一:為什么需要REDO日志
- 緩沖池可以幫助我們消除CPU和磁盤之間的鴻溝,checkpoint機制可以保證數據的最終落盤,然而由于checkpoint 并不是每次變更的時候就觸發 的,而是master線程隔一段時間去處理的。所以最壞的情況就是事務提交后,剛寫完緩沖池,數據庫宕機了,那么這段數據就是丟失的,無法恢復。
- 事務包含持久性的特性,就是說對于一個已經提交的事務,在事務提交后即使系統發生了潰,這個事務對數據庫中所做的更改也不能丟失。
解決思路:先寫日志,再寫磁盤,只有日志寫入成功,才算事務提交成功,這里的日志就是rodo日志
二:什么是REDO日志
Redo Log是MySQL用于實現崩潰恢復和數據持久性的一種機制。在事務進行過程中,MySQL會將事務做了什么改動記錄到Redo Log中。當系統崩潰或者發生異常情況時,MySQL會利用Redo Log中的記錄信息來進行恢復操作,將事務所做的修改持久化到磁盤中。
三:redo的組成
- 重做日志的緩沖 (redo log buffer) ,保存在內存中,是易失的
- 重做日志文件 (redo log file) ,保存在硬盤中,是持久的
四:redo的整體流程
- 先將原始數據從磁盤中讀入內存中來,修改數據的內存拷貝
- 生成一條重做日志并寫入redo log buffer,記錄的是數據被修改后的值
- 當事務commit時,將redo log buffer中的內容刷新到 redo log file,對 redo log file采用追加
寫的方式 - 定期將內存中修改的數據刷新到磁盤中

五:redo log的刷盤策略
redo log的寫入并不是直接寫入磁盤的,InnoDB引擎會在寫redo log的時候先寫redo log buffer,之后以一定的頻率刷入到真正的redo log file 中。這里的一定頻率怎么看待呢?這就是我們要說的刷盤策略。
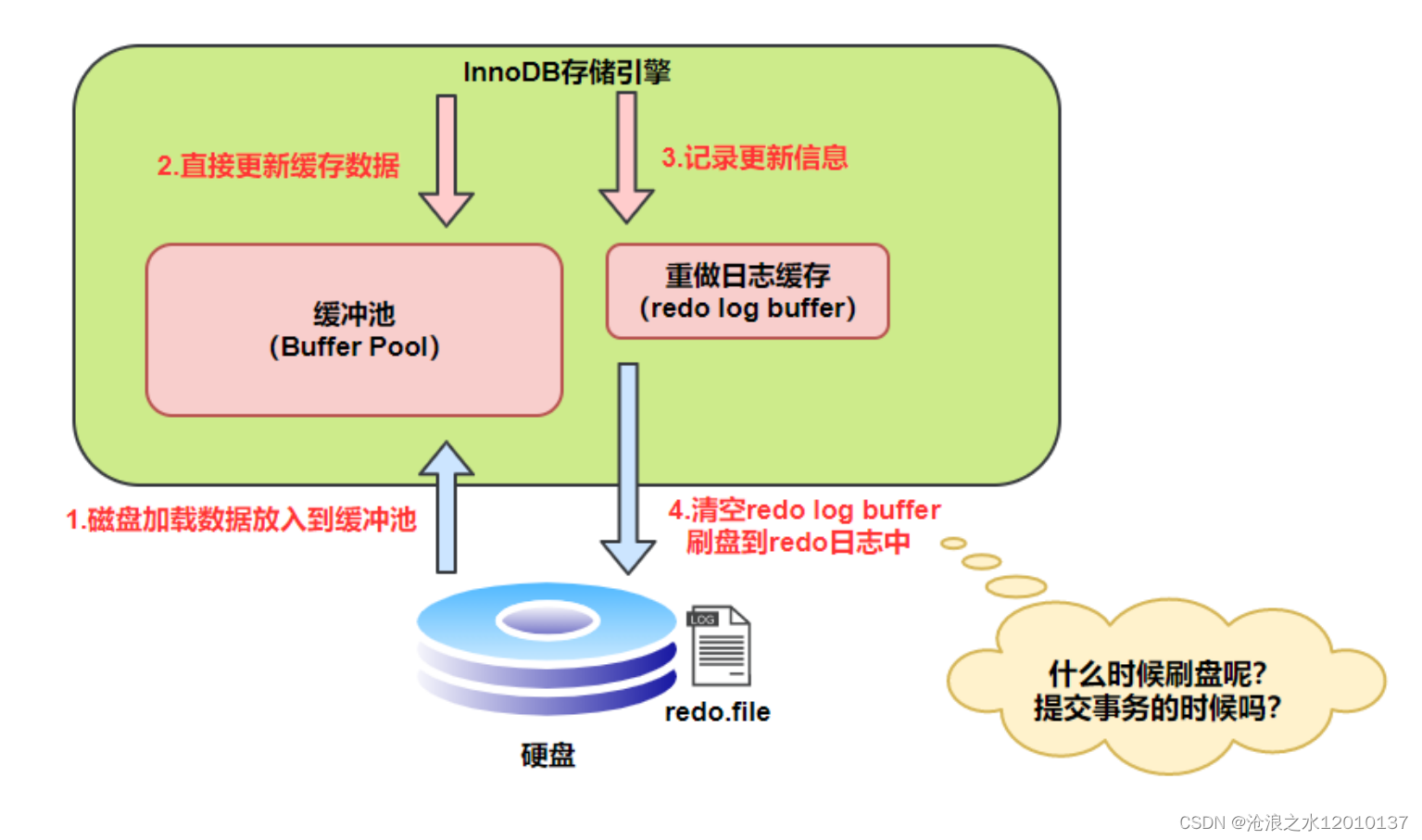
注意,redo log buffer刷盤到redo log file的過程并不是真正的刷到磁盤中去,只是刷入到 文件系統緩存中去,真正的寫入會交給系統自己來決定。那么對于InnoDB來說就存在一個問題,如果交給系統來同步,同樣如果系統宕機,那么數據也丟失了。
針對這種情況,InnoDB提供了一個參數,該參數控制 commit提交事務時,如何將 redo log buffer 中的日志刷新到 redo log
- 設置為0 :表示每次事務提交時不進行刷盤操作。(系統默認master thread每隔1s進行一次重做日志的同步)
- 設置為1 :表示每次事務提交時都將進行同步,刷盤操作( 默認值 )
- 設置為2 :表示每次事務提交時都只把 redo log buffer 內容寫入 page cache,不進行同步。由os自己決定什么時候同步到磁盤文件。
六:什么是Undo Log日志
Undo Log是事務原子性的保證,在事務中更新數據的前置操作其實是要先寫入一個 undo log。如果事務需要回滾,則會從Undo Log中找到相應的記錄來撤銷事務所做的修改。另外,Undo Log還支持MVCC(多版本并發控制)機制,用于在并發事務執行時提供一定的隔離性。
七:undo log的生命周期
假設有2個數值,分別為A=1和B=2,然后將A修改為3,B修改為4
1. start transaction;
2.記錄 A=1 到undo log;
3. update A = 3;
4.記錄 A=3 到redo log;
5.記錄 B=2 到undo log;
6. update B = 4;
7.記錄B = 4 到redo log;
8.將redo log刷新到磁盤
9. commit
在1-8步驟的任意一步系統宕機,事務未提交,該事務就不會對磁盤上的數據做任何影響。
如果在8-9之間宕機,恢復之后可以選擇回滾,也可以選擇繼續完成事務提交,因為此時redo log已經持久化。
若在9之后系統宕機,內存映射中變更的數據還來不及刷回磁盤,那么系統恢復之后,可以根據redo log把數
面試題:
1. redolog和undolog區別?
(1)redo log:記錄的是"物理級別"上的頁修改操作,比如頁號xx、偏移量yyy,寫了’zzz’數據
undo log:記錄的是邏輯操作,比如對某一行數據進行了INSERT語句操作,那么 undo log就記錄一條與之相反的DELETE操作
(2)redo log:目的是為了保證事務的持久性,主要用于崩潰恢復
undo log:目的是為了保證事務的原子性和一致性,主要用于事務回滾

———js判斷上傳的文件是GBK編碼還是UTF-8)







-minikube的安裝)
》筆記(三))


![給定有n個結點的樹和長度為n的排列,q次詢問:l, r, x, 若p[l, r]中存在至少一個結點是x的后代,輸出yes,否則輸出no](http://pic.xiahunao.cn/給定有n個結點的樹和長度為n的排列,q次詢問:l, r, x, 若p[l, r]中存在至少一個結點是x的后代,輸出yes,否則輸出no)

。Javaee項目。ssm項目。)


![Unknown parameter in InstanceGroups[0]: “Configurations“, must be ... 解決方法](http://pic.xiahunao.cn/Unknown parameter in InstanceGroups[0]: “Configurations“, must be ... 解決方法)
