
[paper | code]
- 用生成對象本身作為控制信號,實現無條件圖像生成。
- 訓練階段。Step1:用預訓練模型(例如:Moco v3)提取生成對象的特征編碼;Step2:基于特征編碼,訓練一個擴散模型RDM;Step3:基于特征編碼,和大量圖片,訓練一個圖像生成器(例如:MAGE);
- 推理階段。從RDM從采樣圖像特征作為控制信號,生成圖片;或者生成參考圖像的特征編碼作為控制信號,生成圖片。
- 優點:無需人類標注標簽,實現接近使用標簽的生成模型的能力。
目錄
摘要
引言
方法
實驗結果
Class-unconditioned Generation
Classifier-free Guidance
Ablations
Compuational Cost
Qualitative Results
摘要
- 提出一種無條件圖像生成框架Representation-Conditioned image Generation (RCG);
- RCG的控制信號來自自監督表征分布,該分布是預訓練編碼器對圖片處理得到;
- 生成過程中,RCG使用representation diffusion model (RDM) 從該分布中采樣,作為控制條件生成圖像;
- 在ImageNet 256 x 256分辨率下測試,RCG去得了Frechet Inception Distance (FID) 3.31和Inception Score (IS) 253.4的成績,顯著改善無條件圖像生成方法,縮小了與有條件圖像生成方法的差距。

引言
- 使用圖片本身特征作為控制信號的優點:1)更直觀:藝術家是先形成抽象概念,再形成作品;2)更多數據:無條件圖像生成使得可用的訓練數據變多;3)無需標注:適合分子設計和藥物探索。
- 本文首先使用自監督圖片編碼器(例如:Moco v3),計算圖像特征;其次,用Representation Diffusion Model (RDM) 學習圖像特征分布。這樣做的優點在于:1)RDM可以捕捉圖像特征分布的多樣性;2)圖像特征維度較低,降低計算開銷。
- 生成過程:RDM采樣圖像特征分布作為控制信號,pixel generator生成圖像。
方法
RCG包含3個關鍵部分:1)預訓練自監督圖像編碼器;2)圖像表征生成器;3)圖像生成器。
- 圖像編碼器:本文使用自監督對比學習方法Moco v3作為圖像編碼器。本文使用映射頭(projection head)后的256維表征,每個表征基于其均值和方差歸一化。
- 圖像表征生成器:RDM如下圖所示,每個塊包含輸入層(input layer)、時間編碼映射層(timestep embedding projection layer)和輸出層(output layer)。每層包含LayerNorm、SiLU和線性層。圖像表征生成器通過兩個參數控制:塊數量N和中間特征維度C。
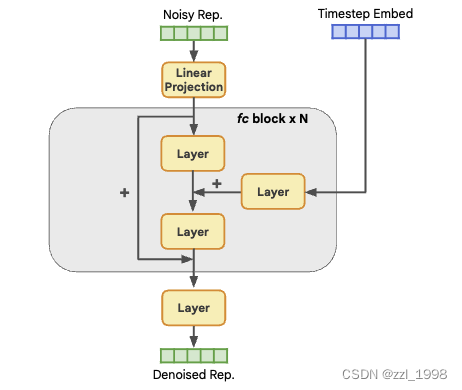
如下圖所示,RDM遵循DDIM做訓練和推理。圖片特征,添加噪聲得到
;RDM的訓練目標是預測去噪結果
。
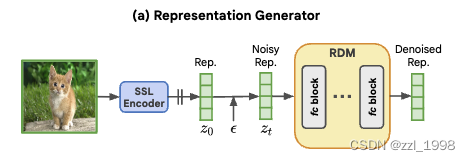
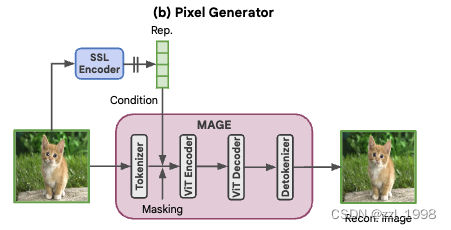
- 圖像生成器:如下圖所示,可以使用任意圖像生成器,唯一修改是把原有的控制條件,例如文本或分類標簽,替換為self-supervised learning (SSL) 表征。訓練時,輸入masked image,輸出完整圖像;推理時輸入為全部mak掉的圖片,輸出完整圖像。訓練和推理時都用圖像編碼作為控制信號。
Classifier-free Guidance:RCG遵循Muse實現classifier-free guidance。訓練時,MAGE有10%的概率,在不受SSL表征控制下生成。推理時,MAGE預測不受SSL表征控制的輸出和受表征控制的
,最終預測為
實驗結果
生成了50K圖像做測試
Class-unconditioned Generation
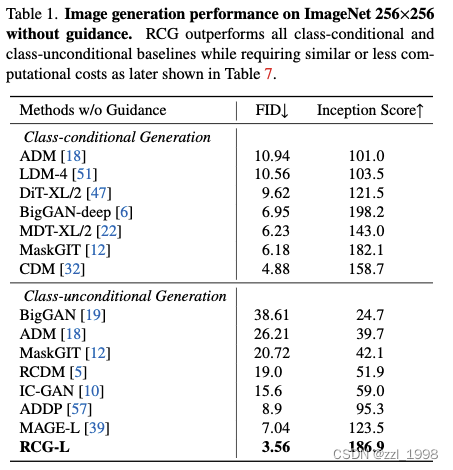

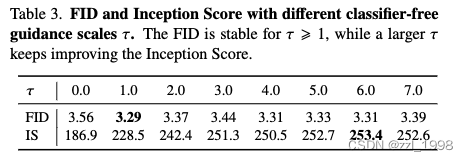
Classifier-free Guidance

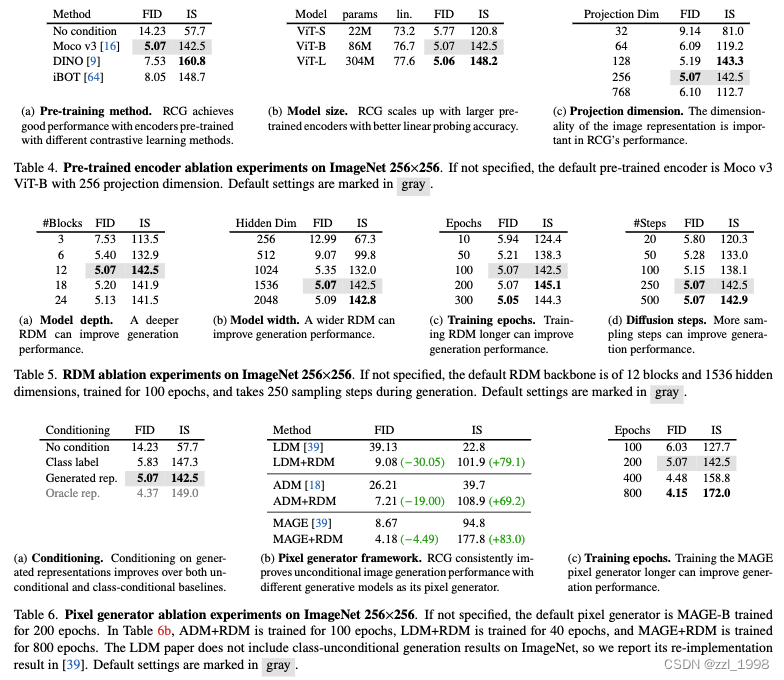
Ablations
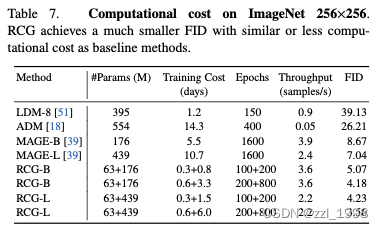
Compuational Cost
Qualitative Results



——淺談用戶體驗測試的主要功能)






)
的常見方法)




下載及使用)




