Order by語句是如何工作的?
首先我們來創建一個表
CREATE TABLE `t` (`id` int(11) NOT NULL,`city` varchar(16) NOT NULL,`name` varchar(16) NOT NULL,`age` int(11) NOT NULL,`addr` varchar(128) DEFAULT NULL,PRIMARY KEY (`id`),KEY `city` (`city`)
) ENGINE=InnoDB;全字段排序?
?scelect city, name ,age from t where city="杭州" order by name limit 1000;
為了避免全表掃描,我們需要給city加上一個索引,然后使用explain語句去查詢,其中extra這個字段中的“using filesort”表示需要排序。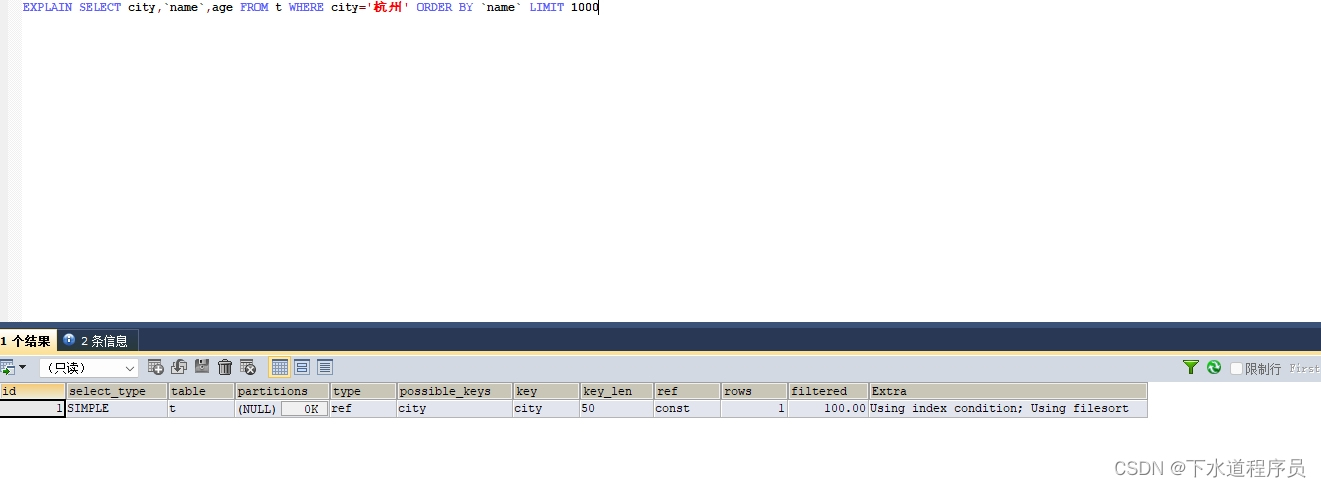
?Mysql對其分配出一塊內存用于排序,內存成為sort_buffer,city=杭州找出來后,初始化sort_buffer放入city name id這三個字段,對sort_buffer中的name字段進行快速排序,取出前1000行返回給客戶端。
按照name排序,可能在內存當中完成,也可能需要外部排序,這取決于所需內存及其參數sort_buffer_size,當name太大的時候,內存放不下,就得使用外部排序進行,就是Mysql開辟sort_buffer_size的大小。
那么如何判斷一個文件是否使用了臨時文件呢??
optimizer_trace='enabled=on'
開啟優化跟蹤,Mysql開啟追蹤查詢優化器的決策過程,記錄有關優化器如何選擇執行計劃的詳細信息,information_schema是一個特殊的數據庫,這個數據庫存儲了關于數據庫,表,列,索引,權限等方面的信息,允許用戶查詢和了解數據庫的結構和狀態。
使用這個查詢中number_of_tmp_files表示的是排序過程中使用臨時文件數,那么為什么使用了12個臨時文件呢,Mysql將其分為12份,每一份單獨排序后存在于臨時文件中,再將12個有序文件合并成為一個有序的大文件。
如果sort_buffer_size超過了需要排序的數據量大小,number_of_tmp_files的數值就為0,表示可以在內存中進行排序。
否則就需要在外部排序,sort_buffer_size 越小,需要分成的份數越多,number_of_tmp_files就越大。
rowid排序
在全排序當中,是對原表的數據讀了一遍,剩下的操作都是在sort_buffer和臨時表當中執行的,但是這存在著一個問題,就是當查詢的時候要返回很多字段的時候,sort_buffer當中要存放的字段數太多,這樣內存當中能同時放下的行數就很少,這樣要分為很多個臨時文件,排序的時候性能會很差,所以我們來使用rowid排序來解決這種問題。
當Mysql認為排序的單行長度太大的時候會采用另外一種算法即為rowid算法。流程是這樣的,初始化sort_buffer確定放入兩個字段name 和id。從索引city當中取出滿足city=“杭州”的主鍵id,然后從這個主鍵id中取出整行,取出id和name存入sort_buffer,然后接著重復從索引city中取出滿足條件的主鍵id,直到不滿足為止。
因為只要排序的列name字段和主鍵id,少了city和age字段的值,不能直接返回了。存的是主鍵id的順序,到時候遍歷排序結果,取前1000行,并按照id的值到原表當中取出city,name和age三個字段返回客戶端。
這樣的話需要進行排序的內存就會變小,相應的臨時文件也相應的變小了。
比較
Mysql在擔心內存不夠用的時候會使用第二種算法來進行排序,但是會增加磁盤訪問,因為第二次返回值的時候,是從主鍵當中再次訪問原表返回的,這就體現出來Mysql的一個思想:如果內存夠就多利用內存,減少磁盤訪問。
我們還可以使用覆蓋索引和聯合索引來解決,其實并不是所有的order by語句都要進行排序操作的,Mysql之所以要生成臨時表做排序操作,是因為原來所有的數據都是無序的,但是如果它天然就是按照name遞增排序的呢?
覆蓋索引是指,索引上的信息足夠滿足查詢請求,不需要再回到主鍵索引上去取數據。
按照這個概念,我們創建一個name ,city ,age 的聯合索引,因為name是遞增天然的,我們就不需要排序直接返回了,直到city不為杭州的時候結束。使用這個的時候,我們可以看extra下面的字段顯示是不是需要排序來決定。因為不是每一個查詢都能使用上覆蓋索引,就需要把所有的字段都建立起聯合索引,因為索引的維護也是有代價的,所以這是一個需要權衡的決定。




)










)



)