1.研究背景與意義
項目參考AAAI Association for the Advancement of Artificial Intelligence
研究背景與意義:
隨著計算機視覺技術的快速發展,深度學習在圖像識別和目標檢測領域取得了巨大的突破。其中,YOLO(You Only Look Once)是一種非常流行的目標檢測算法,以其快速且準確的特點受到了廣泛關注。然而,YOLO算法在小目標檢測和遮擋目標檢測方面仍然存在一些挑戰。
在農業領域,小麥病害的檢測對于保障糧食安全和提高農作物產量具有重要意義。傳統的小麥病害檢測方法需要大量的人力和時間,效率低下且易受主觀因素的影響。因此,開發一種高效準確的小麥病害檢測系統對于農業生產具有重要意義。
目前,基于YOLO算法的小麥病害檢測系統已經取得了一定的成果。然而,由于小麥病害通常具有較小的目標尺寸和復雜的紋理特征,傳統的YOLO算法在小麥病害檢測中仍然存在一些問題。例如,由于YOLO算法的多尺度特性,較小的目標往往容易被忽略或錯誤分類。此外,遮擋目標的檢測也是一個具有挑戰性的問題。
因此,本研究旨在改進YOLOv8算法,提出一種融合可擴張殘差(DWR)注意力模塊的小麥病害檢測系統。該系統將利用DWR注意力模塊來增強YOLOv8算法對小目標和遮擋目標的檢測能力。DWR注意力模塊通過引入可擴張殘差結構,能夠更好地捕捉目標的細節信息,并提高目標的檢測精度。
本研究的意義主要體現在以下幾個方面:
首先,通過改進YOLOv8算法,提出一種融合DWR注意力模塊的小麥病害檢測系統,可以提高小目標和遮擋目標的檢測準確率。這將有助于農業生產中對小麥病害的快速準確檢測,提高農作物的產量和質量。
其次,DWR注意力模塊的引入可以增強目標的細節信息捕捉能力,提高目標的檢測精度。這對于小麥病害的檢測尤為重要,因為小麥病害通常具有復雜的紋理特征,傳統的目標檢測算法往往難以準確識別。
此外,本研究的成果還可以為其他農作物的病害檢測提供借鑒和參考。雖然本研究主要關注小麥病害檢測,但所提出的改進算法和注意力模塊可以應用于其他農作物的病害檢測,提高農業生產的效率和質量。
綜上所述,本研究旨在改進YOLOv8算法,提出一種融合DWR注意力模塊的小麥病害檢測系統。該系統的研究意義主要體現在提高小目標和遮擋目標的檢測準確率,增強目標的細節信息捕捉能力,以及為其他農作物的病害檢測提供借鑒和參考。這將有助于提高農業生產的效率和質量,保障糧食安全。
2.圖片演示



3.視頻演示
【改進YOLOv8】融合可擴張殘差(DWR)注意力模塊的小麥病害檢測系統_嗶哩嗶哩_bilibili
4.數據集的采集&標注和整理
圖片的收集
首先,我們需要收集所需的圖片。這可以通過不同的方式來實現,例如使用現有的公開數據集WheatDatasets。

labelImg是一個圖形化的圖像注釋工具,支持VOC和YOLO格式。以下是使用labelImg將圖片標注為VOC格式的步驟:
(1)下載并安裝labelImg。
(2)打開labelImg并選擇“Open Dir”來選擇你的圖片目錄。
(3)為你的目標對象設置標簽名稱。
(4)在圖片上繪制矩形框,選擇對應的標簽。
(5)保存標注信息,這將在圖片目錄下生成一個與圖片同名的XML文件。
(6)重復此過程,直到所有的圖片都標注完畢。
由于YOLO使用的是txt格式的標注,我們需要將VOC格式轉換為YOLO格式。可以使用各種轉換工具或腳本來實現。
下面是一個簡單的方法是使用Python腳本,該腳本讀取XML文件,然后將其轉換為YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-import xml.etree.ElementTree as ET
import osclasses = [] # 初始化為空列表CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:classes.append(cls) # 如果類別不存在,添加到classes列表中cls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')xml_path = os.path.join(CURRENT_DIR, './label_xml/')# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:label_name = img_xml.split('.')[0]print(label_name)convert_annotation(label_name)print("Classes:") # 打印最終的classes列表
print(classes) # 打印最終的classes列表整理數據文件夾結構
我們需要將數據集整理為以下結構:
-----data|-----train| |-----images| |-----labels||-----valid| |-----images| |-----labels||-----test|-----images|-----labels確保以下幾點:
所有的訓練圖片都位于data/train/images目錄下,相應的標注文件位于data/train/labels目錄下。
所有的驗證圖片都位于data/valid/images目錄下,相應的標注文件位于data/valid/labels目錄下。
所有的測試圖片都位于data/test/images目錄下,相應的標注文件位于data/test/labels目錄下。
這樣的結構使得數據的管理和模型的訓練、驗證和測試變得非常方便。
模型訓練
Epoch gpu_mem box obj cls labels img_size1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]all 3395 17314 0.994 0.957 0.0957 0.0843Epoch gpu_mem box obj cls labels img_size2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]all 3395 17314 0.996 0.956 0.0957 0.0845Epoch gpu_mem box obj cls labels img_size3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代碼講解
5.2 predict.py
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import opsclass DetectionPredictor(BasePredictor):def postprocess(self, preds, img, orig_imgs):preds = ops.non_max_suppression(preds,self.args.conf,self.args.iou,agnostic=self.args.agnostic_nms,max_det=self.args.max_det,classes=self.args.classes)if not isinstance(orig_imgs, list):orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)results = []for i, pred in enumerate(preds):orig_img = orig_imgs[i]pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)img_path = self.batch[0][i]results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))return results
這個程序文件是一個名為predict.py的文件,它是一個用于預測基于檢測模型的類DetectionPredictor的擴展。該類繼承自BasePredictor類,并包含了一個postprocess方法用于后處理預測結果并返回Results對象的列表。
在postprocess方法中,首先對預測結果進行非最大抑制操作,根據設定的置信度閾值和IOU閾值進行篩選,并根據設定的參數進行類別篩選和邊界框縮放操作。然后,將原始圖像、圖像路徑、類別名稱和篩選后的邊界框信息作為參數,創建Results對象并添加到結果列表中。
該文件還包含了一個示例用法,通過創建DetectionPredictor對象并傳入相關參數,可以進行預測操作。
該程序文件使用了Ultralytics YOLO庫,遵循AGPL-3.0許可證。
5.4 backbone\convnextv2.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPathclass LayerNorm(nn.Module):def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise NotImplementedError self.normalized_shape = (normalized_shape, )def forward(self, x):if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass GRN(nn.Module):def __init__(self, dim):super().__init__()self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))def forward(self, x):Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)return self.gamma * (x * Nx) + self.beta + xclass Block(nn.Module):def __init__(self, dim, drop_path=0.):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)self.norm = LayerNorm(dim, eps=1e-6)self.pwconv1 = nn.Linear(dim, 4 * dim)self.act = nn.GELU()self.grn = GRN(4 * dim)self.pwconv2 = nn.Linear(4 * dim, dim)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):input = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1)x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.grn(x)x = self.pwconv2(x)x = x.permute(0, 3, 1, 2)x = input + self.drop_path(x)return xclass ConvNeXtV2(nn.Module):def __init__(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0., head_init_scale=1.):super().__init__()self.depths = depthsself.downsample_layers = nn.ModuleList()stem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList()dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] cur = 0for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])])self.stages.append(stage)cur += depths[i]self.norm = nn.LayerNorm(dims[-1], eps=1e-6)self.head = nn.Linear(dims[-1], num_classes)self.apply(self._init_weights)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):trunc_normal_(m.weight, std=.02)nn.init.constant_(m.bias, 0)def forward(self, x):res = []for i in range(4):x = self.downsample_layers[i](x)x = self.stages[i](x)res.append(x)return res
該程序文件是一個用于構建ConvNeXt V2模型的Python腳本。它定義了一系列的類和函數,用于構建不同規模的ConvNeXt V2模型。
文件中定義了以下類和函數:
-
LayerNorm類:支持兩種數據格式(channels_last和channels_first)的LayerNorm層。
-
GRN類:全局響應歸一化(Global Response Normalization)層。
-
Block類:ConvNeXtV2模型的基本塊。
-
ConvNeXtV2類:ConvNeXt V2模型的主體部分。
-
update_weight函數:用于更新模型權重。
-
convnextv2_atto函數:構建ConvNeXt V2模型(規模為atto)的函數。
-
convnextv2_femto函數:構建ConvNeXt V2模型(規模為femto)的函數。
-
convnextv2_pico函數:構建ConvNeXt V2模型(規模為pico)的函數。
-
convnextv2_nano函數:構建ConvNeXt V2模型(規模為nano)的函數。
-
convnextv2_tiny函數:構建ConvNeXt V2模型(規模為tiny)的函數。
-
convnextv2_base函數:構建ConvNeXt V2模型(規模為base)的函數。
-
convnextv2_large函數:構建ConvNeXt V2模型(規模為large)的函數。
-
convnextv2_huge函數:構建ConvNeXt V2模型(規模為huge)的函數。
這些函數可以根據輸入的參數構建不同規模的ConvNeXt V2模型,并且可以選擇加載預訓練的權重。
5.5 backbone\CSwomTramsformer.py
class CSWinTransformer(nn.Module):def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], mlp_ratio=4., qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm):super().__init__()self.num_classes = num_classesself.depths = depthsself.num_features = self.embed_dim = embed_dimself.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)self.pos_drop = nn.Dropout(p=drop_rate)dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay ruleself.blocks = nn.ModuleList([CSWinBlock(dim=embed_dim, reso=img_size // patch_size, num_heads=num_heads[i], mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])], norm_layer=norm_layer,last_stage=(i == len(depths) - 1))for i in range(len(depths))])self.norm = norm_layer(embed_dim)self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()trunc_normal_(self.head.weight, std=.02)zeros_(self.head.bias)def forward_features(self, x):x = self.patch_embed(x)x = self.pos_drop(x)for blk in self.blocks:x = blk(x)x = self.norm(x) # B L Creturn xdef forward(self, x):x = self.forward_features(x)x = x.mean(dim=1) # B Cif self.num_classes > 0:x = self.head(x)return x
這個程序文件是一個用于圖像分類的CSWin Transformer模型。它實現了CSWinBlock和LePEAttention兩個模塊,并定義了Mlp和Merge_Block兩個輔助模塊。CSWinBlock模塊是CSWin Transformer的基本構建塊,它包含了一個多頭注意力機制和一個多層感知機,用于處理輸入特征。LePEAttention模塊是一個特殊的注意力機制,它使用了局部位置編碼(Local Position Encoding)來增強注意力的表達能力。Mlp模塊是一個多層感知機,用于對輸入特征進行非線性變換。Merge_Block模塊是一個用于特征融合的模塊,它使用了一個卷積層和一個歸一化層來將多個分支的特征融合成一個輸出特征。整個模型的輸入是一個圖像,輸出是圖像的分類結果。
5.6 backbone\EfficientFormerV2.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from typing import Dict
import itertools
import numpy as np
from timm.models.layers import DropPath, trunc_normal_, to_2tupleclass Attention4D(torch.nn.Module):def __init__(self, dim=384, key_dim=32, num_heads=8,attn_ratio=4,resolution=7,act_layer=nn.ReLU,stride=None):super().__init__()self.num_heads = num_headsself.scale = key_dim ** -0.5self.key_dim = key_dimself.nh_kd = nh_kd = key_dim * num_headsif stride is not None:self.resolution = math.ceil(resolution / stride)self.stride_conv = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=stride, padding=1, groups=dim),nn.BatchNorm2d(dim), )self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear')else:self.resolution = resolutionself.stride_conv = Noneself.upsample = Noneself.N = self.resolution ** 2self.N2 = self.Nself.d = int(attn_ratio * key_dim)self.dh = int(attn_ratio * key_dim) * num_headsself.attn_ratio = attn_ratioh = self.dh + nh_kd * 2self.q = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),nn.BatchNorm2d(self.num_heads * self.key_dim), )self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),nn.BatchNorm2d(self.num_heads * self.key_dim), )self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),nn.BatchNorm2d(self.num_heads * self.d),)self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,kernel_size=3, stride=1, padding=1, groups=self.num_heads * self.d),nn.BatchNorm2d(self.num_heads * self.d), )self.talking_head1 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)self.talking_head2 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)self.proj = nn.Sequential(act_layer(),nn.Conv2d(self.dh, dim, 1),nn.BatchNorm2d(dim), )points = list(itertools.product(range(self.resolution), range(self.resolution)))N = len(points)attention_offsets = {}
EfficientFormerV2.py是一個用于圖像分類的模型文件。該文件定義了EfficientFormerV2模型的結構和各個組件的實現。
EfficientFormerV2模型是基于EfficientNet和Transformer的結構進行改進的。它包含了一個Embedding模塊、多個EfficientFormerBlock模塊和一個分類頭部。
Embedding模塊用于將輸入圖像進行特征提取和編碼。它包含了一個卷積層和一個歸一化層。
EfficientFormerBlock模塊是EfficientFormerV2模型的核心組件,用于構建多層的Transformer模塊。每個EfficientFormerBlock模塊包含了多個Attention4D模塊和一個MLP模塊。
Attention4D模塊是一個四維的注意力機制模塊,用于捕捉圖像特征之間的關系。它包含了多個卷積層和歸一化層。
MLP模塊是一個多層感知機模塊,用于對特征進行非線性變換和映射。
分類頭部用于將特征映射到類別概率分布。
整個EfficientFormerV2模型的結構是一個串聯的模塊序列,其中每個EfficientFormerBlock模塊之間使用殘差連接進行連接。最后一個EfficientFormerBlock模塊的輸出經過分類頭部進行分類。
EfficientFormerV2模型的輸入是一個圖像張量,輸出是一個類別概率分布張量。
6.系統整體結構
根據以上分析,該程序是一個用于視覺項目中小麥病害檢測系統的工程。它包含了多個文件,每個文件都有不同的功能,用于實現整個系統的各個模塊和功能。
下面是每個文件的功能的整理:
| 文件路徑 | 功能 |
|---|---|
| export.py | 導出YOLOv8模型為其他格式的文件 |
| predict.py | 進行目標檢測的預測操作 |
| ui.py | 創建圖形用戶界面,并實現與用戶的交互 |
| backbone\convnextv2.py | 構建ConvNeXt V2模型 |
| backbone\CSwomTramsformer.py | 構建CSWin Transformer模型 |
| backbone\EfficientFormerV2.py | 構建EfficientFormerV2模型 |
| backbone\efficientViT.py | 構建EfficientViT模型 |
| backbone\fasternet.py | 構建FasterNet模型 |
| backbone\lsknet.py | 構建LSKNet模型 |
| backbone\repvit.py | 構建RepVIT模型 |
| backbone\revcol.py | 構建RevCoL模型 |
| backbone\SwinTransformer.py | 構建Swin Transformer模型 |
| backbone\VanillaNet.py | 構建VanillaNet模型 |
| extra_modules\afpn.py | 實現AFPN模塊 |
| extra_modules\attention.py | 實現注意力機制模塊 |
| extra_modules\block.py | 實現基本塊模塊 |
| extra_modules\dynamic_snake_conv.py | 實現動態蛇形卷積模塊 |
| extra_modules\head.py | 實現模型的頭部模塊 |
| extra_modules\kernel_warehouse.py | 存儲不同模型的卷積核 |
| extra_modules\orepa.py | 實現OREPA模塊 |
| extra_modules\rep_block.py | 實現REP模塊 |
| extra_modules\RFAConv.py | 實現RFAConv模塊 |
| extra_modules_init_.py | 初始化extra_modules模塊 |
| extra_modules\ops_dcnv3\setup.py | 安裝DCNv3模塊 |
| extra_modules\ops_dcnv3\test.py | 測試DCNv3模塊 |
| extra_modules\ops_dcnv3\functions\dcnv3_func.py | 實現DCNv3模塊的函數 |
| extra_modules\ops_dcnv3\functions_init_.py | 初始化DCNv3模塊的函數 |
| extra_modules\ops_dcnv3\modules\dcnv3.py | 實現DCNv3模塊 |
| extra_modules\ops_dcnv3\modules_init_.py | 初始化DCNv3模塊 |
| models\common.py | 包含通用的模型函數和類 |
| models\experimental.py | 包含實驗性的模型函數和類 |
| models\tf.py | 包含TensorFlow模型函數和類 |
| models\yolo.py | 包含YOLO模型函數和類 |
| models_init_.py | 初始化models模塊 |
| utils\activations.py | 包含各種激活函數 |
| utils\augmentations.py | 包含數據增強函數 |
| utils\autoanchor.py | 包含自動錨框生成函數 |
| utils\autobatch.py | 包含自動批處理函數 |
| utils\callbacks.py | 包含回調函數 |
| utils\datasets.py | 包含數據集處理函數 |
| utils\downloads.py | 包含下載函數 |
| utils\general.py | 包含通用的輔助函數 |
| utils\loss.py | 包含損失函數 |
| utils\metrics.py | 包含評估指標函數 |
| utils\plots.py | 包含繪圖函數 |
| utils\torch_utils.py | 包含PyTorch的輔助函數 |
| utils_init_.py | 初始化utils模塊 |
| utils\aws\resume.py | 實現AWS的恢復函數 |
| utils\aws_init_.py | 初始化AWS模塊 |
| utils\flask_rest_api\example_request.py | 實現Flask REST API的示例請求 |
| utils\flask_rest_api\restapi.py | 實現Flask REST API的功能 |
| utils\loggers_init_.py | 初始化log |
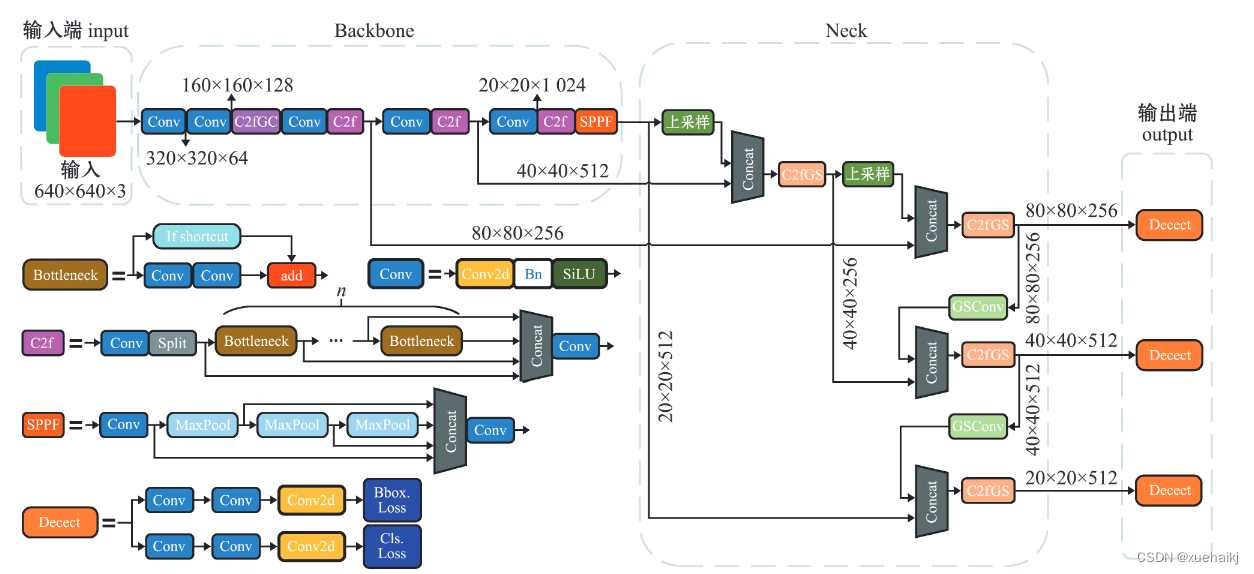
7.YOLOv8簡介
Yolov8網絡模型
Yolov8n的網絡分為輸入端、主干網( Back-bone) 、Neck模塊和輸出端4個部分(圖4)。輸
人端主要有馬賽克( Mosaic)數據增強、自適應錨框計算和自適應灰度填充。主干網有Conv、C2和SPPF結構,其中,C2r模塊是對殘差特征進行學習的主要模塊,該模塊仿照Yolov7的ELAN結構,通過更多的分支跨層連接,豐富了模型的梯度流,可形成一個具有更強特征表示能力的神經網絡模
塊。Neck模塊采用PAN ( path aggregation nelwOrk ,結構,可加強網絡對不同縮放尺度對象特征融合的
能力。輸出端將分類和檢測過程進行解耦,主要包括損失計算和目標檢測框篩選,其中,損失計算過程主要包括正負樣本分配策略和 Loss計算,Yolov8n 網絡主要使用TaskAlignedAssignerl 10]方法,即根據分類與回歸的分數加權結果選擇正樣本;Loss計算包括分類和回歸2個分支,無Ob-jecIness分支。分類分支依然采用BCE Loss,回歸分支則使用了Distribution Focal Loss!11〕和CIOU( complele inlersection over union)損失函數。
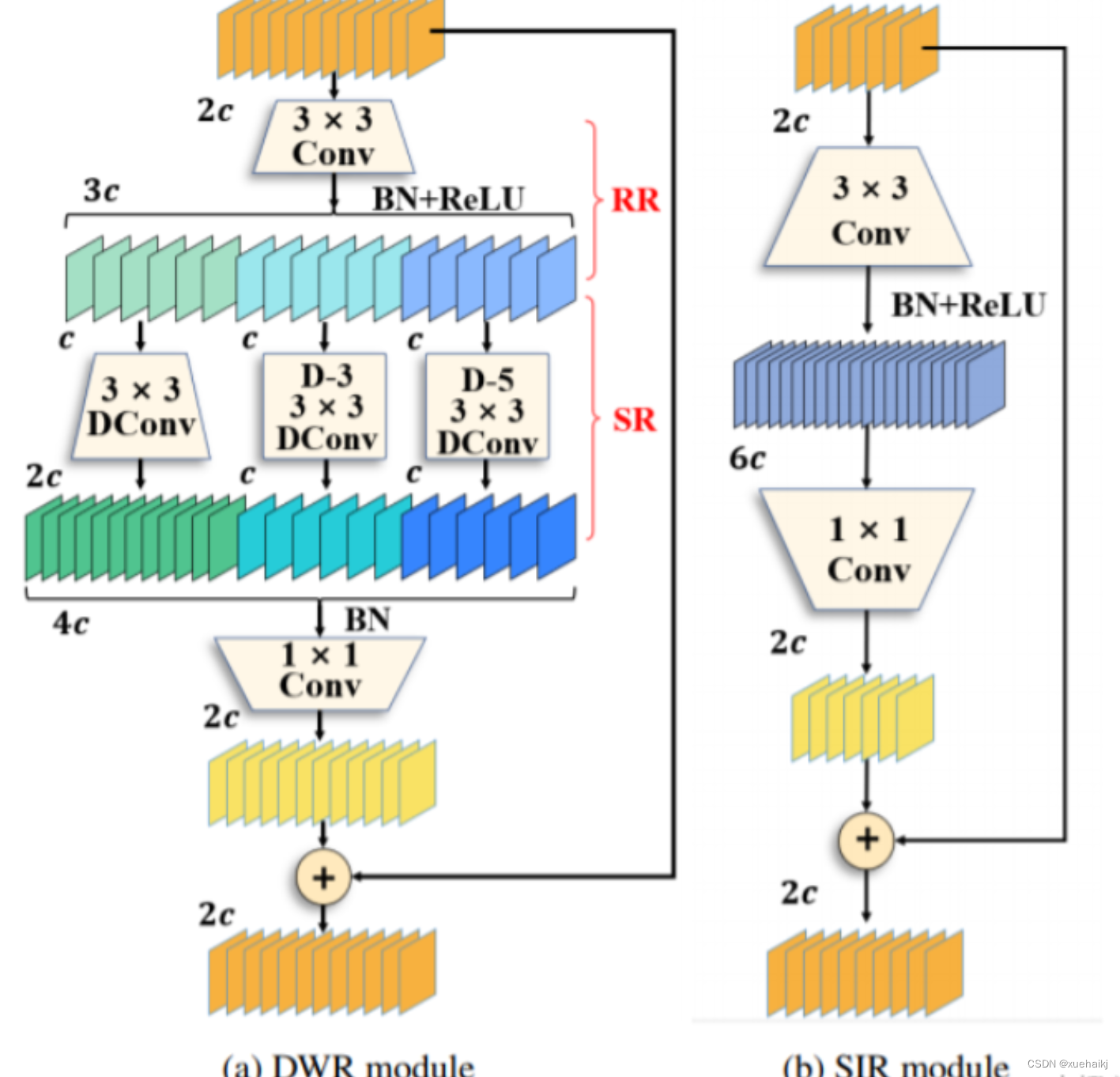
8.可擴張殘差(DWR)注意力模塊
當前的許多工作直接采用多速率深度擴張卷積從一個輸入特征圖中同時捕獲多尺度上下文信息,從而提高實時語義分割的特征提取效率。 然而,這種設計可能會因為結構和超參數的不合理而導致多尺度上下文信息的訪問困難。 為了降低繪制多尺度上下文信息的難度,我們提出了一種高效的多尺度特征提取方法,該方法分解了原始的單步特征提取方法方法分為兩個步驟,區域殘差-語義殘差。 在該方法中,多速率深度擴張卷積在特征提取中發揮更簡單的作用:根據第一步提供的每個簡明區域形式特征圖,在第二步中使用一個所需的感受野執行簡單的基于語義的形態過濾 一步,提高他們的效率。 此外,擴張率和擴張卷積的容量每個網絡階段都經過精心設計,以充分利用所有可以實現的區域形式的特征圖。 因此,我們分別為高層和低層網絡設計了一種新穎的擴張式殘差(DWR)模塊和簡單倒置殘差(SIR)模塊。

首先,該博客引入了一個Dilation-wise Residual(DWR)模塊,用于提取網絡高層的特征,如圖2a所示。多分支結構用于擴展感受野,其中每個分支采用不同空洞率的空洞深度卷積。
然后,專門設計了一個Simple Inverted Residual(SIR)模塊來提取網絡低層的特征,如圖2b所示。該模塊僅具有3×3的微小感受野,但使用inverted bottleneck式結構來擴展通道數量,確保更強的特征提取能力。
最后,基于DWR和SIR模塊,構建了一個編碼器-解碼器風格的網絡DWRSeg,其中解碼器采用了簡單的類似FCN的結構。解碼器使用來自最后兩個階段的強語義信息直接對特征圖進行上采樣,然后將它們與來自較低階段的特征圖(包含豐富的詳細信息)拼接起來,以進行最終預測。
9.訓練結果可視化分析
評價指標
epoch:訓練過程中的epoch號。
train/box_loss、、、train/obj_loss:train/cls_loss訓練期間邊界框、對象和類預測的損失。
metrics/precision、metrics/recall、metrics/mAP_0.5、metrics/mAP_0.5:0.95:不同 IoU(并集交集)閾值下的精度、召回率和平均精度 (mAP)。
val/box_loss、val/obj_loss、val/cls_loss:邊界框、對象和類的驗證損失。
x/lr0, x/lr1, x/lr2:網絡不同部分的學習率。
訓練結果可視化
我將通過為這些指標創建可視化來進行詳細分析,以了解模型在訓練期間的性能和行為。這將包括損失指標的趨勢、精確度、召回率和 mAP 分數的改進,以及學習率在不同時期的變化。讓我們首先可視化訓練和驗證損失。
import matplotlib.pyplot as plt# Setting up the plots
fig, ax = plt.subplots(3, 1, figsize=(12, 18))# Plotting training losses
ax[0].plot(data['epoch'], data['train/box_loss'], label='Box Loss', color='blue')
ax[0].plot(data['epoch'], data['train/obj_loss'], label='Object Loss', color='red')
ax[0].plot(data['epoch'], data['train/cls_loss'], label='Class Loss', color='green')
ax[0].set_xlabel('Epoch')
ax[0].set_ylabel('Training Loss')
ax[0].set_title('Training Losses per Epoch')
ax[0].legend()# Plotting validation losses
ax[1].plot(data['epoch'], data['val/box_loss'], label='Box Loss', color='blue')
ax[1].plot(data['epoch'], data['val/obj_loss'], label='Object Loss', color='red')
ax[1].plot(data['epoch'], data['val/cls_loss'], label='Class Loss', color='green')
ax[1].set_xlabel('Epoch')
ax[1].set_ylabel('Validation Loss')
ax[1].set_title('Validation Losses per Epoch')
ax[1].legend()# Plotting precision, recall, and mAP
ax[2].plot(data['epoch'], data['metrics/precision'], label='Precision', color='purple')
ax[2].plot(data['epoch'], data['metrics/recall'], label='Recall', color='orange')
ax[2].plot(data['epoch'], data['metrics/mAP_0.5'], label='mAP at 0.5 IoU', color='cyan')
ax[2].plot(data['epoch'], data['metrics/mAP_0.5:0.95'], label='mAP at 0.5:0.95 IoU', color='magenta')
ax[2].set_xlabel('Epoch')
ax[2].set_ylabel('Metrics')
ax[2].set_title('Precision, Recall, and mAP per Epoch')
ax[2].legend()plt.tight_layout()
plt.show()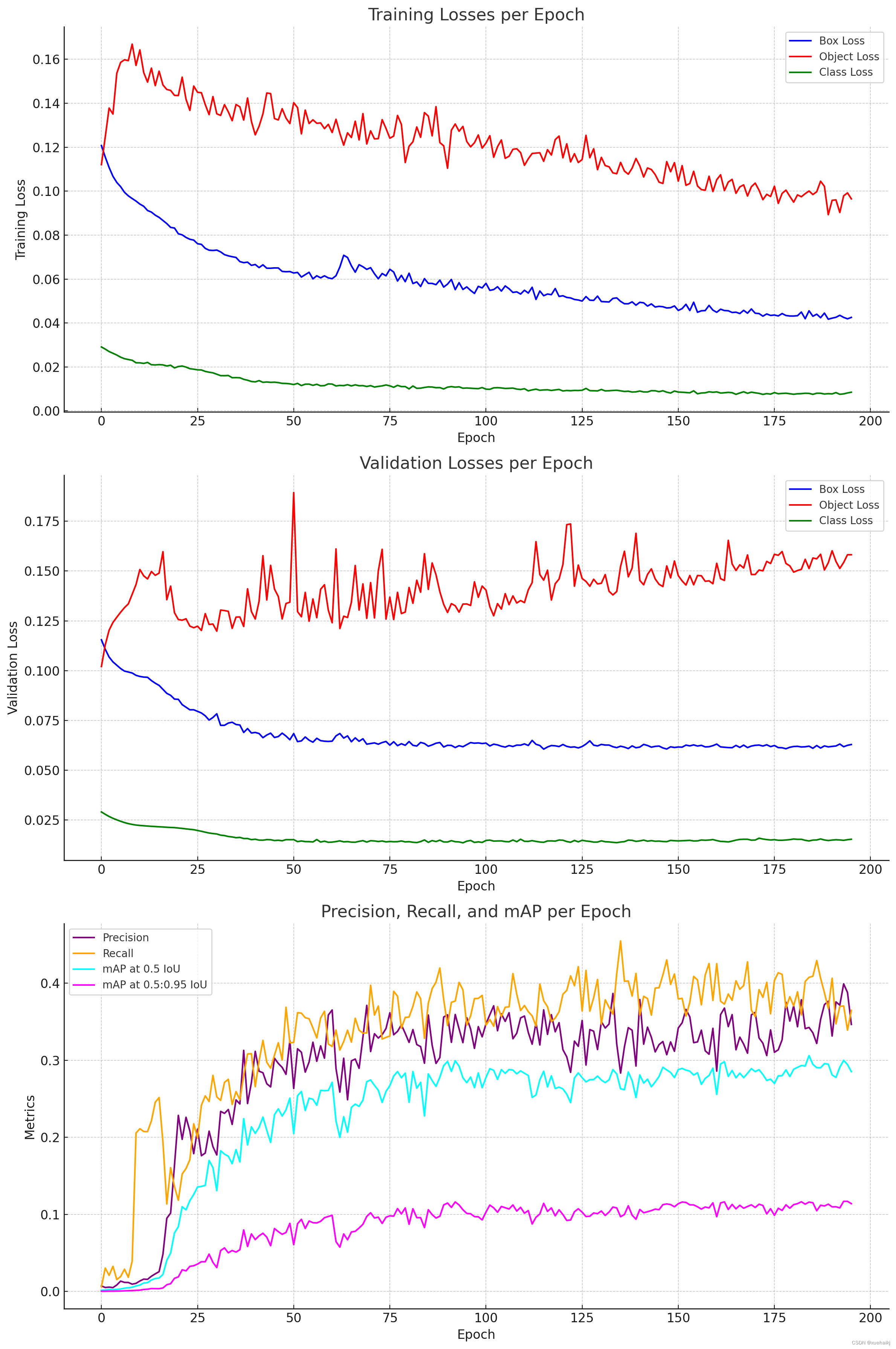
每個時期的訓練損失:
該圖顯示了訓練過程中框、對象和類損失的趨勢。理想情況下,這些應該隨著時間的推移而減少,表明學習和收斂。
每個時期的驗證損失:
與訓練損失類似,這些反映了模型在未見過的數據上的性能。重要的是要看看這些損失是否隨著訓練損失而減少,這表明具有良好的泛化性。
每個 Epoch 的精度、召回率和 mAP:
精度和召回率是對象檢測任務的關鍵指標,分別表示檢測到的對象的準確性和完整性。
不同 IoU 閾值下的平均精度 (mAP) 提供了模型性能的全面視圖,結合了精度和召回率方面。
分析和觀察:
損失:如果訓練和驗證損失正在減少,則表明模型正在有效地學習。然而,如果驗證損失與訓練損失不同,這可能表明過度擬合。
精確率和召回率:這些指標的增長趨勢是可取的。精度側重于模型預測的準確性,而召回率則衡量模型識別所有相關案例的能力。
mAP(平均精度):這是對象檢測任務中的一個關鍵指標。mAP 跨時代的改進表明,該模型在準確檢測具有正確邊界框的對象方面變得越來越好。
10.系統整合
下圖完整源碼&數據集&環境部署視頻教程&自定義UI界面

參考博客《【改進YOLOv8】融合可擴張殘差(DWR)注意力模塊的小麥病害檢測系統》
11.參考文獻
[1]王書獻,張勝茂,朱文斌,等.基于深度學習YOLOV5網絡模型的金槍魚延繩釣電子監控系統目標檢測應用[J].大連海洋大學學報.2021,(5).DOI:10.16535/j.cnki.dlhyxb.2020-333 .
[2]佚名.Deep neural networks for analysis of fisheries surveillance video and automated monitoring of fish discards[J].ICES Journal of Marine Science.2020,77(4).1340-1353.DOI:10.1093/icesjms/fsz149 .
[3]Aloysius T.M. van Helmond,Lars O. Mortensen,Kristian S. Plet‐,等.Electronic monitoring in fisheries: Lessons from global experiences and future opportunities[J].Fish & Fisheries.2020,21(1).162-189.DOI:10.1111/faf.12425 .
[4]Needle, Coby L.,Dinsdale, Rosanne,Buch, Tanja B.,等.Scottish science applications of Remote Electronic Monitoring[J].ICES journal of marine science.2015,72(4).1214-1229.DOI:10.1093/icesjms/fsu225 .
[5]Fran?ois Chollet.Xception: Deep Learning with Depthwise Separable Convolutions[C].


)
















