概述
????????SQL的自連接是指在一個SQL表中,使用自身表格中的實例進行聯接并查詢的操作。自連接通常使用別名來標識一個表格,在自連接中,表格被視為兩個不同的表格,并分別用不同的別名來標識。然后,在WHERE子句中使用這些別名,將它們連接起來,以創建一種與自身關聯的視圖。
組合
????????假設這里有一張存放了商品名稱及價格的表,表里有“蘋果、橘子、香蕉”這 3 條記錄。
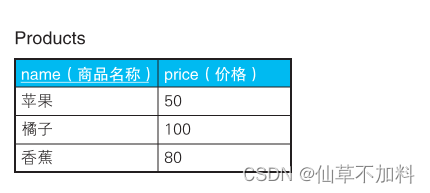
針對不同的需求,有不同的組合結果:
排列A(n,k)
查詢出所有的組合結果,有序集合。
select p1.name as name_1, p2.name as name_2
from products p1, products p2;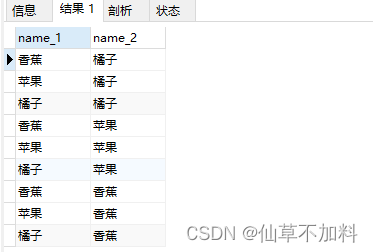 ?
?
?組合C(n,k)
查詢出所有的組合結果,有相同元素的只查出一條。無序集合。
select p1.name as name_1, p2.name as name_2from products p1, products p2where p1.name > p2.name;?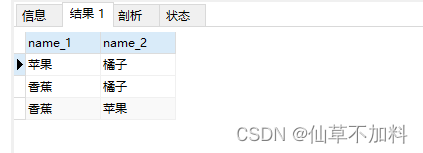
????????使用等號“=”以外的比較運算符,如“<、>、<>”進行的連接稱為“非等值連接”。這里將非等值連接與自連接結合使用了,因此稱為“非等值自連接”。
查找局部不一致的列
? ? ? ? 還是這張商品表,要查找出價格相同,名稱不同的組合。

?使用非等值連接實現。
select distinct p1.name,p1.pricefrom products p1,products p2where p1.name <> p2.name and p1.price = p2.price?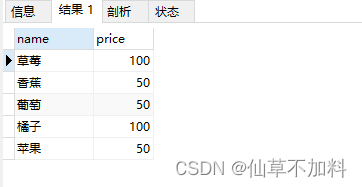
排序
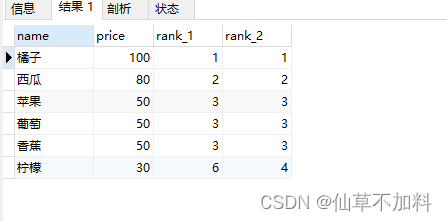
????????現在,我們要按照價格從高到低的順序,對下面這張表里的商品進行排序。我們讓價格相同的商品位次也一樣,而緊接著它們的商品則有兩種排序方法,一種是跳過之后的位次,另一種是不跳過之后的位次。

使用窗口函數實現。
select name,price,rank() over(order by price desc) as rank_1,dense_rank() over(order by price desc) as rank_2
from products;????????RANK函數返回一個唯一的值,當碰到相同數據時,排名按照記錄集中記錄的順序依次遞增。也就是說,如果有多個記錄的分數相同,那么這些記錄的排名將會一樣,并且下一個排名將會跳過這些排名相同的記錄。
????????DENSE_RANK函數也返回一個唯一的值,但當碰到相同數據時,所有相同數據的排名都是一樣的。與RANK函數不同的是,DENSE_RANK函數在下一個排名中會繼續緊隨這些排名相同的行,而不會跳過。也就是說,如果有多個記錄的分數相同,那么這些記錄的排名將會一樣,并且下一個排名將會緊隨在它們后面。
????????總的來說,RANK和DENSE_RANK都是用于排名的函數,但它們的策略略有不同。RANK函數在遇到相同數據時會產生間斷的排名,而DENSE_RANK函數則會產生連續的排名。
?使用非等值自連接實現。
select p1.name,p1.price,( select count(p2.price) from products p2 where p2.price > p1.price ) + 1 as rank_1
from products p1
order by rank_1?????????在子查詢中,統計出價格比自己高的記錄的條數并將其作為自己的位次,由于一定會存在價格最高的商品沒有比自己高的記錄,所以位次會從0開始統計,在子查詢的結果中+1能更明顯的展示出排名。

外連接和內連接
????????外連接(Outer Join)可以分為左外連接(Left Outer Join)、右外連接(Right Outer Join)和全外連接(Full Outer Join)。左外連接返回包括左表中的所有記錄和右表中連接字段相等的記錄,右外連接返回包括右表中的所有記錄和左表中連接字段相等的記錄,全外連接返回左右表中所有的記錄和左右表中連接字段相等的記錄。
????????內連接(Inner Join)是一種常見的連接方式,它只返回兩個表中連接字段相等的行。內連接使用比較運算符根據每個表共有的列的值匹配兩個表中的行。
? ? ? ? 還是上面那個例子,使用外連接來實現。
select p1.name,max(p1.price) as price,count(p2.name) + 1 as rank_1
from products p1 left join products p2 on p1.price < p2.price
group by p1.name
order by rank_1????????通過左外連接,與價格大于自己的商品進行連接,按照商品名稱p1進行分組,統計商品名稱p2的記錄條數,最終結果和上面相同。
? ? ? ? 使用內連接實現。
select p1.name,max(p1.price) as price,count(p2.name) + 1 as rank_1
from products p1 inner join products p2 on p1.price < p2.price
group by p1.name
order by rank_1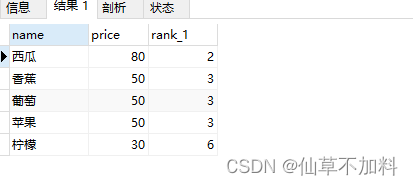 ?
?
? ? ? ? 通過查詢出的條件,可以發現,不存在排名為1的價格為100的橘子商品,這是因為內連接只會查找出p1.price < p2.price的記錄,找不到比橘子價格還高的商品,它就被排除掉了。
總結
- 自連接經常和非等值連接結合起來使用。
- 自連接和 GROUP BY 結合使用可以生成遞歸集合。
- 將自連接看作不同表之間的連接更容易理解。
- 應把表看作行的集合,用面向集合的方法來思考。
- 自連接的性能開銷更大,應盡量給用于連接的列建立索引。
練習題?
1.請使用表products,求出兩列可重組合。

代碼如下:?
select p1.name as name_1,p2.name as name_2 from products p1,products p2where p1.name <= p2.name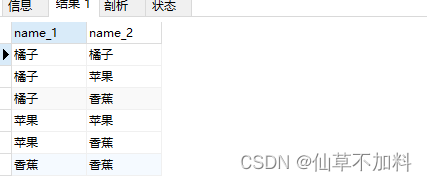 ?
?
2.?這里準備了下面這樣增加了“地區”列的新表 DistrictProducts,請計算一下各個地區商品價格的位次。


代碼如下:
select d1.district,d1.name,d1.price,count(d2.name)+1 as rank_1
from districtproducts d1 left join districtproducts d2 on d1.price < d2.price and d1.district = d2.district
group by district,name,price
order by district,rank_1 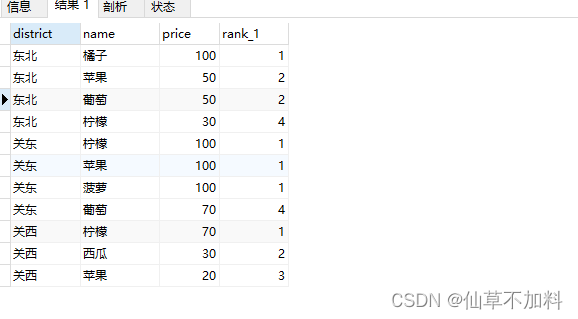
3.假設有下面這樣一張表DistrictProducts2,里邊原本就包含了“位次”列。不過,“位次”列的初始值都是 NULL。往這個列里寫入位次。
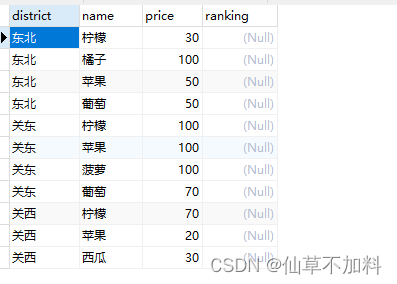
代碼如下:
update districtproducts2 p1
set ranking = (select rank_1 from(select count(p2.price) +1 rank_1from districtproducts2 p2where p1.district = p2.district and p2.price > p1.price) p3) ?
?
需要注意的是如果是下列代碼,會報錯。
UPDATE DistrictProducts2 P1SET ranking = (SELECT COUNT(P2.price) + 1 FROM DistrictProducts2 P2WHERE P1.district = P2.districtAND P2.price > P1.price);?報錯信息:
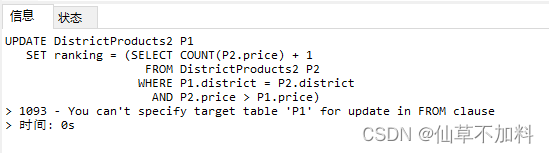
意思是不能先select出同一表中的某些值,再update這個表(在同一語句中)。?所以使用一張臨時表來解決問題。
擴展
????????使用PARTITION BY子句
????????PARTITION BY子句用于在窗口函數中對結果集進行分區,以便在每個分區中進行獨立的計算。PARTITION BY子句通常與ORDER BY子句一起使用,以便將數據按照指定的列進行排序,并將排序后的數據劃分為多個分區。
????????PARTITION BY子句可以將數據按照指定的列進行分組,并在每個分區中進行獨立的計算。它通常與窗口函數一起使用,以便在每個分區中計算聚合函數(如SUM、AVG、MAX等)的值。
UPDATE DistrictProducts2
SET ranking =(SELECT P1.rankingFROM (SELECT district , name ,RANK() OVER(PARTITION BY districtORDER BY price DESC) AS rankingFROM DistrictProducts2) P1WHERE P1.district = DistrictProducts2.districtAND P1.name = DistrictProducts2.name);????????PARTITION BY 子句將數據按照district進行分組,并在每個分區中按照price列進行降序排序,并結合RANK函數生成排名。




)
的常見方法)




下載及使用)








