【論文閱讀筆記】序列數據的數據增強方法綜述
摘要
?這篇論文探討了在深度學習模型中由于對精度的要求不斷提高導致模型框架結構變得更加復雜和深層的趨勢。隨著模型參數量的增加,訓練模型需要更多的數據,但人工標注數據的成本高昂,且由于客觀原因,獲取特定領域的數據可能變得困難。為了緩解數據不足的問題,作者提出了數據增強的概念,通過人為生成新的數據來增加數據量。
?論文指出,數據增強方法在計算機視覺領域取得了顯著的成果,并探討了這些方法是否可以應用在序列數據上。除了在時間域進行增強的方法(如翻轉、裁剪)外,論文還描述了在頻率域實現數據增強的方法。此外,除了基于經驗或知識設計的方法,還詳細論述了一系列基于生成對抗網絡(GAN)的通過機器學習模型自動生成數據的方法。
?論文對應用在自然語言文本、音頻信號和時間序列等多種序列數據上的數據增強方法進行了介紹,并涉及了它們在醫療診斷、情緒判斷等問題上的表現。盡管這些數據類型不同,論文總結了應用在它們上的數據增強方法背后的相似設計思路。最后,論文以這一思路為線索,梳理了應用在各類序列數據類型上的多種數據增強方法,并進行了一定的討論和展望
Introduction
- 線下增強:訓練之前,將整個數據集進行整體操作,再把增強之后的數據集喂入模型中
- 線上增強:更為常用的是線上增強(online augmentation),對即將送入到模型的每一批(batch)數據執行轉換,不必顯式地占用磁盤空間
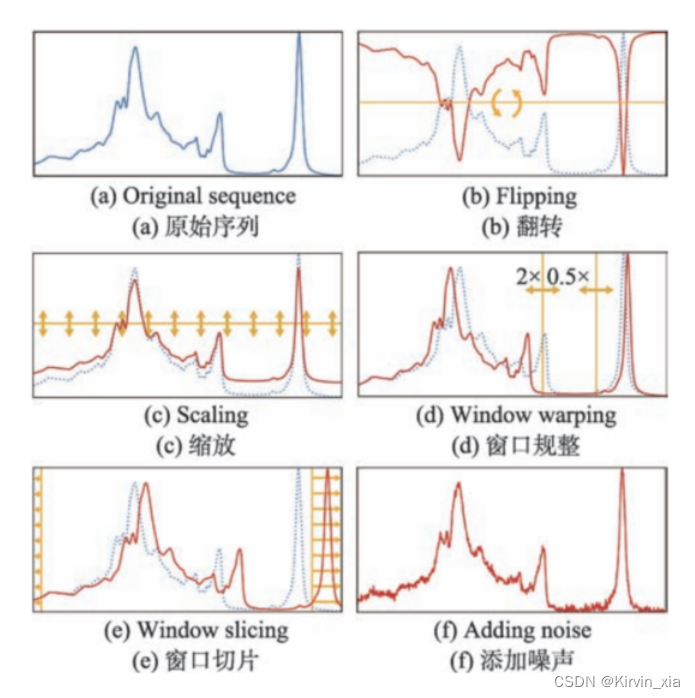
基礎方法
-
如變換取值維度的翻轉、縮放(scaling)或 變 換 時 間 維 度 的 窗 口 規 整
-
窗口切片:滑動窗口在時序數據不斷采樣,切片需要隨機性
-
添加噪聲:對于數值型序列數據,可以對每一個取值隨機地添加一定的噪聲來生成新的序列[4,8],且不影響序列的整體性質和標簽信息
- 通過對時間域數據進行傅里葉變換得到頻率域的振幅譜和相位譜
- 在振幅譜上隨機選擇區間,用基于原始振幅的統計參數重新生成一段信號替換,如圖2[9](b)所示;在相位譜上隨機選擇區間并添加白噪聲
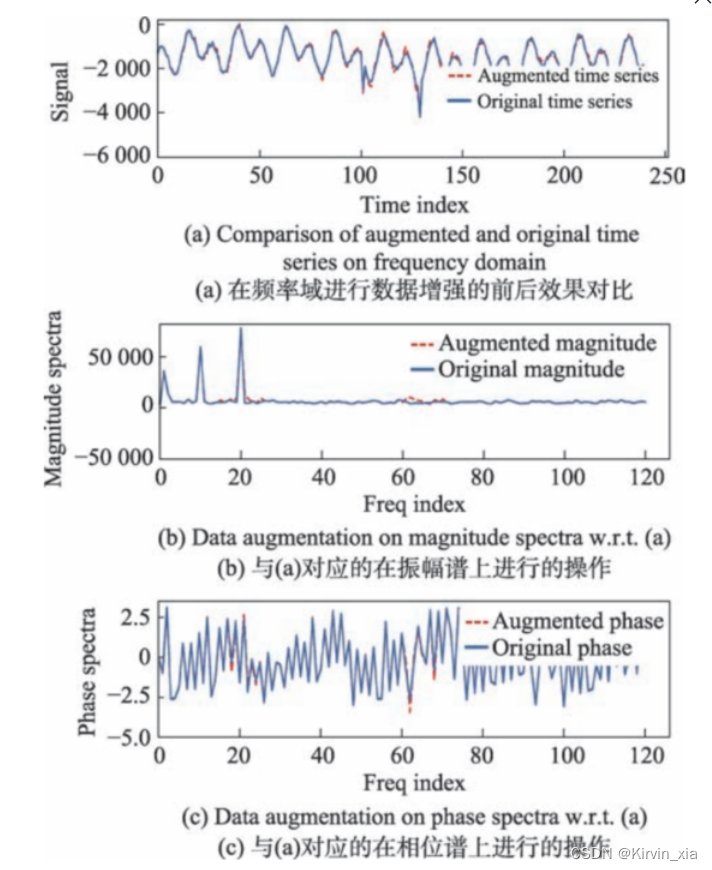
頻率域變換
- 首先對時序數據進行短時傅里葉變換,得到時序關系的譜特征,
- 再在普特征上面使用兩種數據增強的方法,一種是對每一個屬性做局部平均,將局部平均序列接在原始序列的后面
- 二是打亂順序,以增加數據的方差,這種方法會使得數據尺寸發生變化
- 由于STFT變換得到的普特征仍然是具有時序關系,這種數據增強方法也被認為是時間-頻率域進行的
- AAFT:賦值調整傅里葉變換可以實現只在頻率域進行數據增強
基于分解或混合的方法
STL方法的應用:使用STL(Seasonal and Trend Decomposition using Loess)方法將時間序列分解為基礎項、趨勢項、季節項和殘差項。
基礎項、趨勢項和季節項被認為是確定性部分,包含了原始序列的絕大部分信息。
Kegel等人基于相似矩陣和最近鄰搜索等方法為不同成分分配權重,以組合新的時間序列。
隨機的殘差項通過重新建模生成,利用其分布特征和自相關特征。Bergmeir等人的簡單方法:對時間序列信號進行分解,得到趨勢項和季節項之外的剩余項。
對剩余項進行有放回的重復采樣(bootstrap),生成新的剩余項序列,然后與前兩者混合成新的時間序列。
在M3數據集上的實驗證明,這種方法在月頻數據上對預測精度的提升較為顯著,但在長度較短的序列數據上表現一般。-
第一種方法以數據集為單位產生新的序列,而第二種方法以序列為單位產生新的序列。
-
第一種方法更能利用數據集整體的分布特征進行數據增強,避免可能發生在第二種方法中對不典型序列進行增強的情況。
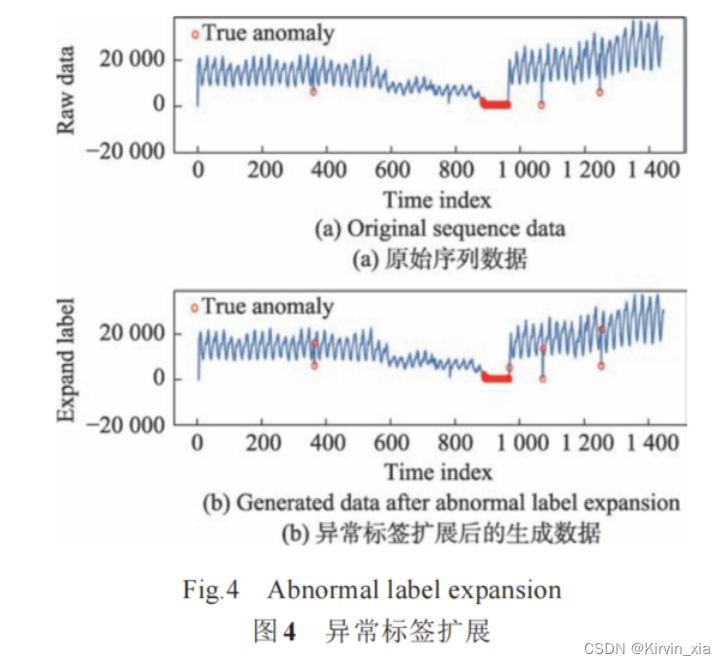
異常標簽擴展
- 對異常檢測任務的數據增強方法,稱為異常標簽擴展(label expansion)。該方法旨在解決類別不平衡的問題,尤其是為了增加數量較少的異常標簽。
基于深度學習的序列數據增強方法
-
使用生成對抗網絡生成數據
-
GAN由生成器和判別器組成
-
判別器判斷樣本是原始數據集的還是模型生成的,而生成器盡可能地最大化判別器判斷錯誤的概率,整個模型的優化是一個二元極大極小博弈

總結


——鼠標亂動惡搞小病毒(有資源))



)

)
:尺取法)


)





)
