本文介紹一些注意力機制的實現,包括SE/ECA/GE/A2-Net/GC/CBAM。
目錄
一、SE(Squeeze-and-Excitation)
二、ECA(Efficient Channel Attention)
三、GE(Gather-Excite)
四、A2-Net(Double Attention Networks)
五、GCNet(Global Context)
六、CBAM(Convolutional Block Attention Module)
一、SE(Squeeze-and-Excitation)
SE是通道注意力機制,論文地址:論文地址
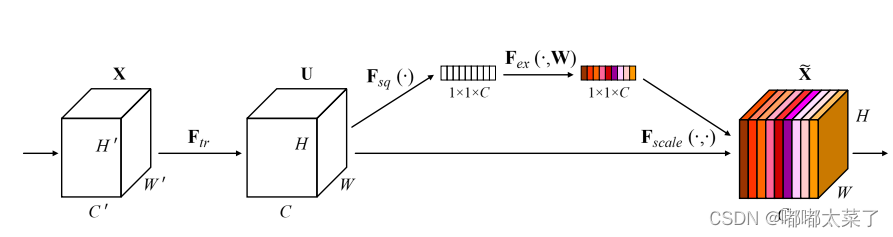
SE模塊流程:
1、輸入特征圖經過自適應池化變為NC11的特征圖,特征圖resize為NC;
2、經過全連接層和Relu、sigmoid生成權重;
3、將權重和輸入特征圖相乘。
如下所示:
torch代碼實現:
import numpy as np
import torch
from torch import nn
from torch.nn import initclass SEAttention(nn.Module):def __init__(self, channel=512,reduction=16):super().__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)二、ECA(Efficient Channel Attention)
ECA是通道注意力機制,論文:論文地址
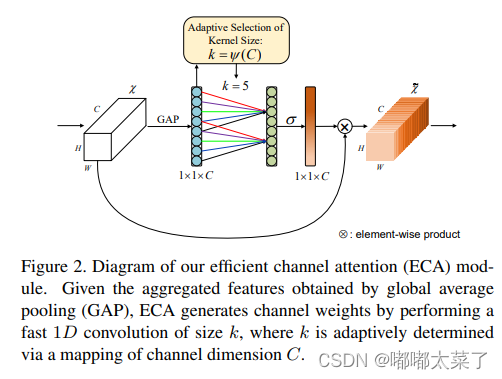
ECA模塊過程:
1、使用自適應池化將NCHW的特征圖變為N1C的特征圖(自適應池化、squeeze、transpose);
2、使用1D卷積生成N1C的特征圖(在C通道做卷積),將經過1D卷積的特征圖變為NC11(transpose、unsqueeze);
3、特征圖通過sigmoid,生成NC11的權重,將權重與原特征圖相乘;
如下圖:
torch代碼:
import torch
from torch import nn
from torch.nn.parameter import Parameterclass ECALayer(nn.Module):"""Constructs a ECA module.Args:channel: Number of channels of the input feature mapk_size: Adaptive selection of kernel size"""def __init__(self, channel, k_size=3):super(eca_layer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False) self.sigmoid = nn.Sigmoid()def forward(self, x):# feature descriptor on the global spatial informationy = self.avg_pool(x)# Two different branches of ECA moduley = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)# Multi-scale information fusiony = self.sigmoid(y)return x * y.expand_as(x)三、GE(Gather-Excite)
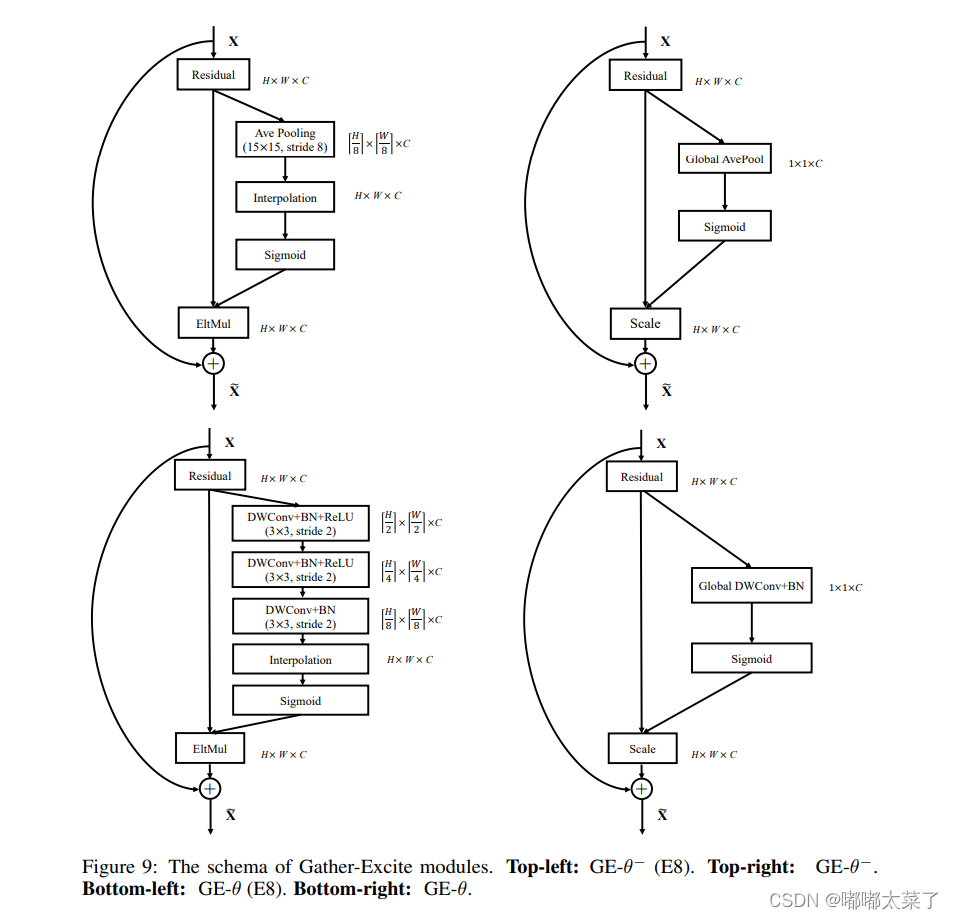
GE是空間注意力機制,論文:論文地址
該機制較為簡單,有四種方式,總體流程如下(看圖理解比較好,不多說了):
可以通過timm輕松調用該模塊,timm實現的源碼:
import mathfrom torch import nn as nn
import torch.nn.functional as Ffrom .create_act import create_act_layer, get_act_layer
from .create_conv2d import create_conv2d
from .helpers import make_divisible
from .mlp import ConvMlpclass GatherExcite(nn.Module):""" Gather-Excite Attention Module"""def __init__(self, channels, feat_size=None, extra_params=False, extent=0, use_mlp=True,rd_ratio=1./16, rd_channels=None, rd_divisor=1, add_maxpool=False,act_layer=nn.ReLU, norm_layer=nn.BatchNorm2d, gate_layer='sigmoid'):super(GatherExcite, self).__init__()self.add_maxpool = add_maxpoolact_layer = get_act_layer(act_layer)self.extent = extentif extra_params:self.gather = nn.Sequential()if extent == 0:assert feat_size is not None, 'spatial feature size must be specified for global extent w/ params'self.gather.add_module('conv1', create_conv2d(channels, channels, kernel_size=feat_size, stride=1, depthwise=True))if norm_layer:self.gather.add_module(f'norm1', nn.BatchNorm2d(channels))else:assert extent % 2 == 0num_conv = int(math.log2(extent))for i in range(num_conv):self.gather.add_module(f'conv{i + 1}',create_conv2d(channels, channels, kernel_size=3, stride=2, depthwise=True))if norm_layer:self.gather.add_module(f'norm{i + 1}', nn.BatchNorm2d(channels))if i != num_conv - 1:self.gather.add_module(f'act{i + 1}', act_layer(inplace=True))else:self.gather = Noneif self.extent == 0:self.gk = 0self.gs = 0else:assert extent % 2 == 0self.gk = self.extent * 2 - 1self.gs = self.extentif not rd_channels:rd_channels = make_divisible(channels * rd_ratio, rd_divisor, round_limit=0.)self.mlp = ConvMlp(channels, rd_channels, act_layer=act_layer) if use_mlp else nn.Identity()self.gate = create_act_layer(gate_layer)def forward(self, x):size = x.shape[-2:]if self.gather is not None:x_ge = self.gather(x)else:if self.extent == 0:# global extentx_ge = x.mean(dim=(2, 3), keepdims=True)if self.add_maxpool:# experimental codepath, may remove or changex_ge = 0.5 * x_ge + 0.5 * x.amax((2, 3), keepdim=True)else:x_ge = F.avg_pool2d(x, kernel_size=self.gk, stride=self.gs, padding=self.gk // 2, count_include_pad=False)if self.add_maxpool:# experimental codepath, may remove or changex_ge = 0.5 * x_ge + 0.5 * F.max_pool2d(x, kernel_size=self.gk, stride=self.gs, padding=self.gk // 2)x_ge = self.mlp(x_ge)if x_ge.shape[-1] != 1 or x_ge.shape[-2] != 1:x_ge = F.interpolate(x_ge, size=size)return x * self.gate(x_ge)四、A2-Net(Double Attention Networks)
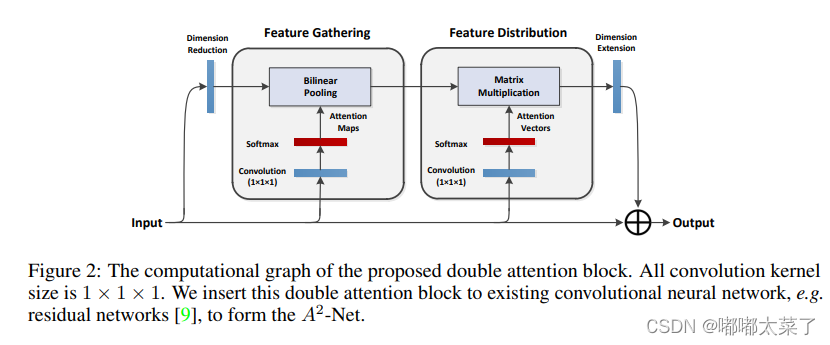
雙重注意力網絡(A2-Nets)方法引入了新的關系函數用于非局部(NL)塊,依次使用兩個連續的注意力塊。論文地址:論文地址
其計算過程類似于SelfAttention模塊,可以看diamagnetic對照理解。
如下圖:
代碼如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass DoubleAtten(nn.Module):"""A2-Nets: Double Attention Networks. NIPS 2018"""def __init__(self,in_c):""":paramin_c: 進行注意力refine的特征圖的通道數目;原文中的降維和升維沒有使用"""super(DoubleAtten,self).__init__()self.in_c = in_c"""以下對同一輸入特征圖進行卷積,產生三個尺度相同的特征圖,即為文中提到A, B, V"""self.convA = nn.Conv2d(in_c,in_c,kernel_size=1)self.convB = nn.Conv2d(in_c,in_c,kernel_size=1)self.convV = nn.Conv2d(in_c,in_c,kernel_size=1)def forward(self,input):feature_maps = self.convA(input)atten_map = self.convB(input)b, _, h, w = feature_maps.shapefeature_maps = feature_maps.view(b, 1, self.in_c, h*w) # 對 A 進行reshapeatten_map = atten_map.view(b, self.in_c, 1, h*w) # 對 B 進行reshape 生成 attention_apsglobal_descriptors = torch.mean((feature_maps * F.softmax(atten_map, dim=-1)),dim=-1) # 特征圖與attention_maps 相乘生成全局特征描述子v = self.convV(input)atten_vectors = F.softmax(v.view(b, self.in_c, h*w), dim=-1) # 生成 attention_vectorsout = torch.bmm(atten_vectors.permute(0,2,1), global_descriptors).permute(0,2,1) # 注意力向量左乘全局特征描述子return out.view(b, _, h, w)五、GCNet(Global Context)
全局上下文網絡(GC-Net)方法使用復雜的基于置換的操作將NL-塊和SE塊集成,以捕捉長期依賴關系。論文:論文地址
可以看出GC模塊是對SE的改進,如下圖:
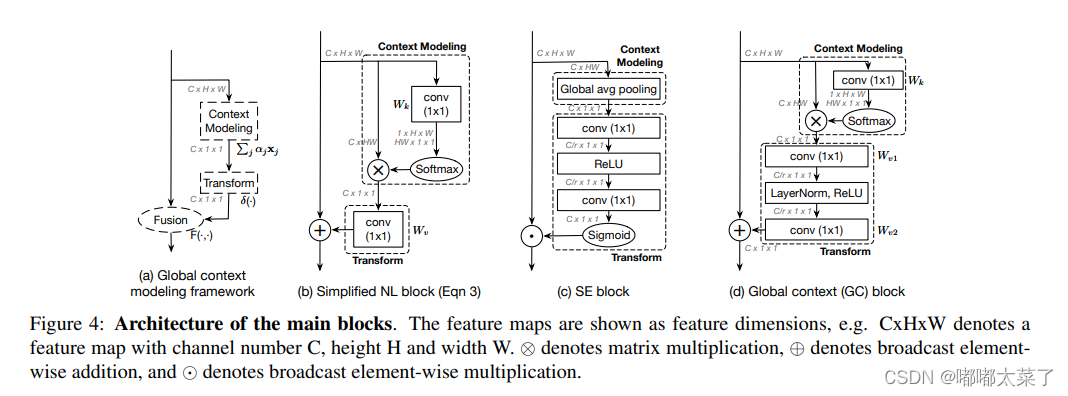
該實現的初始化依賴于mmcv,代碼如下:
import torch
from mmcv.cnn import constant_init, kaiming_init
from torch import nndef last_zero_init(m):if isinstance(m, nn.Sequential):constant_init(m[-1], val=0)else:constant_init(m, val=0)class ContextBlock(nn.Module):def __init__(self,inplanes,ratio,pooling_type='att',fusion_types=('channel_add', )):super(ContextBlock, self).__init__()assert pooling_type in ['avg', 'att']assert isinstance(fusion_types, (list, tuple))valid_fusion_types = ['channel_add', 'channel_mul']assert all([f in valid_fusion_types for f in fusion_types])assert len(fusion_types) > 0, 'at least one fusion should be used'self.inplanes = inplanesself.ratio = ratioself.planes = int(inplanes * ratio)self.pooling_type = pooling_typeself.fusion_types = fusion_typesif pooling_type == 'att':self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)self.softmax = nn.Softmax(dim=2)else:self.avg_pool = nn.AdaptiveAvgPool2d(1)if 'channel_add' in fusion_types:self.channel_add_conv = nn.Sequential(nn.Conv2d(self.inplanes, self.planes, kernel_size=1),nn.LayerNorm([self.planes, 1, 1]),nn.ReLU(inplace=True), # yapf: disablenn.Conv2d(self.planes, self.inplanes, kernel_size=1))else:self.channel_add_conv = Noneif 'channel_mul' in fusion_types:self.channel_mul_conv = nn.Sequential(nn.Conv2d(self.inplanes, self.planes, kernel_size=1),nn.LayerNorm([self.planes, 1, 1]),nn.ReLU(inplace=True), # yapf: disablenn.Conv2d(self.planes, self.inplanes, kernel_size=1))else:self.channel_mul_conv = Noneself.reset_parameters()def reset_parameters(self):if self.pooling_type == 'att':kaiming_init(self.conv_mask, mode='fan_in')self.conv_mask.inited = Trueif self.channel_add_conv is not None:last_zero_init(self.channel_add_conv)if self.channel_mul_conv is not None:last_zero_init(self.channel_mul_conv)def spatial_pool(self, x):batch, channel, height, width = x.size()if self.pooling_type == 'att':input_x = x# [N, C, H * W]input_x = input_x.view(batch, channel, height * width)# [N, 1, C, H * W]input_x = input_x.unsqueeze(1)# [N, 1, H, W]context_mask = self.conv_mask(x)# [N, 1, H * W]context_mask = context_mask.view(batch, 1, height * width)# [N, 1, H * W]context_mask = self.softmax(context_mask)# [N, 1, H * W, 1]context_mask = context_mask.unsqueeze(-1)# [N, 1, C, 1]context = torch.matmul(input_x, context_mask)# [N, C, 1, 1]context = context.view(batch, channel, 1, 1)else:# [N, C, 1, 1]context = self.avg_pool(x)return contextdef forward(self, x):# [N, C, 1, 1]context = self.spatial_pool(x)out = xif self.channel_mul_conv is not None:# [N, C, 1, 1]channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))out = out * channel_mul_termif self.channel_add_conv is not None:# [N, C, 1, 1]channel_add_term = self.channel_add_conv(context)out = out + channel_add_termreturn out六、CBAM(Convolutional Block Attention Module)
CBAM是通道-空間注意力機制,論文:論文地址
很簡單的通道注意力和空間注意力融合。
如下圖:
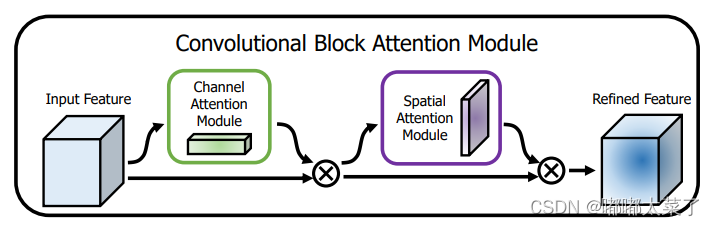
代碼如下:
import numpy as np
import torch
from torch import nn
from torch.nn import initclass ChannelAttention(nn.Module):def __init__(self,channel,reduction=16):super().__init__()self.maxpool=nn.AdaptiveMaxPool2d(1)self.avgpool=nn.AdaptiveAvgPool2d(1)self.se=nn.Sequential(nn.Conv2d(channel,channel//reduction,1,bias=False),nn.ReLU(),nn.Conv2d(channel//reduction,channel,1,bias=False))self.sigmoid=nn.Sigmoid()def forward(self, x) :max_result=self.maxpool(x)avg_result=self.avgpool(x)max_out=self.se(max_result)avg_out=self.se(avg_result)output=self.sigmoid(max_out+avg_out)return outputclass SpatialAttention(nn.Module):def __init__(self,kernel_size=7):super().__init__()self.conv=nn.Conv2d(2,1,kernel_size=kernel_size,padding=kernel_size//2)self.sigmoid=nn.Sigmoid()def forward(self, x) :max_result,_=torch.max(x,dim=1,keepdim=True)avg_result=torch.mean(x,dim=1,keepdim=True)result=torch.cat([max_result,avg_result],1)output=self.conv(result)output=self.sigmoid(output)return outputclass CBAMBlock(nn.Module):def __init__(self, channel=512,reduction=16,kernel_size=49):super().__init__()self.ca=ChannelAttention(channel=channel,reduction=reduction)self.sa=SpatialAttention(kernel_size=kernel_size)def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, _, _ = x.size()residual=xout=x*self.ca(x)out=out*self.sa(out)return out+residual












)


:Unique模型(唯一主鍵)介紹)



