | 0 | 0 | 貓 | 錯誤 |
???????模型評價:模型1對于樣本1和樣本2以非常微弱的優勢判斷正確,對于樣本3的判斷則徹底錯誤。
模型2:
| 模型2 | |||||||
|---|---|---|---|---|---|---|---|
| 預測 | 真實 | 是否正確 | |||||
| 0.1 | 0.2 | 0.7 | 0 | 0 | 1 | 豬 | 正確 |
| 0.1 | 0.7 | 0.2 | 0 | 1 | 0 | 狗 | 正確 |
| 0.3 | 0.4 | 0.3 | 1 | 0 | 0 | 貓 | 錯誤 |
???????模型評價:模型2對于樣本1和樣本2判斷非常準確,對于樣本3判斷錯誤,但是相對來說沒有錯得太離譜。
???????好了,有了模型之后,我們需要通過定義損失函數來判斷模型在樣本上的表現了,那么我們可以定義哪些損失函數呢?我們可以先嘗試使用以下幾種損失函數,然后討論哪種效果更好。
(1)Classification Error(分類錯誤率)
???????最為直接的損失函數定義為:
模型1:
模型2:
???????我們知道,模型1和模型2雖然都是預測錯了1個,但是相對來說模型2表現得更好,損失函數值照理來說應該更小,但是,很遺憾的是,classification error?并不能判斷出來,所以這種損失函數雖然好理解,但表現不太好。
(2)Mean Squared Error(均方誤差MSE)
???????均方誤差損失也是一種比較常見的損失函數,其定義為:
模型1:

對所有樣本的loss求平均:
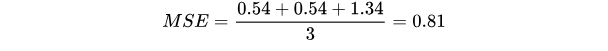
模型2:

對所有樣本的loss求平均:
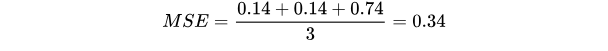
???????我們發現,MSE能夠判斷出來模型2優于模型1,那為什么不采樣這種損失函數呢?主要原因是在分類問題中,使用sigmoid/softmx得到概率,配合MSE損失函數時,采用梯度下降法進行學習時,會出現模型一開始訓練時,學習速率非常慢的情況(損失函數 | Mean-Squared Loss - 知乎)。
???????有了上面的直觀分析,我們可以清楚的看到,對于分類問題的損失函數來說,分類錯誤率和均方誤差損失都不是很好的損失函數,下面我們來看一下交叉熵損失函數的表現情況。
(3)Cross Entropy Loss Function(交叉熵損失函數)
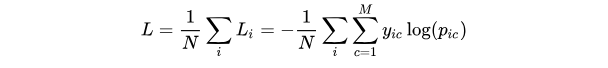
其中:
:類別的數量
:符號函數(0或1),如果樣本 i 的真實類別等于 c 取 1,否則取 0
:觀測樣本 i 屬于類別 c 的預測概率
:樣本的數量
現在我們利用這個表達式計算上面例子中的損失函數值:
模型1:
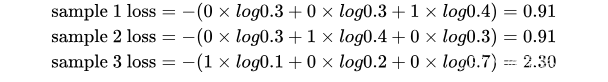
對所有樣本的loss求平均:

模型2:

對所有樣本的loss求平均:

???????可以發現,交叉熵損失函數可以捕捉到模型1和模型2預測效果的差異,因此對于Softmax回歸問題我們常用交叉熵損失函數。
? ? ? 下面兩圖可以很清晰的反應整個Softmax回歸算法的流程:


二、圖像分類數據集
???????MNIST數據集是圖像分類中廣泛使用的數據集之一,但作為基準數據集過于簡單。我們將使用類似但更復雜的Fashion-MNIST數據集。
???????在這里我們定義一些函數用于數據的讀取與顯示,這些函數已經在Python包d2l中定義好了,但為了便于大家理解,這里沒有直接調用d2l中的函數。
1、讀取數據集
???????我們可以通過框架中的內置函數將Fashion-MNIST數據集下載并讀取到內存中。
# 通過ToTensor實例將圖像數據從PIL類型變換成32位浮點數格式,
# 并除以255使得所有像素的數值均在0~1之間
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)???????Fashion-MNIST由10個類別的圖像組成,每個類別由訓練數據集(train dataset)中的6000張圖像和測試數據集(test dataset)中的1000張圖像組成。因此,訓練集和測試集分別包含60000和10000張圖像。測試數據集不會用于訓練,只用于評估模型性能。
print(len(mnist_train), len(mnist_test))60000 10000???????每個輸入圖像的高度和寬度均為28像素。數據集由灰度圖像組成,其通道數為1。為了簡潔起見,本書將高度像素、寬度
像素圖像的形狀記為
或
。接下來我們可以打印一下mnist_train的類型和mnist_train的第一個元素。
print(type(mnist_train))
print(type(mnist_train[0]))
print(mnist_train[0])
print(mnist_train[0][0].shape)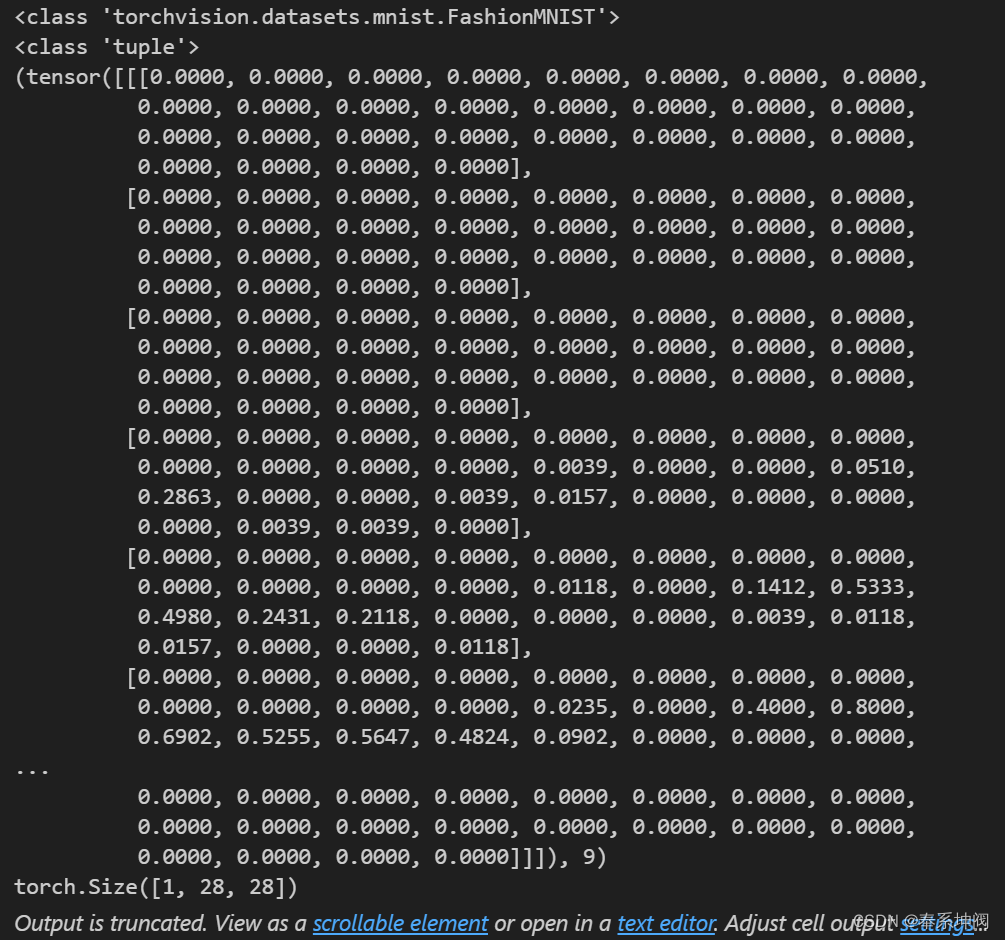
???????可以看出mnist_train的類型為<class 'torchvision.datasets.mnist.FashionMNIST'>。mnist_train的第一個元素的類型是<class 'tuple'>,是一個元組,元組第一個元素是轉化為tensor后的灰度值,第二個元素是圖像所屬類別index,這里是9。因為是灰度圖,因此channel數量為1,圖片長和寬都是28,因此形狀是(1,28,28)。
???????Fashion-MNIST中包含的10個類別,分別為t-shirt(T恤)、trouser(褲子)、pullover(套衫)、dress(連衣裙)、coat(外套)、sandal(涼鞋)、shirt(襯衫)、sneaker(運動鞋)、bag(包)和ankle boot(短靴)。
???????以下函數用于在數字標簽索引及其文本名稱之間進行轉換。
def get_fashion_mnist_labels(labels): # labels:mnist_train和mnist_test里面圖像的類別index(數字)"""返回Fashion-MNIST數據集的文本標簽"""text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']return [text_labels[int(i)] for i in labels] # 根據index返回文本標簽列表('t-shirt', 'trouser'...)???????我們現在可以創建一個函數來可視化這些樣本。
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save"""繪制圖像列表""""""imgs: tensor向量num_rows: 畫圖時的行數num_cols: 畫圖時的列數titles: 每張圖片的標題scales: 因為要將num_rows*num_cols張圖片畫到一張圖上,并且還要添加一些文字,因此需要對大圖進行一定的縮放才能保證每張小圖之間的間隙"""figsize = (num_cols * scale, num_rows * scale)# figsize = (num_cols, num_rows)_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):# 圖片張量ax.imshow(img.numpy())else:# PIL圖片ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])return axes???????以下是訓練數據集中前18個樣本的圖像及其相應的標簽。
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))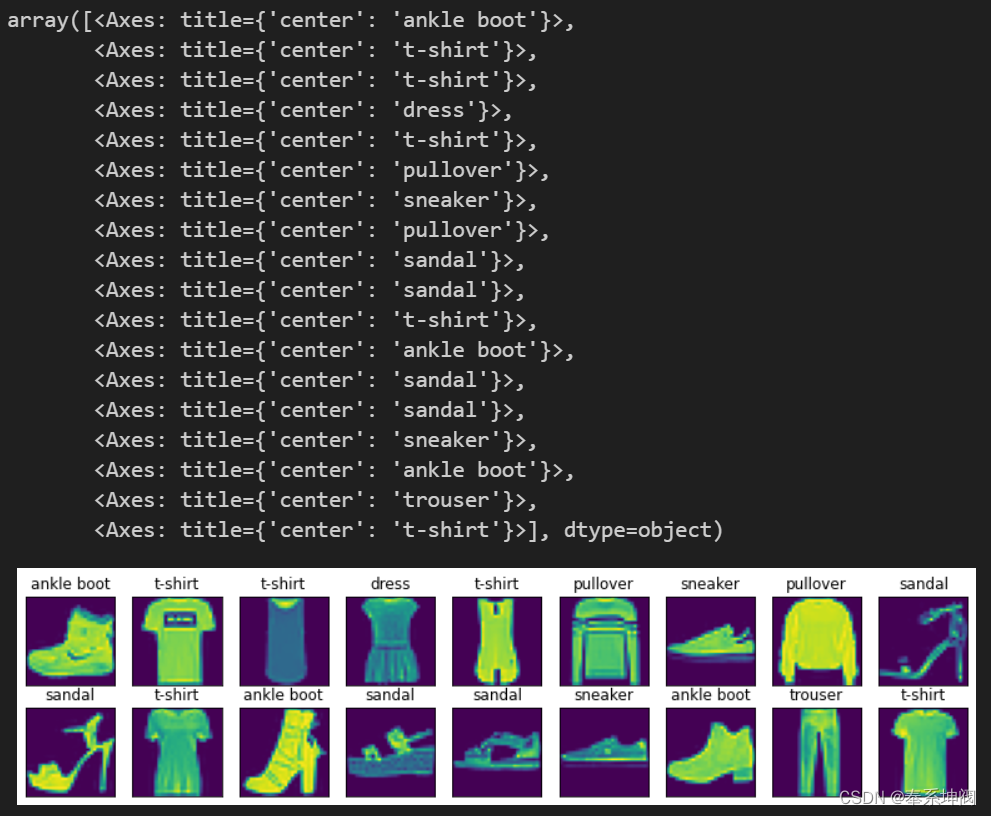
2、讀取小批量數據
???????為了使我們在讀取訓練集和測試集時更容易,我們使用內置的數據迭代器,而不是從零開始創建。在每次迭代中,數據加載器每次都會讀取一小批量數據,大小為`batch_size`。通過內置數據迭代器,我們可以隨機打亂所有樣本,從而無偏見地讀取小批量。
batch_size = 256def get_dataloader_workers(): #@save"""使用4個進程來讀取數據"""return 4train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers())3、整合所有組件
???????現在我們定義`load_data_fashion_mnist`函數,用于獲取和讀取Fashion-MNIST數據集。這個函數返回訓練集和驗證集的數據迭代器。此外,這個函數還接受一個可選參數`resize`,用來將圖像大小調整為另一種形狀。
def load_data_fashion_mnist(batch_size, resize=None):"""下載Fashion-MNIST數據集,然后將其加載到內存中"""trans = [transforms.ToTensor()] # 此時的trans是一個列表if resize:trans.insert(0, transforms.Resize(resize)) # 如果提供了resize參數,則在轉換鏈中插入Resize操作trans = transforms.Compose(trans) # 將一系列的圖像轉換操作組合成一個轉換鏈。# trans是一個由多個圖像轉換操作組成的列表。它按照列表中的順序依次應用這些轉換操作。# 這樣可以將多個轉換操作組合在一起,以便在加載數據時一次性應用它們。mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))???????下面,我們通過指定`resize`參數來測試`load_data_fashion_mnist`函數的圖像大小調整功能。
train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
for X, y in train_iter:print(X.shape, X.dtype, y.shape, y.dtype)breaktorch.Size([32, 1, 64, 64]) torch.float32 torch.Size([32]) torch.int64三、softmax回歸的從零開始實現
...
參考文獻
[1]??損失函數|交叉熵損失函數
[2]??深度學習模型系列一——多分類模型——Softmax 回歸-CSDN博客
[3]??Softmax 回歸_嗶哩嗶哩_bilibili

![[MySQL]SQL優化之索引的使用規則](http://pic.xiahunao.cn/[MySQL]SQL優化之索引的使用規則)
)


)
)

:基本概念)










