任務背景
運維人員需要對系統和業務日志進行精準把控,便于分析系統和業務狀態。日志分布在不同的服務器上,傳統的使用傳統的方法依次登錄每臺服務器查看日志,既繁瑣又效率低下。所以我們需要==集中化==的日志管理工具將位于不同服務器上的日志收集到一起, 然后進行分析,展示。
前面我們學習過rsyslog,它就可以實現集中化的日志管理,可是rsyslog集中后的日志實現統計與檢索又成了一個問題。使用wc, grep, awk等相關命令可以實現統計與檢索,但如果要求更高的場景,這些命令也會力不從心。所以我們需要一套專業的日志收集分析展示系統。
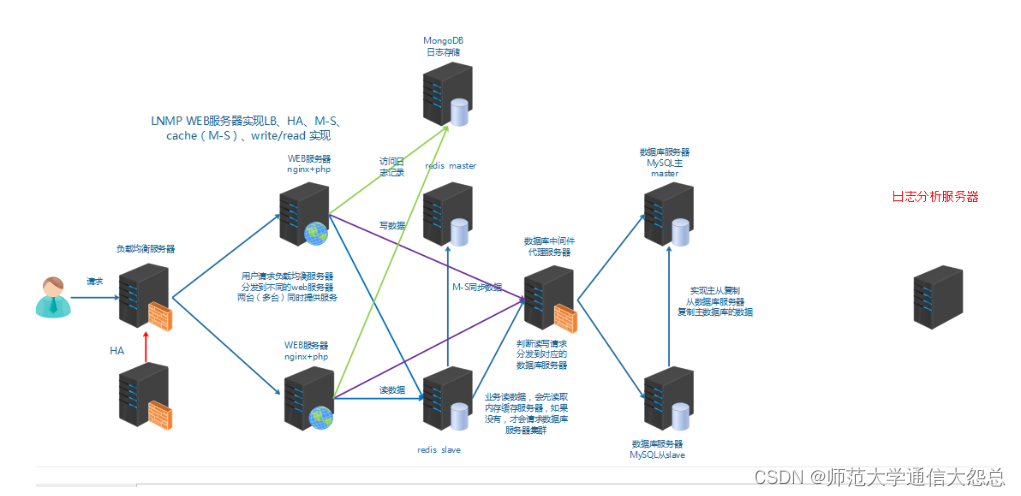
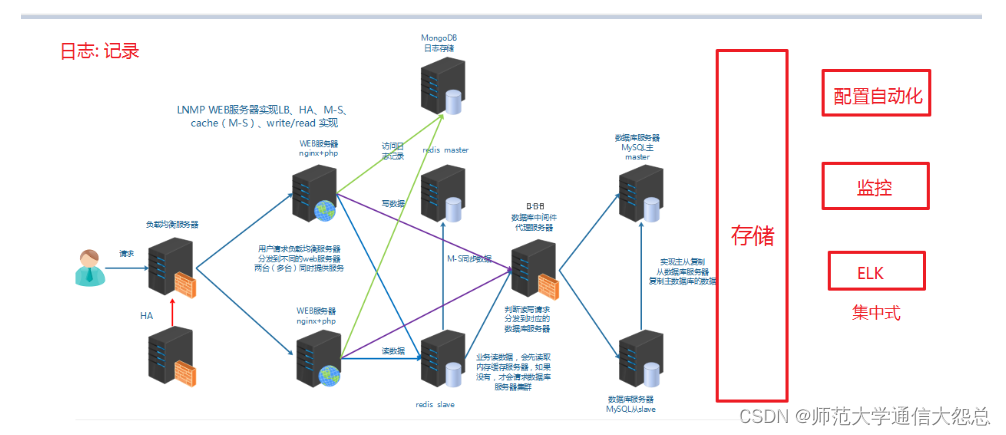

總結:
1、日志是用于記錄系統或業務的狀態
2、通過日志可以獲得系統或業務的狀態,并進行分析。
3、早期的日志是分散在各主機上
4、通過rsyslog實現本地日志管理,收集,輪轉,集中管理
5、早期的日志分析方法:wc,grep,awk
6、集中式的日志收集、分析、展示系統
任務要求
1, 搭建ELK集群
2, 收集日志信息并展示
任務拆解
1, 認識ELK
2, 部署elasticsearch集群并了解其基本概念
3, 安裝elasticsearch-head實現圖形化操作
4, 安裝logstash收集日志
5, 安裝kibana日志展示
6, 安裝file beat實現輕量級日志收集
學習目標
- 能夠說出ELK的應用場景
- 能夠區分ELK架構中elasticsearch,logstash,kibina三個軟件各自的主要功能
- 能夠單機部署elasticsearch
- 能夠部署elasticsearch集群
- 理解ELK中索引的概念
- 能夠部署logstash
- 能夠使用logstash做日志采集
認識ELK
ELK是一套開源的日志分析系統,由elasticsearch+logstash+Kibana組成。
官網說明:使用 Elastic 解決方案推動重要結果的交付 | Elastic
首先: 先一句話簡單了解E,L,K這三個軟件
elasticsearch: 分布式搜索引擎
logstash: 日志收集與過濾,輸出給elasticsearch
Kibana: 圖形化展示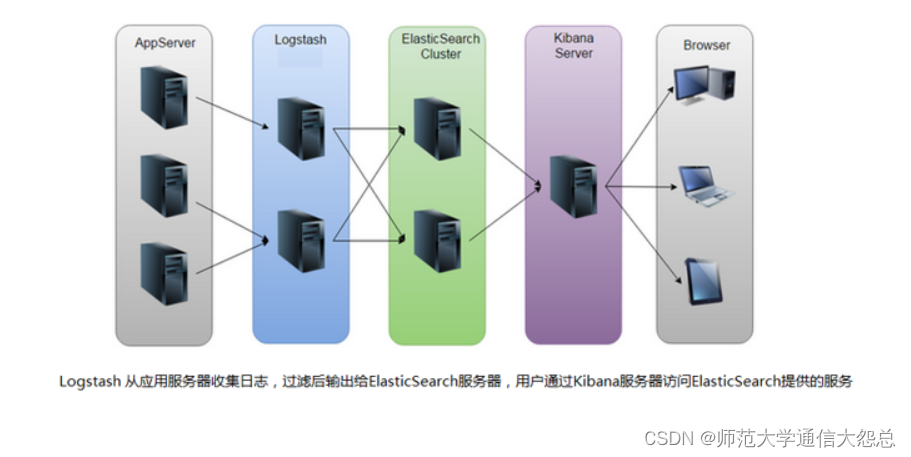
elk下載地址:下載 Elastic 產品 | Elastic
環境準備:
四臺機器(內存建議大于1G,比如1.5G; filebeat服務器可為1G) :
1,靜態IP(要求能上公網,最好用虛擬機的NAT網絡類型上網)
2,主機名及主機名綁定
10.1.1.11 vm1.cluster.com kibana 10.1.1.12 vm2.cluster.com elasticsearch 10.1.1.13 vm3.cluster.com logstash 10.1.1.14 vm4.cluster.com filebeat
3, 關閉防火墻和selinux
# systemctl stop firewalld # systemctl disable firewalld # iptables -F # setenforce 0 setenforce: SELinux is disabled
4, 時間同步
# systemctl restart ntpd # systemctl enable ntpd
5, yum源(centos安裝完系統后的默認yum源就OK)
elasticsearch
elasticsearch簡介
Elasticsearch(簡稱ES)是一個開源的分布式搜索引擎,Elasticsearch還是一個分布式文檔數據庫。所以它提供了大量數據的存儲功能,快速的搜索與分析功能。
提到搜索,大家肯定就想到了百度,谷歌,必應等。當然也有如下的搜索場景。
elasticsearch部署
第1步: 在elasticsearch服務器上(我這里為vm2),確認jdk(使用系統自帶的openjdk就OK)
[root@vm2 ~]# rpm -qa |grep openjdk java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64 java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64 [root@vm2 ~]# java -version openjdk version "1.8.0_161" OpenJDK Runtime Environment (build 1.8.0_161-b14) OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
第2步: es的安裝,配置
[root@vm2 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.2.rpm [root@vm2 ~]# rpm -ivh elasticsearch-6.5.2.rpm
第3步: 單機es的配置與服務啟動
[root@vm2 ~]# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#" cluster.name: elk-cluster 可以自定義一個集群名稱,不配置的話默認會取名為elasticsearch path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 打開注釋,并修改為監聽所有 http.port: 9200 打開注釋,監聽端口9200 ? [root@vm2 ~]# systemctl start elasticsearch [root@vm2 ~]# systemctl enable elasticsearch ? 啟動有點慢和卡,稍等1分鐘左右,查看到以下端口則表示啟動OK [root@vm2 ~]# netstat -ntlup |grep java tcp6 ? ? ? 0 ? ? ?0 :::9200 ? ? ? ? ? ? ? ? :::* ? ? ? ? ? ? ? ? ? ?LISTEN ? ? ?5329/java ? ? ? ? ? tcp6 ? ? ? 0 ? ? ?0 :::9300 ? ? ? ? ? ? ? ? :::* ? ? ? ? ? ? ? ? ? ?LISTEN ? ? ?5329/java ? 9200則是數據傳輸端口 9300端口是集群通信端口(我們暫時還沒有配置集群,現在是單點elasticsearch)
第4步: 查看狀態
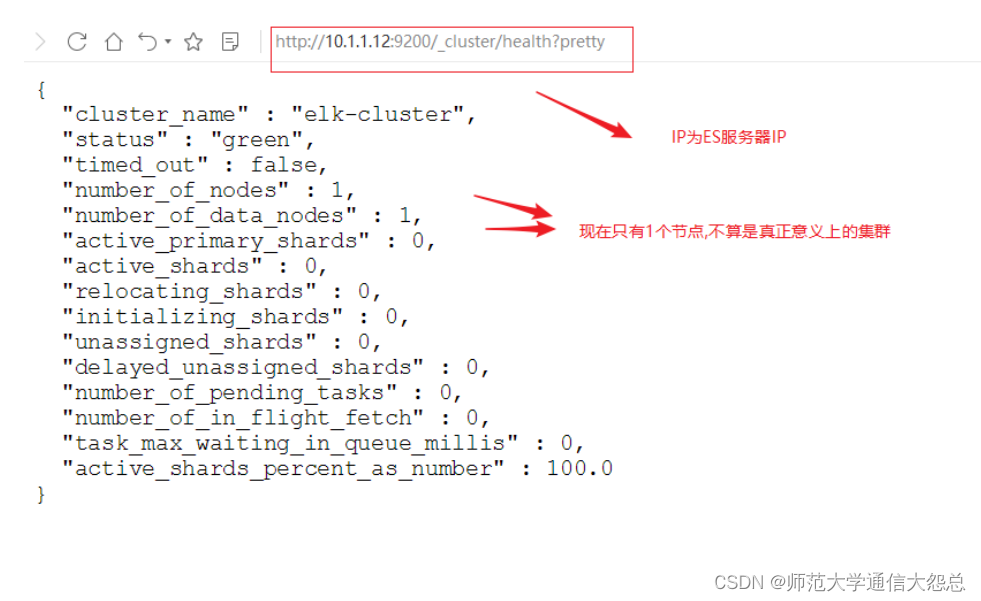
使用curl命令或瀏覽器訪問http://10.1.1.12:9200/_cluster/health?pretty地址(IP為ES服務器IP)
[root@vm2 ~]# curl http://10.1.1.12:9200/_cluster/health?pretty
elasticsearch集群部署
集群部署主要注意以下幾個方面
-
集群配置參數:
-
discovery.zen.ping.unicast.hosts,Elasticsearch默認使用Zen Discovery來做節點發現機制,推薦使用unicast來做通信方式,在該配置項中列舉出Master節點。
-
discovery.zen.minimum_master_nodes,該參數表示集群中Master節點可工作Master的最小票數,默認值是1。為了提高集群的可用性,避免腦裂現象。官方推薦設置為(N/2)+1,其中N是具有Master資格的節點的數量。
-
discovery.zen.ping_timeout,表示節點在發現過程中的等待時間,默認值是30秒,可以根據自身網絡環境進行調整,一定程度上提供可用性。
-
-
集群節點:
-
節點類型主要包括Master節點和data節點(client節點和ingest節點不討論)。通過設置兩個配置項node.master和node.data為true或false來決定將一個節點分配為什么類型的節點。
-
盡量將Master節點和Data節點分開,通常Data節點負載較重,需要考慮單獨部署。
-
-
內存:
-
Elasticsearch默認設置的內存是1GB,對于任何一個業務部署來說,這個都太小了。通過指定ES_HEAP_SIZE環境變量,可以修改其堆內存大小,服務進程在啟動時候會讀取這個變量,并相應的設置堆的大小。建議設置系統內存的一半給Elasticsearch,但是不要超過32GB。
-
-
硬盤空間:
-
Elasticsearch默認將數據存儲在/var/lib/elasticsearch路徑下,隨著數據的增長,一定會出現硬盤空間不夠用的情形,大環境建議把分布式存儲掛載到/var/lib/elasticsearch目錄下以方便擴容。
-
配置參考文檔: Elasticsearch Guide | Elastic
首先在ES集群所有節點都安裝ES(步驟省略)
可以使用兩臺或兩臺以上ES做集群, 以下就是兩臺ES做集群的配置
[root@vm1 ~]# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#" cluster.name: elk-cluster node.name: 10.1.1.11 本機IP或主機名 node.master: false 指定不為master節點 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.unicast.hosts: ["10.1.1.11", "10.1.1.12"] 集群所有節點IP
[root@vm2 ~]# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#" cluster.name: elk-cluster node.name: 10.1.1.12 本機IP或主機名 node.master: true 指定為master節點 path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.unicast.hosts: ["10.1.1.11", "10.1.1.12"] 集群所有節點IP
啟動或重啟服務
[root@vm1 ~]# systemctl restart elasticsearch [root@vm1 ~]# systemctl enable elasticsearch [root@vm2 ~]# systemctl restart elasticsearch
查看狀態
json(java script object notation)java對象表示法
elasticsearch基礎概念
主要的基礎概念有:Node, Index,Type,Document,Field,shard和replicas.
Node(節點):運行單個ES實例的服務器
Cluster(集群):一個或多個節點構成集群
Index(索引):索引是多個文檔的集合
Type(類型):一個Index可以定義一種或多種類型,將Document邏輯分組
Document(文檔):Index里每條記錄稱為Document,若干文檔構建一個Index
Field(字段):ES存儲的最小單元
Shards(分片):ES將Index分為若干份,每一份就是一個分片
Replicas(副本):Index的一份或多份副本
為了便于理解,我們和mysql這種關系型數據庫做一個對比:
| 關系型數據庫(如mysql,oracle等) | elasticsearch |
|---|---|
| database或schema | index |
| table | type |
| row | document |
| column或field | field |
ES是分布式搜索引擎,每個索引有一個或多個分片(shard),索引的數據被分配到各個分片上。你可以看作是一份數據分成了多份給不同的節點。
當ES集群增加或刪除節點時,shard會在多個節點中均衡分配。默認是5個primary shard(主分片)和1個replica shard(副本,用于容錯)。
elaticsearch基礎API操作
前面我們通過http://10.1.1.12:9200/_cluster/health?pretty查看ES集群狀態,其實就是它的一種API操作。
什么是API?
API(Application Programming Interface)應用程序編程接口,就是無需訪問程序源碼或理解內部工作機制就能實現一些相關功能的接口。
RestFul API 格式
curl -X<verb> ‘<protocol>://<host>:<port>/<path>?<query_string>’-d ‘<body>’
| 參數 | 描述 |
|---|---|
| verb | HTTP方法,比如GET、POST、PUT、HEAD、DELETE |
| host | ES集群中的任意節點主機名 |
| port | ES HTTP服務端口,默認9200 |
| path | 索引路徑 |
| query_string | 可選的查詢請求參數。例如?pretty參數將返回JSON格式數據 |
| -d | 里面放一個GET的JSON格式請求主體 |
| body | 自己寫的 JSON格式的請求主體 |
elasticseearch的API很多, 我們運維人員主要用到以下幾個要介紹的較簡單的API。
更多API參考: Elasticsearch Reference [6.2] | Elastic
查看節點信息
通過curl或瀏覽器訪問http://10.1.1.12:9200/_cat/nodes?v(ip為ES節點IP,如果有ES集群,則為ES任意節點IP)
[root@vm2 ~]# curl http://10.1.1.12:9200/_cat/nodes?v ip ? ? ? ?heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 10.1.1.12 ? ? ? ? ? 29 ? ? ? ? ?94 ? 2 ? ?2.33 ? ?1.88 ? ? 0.85 mdi ? ? ? - ? ? ?10.1.1.12 10.1.1.11 ? ? ? ? ? 26 ? ? ? ? ?92 ? 0 ? ?0.24 ? ?0.37 ? ? 0.33 mdi ? ? ? * ? ? ?10.1.1.11
查看索引信息
通過curl或瀏覽器訪問http://10.1.1.12:9200/_cat/indices?v
[root@vm2 ~]# curl http://10.1.1.12:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size 默認現在沒有任何索引
新增索引
[root@vm2 ~]# curl -X PUT http://10.1.1.12:9200/nginx_access_log
{"acknowledged":true,"shards_acknowledged":true,"index":"nginx_access_log"}[root@vm2 ~]# curl http://10.1.1.12:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open nginx_access_log 90Z7DvInTz6seXMBYhHVAw 5 1 0 0 2.2kb 1.1kb460b
green:所有的主分片和副本分片都已分配。你的集群是100%可用的。
yellow:所有的主分片已經分片了,但至少還有一個副本是缺失的。不會有數據丟失,所以搜索結果依然是完整的。不過,你的高可用性在某種程度上被弱化。如果 更多的 分片消失,你就會丟數據了。把 yellow 想象成一個需要及時調查的警告。
red:至少一個主分片(以及它的全部副本)都在缺失中。這意味著你在缺少數據:搜索只能返回部分數據,而分配到這個分片上的寫入請求會返回一個異常。
刪除索引
[root@vm2 ~]# curl -X DELETE http://10.1.1.12:9200/nginx_access_log
{"acknowledged":true}
ES查詢語句(拓展了解)
ES提供一種可用于執行查詢JSON式的語言,被稱為Query DSL。
針對elasticsearch的操作,可以分為增、刪、改、查四個動作。
查詢匹配條件:
-
match_all
-
from,size
-
match
-
bool
-
range
查詢應用案例:
導入數據源
使用官方提供的示例數據:
1, 下載并導入進elasticsearch
[root@vm2 ~]# wget https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json ? 導入進elasticsearch [root@vm2 ~]# curl -H "Content-Type: application/json" -XPOST "10.1.1.12:9200/bank/_doc/_bulk?pretty&refresh" --data-binary "@accounts.json" ? 查詢確認 [root@vm2 ~]# curl "10.1.1.12:9200/_cat/indices?v" health status index ? ? ?uuid ? ? ? ? ? ? ? ? ? pri rep docs.count docs.deleted store.size pri.store.size green ?open ? bank ? ? ? CzFQ_Gu1Qr2-bpV5MF0OBg ? 5 ? 1 ? ? ? 1000 ? ? ? ? ? ?0 ? ?874.7kb ? ? ? ?434.4kb
2, 查詢bank索引的數據(使用查詢字符串進行查詢)
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?q=*&sort=account_number:asc&pretty"說明: 默認結果為10條 _search 屬于一類API,用于執行查詢操作 q=* ES批量索引中的所有文檔 sort=account_number:asc 表示根據account_number按升序對結果排序 pretty調整顯示格式
3, 查詢bank索引的數據 (使用json格式進行查詢)
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search" -H 'Content-Type: application/json' -d'
{"query": { "match_all": {} },"sort": [{ "account_number": "asc" }]
}
'
注意: 最后為單引號
問題: 怎么將上面json格式進行pretty查詢?
查詢匹配動作及案例:
-
match_all
-
匹配所有文檔。默認查詢
-
示例:查詢所有,默認只返回10個文檔
-
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": { "match_all": {} }
}
'
?
# query告訴我們查詢什么
# match_all是我們查詢的類型
# match_all查詢僅僅在指定的索引的所有文件進行搜索
-
from,size
-
除了query參數外,還可以傳遞其他參數影響查詢結果,比如前面提到的sort,接下來使用的size
-
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": { "match_all": {} },"size": 1
}
'
查詢1條數據
指定位置與查詢條數
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": { "match_all": {} },"from": 0, "size": 2
}
'
from 0表示從第1個開始
size 指定查詢的個數
示例: 查詢account_number從第501條到510條的數據
curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": { "match_all": {} },"from": 500,"size": 10,"sort": [{ "account_number": "asc" }]
}
' 2>/dev/null |grep account_number
-
匹配查詢字段
-
返回_source字段中的片段字段
-
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": { "match_all": {} },"_source": ["account_number", "balance"]
}
'
-
match
-
基本搜索查詢,針對特定字段或字段集合進行搜索
-
查詢編號為20的賬戶
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": { "match": { "account_number": 20 } }
}
'
返回地址中包含mill的賬戶
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": { "match": { "address": "mill" } }
}
'
返回地址有包含mill或lane的所有賬戶
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": { "match": { "address": "mill lane" } } # 空格就是或的關系
}
'
-
bool
bool must 查詢的字段必須同時存在
查詢包含mill和lane的所有賬戶
?
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": {"bool": {"must": [{ "match": { "address": "mill" } },{ "match": { "address": "lane" } }]}}
}
'
?
bool should 查詢的字段僅存在一即可
查詢包含mill或lane的所有賬戶
?
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": {"bool": {"should": [{ "match": { "address": "mill" } },{ "match": { "address": "lane" } }]}}
}
'
-
range
-
指定區間內的數字或者時間
-
操作符:gt大于,gte大于等于,lt小于,lte小于等于
-
查詢余額大于或等于20000且小于等于30000的賬戶
?
[root@vm2 ~]# curl -X GET "10.1.1.12:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{"query": {"bool": {"must": { "match_all": {} },"filter": {"range": {"balance": {"gte": 20000,"lte": 30000}}}}}
}
'
elasticsearch-head
elasticsearch-head是集群管理、數據可視化、增刪改查、查詢語句可視化工具。從ES5版本后安裝方式和ES2以上的版本有很大的不同,在ES2中可以直接在bin目錄下執行plugin install xxxx 來進行安裝,但是在ES5中這種安裝方式變了,要想在ES5中安裝Elasticsearch Head必須要安裝NodeJs,然后通過NodeJS來啟動Head。
官網地址:GitHub - mobz/elasticsearch-head: A web front end for an elastic search cluster
elasticsearch-head安裝
第1步: 下載相關軟件并上傳到服務器
官網有安裝說明,可以通過git安裝,也可以下載zip包解壓安裝
下載相應的軟件包,并拷貝到ES集群的一個節點上(我這里拷貝到10.1.1.12這臺,也就是vm2上)
nodejs下載頁面: Download | Node.js
第2步: 安裝nodejs
[root@vm2 ~]# tar xf node-v10.15.0-linux-x64.tar.xz -C /usr/local/ [root@vm2 ~]# mv /usr/local/node-v10.15.0-linux-x64/ /usr/local/nodejs/ [root@vm2 ~]# ls /usr/local/nodejs/bin/npm /usr/local/nodejs/bin/npm 確認有此命令 [root@vm2 ~]# ln -s /usr/local/nodejs/bin/npm /bin/npm [root@vm2 ~]# ln -s /usr/local/nodejs/bin/node /bin/node
第3步: 安裝es-head
安裝方法1(需要網速好):
[root@vm2 ~]# git clone git://github.com/mobz/elasticsearch-head.git [root@vm2 ~]# cd elasticsearch-head先使用npm安裝grunt npm(node package manager):node包管理工具,類似yum Grunt是基于Node.js的項目構建工具 [root@vm2 elasticsearch-head]# npm install -g grunt-cli安裝時間較久,還會在網上下載phantomjs包 [root@vm2 elasticsearch-head]# npm install
安裝可能有很多錯誤,我這里出現了下面的錯誤(重點是注意紅色的ERR!,黃色的WARN不用管)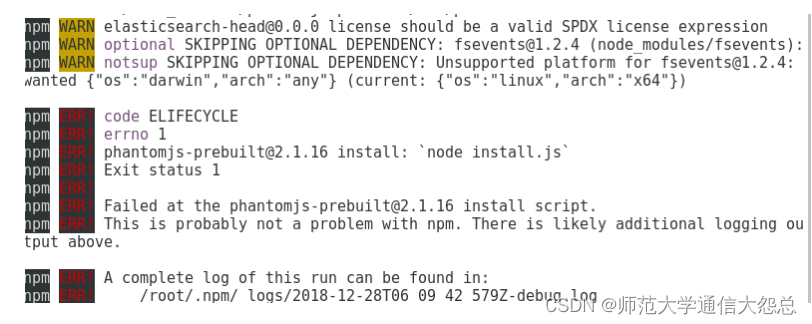
解決方法:
[root@vm2 elasticsearch-head]# npm install phantomjs-prebuilt@2.1.16 --ignore-script 此命令執行后不用再返回去執行npm install了,直接開始啟動 ? [root@vm2 elasticsearch-head]# nohup npm run start &
安裝方法二 : (==網速特別慢導致安裝時間過長的話可以嘗試以下方法==)
git clone慢的話就使用下載好的zip壓縮包解壓安裝 [root@vm2 ~]# unzip elasticsearch-head-master.zip -d /usr/local/ [root@vm2 ~]# mv /usr/local/elasticsearch-head-master/ /usr/local/es-head/ [root@vm2 ~]# cd /usr/local/es-head/ [root@vm2 es-head]# npm install -g grunt-cli --registry=http://registry.npm.taobao.org ? [root@vm2 es-head]# npm install --registry=http://registry.npm.taobao.org 當安裝出現下載phantomjs軟件包特別慢的時候,可以ctrl+c取消,拷貝下載好的phantomjs包到特定位置再重新安裝 [root@vm2 es-head]# cp phantomjs-2.1.1-linux-x86_64.tar.bz2 /tmp/phantomjs/ 注意:phantomjs請改成自己的絕對路徑 [root@vm2 es-head]# npm install --registry=http://registry.npm.taobao.org ? [root@vm2 es-head]# nohup npm run start &
==注意: 運行nohup npm run start &必須要先cd到es-head的目錄==
第4步:瀏覽器訪問
瀏覽器訪問http://es-head節點IP:9100 ,并在下面的地址里把localhost改為es-head節點IP(瀏覽器與es-head不是同一節點就要做)
第5步: 修改ES集群配置文件,并重啟服務
[root@vm1 ~]# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#" cluster.name: elk-cluster node.name: 10.1.1.11 node.master: false path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.unicast.hosts: ["10.1.1.11", "10.1.1.12"] http.cors.enabled: true http.cors.allow-origin: "*" 加上最后這兩句 ? [root@vm2 ~]# cat /etc/elasticsearch/elasticsearch.yml |grep -v "#" cluster.name: elk-cluster node.name: 10.1.1.12 node.master: true path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.unicast.hosts: ["10.1.1.11", "10.1.1.12"] http.cors.enabled: true http.cors.allow-origin: "*" 加上最后這兩句 ? [root@vm1 ~]# systemctl restart elasticsearch [root@vm2 ~]# systemctl restart elasticsearch
第6步: 再次連接就可以看到信息了
新建個索引試試 ???????
刪除此索引
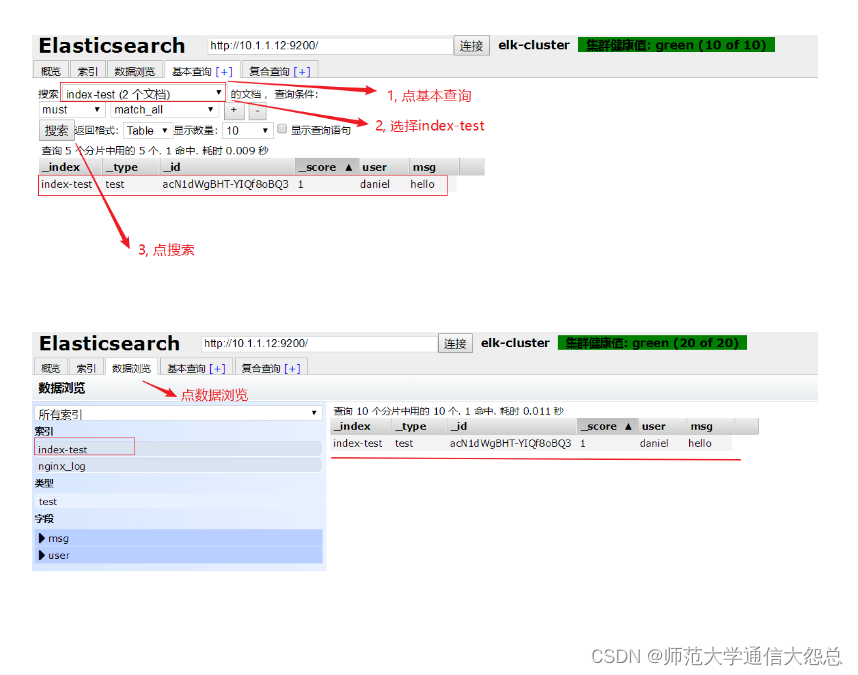
es-head查詢驗證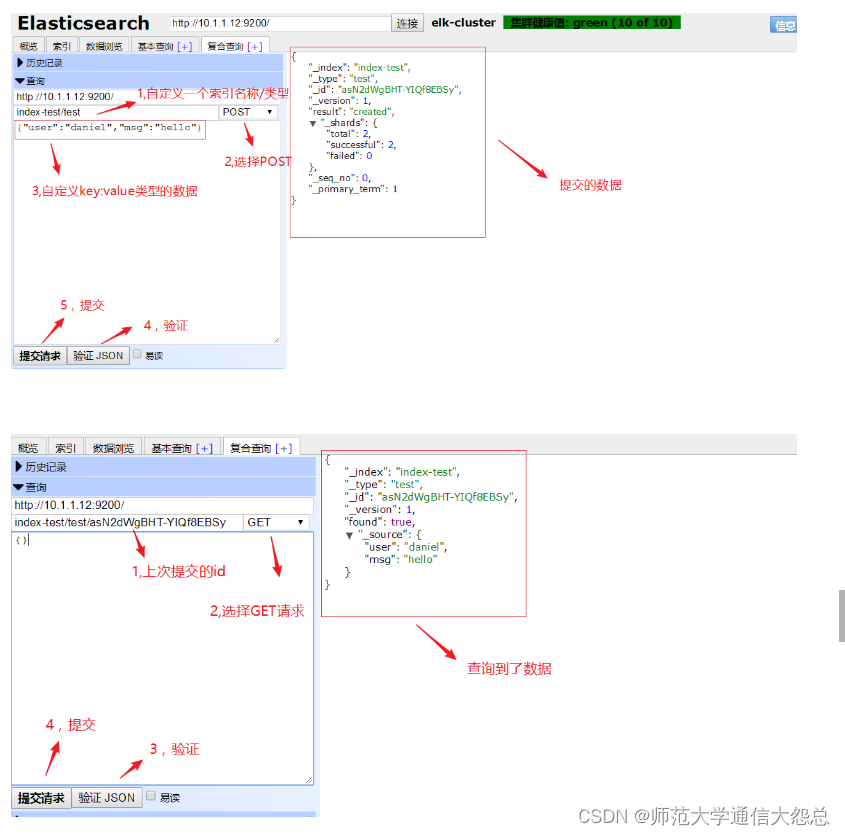
logstash
logstash簡介
logstash是一個開源的數據采集工具,通過數據源采集數據.然后進行過濾,并自定義格式輸出到目的地。
數據分為:
-
結構化數據 如:mysql數據庫里的表等
-
半結構化數據 如: xml,yaml,json等
-
非結構化數據 如:文檔,圖片,音頻,視頻等
logstash可以采集任何格式的數據,當然我們這里主要是討論采集系統日志,服務日志等日志類型數據。
官方產品介紹:Logstash:收集、解析和轉換日志 | Elastic
input插件: 用于導入日志源 (==配置必須==)
Input plugins | Logstash Reference [8.11] | Elastic
filter插件: 用于過濾(==不是配置必須的==)
Filter plugins | Logstash Reference [8.11] | Elastic
output插件: 用于導出(==配置必須==)
Output plugins | Logstash Reference [8.11] | Elastic
logstash部署
在logstash服務器上確認openjdk安裝
[root@vm3 ~]# java -version openjdk version "1.8.0_161" OpenJDK Runtime Environment (build 1.8.0_161-b14) OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
在logstash服務器上安裝logstash
[root@vm3 ~]# wget https://artifacts.elastic.co/downloads/logstash/logstash-6.5.2.rpm [root@vm3 ~]# rpm -ivh logstash-6.5.2.rpm
配置logstash主配置文件
[root@vm3 ~]# cat /etc/logstash/logstash.yml |grep -v '#' |grep -v '^$' path.data: /var/lib/logstash path.config: /etc/logstash/conf.d/ 打開注釋,并加上配置目錄路徑 http.host: "10.1.1.13" 打開注釋,并改為本機IP(這是用于xpack監控用,但要收費,所以在這里不配置也可以) path.logs: /var/log/logstash
啟動測試
[root@vm3 ~]# cd /usr/share/logstash/bin
使用下面的空輸入和空輸出啟動測試一下
[root@vm3 bin]# ./logstash -e 'input {stdin {}} output {stdout {}}'
運行后,輸入字符將被stdout做為標準輸出內容輸出
關閉啟動
測試能啟動成功后,ctrl+c取消,則關閉了
另一種驗證方法:
#上述測試還可以使用如下方法進行:
[root@vm3]# vim /etc/logstash/conf.d/test.confinput {stdin {}
}filter {
}output {stdout {codec => rubydebug }
}[root@vm3 bin]# pwd
/usr/share/logstash/bin[root@vm3 bin]# ./logstash --path.settings /etc/logstash -f /etc/logstash/conf.d/test.conf -t
......
Config Validation Result: OK. Exiting Logstash--path.settings 指定logstash主配置文件目錄
-f 指定片段配置文件
-t 測試配置文件是否正確
codec => rubydebug這句可寫可不定,默認就是這種輸出方式
[root@vm3 bin]# ./logstash --path.settings /etc/logstash -r -f /etc/logstash/conf.d/test.conf
......haha
{"@timestamp" => 2019-07-02T10:40:10.839Z,"message" => "haha","host" => "vm3.cluster.com","@version" => "1"
}
hehe
{"@timestamp" => 2019-07-02T10:40:11.794Z,"message" => "hehe","host" => "vm3.cluster.com","@version" => "1"
}-r參數很強大,會動態裝載配置文件,也就是說啟動后,可以不用重啟修改配置文件
日志采集
采集messages日志
這里以/var/log/messages為例,只定義input輸入和output輸出,不考慮過濾
[root@vm3 bin]# vim /etc/logstash/conf.d/test.conf
input {file {path => "/var/log/messages"start_position => "beginning"}
}output {elasticsearch{hosts => ["10.1.1.12:9200"]index => "test-%{+YYYY.MM.dd}"}
}[root@vm3 bin]# ./logstash --path.settings /etc/logstash/ -r -f /etc/logstash/conf.d/test.conf &后臺運行如果要殺掉,請使用pkill java或ps查看PID再kill -9清除
通過瀏覽器訪問es-head驗證
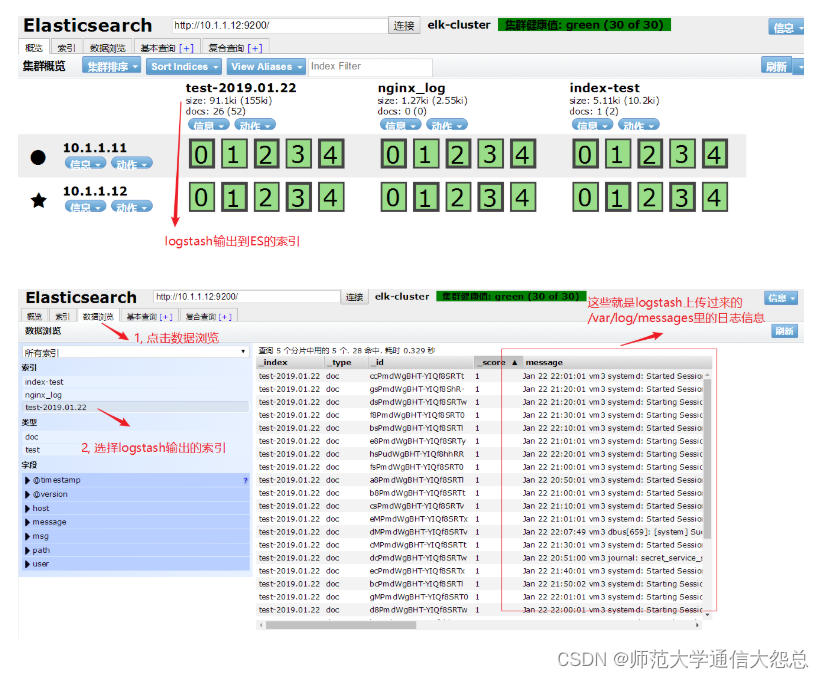
請自行練習驗證:
1, 在logstash那臺服務器上做一些操作(比如,重啟下sshd服務), 讓/var/log/message有新的日志信息,然后驗證es-head里的數據。
結果: 會自動更新, 瀏覽器刷新就能在es-head上看到更新的數據。
2, kill掉logstash進程(相當于關閉), 也做一些操作讓/var/log/message日志有更新,然后再次啟動logstash。
結果: 會自動連上es集群, es-head里也能查看到數據的更新。
采集多日志源
[root@vm3 bin]# vim /etc/logstash/conf.d/test.confinput {file {path => "/var/log/messages"start_position => "beginning"type => "messages"}file {path => "/var/log/yum.log"start_position => "beginning"type => "yum"}
}filter {}output {if [type] == "messages" {elasticsearch {hosts => ["10.1.1.12:9200","10.1.1.11:9200"]index => "messages-%{+YYYY-MM-dd}"}}if [type] == "yum" {elasticsearch {hosts => ["10.1.1.12:9200","10.1.1.11:9200"]index => "yum-%{+YYYY-MM-dd}"}}
}





覆蓋優化 - 附代碼)
)












Blob and ArrayBuffer)