-天池龍珠計劃SQL訓練營
SQL訓練營頁面地址:https://tianchi.aliyun.com/specials/promotion/aicampsql
3.1 視圖
我們先來看一個查詢語句(僅做示例,未提供相關數據)
SELECT stu_name FROM view_students_info;
單從表面上看起來這個語句是和正常的從數據表中查詢數據是完全相同的,但其實我們操作的是一個視圖。所以從SQL的角度來說操作視圖與操作表看起來是完全相同的,那么為什么還會有視圖的存在呢?視圖到底是什么?視圖與表有什么不同呢?
3.1.1 什么是視圖
視圖是一個虛擬的表,不同于直接操作數據表,視圖是依據SELECT語句來創建的(會在下面具體介紹),所以操作視圖時會根據創建視圖的SELECT語句生成一張虛擬表,然后在這張虛擬表上做SQL操作。
3.1.2 視圖與表有什么區別
《sql基礎教程第2版**》用一句話非常凝練的概括了視圖與表的區別—“是否保存了實際的數據”。所以視圖并不是數據庫真實存儲的數據表,它可以看作是一個窗口,通過這個窗口我們可以看到數據庫表中真實存在的數據。所以我們要區別視圖和數據表的本質,即視圖是基于真實表的一張虛擬的表,其數據來源均建立在真實表的基礎上。

圖片來源:《sql基礎教程第2版》
下面這句順口溜也方便大家記憶視圖與表的關系:“視圖不是表,視圖是虛表,視圖依賴于表”。
3.1.3 為什么會存在視圖
那既然已經有數據表了,為什么還需要視圖呢?主要有以下幾點原因:
- 通過定義視圖可以將頻繁使用的SELECT語句保存以提高效率。
- 通過定義視圖可以使用戶看到的數據更加清晰。
- 通過定義視圖可以不對外公開數據表全部字段,增強數據的保密性。
- 通過定義視圖可以降低數據的冗余。
3.1.4 如何創建視圖
說了這么多視圖與表的區別,下面我們就一起來看一下如何創建視圖吧。
創建視圖的基本語法如下:
CREATE VIEW <視圖名稱>(<列名1>,<列名2>,...) AS <SELECT語句>
其中SELECT 語句需要書寫在 AS 關鍵字之后。 SELECT 語句中列的排列順序和視圖中列的排列順序相同, SELECT 語句中的第 1 列就是視圖中的第 1 列, SELECT 語句中的第 2 列就是視圖中的第 2 列,以此類推。而且視圖的列名是在視圖名稱之后的列表中定義的。
需要注意的是視圖名在數據庫中需要是唯一的,不能與其他視圖和表重名。
視圖不僅可以基于真實表,我們也可以在視圖的基礎上繼續創建視圖。
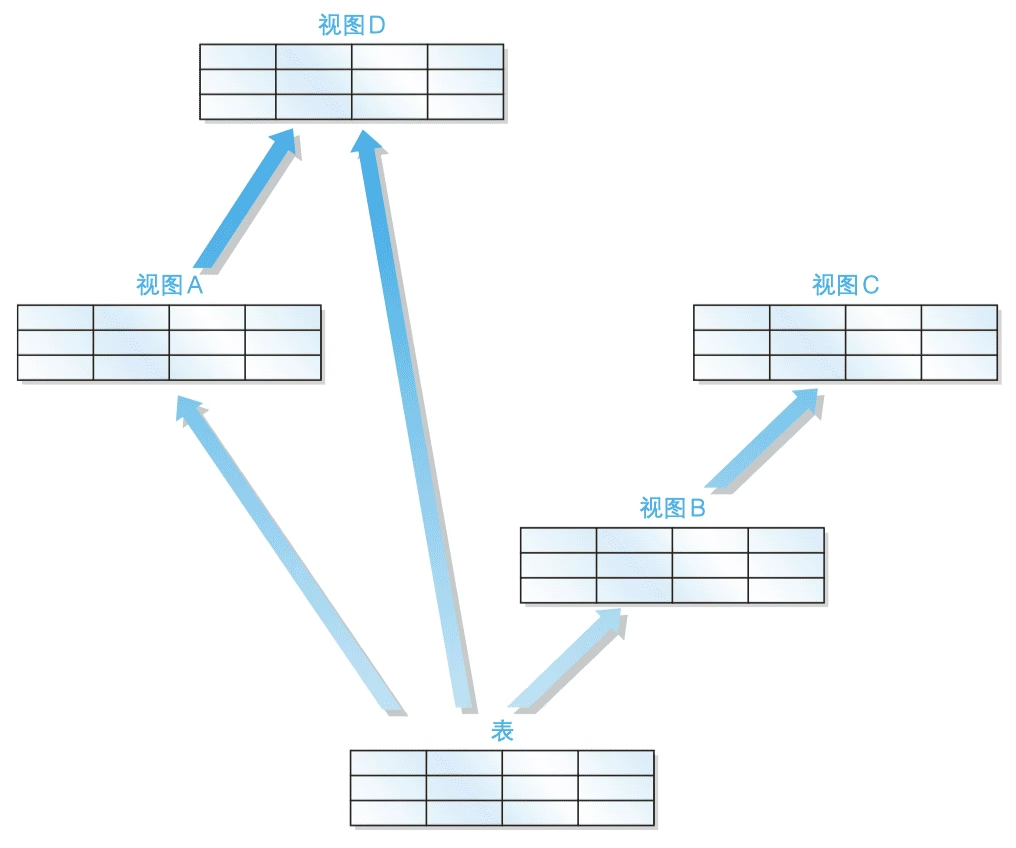
圖片來源:《sql基礎教程第2版》
雖然在視圖上繼續創建視圖的語法沒有錯誤,但是我們還是應該盡量避免這種操作。這是因為對多數 DBMS 來說, 多重視圖會降低 SQL 的性能。
- 注意事項
需要注意的是在一般的DBMS中定義視圖時不能使用ORDER BY語句。下面這樣定義視圖是錯誤的。
CREATE VIEW productsum (product_type, cnt_product)
AS
SELECT product_type, COUNT(*)FROM productGROUP BY product_typeORDER BY product_type;
為什么不能使用 ORDER BY 子句呢?這是因為視圖和表一樣,數據行都是沒有順序的。
在 MySQL中視圖的定義是允許使用 ORDER BY 語句的,但是若從特定視圖進行選擇,而該視圖使用了自己的 ORDER BY 語句,則視圖定義中的 ORDER BY 將被忽略。
- 基于單表的視圖
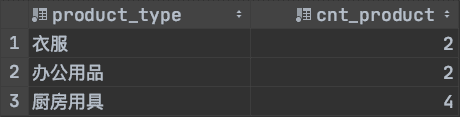
我們在product表的基礎上創建一個視圖,如下:
CREATE VIEW productsum (product_type, cnt_product)
AS
SELECT product_type, COUNT(*)FROM productGROUP BY product_type ;
創建的視圖如下圖所示:
- 基于多表的視圖
為了學習多表視圖,我們再創建一張表,相關代碼如下:
CREATE TABLE shop_product
(shop_id CHAR(4) NOT NULL,shop_name VARCHAR(200) NOT NULL,product_id CHAR(4) NOT NULL,quantity INTEGER NOT NULL,PRIMARY KEY (shop_id, product_id));
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000A', '東京', '0001', 30);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000A', '東京', '0002', 50);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000A', '東京', '0003', 15);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0002', 30);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0003', 120);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0004', 20);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0006', 10);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0007', 40);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0003', 20);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0004', 50);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0006', 90);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0007', 70);
INSERT INTO shop_product (shop_id, shop_name, product_id, quantity) VALUES ('000D', '福岡', '0001', 100);
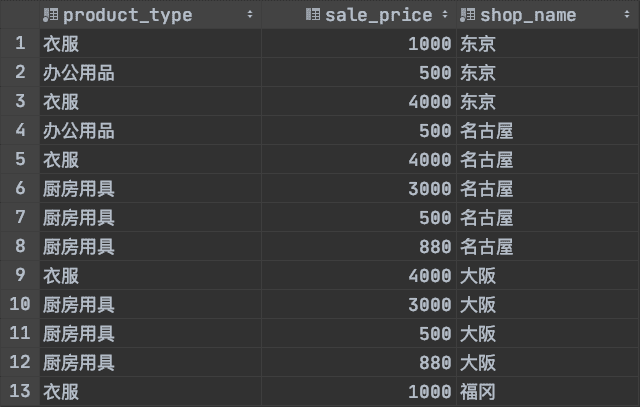
我們在product表和shop_product表的基礎上創建視圖。
CREATE VIEW view_shop_product(product_type, sale_price, shop_name)
AS
SELECT product_type, sale_price, shop_nameFROM product,shop_productWHERE product.product_id = shop_product.product_id;
創建的視圖如下圖所示
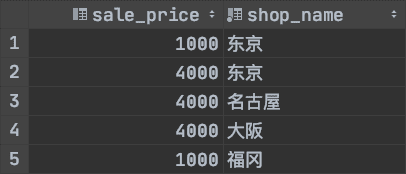
我們可以在這個視圖的基礎上進行查詢
SELECT sale_price, shop_nameFROM view_shop_productWHERE product_type = '衣服';
查詢結果為:
3.1.5 如何修改視圖結構
修改視圖結構的基本語法如下:
ALTER VIEW <視圖名> AS <SELECT語句>
其中視圖名在數據庫中需要是唯一的,不能與其他視圖和表重名。
當然也可以通過將當前視圖刪除然后重新創建的方式達到修改的效果。(對于數據庫底層是不是也是這樣操作的呢,你可以自己探索一下。)
- 修改視圖
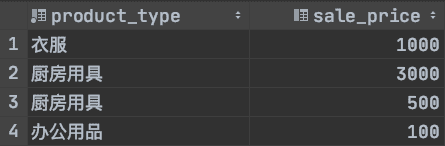
我們修改上方的productSum視圖為
ALTER VIEW productSumASSELECT product_type, sale_priceFROM ProductWHERE regist_date > '2009-09-11';
此時productSum視圖內容如下圖所示
3.1.6 如何更新視圖內容
因為視圖是一個虛擬表,所以對視圖的操作就是對底層基礎表的操作,所以在修改時只有滿足底層基本表的定義才能成功修改。
對于一個視圖來說,如果包含以下結構的任意一種都是不可以被更新的:
- 聚合函數 SUM()、MIN()、MAX()、COUNT() 等。
- DISTINCT 關鍵字。
- GROUP BY 子句。
- HAVING 子句。
- UNION 或 UNION ALL 運算符。
- FROM 子句中包含多個表。
視圖歸根結底還是從表派生出來的,因此,如果原表可以更新,那么 視圖中的數據也可以更新。反之亦然,如果視圖發生了改變,而原表沒有進行相應更新的話,就無法保證數據的一致性了。
- 更新視圖
因為我們剛剛修改的productSum視圖不包括以上的限制條件,我們來嘗試更新一下視圖
UPDATE productsumSET sale_price = '5000'WHERE product_type = '辦公用品';
此時我們再查看productSum視圖,可以發現數據已經更新了
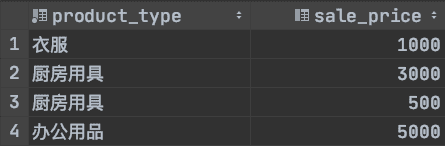
此時觀察原表也可以發現數據也被更新了

不知道大家看到這個結果會不會有疑問,剛才修改視圖的時候是設置product_type='辦公用品’的商品的sale_price=5000,為什么原表的數據只有一條做了修改呢?
還是因為視圖的定義,視圖只是原表的一個窗口,所以它修改也只能修改透過窗口能看到的內容。
注意:這里雖然修改成功了,但是并不推薦這種使用方式。而且我們在創建視圖時也盡量使用限制不允許通過視圖來修改表
3.1.7 如何刪除視圖
刪除視圖的基本語法如下:
DROP VIEW <視圖名1> [ , <視圖名2> …]
注意:需要有相應的權限才能成功刪除。
- 刪除視圖
我們刪除剛才創建的productSum視圖
DROP VIEW productSum;
如果我們繼續操作這個視圖的話就會提示當前操作的內容不存在。
3.2 子查詢
我們先來看一個語句(僅做示例,未提供相關數據)
SELECT stu_name
FROM (SELECT stu_name, COUNT(*) AS stu_cntFROM students_infoGROUP BY stu_age) AS studentSum;
這個語句看起來很好理解,其中使用括號括起來的sql語句首先執行,執行成功后再執行外面的sql語句。但是我們上一節提到的視圖也是根據SELECT語句創建視圖然后在這個基礎上再進行查詢。那么什么是子查詢呢?子查詢和視圖又有什么關系呢?
3.2.1 什么是子查詢
子查詢指一個查詢語句嵌套在另一個查詢語句內部的查詢,這個特性從 MySQL 4.1 開始引入,在 SELECT 子句中先計算子查詢,子查詢結果作為外層另一個查詢的過濾條件,查詢可以基于一個表或者多個表。
3.2.2 子查詢和視圖的關系
子查詢就是將用來定義視圖的 SELECT 語句直接用于 FROM 子句當中。其中AS studentSum可以看作是子查詢的名稱,而且由于子查詢是一次性的,所以子查詢不會像視圖那樣保存在存儲介質中, 而是在 SELECT 語句執行之后就消失了。
3.2.3 嵌套子查詢
與在視圖上再定義視圖類似,子查詢也沒有具體的限制,例如我們可以這樣
SELECT product_type, cnt_product
FROM (SELECT *FROM (SELECT product_type, COUNT(*) AS cnt_productFROM product GROUP BY product_type) AS productsumWHERE cnt_product = 4) AS productsum2;
其中最內層的子查詢我們將其命名為productSum,這條語句根據product_type分組并查詢個數,第二層查詢中將個數為4的商品查詢出來,最外層查詢product_type和cnt_product兩列。
雖然嵌套子查詢可以查詢出結果,但是隨著子查詢嵌套的層數的疊加,SQL語句不僅會難以理解而且執行效率也會很差,所以要盡量避免這樣的使用。
3.2.4 標量子查詢
標量就是單一的意思,那么標量子查詢也就是單一的子查詢,那什么叫做單一的子查詢呢?
所謂單一就是要求我們執行的SQL語句只能返回一個值,也就是要返回表中具體的某一行的某一列。例如我們有下面這樣一張表
product_id | product_name | sale_price
------------+-------------+----------
0003 | 運動T恤 | 4000
0004 | 菜刀 | 3000
0005 | 高壓鍋 | 6800
那么我們執行一次標量子查詢后是要返回類似于,“0004”,“菜刀”這樣的結果。
3.2.5 標量子查詢有什么用
我們現在已經知道標量子查詢可以返回一個值了,那么它有什么作用呢?
直接這樣想可能會有些困難,讓我們看幾個具體的需求:
- 查詢出銷售單價高于平均銷售單價的商品
- 查詢出注冊日期最晚的那個商品
你有思路了嗎?
讓我們看如何通過標量子查詢語句查詢出銷售單價高于平均銷售單價的商品。
SELECT product_id, product_name, sale_priceFROM productWHERE sale_price > (SELECT AVG(sale_price) FROM product);
上面的這條語句首先后半部分查詢出product表中的平均售價,前面的sql語句在根據WHERE條件挑選出合適的商品。
由于標量子查詢的特性,導致標量子查詢不僅僅局限于 WHERE 子句中,通常任何可以使用單一值的位置都可以使用。也就是說, 能夠使用常數或者列名的地方,無論是 SELECT 子句、GROUP BY 子句、HAVING 子句,還是 ORDER BY 子句,幾乎所有的地方都可以使用。
我們還可以這樣使用標量子查詢:
SELECT product_id,product_name,sale_price,(SELECT AVG(sale_price)FROM product) AS avg_priceFROM product;
你能猜到這段代碼的運行結果是什么嗎?運行一下看看與你想象的結果是否一致。
3.2.6 關聯子查詢
- 什么是關聯子查詢
關聯子查詢既然包含關聯兩個字那么一定意味著查詢與子查詢之間存在著聯系。這種聯系是如何建立起來的呢?
我們先看一個例子:
SELECT product_type, product_name, sale_priceFROM product AS p1WHERE sale_price > (SELECT AVG(sale_price)FROM product AS p2WHERE p1.product_type = p2.product_typeGROUP BY product_type);
你能理解這個例子在做什么操作么?先來看一下這個例子的執行結果
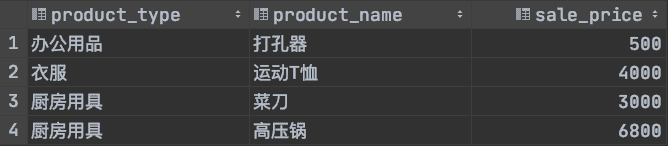
通過上面的例子我們大概可以猜到嗎,關聯子查詢就是通過一些標志將內外兩層的查詢連接起來起到過濾數據的目的,接下來我們就一起看一下關聯子查詢的具體內容吧。
- 關聯子查詢與子查詢的聯系
還記得我們之前的那個例子么查詢出銷售單價高于平均銷售單價的商品,這個例子的SQL語句如下
SELECT product_id, product_name, sale_priceFROM productWHERE sale_price > (SELECT AVG(sale_price) FROM product);
我們再來看一下這個需求選取出各商品種類中高于該商品種類的平均銷售單價的商品。SQL語句如下:
SELECT product_type, product_name, sale_priceFROM product ASp1WHERE sale_price > (SELECT AVG(sale_price)FROM product ASp2WHERE p1.product_type =p2.product_typeGROUP BY product_type);
可以看出上面這兩個語句的區別嗎?
在第二條SQL語句也就是關聯子查詢中我們將外面的product表標記為p1,將內部的product設置為p2,而且通過WHERE語句連接了兩個查詢。
但是如果剛接觸的話一定會比較疑惑關聯查詢的執行過程,這里有一個博客講的比較清楚。在這里我們簡要的概括為:
- 首先執行不帶WHERE的主查詢
- 根據主查詢訊結果匹配product_type,獲取子查詢結果
- 將子查詢結果再與主查詢結合執行完整的SQL語句
在子查詢中像標量子查詢,嵌套子查詢或者關聯子查詢可以看作是子查詢的一種操作方式即可。
小結
視圖和子查詢是數據庫操作中較為基礎的內容,對于一些復雜的查詢需要使用子查詢加一些條件語句組合才能得到正確的結果。但是無論如何對于一個SQL語句來說都不應該設計的層數非常深且特別復雜,不僅可讀性差而且執行效率也難以保證,所以盡量有簡潔的語句來完成需要的功能。
練習題-第一部分
3.1
創建出滿足下述三個條件的視圖(視圖名稱為 ViewPractice5_1)。使用 product(商品)表作為參照表,假設表中包含初始狀態的 8 行數據。
- 條件 1:銷售單價大于等于 1000 日元。
- 條件 2:登記日期是 2009 年 9 月 20 日。
- 條件 3:包含商品名稱、銷售單價和登記日期三列。
對該視圖執行 SELECT 語句的結果如下所示。
SELECT * FROM ViewPractice5_1;
執行結果
product_name | sale_price | regist_date
--------------+------------+------------
T恤衫 | 1000 | 2009-09-20
菜刀 | 3000 | 2009-09-20
CREATE VIEW ViewPractice5_1 AS
SELECT product_name , sale_price , regist_dateFROM product
WHERE sale_price >= 1000AND regist_date = '2009-09-20';
3.2
向習題一中創建的視圖 ViewPractice5_1 中插入如下數據,會得到什么樣的結果呢?
INSERT INTO ViewPractice5_1 VALUES (' 刀子 ', 300, '2009-11-02');
答:插入時會報錯,因為視圖只有原表的三個字段,而表的其他字段有非空約束,所以插入三個字段不滿足表約束。
3.3
請根據如下結果編寫 SELECT 語句,其中 sale_price_all 列為全部商品的平均銷售單價。
product_id | product_name | product_type | sale_price | sale_price_all
------------+-------------+--------------+------------+---------------------
0001 | T恤衫 | 衣服 | 1000 | 2097.5000000000000000
0002 | 打孔器 | 辦公用品 | 500 | 2097.5000000000000000
0003 | 運動T恤 | 衣服 | 4000 | 2097.5000000000000000
0004 | 菜刀 | 廚房用具 | 3000 | 2097.5000000000000000
0005 | 高壓鍋 | 廚房用具 | 6800 | 2097.5000000000000000
0006 | 叉子 | 廚房用具 | 500 | 2097.5000000000000000
0007 | 擦菜板 | 廚房用具 | 880 | 2097.5000000000000000
0008 | 圓珠筆 | 辦公用品 | 100 | 2097.5000000000000000
SELECT product_id,product_name,product_type,sale_price,(SELECT AVG(sale_price) FROM product) AS sale_price_allFROM product;
3.4
請根據習題一中的條件編寫一條 SQL 語句,創建一幅包含如下數據的視圖(名稱為AvgPriceByType)。
product_id | product_name | product_type | sale_price | avg_sale_price
------------+-------------+--------------+------------+---------------------
0001 | T恤衫 | 衣服 | 1000 |2500.0000000000000000
0002 | 打孔器 | 辦公用品 | 500 | 300.0000000000000000
0003 | 運動T恤 | 衣服 | 4000 |2500.0000000000000000
0004 | 菜刀 | 廚房用具 | 3000 |2795.0000000000000000
0005 | 高壓鍋 | 廚房用具 | 6800 |2795.0000000000000000
0006 | 叉子 | 廚房用具 | 500 |2795.0000000000000000
0007 | 擦菜板 | 廚房用具 | 880 |2795.0000000000000000
0008 | 圓珠筆 | 辦公用品 | 100 | 300.0000000000000000
提示:其中的關鍵是 avg_sale_price 列。與習題三不同,這里需要計算出的 是各商品種類的平均銷售單價。這與使用關聯子查詢所得到的結果相同。 也就是說,該列可以使用關聯子查詢進行創建。問題就是應該在什么地方使用這個關聯子查詢。
CREATE VIEW AvgPriceByType AS
SELECT product_id,product_name,product_type,sale_price,(SELECT AVG(sale_price)FROM product p2WHERE p1.product_type = p2.product_typeGROUP BY p1.product_type) AS avg_sale_price
FROM product p1;
-- 確認視圖內容
SELECT * FROM AvgPriceByType;
3.3 各種各樣的函數
sql自帶了各種各樣的函數,極大提高了sql語言的便利性。
所謂函數,類似一個黑盒子,你給它一個輸入值,它便按照預設的程序定義給出返回值,輸入值稱為參數。
函數大致分為如下幾類:
- 算術函數 (用來進行數值計算的函數)
- 字符串函數 (用來進行字符串操作的函數)
- 日期函數 (用來進行日期操作的函數)
- 轉換函數 (用來轉換數據類型和值的函數)
- 聚合函數 (用來進行數據聚合的函數)
函數總個數超過200個,不需要完全記住,常用函數有 30~50 個,其他不常用的函數使用時查閱文檔即可。
3.3.1 算數函數
- **+ - * /**四則運算在之前的章節介紹過,此處不再贅述。
為了演示其他的幾個算數函數,在此構造samplemath表
-- DDL :創建表
USE shop;
DROP TABLE IF EXISTS samplemath;
CREATE TABLE samplemath
(m float(10,3),
n INT,
p INT);-- DML :插入數據
START TRANSACTION; -- 開始事務
INSERT INTO samplemath(m, n, p) VALUES (500, 0, NULL);
INSERT INTO samplemath(m, n, p) VALUES (-180, 0, NULL);
INSERT INTO samplemath(m, n, p) VALUES (NULL, NULL, NULL);
INSERT INTO samplemath(m, n, p) VALUES (NULL, 7, 3);
INSERT INTO samplemath(m, n, p) VALUES (NULL, 5, 2);
INSERT INTO samplemath(m, n, p) VALUES (NULL, 4, NULL);
INSERT INTO samplemath(m, n, p) VALUES (8, NULL, 3);
INSERT INTO samplemath(m, n, p) VALUES (2.27, 1, NULL);
INSERT INTO samplemath(m, n, p) VALUES (5.555,2, NULL);
INSERT INTO samplemath(m, n, p) VALUES (NULL, 1, NULL);
INSERT INTO samplemath(m, n, p) VALUES (8.76, NULL, NULL);
COMMIT; -- 提交事務
-- 查詢表內容
SELECT * FROM samplemath;
+----------+------+------+
| m | n | p |
+----------+------+------+
| 500.000 | 0 | NULL |
| -180.000 | 0 | NULL |
| NULL | NULL | NULL |
| NULL | 7 | 3 |
| NULL | 5 | 2 |
| NULL | 4 | NULL |
| 8.000 | NULL | 3 |
| 2.270 | 1 | NULL |
| 5.555 | 2 | NULL |
| NULL | 1 | NULL |
| 8.760 | NULL | NULL |
+----------+------+------+
11 rows in set (0.00 sec)
- ABS – 絕對值
語法:ABS( 數值 )
ABS 函數用于計算一個數字的絕對值,表示一個數到原點的距離。
當 ABS 函數的參數為NULL時,返回值也是NULL。
- MOD – 求余數
語法:MOD( 被除數,除數 )
MOD 是計算除法余數(求余)的函數,是 modulo 的縮寫。小數沒有余數的概念,只能對整數列求余數。
注意:主流的 DBMS 都支持 MOD 函數,只有SQL Server 不支持該函數,其使用**%**符號來計算余數。
- ROUND – 四舍五入
語法:ROUND( 對象數值,保留小數的位數 )
ROUND 函數用來進行四舍五入操作。
注意:當參數 保留小數的位數 為變量時,可能會遇到錯誤,請謹慎使用變量。
SELECT m,
ABS(m)ASabs_col ,
n, p,
MOD(n, p) AS mod_col,
ROUND(m,1)ASround_colS
FROM samplemath;
+----------+---------+------+------+---------+-----------+
| m | abs_col | n | p | mod_col | round_col |
+----------+---------+------+------+---------+-----------+
| 500.000 | 500.000 | 0 | NULL | NULL | 500.0 |
| -180.000 | 180.000 | 0 | NULL | NULL | -180.0 |
| NULL | NULL | NULL | NULL | NULL | NULL |
| NULL | NULL | 7 | 3 | 1 | NULL |
| NULL | NULL | 5 | 2 | 1 | NULL |
| NULL | NULL | 4 | NULL | NULL | NULL |
| 8.000 | 8.000 | NULL | 3 | NULL | 8.0 |
| 2.270 | 2.270 | 1 | NULL | NULL | 2.3 |
| 5.555 | 5.555 | 2 | NULL | NULL | 5.6 |
| NULL | NULL | 1 | NULL | NULL | NULL |
| 8.760 | 8.760 | NULL | NULL | NULL | 8.8 |
+----------+---------+------+------+---------+-----------+
11 rows in set (0.08 sec)
3.3.2 字符串函數
字符串函數也經常被使用,為了學習字符串函數,在此我們構造samplestr表。
-- DDL :創建表
USE shop;
DROP TABLE IF EXISTS samplestr;
CREATE TABLE samplestr
(str1 VARCHAR (40),
str2 VARCHAR (40),
str3 VARCHAR (40)
);
-- DML:插入數據
START TRANSACTION;
INSERT INTO samplestr (str1, str2, str3) VALUES ('opx', 'rt', NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('abc', 'def', NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('太陽', '月亮', '火星');
INSERT INTO samplestr (str1, str2, str3) VALUES ('aaa', NULL, NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES (NULL, 'xyz', NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('@!#$%', NULL, NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('ABC', NULL, NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('aBC', NULL, NULL);
INSERT INTO samplestr (str1, str2, str3) VALUES ('abc哈哈', 'abc', 'ABC');
INSERT INTO samplestr (str1, str2, str3) VALUES ('abcdefabc', 'abc', 'ABC');
INSERT INTO samplestr (str1, str2, str3) VALUES ('micmic', 'i', 'I');
COMMIT;
-- 確認表中的內容
SELECT * FROM samplestr;
+-----------+------+------+
| str1 | str2 | str3 |
+-----------+------+------+
| opx | rt | NULL |
| abc | def | NULL |
| 太陽 | 月亮 | 火星 |
| aaa | NULL | NULL |
| NULL | xyz | NULL |
| @!#$% | NULL | NULL |
| ABC | NULL | NULL |
| aBC | NULL | NULL |
| abc哈哈 | abc | ABC |
| abcdefabc | abc | ABC |
| micmic | i | I |
+-----------+------+------+
11 rows in set (0.00 sec)
- CONCAT – 拼接
語法:CONCAT(str1, str2, str3)
MySQL中使用 CONCAT 函數進行拼接。
- LENGTH – 字符串長度
語法:LENGTH( 字符串 )
- LOWER – 小寫轉換
LOWER 函數只能針對英文字母使用,它會將參數中的字符串全都轉換為小寫。該函數不適用于英文字母以外的場合,不影響原本就是小寫的字符。
類似的, UPPER 函數用于大寫轉換。
- REPLACE – 字符串的替換
語法:REPLACE( 對象字符串,替換前的字符串,替換后的字符串 )
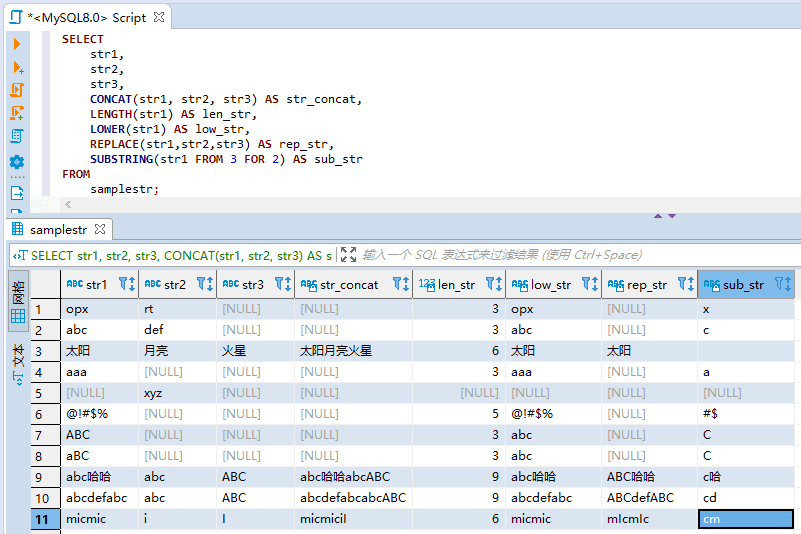
- SUBSTRING – 字符串的截取
語法:SUBSTRING (對象字符串 FROM 截取的起始位置 FOR 截取的字符數)
使用 SUBSTRING 函數 可以截取出字符串中的一部分字符串。截取的起始位置從字符串最左側開始計算,索引值起始為1。
- (擴展內容)SUBSTRING_INDEX – 字符串按索引截取
語法:SUBSTRING_INDEX (原始字符串, 分隔符,n)
該函數用來獲取原始字符串按照分隔符分割后,第 n 個分隔符之前(或之后)的子字符串,支持正向和反向索引,索引起始值分別為 1 和 -1。
SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);
+------------------------------------------+
| SUBSTRING_INDEX('www.mysql.com', '.', 2) |
+------------------------------------------+
| www.mysql |
+------------------------------------------+
1 row in set (0.00 sec)
SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2);
+-------------------------------------------+
| SUBSTRING_INDEX('www.mysql.com', '.', -2) |
+-------------------------------------------+
| mysql.com |
+-------------------------------------------+
1 row in set (0.00 sec)
獲取第1個元素比較容易,獲取第2個元素/第n個元素可以采用二次拆分的寫法。
SELECT SUBSTRING_INDEX('www.mysql.com', '.', 1);
+------------------------------------------+
| SUBSTRING_INDEX('www.mysql.com', '.', 1) |
+------------------------------------------+
| www |
+------------------------------------------+
1 row in set (0.00 sec)
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('www.mysql.com', '.', 2), '.', -1);
+--------------------------------------------------------------------+
| SUBSTRING_INDEX(SUBSTRING_INDEX('www.mysql.com', '.', 2), '.', -1) |
+--------------------------------------------------------------------+
| mysql |
+--------------------------------------------------------------------+
1 row in set (0.00 sec)
3.3.3 日期函數
不同DBMS的日期函數語法各有不同,本課程介紹一些被標準 SQL 承認的可以應用于絕大多數 DBMS 的函數。特定DBMS的日期函數查閱文檔即可。
- CURRENT_DATE – 獲取當前日期
SELECT CURRENT_DATE;
+--------------+
| CURRENT_DATE |
+--------------+
| 2020-08-08 |
+--------------+
1 row in set (0.00 sec)
- CURRENT_TIME – 當前時間
SELECT CURRENT_TIME;
+--------------+
| CURRENT_TIME |
+--------------+
| 17:26:09 |
+--------------+
1 row in set (0.00 sec)
- CURRENT_TIMESTAMP – 當前日期和時間
SELECT CURRENT_TIMESTAMP;
+---------------------+
| CURRENT_TIMESTAMP |
+---------------------+
| 2020-08-08 17:27:07 |
+---------------------+
1 row in set (0.00 sec)
- EXTRACT – 截取日期元素
語法:EXTRACT(日期元素 FROM 日期)
使用 EXTRACT 函數可以截取出日期數據中的一部分,例如“年”
“月”,或者“小時”“秒”等。該函數的返回值并不是日期類型而是數值類型
SELECT CURRENT_TIMESTAMP as now,
EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year,
EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month,
EXTRACT(DAY FROM CURRENT_TIMESTAMP) AS day,
EXTRACT(HOUR FROM CURRENT_TIMESTAMP) AS hour,
EXTRACT(MINUTE FROM CURRENT_TIMESTAMP) AS MINute,
EXTRACT(SECOND FROM CURRENT_TIMESTAMP) AS second;
+---------------------+------+-------+------+------+--------+--------+
| now | year | month | day | hour | MINute | second |
+---------------------+------+-------+------+------+--------+--------+
| 2020-08-08 17:34:38 | 2020 | 8 | 8 | 17 | 34 | 38 |
+---------------------+------+-------+------+------+--------+--------+
1 row in set (0.00 sec)
3.3.4 轉換函數
“轉換”這個詞的含義非常廣泛,在 SQL 中主要有兩層意思:一是數據類型的轉換,簡稱為類型轉換,在英語中稱為cast;另一層意思是值的轉換。
- CAST – 類型轉換
語法:CAST(轉換前的值 AS 想要轉換的數據類型)
-- 將字符串類型轉換為數值類型
SELECT CAST('0001' AS SIGNED INTEGER) AS int_col;
+---------+
| int_col |
+---------+
| 1 |
+---------+
1 row in set (0.00 sec)
-- 將字符串類型轉換為日期類型
SELECT CAST('2009-12-14' AS DATE) AS date_col;
+------------+
| date_col |
+------------+
| 2009-12-14 |
+------------+
1 row in set (0.00 sec)
- COALESCE – 將NULL轉換為其他值
語法:COALESCE(數據1,數據2,數據3……)
COALESCE 是 SQL 特有的函數。該函數會返回可變參數 A 中左側開始第 1個不是NULL的值。參數個數是可變的,因此可以根據需要無限增加。
在 SQL 語句中將 NULL 轉換為其他值時就會用到轉換函數。
SELECT COALESCE(NULL, 11) AS col_1,
COALESCE(NULL, 'hello world', NULL) AS col_2,
COALESCE(NULL, NULL, '2020-11-01') AS col_3;
+-------+-------------+------------+
| col_1 | col_2 | col_3 |
+-------+-------------+------------+
| 11 | hello world | 2020-11-01 |
+-------+-------------+------------+
1 row in set (0.00 sec)
3.4 謂詞
3.4.1 什么是謂詞
謂詞就是返回值為真值的函數。包括TRUE / FALSE / UNKNOWN。
謂詞主要有以下幾個:
- LIKE
- BETWEEN
- IS NULL、IS NOT NULL
- IN
- EXISTS
3.4.2 LIKE謂詞 – 用于字符串的部分一致查詢
當需要進行字符串的部分一致查詢時需要使用該謂詞。
部分一致大體可以分為前方一致、中間一致和后方一致三種類型。
首先我們來創建一張表
-- DDL :創建表
CREATE TABLE samplelike
( strcol VARCHAR(6) NOT NULL,
PRIMARY KEY (strcol)
samplelike);
-- DML :插入數據
START TRANSACTION; -- 開始事務
INSERT INTO samplelike (strcol) VALUES ('abcddd');
INSERT INTO samplelike (strcol) VALUES ('dddabc');
INSERT INTO samplelike (strcol) VALUES ('abdddc');
INSERT INTO samplelike (strcol) VALUES ('abcdd');
INSERT INTO samplelike (strcol) VALUES ('ddabc');
INSERT INTO samplelike (strcol) VALUES ('abddc');
COMMIT; -- 提交事務
SELECT * FROM samplelike;
+--------+
| strcol |
+--------+
| abcdd |
| abcddd |
| abddc |
| abdddc |
| ddabc |
| dddabc |
+--------+
6 rows in set (0.00 sec)
- 前方一致:選取出“dddabc”
前方一致即作為查詢條件的字符串(這里是“ddd”)與查詢對象字符串起始部分相同。
SELECT *
FROM samplelike
WHERE strcol LIKE 'ddd%';
+--------+
| strcol |
+--------+
| dddabc |
+--------+
1 row in set (0.00 sec)
其中的**%**是代表“零個或多個任意字符串”的特殊符號,本例中代表“以ddd開頭的所有字符串”。
- 中間一致:選取出“abcddd”,“dddabc”,“abdddc”
中間一致即查詢對象字符串中含有作為查詢條件的字符串,無論該字符串出現在對象字
符串的最后還是中間都沒有關系。
SELECT *
FROM samplelike
WHERE strcol LIKE '%ddd%';
+--------+
| strcol |
+--------+
| abcddd |
| abdddc |
| dddabc |
+--------+
3 rows in set (0.00 sec)
- 后方一致:選取出“abcddd“
后方一致即作為查詢條件的字符串(這里是“ddd”)與查詢對象字符串的末尾部分相同。
SELECT *
FROM samplelike
WHERE strcol LIKE '%ddd';
+--------+
| strcol |
+--------+
| abcddd |
+--------+
1 row in set (0.00 sec)
綜合如上三種類型的查詢可以看出,查詢條件最寬松,也就是能夠取得最多記錄的是中間一致。這是因為它同時包含前方一致和后方一致的查詢結果。
- **_**下劃線匹配任意 1 個字符
使用 _(下劃線)來代替 %,與 % 不同的是,它代表了“任意 1 個字符”。
SELECT *
FROM samplelike
WHERE strcol LIKE 'abc__';
+--------+
| strcol |
+--------+
| abcdd |
+--------+
1 row in set (0.00 sec)
3.4.3 BETWEEN謂詞 – 用于范圍查詢
使用 BETWEEN 可以進行范圍查詢。該謂詞與其他謂詞或者函數的不同之處在于它使用了 3 個參數。
-- 選取銷售單價為100~ 1000元的商品
SELECT product_name, sale_price
FROM product
WHERE sale_price BETWEEN 100 AND 1000;
+--------------+------------+
| product_name | sale_price |
+--------------+------------+
| T恤 | 1000 |
| 打孔器 | 500 |
| 叉子 | 500 |
| 擦菜板 | 880 |
| 圓珠筆 | 100 |
+--------------+------------+
5 rows in set (0.00 sec)
BETWEEN 的特點就是結果中會包含 100 和 1000 這兩個臨界值,也就是閉區間。如果不想讓結果中包含臨界值,那就必須使用 < 和 >。
SELECT product_name, sale_price
FROM product
WHERE sale_price > 100
AND sale_price < 1000;
+--------------+------------+
| product_name | sale_price |
+--------------+------------+
| 打孔器 | 500 |
| 叉子 | 500 |
| 擦菜板 | 880 |
+--------------+------------+
3 rows in set (0.00 sec)
3.4.4 IS NULL、 IS NOT NULL – 用于判斷是否為NULL
為了選取出某些值為 NULL 的列的數據,不能使用 =,而只能使用特定的謂詞IS NULL。
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IS NULL;
+--------------+----------------+
| product_name | purchase_price |
+--------------+----------------+
| 叉子 | NULL |
| 圓珠筆 | NULL |
+--------------+----------------+
2 rows in set (0.00 sec)
與此相反,想要選取 NULL 以外的數據時,需要使用IS NOT NULL。
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IS NOT NULL;
+--------------+----------------+
| product_name | purchase_price |
+--------------+----------------+
| T恤 | 500 |
| 打孔器 | 320 |
| 運動T恤 | 2800 |
| 菜刀 | 2800 |
| 高壓鍋 | 5000 |
| 擦菜板 | 790 |
+--------------+----------------+
6 rows in set (0.00 sec)
3.4.5 IN謂詞 – OR的簡便用法
多個查詢條件取并集時可以選擇使用or語句。
-- 通過OR指定多個進貨單價進行查詢
SELECT product_name, purchase_price
FROM product
WHERE purchase_price = 320
OR purchase_price = 500
OR purchase_price = 5000;
+--------------+----------------+
| product_name | purchase_price |
+--------------+----------------+
| T恤 | 500 |
| 打孔器 | 320 |
| 高壓鍋 | 5000 |
+--------------+----------------+
3 rows in set (0.00 sec)
雖然上述方法沒有問題,但還是存在一點不足之處,那就是隨著希望選取的對象越來越多, SQL 語句也會越來越長,閱讀起來也會越來越困難。這時, 我們就可以使用IN 謂詞
`IN(值1, 值2, 值3, …)來替換上述 SQL 語句。
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IN (320, 500, 5000);
+--------------+----------------+
| product_name | purchase_price |
+--------------+----------------+
| T恤 | 500 |
| 打孔器 | 320 |
| 高壓鍋 | 5000 |
+--------------+----------------+
3 rows in set (0.00 sec)
上述語句簡潔了很多,可讀性大幅提高。
反之,希望選取出“進貨單價不是 320 元、 500 元、 5000 元”的商品時,可以使用否定形式NOT IN來實現。
SELECT product_name, purchase_price
FROM product
WHERE purchase_price NOT IN (320, 500, 5000);
+--------------+----------------+
| product_name | purchase_price |
+--------------+----------------+
| 運動T恤 | 2800 |
| 菜刀 | 2800 |
| 擦菜板 | 790 |
+--------------+----------------+
3 rows in set (0.00 sec)
需要注意的是,在使用IN 和 NOT IN 時是無法選取出NULL數據的。
實際結果也是如此,上述兩組結果中都不包含進貨單價為 NULL 的叉子和圓珠筆。 NULL 只能使用 IS NULL 和 IS NOT NULL 來進行判斷。
3.4.6 使用子查詢作為IN謂詞的參數
- IN和子查詢
IN 謂詞(NOT IN 謂詞)具有其他謂詞所沒有的用法,那就是可以使用子查詢作為其參數。我們已經在 5-2 節中學習過了,子查詢就是 SQL內部生成的表,因此也可以說“能夠將表作為 IN 的參數”。同理,我們還可以說“能夠將視圖作為 IN 的參數”。
在此,我們創建一張新表shopproduct顯示出哪些商店銷售哪些商品。
-- DDL :創建表
DROP TABLE IF EXISTS shopproduct;
CREATE TABLE shopproduct
( shop_id CHAR(4) NOT NULL,shop_name VARCHAR(200) NOT NULL,
product_id CHAR(4) NOT NULL,quantity INTEGER NOT NULL,
PRIMARY KEY (shop_id, product_id) -- 指定主鍵
);
-- DML :插入數據
START TRANSACTION; -- 開始事務
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '東京', '0001', 30);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '東京', '0002', 50);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '東京', '0003', 15);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0002', 30);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0003', 120);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0004', 20);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0006', 10);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0007', 40);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0003', 20);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0004', 50);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0006', 90);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0007', 70);
INSERT INTO shopproduct (shop_id, shop_name, product_id, quantity) VALUES ('000D', '福岡', '0001', 100);
COMMIT; -- 提交事務
SELECT * FROM shopproduct;
+---------+-----------+------------+----------+
| shop_id | shop_name | product_id | quantity |
+---------+-----------+------------+----------+
| 000A | 東京 | 0001 | 30 |
| 000A | 東京 | 0002 | 50 |
| 000A | 東京 | 0003 | 15 |
| 000B | 名古屋 | 0002 | 30 |
| 000B | 名古屋 | 0003 | 120 |
| 000B | 名古屋 | 0004 | 20 |
| 000B | 名古屋 | 0006 | 10 |
| 000B | 名古屋 | 0007 | 40 |
| 000C | 大阪 | 0003 | 20 |
| 000C | 大阪 | 0004 | 50 |
| 000C | 大阪 | 0006 | 90 |
| 000C | 大阪 | 0007 | 70 |
| 000D | 福岡 | 0001 | 100 |
+---------+-----------+------------+----------+
13 rows in set (0.00 sec)
由于單獨使用商店編號(shop_id)或者商品編號(product_id)不能區分表中每一行數據
,因此指定了 2 列作為主鍵(primary key)對商店和商品進行組合,用來唯一確定每一行數據。
假設我么需要取出大阪在售商品的銷售單價,該如何實現呢?
第一步,取出大阪門店的在售商品 product_id ; 第二步,取出大阪門店在售商品的銷售單價 sale_price
-- step1:取出大阪門店的在售商品 `product_id`
SELECT product_id
FROM shopproduct
WHERE shop_id = '000C';
+------------+
| product_id |
+------------+
| 0003 |
| 0004 |
| 0006 |
| 0007 |
+------------+
4 rows in set (0.00 sec)
上述語句取出了大阪門店的在售商品編號,接下來,我么可以使用上述語句作為第二步的查詢條件來使用了。
-- step2:取出大阪門店在售商品的銷售單價 `sale_price`
SELECT product_name, sale_price
FROM product
WHERE product_id IN (SELECT product_idFROM shopproductWHERE shop_id = '000C');
+--------------+------------+
| product_name | sale_price |
+--------------+------------+
| 運動T恤 | 4000 |
| 菜刀 | 3000 |
| 叉子 | 500 |
| 擦菜板 | 880 |
+--------------+------------+
4 rows in set (0.00 sec)
根據第5章學習的知識,子查詢是從最內層開始執行的(由內而外),因此,上述語句的子查詢執行之后,sql 展開成下面的語句
-- 子查詢展開后的結果
SELECT product_name, sale_price
FROM product
WHERE product_id IN ('0003', '0004', '0006', '0007');
+--------------+------------+
| product_name | sale_price |
+--------------+------------+
| 運動T恤 | 4000 |
| 菜刀 | 3000 |
| 叉子 | 500 |
| 擦菜板 | 880 |
+--------------+------------+
4 rows in set (0.00 sec)
可以看到,子查詢轉換之后變為 in 謂詞用法,你理解了嗎?
或者,你會疑惑既然 in 謂詞也能實現,那為什么還要使用子查詢呢?這里給出兩點原因:
①:實際生活中,某個門店的在售商品是不斷變化的,使用 in 謂詞就需要經常更新 sql 語句,降低了效率,提高了維護成本;
②:實際上,某個門店的在售商品可能有成百上千個,手工維護在售商品編號真是個大工程。
使用子查詢即可保持 sql 語句不變,極大提高了程序的可維護性,這是系統開發中需要重點考慮的內容。
- NOT IN和子查詢
NOT IN 同樣支持子查詢作為參數,用法和 in 完全一樣。
-- NOT IN 使用子查詢作為參數,取出未在大阪門店銷售的商品的銷售單價
SELECT product_name, sale_priceFROM productWHERE product_id NOT IN (SELECT product_idFROM shopproductWHERE shop_id = '000A');
+--------------+------------+
| product_name | sale_price |
+--------------+------------+
| 菜刀 | 3000 |
| 高壓鍋 | 6800 |
| 叉子 | 500 |
| 擦菜板 | 880 |
| 圓珠筆 | 100 |
+--------------+------------+
5 rows in set (0.00 sec)
3.4.7 EXIST 謂詞
EXIST 謂詞的用法理解起來有些難度。
① EXIST 的使用方法與之前的都不相同
② 語法理解起來比較困難
③ 實際上即使不使用 EXIST,基本上也都可以使用 IN(或者 NOT IN)來代替
這么說的話,還有學習 EXIST 謂詞的必要嗎?答案是肯定的,因為一旦能夠熟練使用 EXIST 謂詞,就能體會到它極大的便利性。
不過,你不用過于擔心,本課程介紹一些基本用法,日后學習時可以多多留意 EXIST 謂詞的用法,以期能夠在達到 SQL 中級水平時掌握此用法。
- EXIST謂詞的使用方法
謂詞的作用就是 “判斷是否存在滿足某種條件的記錄”。
如果存在這樣的記錄就返回真(TRUE),如果不存在就返回假(FALSE)。
EXIST(存在)謂詞的主語是“記錄”。
我們繼續以 IN和子查詢 中的示例,使用 EXIST 選取出大阪門店在售商品的銷售單價。
SELECT product_name, sale_priceFROM product AS pWHERE EXISTS (SELECT *FROM shopproduct AS spWHERE sp.shop_id = '000C'AND sp.product_id = p.product_id);
+--------------+------------+
| product_name | sale_price |
+--------------+------------+
| 運動T恤 | 4000 |
| 菜刀 | 3000 |
| 叉子 | 500 |
| 擦菜板 | 880 |
+--------------+------------+
4 rows in set (0.00 sec)
- EXIST的參數
之前我們學過的謂詞,基本上都是像“列 LIKE 字符串”或者“ 列 BETWEEN 值 1 AND 值 2”這樣需要指定 2 個以上的參數,而 EXIST 的左側并沒有任何參數。因為 EXIST 是只有 1 個參數的謂詞。 所以,EXIST 只需要在右側書寫 1 個參數,該參數通常都會是一個子查詢。
(SELECT *FROM shopproduct AS spWHERE sp.shop_id = '000C'AND sp.product_id = p.product_id)
上面這樣的子查詢就是唯一的參數。確切地說,由于通過條件“SP.product_id = P.product_id”將 product 表和 shopproduct表進行了聯接,因此作為參數的是關聯子查詢。 EXIST 通常會使用關聯子查詢作為參數。
- 子查詢中的SELECT *
由于 EXIST 只關心記錄是否存在,因此返回哪些列都沒有關系。 EXIST 只會判斷是否存在滿足子查詢中 WHERE 子句指定的條件“商店編號(shop_id)為 ‘000C’,商品(product)表和商店
商品(shopproduct)表中商品編號(product_id)相同”的記錄,只有存在這樣的記錄時才返回真(TRUE)。
因此,使用下面的查詢語句,查詢結果也不會發生變化。
SELECT product_name, sale_priceFROM product AS pWHERE EXISTS (SELECT 1 -- 這里可以書寫適當的常數FROM shopproduct AS spWHERE sp.shop_id = '000C'AND sp.product_id = p.product_id);
+--------------+------------+
| product_name | sale_price |
+--------------+------------+
| 運動T恤 | 4000 |
| 菜刀 | 3000 |
| 叉子 | 500 |
| 擦菜板 | 880 |
+--------------+------------+
4 rows in set (0.00 sec)
大家可以把在 EXIST 的子查詢中書寫 SELECT * 當作 SQL 的一種習慣。
- 使用NOT EXIST替換NOT IN
就像 EXIST 可以用來替換 IN 一樣, NOT IN 也可以用NOT EXIST來替換。
下面的代碼示例取出,不在大阪門店銷售的商品的銷售單價。
SELECT product_name, sale_priceFROM product AS pWHERE NOT EXISTS (SELECT *FROM shopproduct AS spWHERE sp.shop_id = '000A'AND sp.product_id = p.product_id);
+--------------+------------+
| product_name | sale_price |
+--------------+------------+
| 菜刀 | 3000 |
| 高壓鍋 | 6800 |
| 叉子 | 500 |
| 擦菜板 | 880 |
| 圓珠筆 | 100 |
+--------------+------------+
5 rows in set (0.00 sec)
NOT EXIST 與 EXIST 相反,當“不存在”滿足子查詢中指定條件的記錄時返回真(TRUE)。
3.5 CASE 表達式
3.5.1 什么是 CASE 表達式?
CASE 表達式是函數的一種。是 SQL 中數一數二的重要功能,有必要好好學習一下。
CASE 表達式是在區分情況時使用的,這種情況的區分在編程中通常稱為(條件)分支。
CASE表達式的語法分為簡單CASE表達式和搜索CASE表達式兩種。由于搜索CASE表達式包含簡單CASE表達式的全部功能。本課程將重點介紹搜索CASE表達式。
語法:
CASE WHEN <求值表達式> THEN <表達式>WHEN <求值表達式> THEN <表達式>WHEN <求值表達式> THEN <表達式>...
ELSE <表達式>
END
上述語句執行時,依次判斷 when 表達式是否為真值,是則執行 THEN 后的語句,如果所有的 when 表達式均為假,則執行 ELSE 后的語句。
無論多么龐大的 CASE 表達式,最后也只會返回一個值。
3.5.2 CASE表達式的使用方法
假設現在 要實現如下結果:
A :衣服
B :辦公用品
C :廚房用具
因為表中的記錄并不包含“A : ”或者“B : ”這樣的字符串,所以需要在 SQL 中進行添加。并將“A : ”“B : ”“C : ”與記錄結合起來。
- 應用場景1:根據不同分支得到不同列值
SELECT product_name,CASE WHEN product_type = '衣服' THEN CONCAT('A : ',product_type)WHEN product_type = '辦公用品' THEN CONCAT('B : ',product_type)WHEN product_type = '廚房用具' THEN CONCAT('C : ',product_type)ELSE NULLEND AS abc_product_typeFROM product;
+--------------+------------------+
| product_name | abc_product_type |
+--------------+------------------+
| T恤 | A : 衣服 |
| 打孔器 | B : 辦公用品 |
| 運動T恤 | A : 衣服 |
| 菜刀 | C : 廚房用具 |
| 高壓鍋 | C : 廚房用具 |
| 叉子 | C : 廚房用具 |
| 擦菜板 | C : 廚房用具 |
| 圓珠筆 | B : 辦公用品 |
+--------------+------------------+
8 rows in set (0.00 sec)
ELSE 子句也可以省略不寫,這時會被默認為 ELSE NULL。但為了防止有人漏讀,還是希望大家能夠顯示地寫出 ELSE 子句。
此外, CASE 表達式最后的“END”是不能省略的,請大家特別注意不要遺漏。忘記書寫 END 會發生語法錯誤,這也是初學時最容易犯的錯誤。
- 應用場景2:實現列方向上的聚合
通常我們使用如下代碼實現行的方向上不同種類的聚合(這里是 sum)
SELECT product_type,SUM(sale_price) AS sum_priceFROM productGROUP BY product_type;
+--------------+-----------+
| product_type | sum_price |
+--------------+-----------+
| 衣服 | 5000 |
| 辦公用品 | 600 |
| 廚房用具 | 11180 |
+--------------+-----------+
3 rows in set (0.00 sec)
假如要在列的方向上展示不同種類額聚合值,該如何寫呢?
sum_price_clothes | sum_price_kitchen | sum_price_office
------------------+-------------------+-----------------5000 | 11180 | 600
聚合函數 + CASE WHEN 表達式即可實現該效果
-- 對按照商品種類計算出的銷售單價合計值進行行列轉換
SELECT SUM(CASE WHEN product_type = '衣服' THEN sale_price ELSE 0 END) AS sum_price_clothes,SUM(CASE WHEN product_type = '廚房用具' THEN sale_price ELSE 0 END) AS sum_price_kitchen,SUM(CASE WHEN product_type = '辦公用品' THEN sale_price ELSE 0 END) AS sum_price_officeFROM product;
+-------------------+-------------------+------------------+
| sum_price_clothes | sum_price_kitchen | sum_price_office |
+-------------------+-------------------+------------------+
| 5000 | 11180 | 600 |
+-------------------+-------------------+------------------+
1 row in set (0.00 sec)
- (擴展內容)應用場景3:實現行轉列
假設有如下圖表的結構
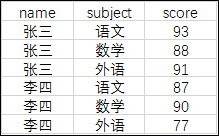
計劃得到如下的圖表結構
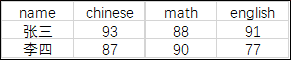
聚合函數 + CASE WHEN 表達式即可實現該轉換
-- CASE WHEN 實現數字列 score 行轉列
SELECT name,SUM(CASE WHEN subject = '語文' THEN score ELSE null END) as chinese,SUM(CASE WHEN subject = '數學' THEN score ELSE null END) as math,SUM(CASE WHEN subject = '外語' THEN score ELSE null END) as englishFROM scoreGROUP BY name;
+------+---------+------+---------+
| name | chinese | math | english |
+------+---------+------+---------+
| 張三 | 93 | 88 | 91 |
| 李四 | 87 | 90 | 77 |
+------+---------+------+---------+
2 rows in set (0.00 sec)
上述代碼實現了數字列 score 的行轉列,也可以實現文本列 subject 的行轉列
-- CASE WHEN 實現文本列 subject 行轉列
SELECT name,MAX(CASE WHEN subject = '語文' THEN subject ELSE null END) as chinese,MAX(CASE WHEN subject = '數學' THEN subject ELSE null END) as math,MIN(CASE WHEN subject = '外語' THEN subject ELSE null END) as englishFROM scoreGROUP BY name;
+------+---------+------+---------+
| name | chinese | math | english |
+------+---------+------+---------+
| 張三 | 語文 | 數學 | 外語 |
| 李四 | 語文 | 數學 | 外語 |
+------+---------+------+---------+
2 rows in set (0.00 sec
總結:
- 當待轉換列為數字時,可以使用SUM AVG MAX MIN等聚合函數;
- 當待轉換列為文本時,可以使用MAX MIN等聚合函數
練習題-第二部分
3.5
運算或者函數中含有 NULL 時,結果全都會變為NULL ?(判斷題)
正確
3.6
對本章中使用的 product(商品)表執行如下 2 條 SELECT 語句,能夠得到什么樣的結果呢?
①
SELECT product_name, purchase_priceFROM productWHERE purchase_price NOT IN (500, 2800, 5000);
**結果為: product_name | purchase_price | **
**| 打孔器 | 320 **
** | 擦菜板 | 790 **
** 不包含 purchase_price 為 NULL 的商品,這是因為 謂詞?法與 NULL 進??較。 **
②
SELECT product_name, purchase_priceFROM productWHERE purchase_price NOT IN (500, 2800, 5000, NULL);
**結果: 返回了零條記錄, 這是因為 NOT IN 的參數中不能包含 NULL ,否則,查詢結果通常為空。 **
3.7
按照銷售單價( sale_price)對練習 6.1 中的 product(商品)表中的商品進行如下分類。
- 低檔商品:銷售單價在1000日元以下(T恤衫、辦公用品、叉子、擦菜板、 圓珠筆)
- 中檔商品:銷售單價在1001日元以上3000日元以下(菜刀)
- 高檔商品:銷售單價在3001日元以上(運動T恤、高壓鍋)
請編寫出統計上述商品種類中所包含的商品數量的 SELECT 語句,結果如下所示。
執行結果
low_price | mid_price | high_price
----------+-----------+------------5 | 1 | 2
SELECT SUM(CASE WHEN sale_price <= 1000 THEN 1 ELSE 0 END) AS
low_price,SUM(CASE WHEN sale_price BETWEEN 1001 AND 3000 THEN 1 ELSE 0 END) AS
mid_price,SUM(CASE WHEN sale_price >= 3001 THEN 1 ELSE 0 END) AS
high_priceFROM product;




 - 用好strace)


)
)

覆蓋優化 - 附代碼)


RTTI運行時類型信息typeid和type_info)


 以上普通 APP 隱藏應用圖標問題探究及解決方案)


