文章目錄
- 一、完整代碼
- 二、論文解讀
- 2.1 模型架構
- 2.2 參數設置
- 2.3 數據
- 2.4 評估
- 三、對比
- 四、整體總結
論文:RoBERTa:A Robustly Optimized BERT Pretraining Approach
作者:Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov
時間:2019
地址:https://github.com/pytorch/fairseq
一、完整代碼
這里我們使用python代碼進行實現
# 完整代碼在這里
# 有時間再做
二、論文解讀
RoBERTa,這個論文名字我剛聽到的時候,我以為是加了旋轉編碼的BERT,沒想到是A Robustly Optimized BERT Pretraining Approach,其只是對BERT的一種探索和優化,其主要探索在以下幾個方面:
- 訓練更長的時間,使用更大的批次,處理更多的數據可以顯著提高性能;
- NSP任務效果并不顯著,在訓練的時候可以刪除;
- 訓練更長的sentence;
- 動態mask相較于靜態mask其提升并不是很大,但是RoBERTa還是采用了這種做法;
2.1 模型架構
和BERT完全一致,是transformer的encoder層構成的;

2.2 參數設置
Adam: β 1 = 0.9 , β 2 = 0.999 , ? = 1 e ? 6 \beta_1=0.9, \beta_2=0.999, \epsilon=1e-6 β1?=0.9,β2?=0.999,?=1e?6, L 2 = 0.01 L_2=0.01 L2?=0.01
dropout: d r o p o u t ? r a t e = 0.1 dropout-rate=0.1 dropout?rate=0.1
updates: 1000000 1000000 1000000
batch_size: 256 256 256
token_size: 512 512 512
attention_activation: G E L U GELU GELU
2.3 數據
為了擴大數據量,這里使用了下面這四個數據;
- BOOKCORPUS (Zhu et al., 2015) plus English WIKIPEDIA. This is the original data used to train BERT. (16GB).
- CC-NEWS, which we collected from the English portion of the CommonCrawl News dataset (Nagel, 2016). The data contains 63 million English news articles crawled between September 2016 and February 2019. (76GB after filtering).
- OPENWEBTEXT (Gokaslan and Cohen, 2019), an open-source recreation of the WebText corpus described in Radford et al. (2019). The text is web content extracted from URLs shared on Reddit with at least three upvotes. (38GB).
- STORIES, a dataset introduced in Trinh and Le(2018) containing a subset of CommonCrawl data filtered to match the story-like style of Winograd schemas. (31GB).
2.4 評估
這里介紹了三個benchmarks,分別是:GLUE,SQuAD,RACE
GLUE:通用語言理解評估(GLUE)基準測試(Wang et al.,2019b)是一個用于評估自然語言理解系統的9個數據集的集合。6個任務被定義為單個句子分類或句子對分類任務。GLUE的組織者提供了培訓和開發數據的分割,以及一個提交服務器和排行榜,允許參與者在私人保留的測試數據上評估和比較他們的系統。
SQuAD:斯坦福問題回答數據集(SQuAD)提供了一段上下文和一個問題。任務是通過從上下文中提取相關的跨度來回答這個問題。有了兩個版本的SQuAD: V1.1和V2.0(Rajpurkar等人,2016,2018)。在V1.1中,上下文總是包含一個答案,而在V2.0中的一些問題在所提供的上下文中沒有設有回答,這使得任務更具挑戰性。
RACE:從考試中獲得的閱讀理解(RACE)(Lai et al.,2017)任務是一個大規模的閱讀理解數據集,有超過28000篇文章和近10萬個問題。該數據集收集自專為中高中生設計的中國英語考試。在競賽中,每一段都與多個問題相關聯。對于每個問題,這個任務是從四個選項中選擇一個正確的答案。種族比其他流行的閱讀理解數據集的背景要長得多,需要推理的問題比例非常大
三、對比
Static Masking 和 Dynamic Masking

可以發現其實提升并不明顯,有的還降了,但是作者硬是認為也沒辦法,transformer用靜態怎么可能沒考慮動態呢,硬是水;
Model Input Format, Next Sentence Prediction 和 TrainBatch

這里先解釋一下:
SEGMENT-PAIR+NSP:這遵循了BERT(Devlin et al.,2019)中使用的原始輸入格式,有NSP丟失。每個輸入都有一對片段,每個片段可以包含多個自然句子,但總的組合長度必須小于512個標記。
SENTENCE-PAIR+NSP:每個輸入包含一對自然句子,要么從一個文檔的連續部分中采樣,要么從單獨的文檔中采樣。由于這些輸入明顯短于512個令牌,我們增加批大小,使令牌的總數保持與SEGMENT-PAIR+NSP相似。我們保留了NSP的損失。
FULL-SENTENCES:每個輸入都包含了從一個或多個文檔中連續采樣的完整句子,因此總長度最多為512個標記。輸入可以跨越文檔邊界。當我們到達一個文檔的結尾時,我們就開始從下一個文檔中采樣句子,并在文檔之間添加一個額外的分隔符標記。我們消除了NSP的損失。
DOC-SENTENCES:輸入的構造類似于FULL-SENTENCES,只是它們可能不會跨越文檔邊界。在文檔末尾附近采樣的輸入可能小于512個標記,因此我們在這些情況下動態地增加批處理大小,以實現與全句相似的總標記數量。我們消除了NSP的損失。
從這里我們可以發現:NSP影響不顯著,使用DOC要比FULL要略好;
TrainBatch

從這里我們可以發現,batch越大,能力越強;這里lr不同也許造成了一點干擾;
分詞編碼方式采取的是BPE,原來是30k,這里變大了,變成50k;
效果:



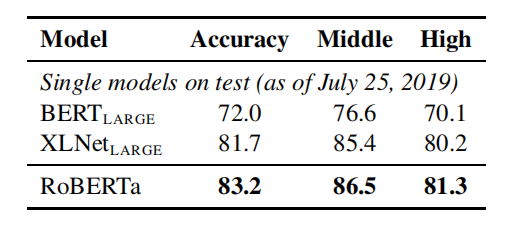
這也許表示了模型越大越好;
四、整體總結
RoBERTa只是對transformer的一種探索,結果是模型越大效果越好;
)




)



)









