文章目錄
- 一、完整代碼
- 二、論文解讀
- 2.1 介紹
- 2.2 架構
- 2.3 輸入端
- 2.4 結果
- 三、過程實現
- 四、整體總結
論文:Unified Language Model Pre-training for Natural Language Understanding and Generation
作者:Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, Hsiao-Wuen Hon
時間:2019
地址:https://github.com/microsoft/unilm
一、完整代碼
這里我們使用python代碼進行實現
# 完整代碼在這里
# 有時間再弄.......
二、論文解讀
2.1 介紹
這篇論文主要講的是一個統一的語言模型的預訓練,其就是結合三種語言模型來對結果進行優化:unidirectional, bidirectional, sequence-to-sequence;前者的代表是GPT;中間的代表是BERT;后面很新奇,但是其本質也很簡單,類似于GPT在mask加掩碼;

這里并不是一個模型中包含這三種層來進行訓練,而是共享參數然后對每一個語言模型的要求進行mask再來訓練;

一個語言模型對應一個或幾個下游任務,讓模型理解這個下游任務,然后疊加,這個就是UNILM;
2.2 架構
模型架構如圖所示:
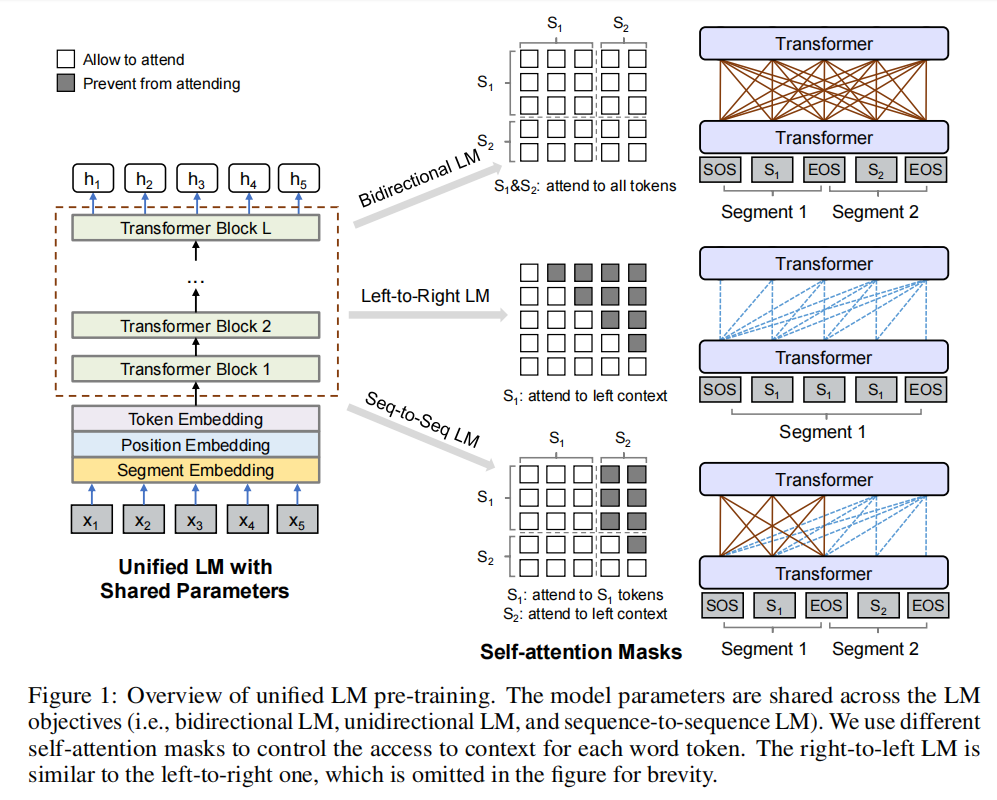
這個不就是mask一下嗎,換著花樣水,感覺就是統一了一下,沒想到這也能發論文,哈哈哈哈;

以上是其架構的公式;注意這里在訓練時M結構是不發生改變的;
2.3 輸入端
這里在輸入端和bert一樣,選擇加隨機掩碼的方式,把隨機的字符換成[mask]
2.4 結果
Question Answering
第一個被稱為extractive QA,其中答案是段落中的文本跨度。另一種稱為generative QA,答案需要動態生成。

Question Generation
Given an input passage and an answer span, our goal is to generate a question that asks for the answer.
就是給一段文本和答案,輸出該答案的問題;

Response Generation
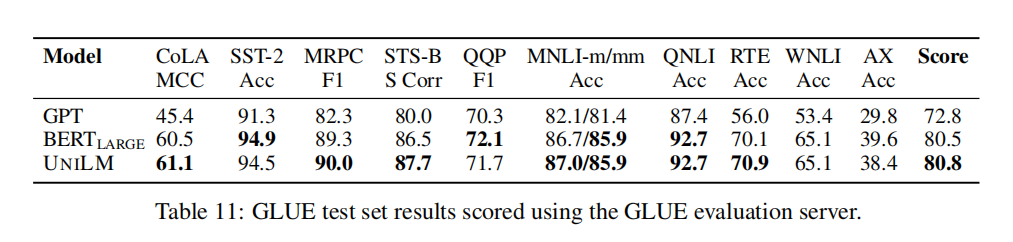
這樣可以說明我們結合三種模型的效果在訓練步驟一致的情況下和BERT是不相上下的,但是這里要清楚的是:UNILM的初始架構是和BERT large是一致的,這樣看來UNILM有種類似于regularization的效果;
三、過程實現
實現過程比較簡單,有時間再弄;
四、整體總結
這篇文章最重要一點就是結合多種模型來適配多種任務得到的效果要比單一的模型要好;

)
)


,集成了深度二開的ripro主題,非常適合做資源網站創業用)











)

)