用訓練好的模型結果進行預測,需要采用一些評價指標來進行評價,才可以得到最優的模型
常用的指標:
1.分類任務
- ConfusionMatrix? 混淆矩陣
- Accuracy?? 準確率
- Precision? 精確率
- Recall?????? 召回率
- F1 score?? H-mean值
- ROC Curve? ROC曲線
- PR Curve???? PR曲線
- AUC
??????? ……
下面我將會具體介紹以上幾種常見的分類模型評價指標
?ConfusionMatrix 混淆矩陣
?混淆矩陣是評判模型結果的一種指標,屬于模型評估的一部分,常用于評判分類器模型的優劣
| 混淆矩陣(ConfusionMatrix) | 真實值(labels) | ||
| Positive | Negative | ||
| 預測值(predict) | Positive | TP | FP |
| Negative | FN | TN | |
其中,
- TP (True? Positive) ? : 真實值和預測值均為Positive
- FP (False Positive)?? : 真實值為Negative,預測值為Positive
- FN (False Negative) : 真實值為Positive,預測值為Negative
- TN (True? Negative)? : 真實值為Negative,預測值為Negative
一般地,期望TP和TN越高越好,FN和FP越低越好
?Accuracy? 準確率、Precision 精確率、Recall 召回率
(引用 up主 :霹靂吧啦Wz的個人空間-霹靂吧啦Wz個人主頁-嗶哩嗶哩視頻?? 的一張圖做說明)
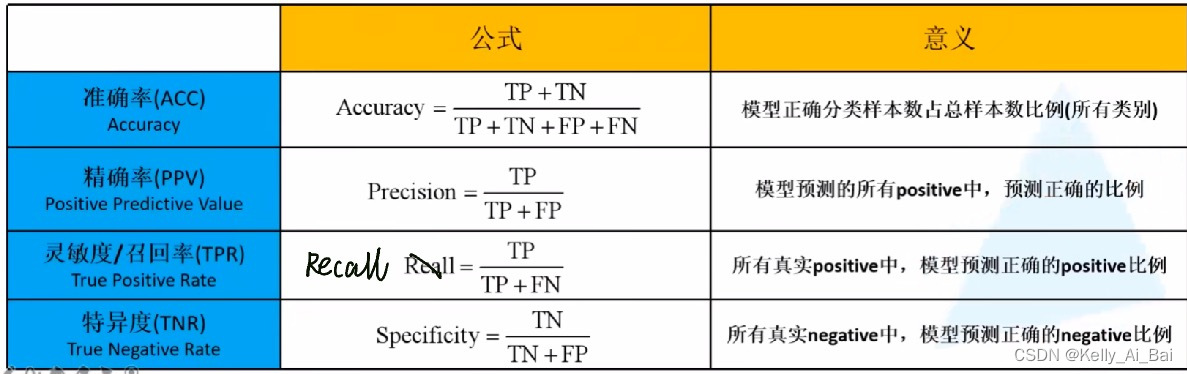
準確率(正確率) :所有預測正確的樣本數 / 總樣本數?? (所有的預測正確(正類負類)的占總的比重)
?雖然準確率可以判斷總的正確率,但是在樣本不平衡 的情況下,并不能作為很好的指標來衡量結果。舉個簡單的例子,比如在一個總樣本中,正樣本占 90%,負樣本占 10%,樣本是嚴重不平衡的。對于這種情況,我們只需要將全部樣本預測為正樣本即可得到 90% 的高準確率,但實際上我們并沒有很用心的分類,只是隨便無腦一分而已。這就說明了:由于樣本不平衡的問題,導致了得到的高準確率結果含有很大的水分。即如果樣本不平衡,準確率就會失效
作者:easyAI產品經理的AI知識庫
鏈接:https://juejin.cn/post/6844903470756167688
來源:稀土掘金
精確率(查準率):預測正類為正類的樣本數 / 預測的正類樣本數??? (真正正確的占所有預測為正的比例)
精準率和準確率看上去有些類似,但是完全不同的兩個概念。精準率代表對正樣本結果中的預測準確程度,而準確率則代表整體的預測準確程度,既包括正樣本,也包括負樣本
作者:easyAI產品經理的AI知識庫
鏈接:https://juejin.cn/post/6844903470756167688
來源:稀土掘金
召回率(查全率):預測正類為正類的樣本數 / 真實值為正類的樣本數 (真正正確的占所有實際為正的比例)
召回率的應用場景: 比如拿網貸違約率為例,相對好用戶,我們更關心壞用戶,不能錯放過任何一個壞用戶。因為如果我們過多的將壞用戶當成好用戶,這樣后續可能發生的違約金額會遠超過好用戶償還的借貸利息金額,造成嚴重償失。召回率越高,代表實際壞用戶被預測出來的概率越高,它的含義類似:寧可錯殺一千,絕不放過一個
作者:easyAI產品經理的AI知識庫
鏈接:https://juejin.cn/post/6844903470756167688
來源:稀土掘金
注意:
- 精確率和召回率的區別
?????? 從數學角度來看,精確率和召回率就是分母不一樣
?????? 召回率的分母是原本的正類(TP+FN),
?????? 召回率讓模型預測到所有想被預測到的樣本(就算預測錯的多一些,也能接受)
下面引用 博主?清如許. 的一張圖片作總結
博客鏈接:https://blog.csdn.net/MacWx/article/details/129119016?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-129119016-blog-80964865.235^v39^pc_relevant_anti_t3_base&spm=1001.2101.3001.4242.2&utm_relevant_index=4
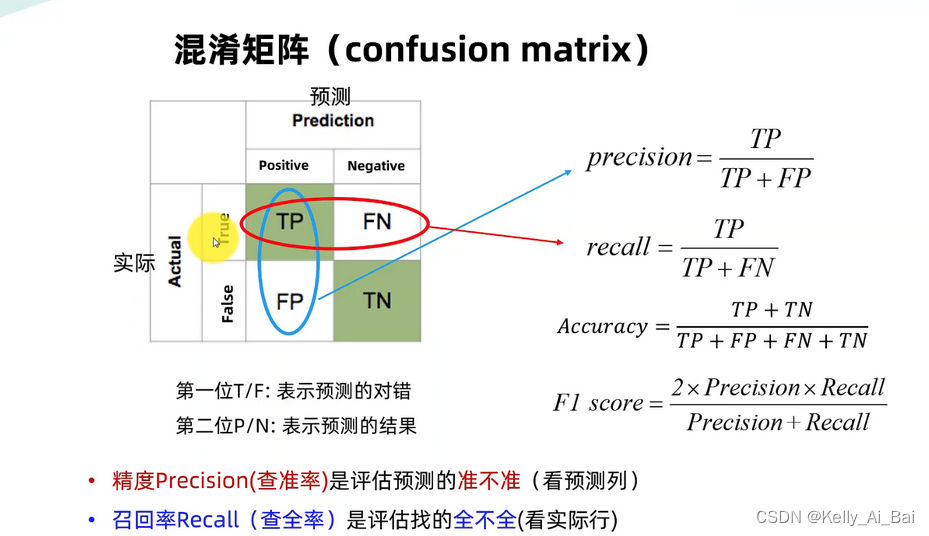
總得來說,精確率就是不錯報,召回率就是不漏報
F1-Score(F1值、調和平均數)
精確率(Precision)和召回率(Recall)之間是兩難全的關系,為了綜合兩者的表現,在兩者之間找一個平衡點,就出現了一個 F1分數?
F = 2 / (1/Precision + 1/Recall) = (2 * Precision * Recall)/ (Precision + Recall)
F1值越大越好,F1對 Precision 和 Recall 進行了加權
ROC曲線
PR曲線
雖然準確率可以判斷總的正確率,但是在樣本不平衡 的情況下,并不能作為很好的指標來衡量結果。舉個簡單的例子,比如在一個總樣本中,正樣本占 90%,負樣本占 10%,樣本是嚴重不平衡的。對于這種情況,我們只需要將全部樣本預測為正樣本即可得到 90% 的高準確率,但實際上我們并沒有很用心的分類,只是隨便無腦一分而已。這就說明了:由于樣本不平衡的問題,導致了得到的高準確率結果含有很大的水分。即如果樣本不平衡,準確率就會失效
作者:easyAI產品經理的AI知識庫
鏈接:https://juejin.cn/post/6844903470756167688
來源:稀土掘金
2.回歸任務
- MSE???? 均方誤差??? Mean Square Error
- RMSE? 均方根誤差 Root Mean Square Error
- MAE??? 平均絕對誤差 Mean Absolute Error
????????? ……

-復雜查詢方法-視圖、子查詢、函數等)




 - 用好strace)


)
)

覆蓋優化 - 附代碼)


RTTI運行時類型信息typeid和type_info)


 以上普通 APP 隱藏應用圖標問題探究及解決方案)
